non-capit alist societies.
which are these????
non-capit alist societies.
which are these????
Autoriteit Persoonsgegevens over generative AI
eLife Assessment
This study provides valuable insight into stress biology by showing that yeast populations can rapidly evolve a trehalose producing resting state that substantially improves survival and rapid regrowth after freeze-thaw. This finding is consistent with the role of trehalose metabolism as a biophysical adaptation that is broadly relevant to the community working on environmental resilience and dormancy. The evidence is convincing: the authors integrate experimental evolution, cell-level biophysical measurements, and modelling in a mutually reinforcing manner.
Reviewer #1 (Public review):
Summary:
This manuscript presents findings on the adaptation mechanisms of Saccharomyces cerevisiae under extreme stress conditions. The authors try to generalize this to adaptation to stress tolerance. A major finding is that S. cerevisiae evolves a quiescence-like state with high trehalose to adapt to freeze-thaw tolerance independent of their genetic background. The manuscript is comprehensive, and each of the conclusions is well supported by careful experiments.
Strengths:
This is excellent interdisciplinary work.
I have commented on the response of the authors, in-line, below. This is to maintain the conversation thread with the authors.
Comment 1:
Earlier papers have shown that loss of ribosomal proteins, that slow growth, leads to better stress tolerance in S. cerevisiae. Given this, isn't it expected that any adaptation that slows down growth would, overall, increase stress tolerance? Even for other systems, it has been shown that slowing down growth (by spore formation in yeast or bacteria/or dauer formation in C. elegans) is an effective strategy to combat stress and hence is a likely route to adaptation. The authors stress this as one of the primary findings. I would like the authors to explain their position, detailing how their findings are unexpected in the context of the literature.
Response:
We agree that the link between slower growth and higher stress tolerance has been well stud-ied. What is distinctive here is that repeated, near-lethal freeze-thaw selected not only for a tolerant/quiescent-like state but also for a shorter lag on re-entry. In this regime of freeze-thaw-regrowth, cells that are tolerant but slow to restart would be outcompeted by naive fast growers. Our quiescence-based selection simulations reproduce exactly this constraint. We have added this explanation to the Results to make clear that the novelty is the co-evolution of a tolerant, trehalose-rich state together with rapid regrowth under an alternating regime.
Comment to Response: I get the point. I believe that the outcome is highly dependent on how selection pressure is administered. So, generalizing this over all stresses (as done in the abstract) may not be accurate.
Comment 2:
Convergent evolution of traits: I find the results unsurprising. When selecting for a trait, if there is a major mode to adapt to that stress, most of the strains would adapt to that mode, independent of the route. According to me, finding out this major route was the objective of many of the previous reports on adaptive evolution. The surprising part in the previous papers (on adaptive evolution of bacteria or yeast) was the resampling of genes that acquired mutations in multiple replicates of an evolution experiments, providing a handle to understand the major genetic route or the molecular mechanism that guides the adaptation (for example in this case it would be - what guides the over-accumulation of trehalose). I fail to understand why the authors find the results surprising, and I would be happy to understand that from the authors. I may have missed something important.
Response:
Our surprise was precisely that we did not see the classical pattern of "phenotypic convergence + repeated mutations in the same locus/module." All independently evolved lines converged on a trehalose-rich, mechanically reinforced, quiescence-like phenotype, but population sequencing across lines did not reveal a single repeatedly hit gene or small shared pathway, even when we increased selection stringency (1-3 freeze-thaw cycles per round). We have now stated in the manuscript that this decoupling (strong phenotypic convergence, non-overlapping genetic routes) is the central inference: selection is acting on a physiologically defined state that multiple genotypes can reach.
Comment to Response: You indeed saw a case of phenotypic convergence. Converging towards trehalose-rich, mechanically reinforced, quiescent like - are phenotypes that have converged. This is what prevented lysis. The same locus need not be mutated over and over again, if the trehalose pathway is controlled by many processes (it is, and many are still unknown as I point in the next comment), many different mutations on different loci can result in the same regulation! I do not see the decoupling between phenotypic convergence and decoupling of genetic mutations as surprising or novel; molecular and cellular biology is replete with such examples where deletion(mutation) of hundreds of different genes can have the same phenotypic outcome (yeast deletion library screening, indirect effects etc). If this was a specific question unsolved in evolutionary biology, then the matter is different.
A minor point: Here I would also like to point out that the three phenotypes you measure may be linked to each other, so their independent evolution may just be a cause-effect relationship. For example Trehalose accumulation may drive the other two. This has not been deconvoluted in this manuscript.
Comment 3:
Adaptive evolution would work on phenotype, as all of selective evolution is supposed to. So, given that one of the phenotypes well-known in literature to allow free-tolerance is trehalose accumulation, I think it is not surprising that this trait is selected. For me, this is not a case of "non-genetic" adaptation as the authors point out: it is likely because perturbation of many genes can individually result in the same outcome - up-regulation of trehalose accumulation. Thereby, although the adaptation is genetic, it is not homogeneous across the evolving lines - the end result is. Do the authors check that the trait is actually a non-genetic adaptation, i.e., if they regrow the cells for a few generations without the stress, the cells fall back to being similarly only partially fit to freeze-thaw cycles? Additionally, the inability to identify a network that is conserved in the sequencing does not mean that there is no regulatory pathway. A large number of cryptic pathways may exist to alter cellular metabolic states.<br /> This is a point in continuation of point #2, and I would like to understand what I have missed.
Response:
We agree, and we have removed the wording "non-genetic adaptation." The evolved populations retain high survival even after regrowth for {greater than or equal to}25 generations without freeze-thaw, so the adaptation is clearly genetically maintained. What our data show is that there is no single genetic route to the shared phenotype; different mutations can all drive cells into the same trehalose-rich, quiescence-like, mechanochemically reinforced state. We now describe this as "genetic diversification with phenotypic convergence."
Comment to Response: While the last term does explain what is going on, isn't it an outcome that is routine in cell biology (as pointed out in my previous comment to your response)? I apologize for not understanding the punchline that is provided in the last few sentences of the abstract.
Comment 4:
To propose the convergent nature, it would be important to check for independently evolved lines and most probably more than 2 lines. It is not clear from their results section if they have multiple lines that have evolved independently.
Response:
We indeed evolved four independent lines and maintained two independent controls. We have added this information at the start of the Results so that the level of replication is immediately clear.
Comment to Response: Previous large scale studies have done hundreds of sequencing to oversample the pathway and figure out reproducible loci. With pooled sequencing (as mentioned below) and only 4 sample evolution, I am not sure that you would have the power in your study to conclude in the loci are sampled or not! If there were 10 gene LOFs that control Trehalose levels (which you can find from the published deletion screening experiment), then four of the experiments are likely to go through one of these routes; what is the likely event that you would identify the same route in two pools? It is unlikely, and therefore, sequencing of 4 pools cannot tell you if the mutation path is repeatedly sampled or not.
Comment 5:
For the genomic studies, it is not clear if the authors sequenced a pool or a single colony from the evolved strains. This is an important point, since an average sequence will miss out on many mutations and only focus on the mutations inherited from a common ancestral cell. It is also not clear from the section.
Response:
We sequenced population samples from the evolved lines. Our specific question was whether independently evolved lines would show the same high-frequency genetic solution, as is often seen in parallel evolution. Pool sequencing may under-sample rare/private variants, but it is appropriate for detecting such shared, high-frequency routes - and we do not find any. We have clarified this rationale in the Methods/Results.
Comment to Response: Please provide the average sequencing depth of each sequencing run. It is essential to understand the power of this study in identifying mutations. What coverage was used in Xgenome size?
Reviewer #2 (Public review):
Summary:
The authors used experimental evolution, repeatedly subjecting Saccharomyces cerevisiae populations to rapid liquid-nitrogen freeze-thaw cycles, while tracking survival, cellular biophysics, metabolite levels, and whole-genome sequence changes. Within 25 cycles, viability rose from ~2 % to ~70 % in all independent lines, demonstrating rapid and highly convergent adaptation despite distinct starting genotypes. Evolved cells accumulated about three-fold more intracellular trehalose, adopted a quiescence-like phenotype (smaller, denser, non-budding cells), showed cytoplasmic stiffening and reduced membrane damage, and re-entered growth with shorter lags-traits that together protected them from ice-induced injury. Whole-genome indicated that multiple genetic routes can yield the same mechano-chemical survival strategy. A population model in which trehalose controls quiescence entry, growth rate, lag, and freeze-thaw survival reproduced the empirical dynamics, implicating physiological state transitions rather than specific mutations as the primary adaptive driver. The study therefore concludes that extreme-stress tolerance can evolve quickly through a convergent, trehalose-rich quiescence-like state that reinforces membrane integrity and cytoplasmic structure.
Strengths:
Experimental design, data presentation and interpretation, writing
Weaknesses:
None
Comments on revisions:
The revised manuscript is improved and addresses the reviews concerns adequately.
Author response:
The following is the authors’ response to the original reviews.
We thank the editor and the reviewers for the detailed and constructive comments. In revising the manuscript we have: (i) clarified what is new relative to prior stress tolerance work, (ii) made explicit that we observe phenotypic convergence without a shared genetic route, (iii) stated upfront that we evolved four independent lines plus two controls, and (iv) corrected figure legends, statistics, and the missing citations. Below we respond point-by-point.
Public Reviews:
Reviewer #1 (Public review):
Summary:
This manuscript presents findings on the adaptation mechanisms of Saccharomyces cerevisiae under extreme stress conditions. The authors try to generalize this to adaptation to stress tolerance. A major finding is that S. cerevisiae evolves a quiescence-like state with high trehalose to adapt to freeze-thaw tolerance independent of their genetic background. The manuscript is comprehensive, and each of the conclusions is well supported by careful experiments.
Strengths:
This is excellent interdisciplinary work.
Weaknesses:
I have questions regarding the overall novelty of the proposal, which I would like the authors to explain.
(1) Earlier papers have shown that loss of ribosomal proteins, that slow growth, leads to better stress tolerance in S. cerevisiae. Given this, isn’t it expected that any adaptation that slows down growth would, overall, increase stress tolerance? Even for other systems, it has been shown that slowing down growth (by spore formation in yeast or bacteria/or dauer formation in C. elegans) is an effective strategy to combat stress and hence is a likely route to adaptation. The authors stress this as one of the primary findings. I would like the authors to explain their position, detailing how their findings are unexpected in the context of the literature.
We agree that the link between slower growth and higher stress tolerance has been well studied. What is distinctive here is that repeated, near-lethal freeze–thaw selected not only for a tolerant/quiescent-like state but also for a shorter lag on re-entry. In this regime of freeze–thaw–regrowth, cells that are tolerant but slow to restart would be outcompeted by naive fast growers. Our quiescence-based selection simulations reproduce exactly this constraint. We have added this explanation to the Results to make clear that the novelty is the co-evolution of a tolerant, trehaloserich state together with rapid regrowth under an alternating regime.
(2) Convergent evolution of traits: I find the results unsurprising. When selecting for a trait, if there is a major mode to adapt to that stress, most of the strains would adapt to that mode, independent of the route. According to me, finding out this major route was the objective of many of the previous reports on adaptive evolution. The surprising part in the previous papers (on adaptive evolution of bacteria or yeast) was the resampling of genes that acquired mutations in multiple replicates of an evolution experiments, providing a handle to understand the major genetic route or the molecular mechanism that guides the adaptation (for example in this case it would be - what guides the overaccumulation of trehalose). I fail to understand why the authors find the results surprising, and I would be happy to understand that from the authors. I may have missed something important.
Our surprise was precisely that we did not see the classical pattern of “phenotypic convergence + repeated mutations in the same locus/module.” All independently evolved lines converged on a trehalose-rich, mechanically reinforced, quiescence-like phenotype, but population sequencing across lines did not reveal a single repeatedly hit gene or small shared pathway, even when we increased selection stringency (1–3 freeze–thaw cycles per round). We have now stated in the manuscript that this decoupling (strong phenotypic convergence, non-overlapping genetic routes) is the central inference: selection is acting on a physiologically defined state that multiple genotypes can reach.
(3) Adaptive evolution would work on phenotype, as all of selective evolution is supposed to. So, given that one of the phenotypes well-known in literature to allow free-tolerance is trehalose accumulation, I think it is not surprising that this trait is selected. For me, this is not a case of ”non-genetic” adaptation as the authors point out: it is likely because perturbation of many genes can individually result in the same outcome - up-regulation of trehalose accumulation. Thereby, although the adaptation is genetic, it is not homogeneous across the evolving lines - the end result is. Do the authors check that the trait is actually a non-genetic adaptation, i.e., if they regrow the cells for a few generations without the stress, the cells fall back to being similarly only partially fit to freeze-thaw cycles? Additionally, the inability to identify a network that is conserved in the sequencing does not mean that there is no regulatory pathway. A large number of cryptic pathways may exist to alter cellular metabolic states.
This is a point in continuation of point #2, and I would like to understand what I have missed.
We agree, and we have removed the wording “non-genetic adaptation.” The evolved populations retain high survival even after regrowth for ≥25 generations without freeze–thaw, so the adaptation is clearly genetically maintained. What our data show is that there is no single genetic route to the shared phenotype; different mutations can all drive cells into the same trehalose-rich, quiescencelike, mechanochemically reinforced state. We now describe this as “genetic diversification with phenotypic convergence.”
(4) To propose the convergent nature, it would be important to check for independently evolved lines and most probably more than 2 lines. It is not clear from their results section if they have multiple lines that have evolved independently.
We indeed evolved four independent lines and maintained two independent controls. We have added this information at the start of the Results so that the level of replication is immediately clear.
(5) For the genomic studies, it is not clear if the authors sequenced a pool or a single colony from the evolved strains. This is an important point, since an average sequence will miss out on many mutations and only focus on the mutations inherited from a common ancestral cell. It is also not clear from the section.
We sequenced population samples from the evolved lines. Our specific question was whether independently evolved lines would show the same high-frequency genetic solution, as is often seen in parallel evolution. Pool sequencing may under-sample rare/private variants, but it is appropriate for detecting such shared, high-frequency routes — and we do not find any. We have clarified this rationale in the Methods/Results.
Reviewer #2 (Public review):
Summary:
The authors used experimental evolution, repeatedly subjecting Saccharomyces cerevisiae populations to rapid liquid-nitrogen freeze-thaw cycles while tracking survival, cellular biophysics, metabolite levels, and whole-genome sequence changes. Within 25 cycles, viability rose from ~2 % to ~70 % in all independent lines, demonstrating rapid and highly convergent adaptation despite distinct starting genotypes. Evolved cells accumulated about threefold more intracellular trehalose, adopted a quiescence-like phenotype (smaller, denser, non-budding cells), showed cytoplasmic stiffening and reduced membrane damage, and re-entered growth with shorter lag traits that together protected them from ice-induced injury. Whole-genome sequencing indicated that multiple genetic routes can yield the same mechano-chemical survival strategy. A population model in which trehalose controls quiescence entry, growth rate, lag, and freeze-thaw survival reproduced the empirical dynamics, implicating physiological state transitions rather than specific mutations as the primary adaptive driver. The study therefore concludes that extreme-stress tolerance can evolve quickly through a convergent, trehalose-rich quiescence-like state that reinforces membrane integrity and cytoplasmic structure.
Strengths:
The strengths of the paper are the experimental design, data presentation and interpretation, and that it is well-written.
(1) While the phenotyping is thorough, a few more growth curves would be quite revealing to determine the extent of cross-stress protection. For example, comparing growth rates under YPD vs. YPEG (EtOH/glycerol), and measuring growth at 37ºC or in the presence of 0.8 M KCl.
We thank the referee for the interesting suggestions. However, growth rates alone may be difficult to interpret since WT strains also show different growth rates under these conditions. Therefore, comparing the relative fitness or survival of the evolved strains versus the WT under these stresses would be more informative. In the present study we limited growth/survival measurements to what was needed to parameterize the adaptation model in YPD under the freeze–thaw regime. We have now added a statement in the Discussion that, given the shared trehalose/mechanical mechanism, such cross-stress assays are an expected and straightforward follow-up.
(2) Is GEMS integrated prior to evolution? Are the evolved cells transformable?
Yes. GEMs were integrated prior to evolution, because the non-integrated evolved population showed low transformation efficiency, likely due to altered cell-wall properties.
(3) From the table, it looks like strains either have mutations in Ras1/2 or Vac8. Given the known requirements of Ras/PKA signaling for the G1/S checkpoint (to make sure there are enough nutrients for S phase), this seems like a pathway worth mentioning and referencing. Regarding Vac8, its emerging roles in NVJ and autophagy suggest another nutrient checkpoint, perhaps through TORC1. The common theme is rewired metabolism, which is probably influencing the carbon shuttling to trehalose synthesis.
We appreciate the reviewer’s suggestion to consider pathways like Ras/PKA (linked to Ras1/2) and autophagy/TORC1 (linked to Vac8) as potential upstream modulators. While these pathways are involved in nutrient sensing and metabolic regulation, we choose not to emphasize them specifically. This is because (i) some evolved lines lack Ras1/2 or Vac8 variants, and (ii) none of the variants lies directly in trehalose synthesis/degradation pathways. Furthermore, direct links to trehalose accumulation are not well established for these specific variants in this context, and pathways like Ras are global regulators with broad effects. Together with the strongly convergent phenotype, this supports our main inference that multiple genetic/metabolic routes can feed into the same trehalose-rich, mechanochemically reinforced, quiescence-like state. We have added a note in the discussion regarding metabolic rewiring and trehalose.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Generally, the results sections should have more details. The figures should be corrected, and the legends should be checked for correctness. The manuscript seems to have been assembled in haste?
We have expanded the relevant Results subsections with one-sentence motivations (why each measurement was performed) and we have corrected the figure legends for ordering and consistency.
Figure 3: It will be good to have the correct p-values on the figure itself. P-values are typically less than 1, unless there is some special method (here the values presented are
, etc). Please explain how the P-values were obtained in the figure legend itself.
Figure 3 now shows the actual p-values. The legend specifies the details and the sample sizes used.
Figure 5: It is not clear what the error bars show in 5B, E (different evolved population/ clones/ cells?). All the figure legends are mixed up, please correct them. It is difficult to follow the paper.
Figure 5 legends now state clearly what the error bars represent (biological replicates) and which panels are from single-cell measurements. We have checked the panel lettering and legend order for consistency with the flow of the main text.
Reviewer #3 (Recommendations for the authors):
Overall, the paper is outstanding, well-written, and insightful.
A point to address is that there are missing citations on lines 60, 91.
We have added the missing citations at both locations. We apologize for the omission, which was due to a compilation error. This error has been fixed, and the bibliography has been corrected (now containing 74 references).
La ciencia de la información [ 1 ] [ 2 ] [ 3 ] (abreviada como infosci ) es un campo académico que se ocupa principalmente del análisis , la recopilación, la clasificación , la manipulación, el almacenamiento, la recuperación , el movimiento, la difusión y la protección de la información
A demás de lo que se menciona sobre la ciencia de la informacion, agregaria que es una necesidad del ser humano para su desarrollo integral.
eLife Assessment
The authors present an important set of data implicating ETFDH as an epigenetically suppressed gene in cancer with tumor suppressive functions. The evidence is convincing, with the authors demonstrating that suppression of ETFDH activity results in accumulation of amino acids that impact metabolism via hyperactive mTORC1.
Reviewer #1 (Public review):
In their manuscript, Papadopoli et al explore the role of ETFDH in transformation. They note that ETFDH protein levels are decreased in cancer, and that deletion of ETFDH in cancer cell lines results in increased tumorigenesis, elevated OXPHOS and glycolysis, and a reduction in lipid and amino acid oxidation. The authors attribute these effects to increased amino acid levels stimulating mTORC1 signaling and driving alterations in BCL6 and EIF4EBP1. They conclude that ETFDH1 is epigenetically silenced in a proportion of neoplasms, suggesting a tumor-suppressive function. Overall, the authors logically present clear data and perform appropriate experiments to support their hypotheses.
Reviewer #2 (Public review):
Summary:
The altered metabolism of tumors enables their growth and survival. Classically, tumor metabolism often involves increased activity of a given pathway in intermediary metabolism to provide energy or substrates needed for growth. Papadopoli et al. investigate the converse - the role of mitochondrial electron transfer flavoprotein dehydrogenase (ETFDH) in cancer metabolism and growth. The authors present compelling evidence that ETFDH insufficiency, which is detrimental in non-malignant tissues, paradoxically enhances bioenergetic capacity and accelerates neoplastic growth in cancer cells in spite of the decreased metabolic fuel flexibility that this affords tumor cells. This is achieved through the retrograde activation of the mTORC1/BCL-6/4E-BP1 axis, leading to metabolic and signaling reprogramming that favors tumor progression.
Strengths:
This review focuses primarily on the cancer metabolism aspects of the manuscript.
The study provides robust evidence linking ETFDH insufficiency to enhanced cancer cell bioenergetics and tumor growth.
The use of multiple cancer cell lines and in vivo models strengthens the generalizability of the findings.
The mechanistic insights into the mTORC1/BCL-6/4E-BP1 axis and its role in metabolic reprogramming are of general interest within and outside the immediate field of tumor metabolism.
Conclusion:
This manuscript provides significant insights into the role of ETFDH insufficiency in cancer metabolism and growth. The findings highlight the potential of targeting the mTORC1/BCL-6/4E-BP1 axis in ETFDH-deficient cancers. The compelling data support the conclusions presented in the manuscript, which will be valuable to the cancer metabolism community.
[Editors' note: The authors have addressed each of the two weaknesses previously listed in the public review, providing new experimental data on nucleotides and showing that the catalytic activity is required via the suggested addback experiment.]
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Authors state, "we identified ETF dehydrogenase (ETFDH) as one of the most dispensable metabolic genes in neoplasia." Surely there are thousands of genes that are dispensable for neoplasia. Perhaps the authors can revise this sentence and similar sentiments in the text.
We agree with the reviewer and have corrected the text accordingly. Specifically, we rephrased the sentence: “Surprisingly, we observed that in contrast to muscle, ETFDH is one of the most non-essential metabolic genes in cancer cells.” to “Surprisingly, we observed that in contrast to muscle, ETFDH is a non-essential gene in acute lymphoblastic leukemia NALM-6 cells”
Authors state, "These findings show that ETFDH loss elevates glutamine utilization in the CAC to support mitochondrial metabolism." While elevated glutamine to CAC flux is consistent with the statement that increased glutamine, the authors have not measured the effect of restoring glutamine utilization to baseline on mitochondrial metabolism. Thus, the causality implied by the authors can only be inferred based on the data presented. Indeed, the increased glutamine consumption may be linked to the increase in ROS, as glutamate efflux via system xCT is a major determinant of glutamine catabolism in vitro.
Indeed. We changed the statement "These findings show that ETFDH loss elevates glutamine utilization in the CAC to support mitochondrial metabolism." to "Collectively, these data demonstrate that ETF insufficiency in cancer cells remodels mitochondrial metabolism and increases the glutamine consumption and anaplerosis."
Authors state that the mechanism described is an example of "retrograde signaling". However, the mechanism seems to be related to a reduction in BCAA catabolism, suggesting that the observed effects may be a consequence of altered metabolic flux rather than a direct signaling pathway. The data presented do not delineate whether the observed effects stem from disrupted mitochondrial communication or from shifts in nutrient availability and metabolic regulation.
Notwithstanding that the term “retrograde” was used to refer to signaling from mitochondria to mTORC1, rather than from mTORC1 to mitochondria [1], we have removed the term “retrograde signaling” throughout the manuscript.
The authors should discuss which amino acids that are ETFDH substrates might affect mTORC1 activity or consider whether other ETFDH substrates might also affect mTORC1 in their discussion. Along these lines, the authors might consider discussing why amino acids that are not ETFDH substrates are increased upon ETFDH loss.
Based on the literature, we expect that branched chain amino acids that are ETFDH substrates (e.g., leucine) are likely to play a major role in activating mTORC1 upon ETFDH abrogation. As expected, the aforementioned amino acids are among those that are the most highly upregulated in ETFDH deficient cells (Fig 3A). We have, however, never formally tested the role of branched chain amino acid in activating mTORC1 in the context of ETFDH disruption. The increase in amino acids that are not metabolized via ETFDH, is likely to stem from global metabolic rewiring of ETFDH-deficient cells and observed alterations in amino acid uptake (e.g., glutamine; Fig 2F). We discuss this in the revised version of the paper as follows:
“Several metabolites can be sensed via signaling partners upstream of mTORC1, including leucine, arginine, methionine/SAM, and threonine [2]. Branched-chain amino acids (leucine, isoleucine, and valine), which are among the highest upregulated metabolites in ETFDH deficient cells (Fig 3A) serve as ETFDH substrates, and have been described to display strong activation capabilities towards mTORC1 in the literature [3,4]. Glutamine can also activate mTORC1 through Arf family of GTPases [5]. Indeed, glutamine can supplement the non-essential amino acid (NEAA) pool through transamination [6] and amino acid uptake [7]. Accordingly, the maintenance of NEAA that are non-ETFDH substrates may be supported by the global metabolic rewiring fueled by enhanced glutamine metabolism in ETFDH-deficient cells. Deciphering the mechanisms leading to accumulation of specific amino acids and their role in ETFDH-dependent mTORC1 modulation is warranted.”
Reviewer #2 (Public review):
The authors would strengthen the paper considerably by adding back catalytically inactive ETFDH to show that the activity of this enzyme is responsible for the increased growth phenotypes and changes in labeling that they observe.
Based on the Reviewers’ suggestions we performed these experiments. Herein, we took advantage of Y304A/G306E ETFDH mutant that impairs electron transfer from ETF and cannot substitute for the wild type (WT) gene function in ETFDH-deficient myoblasts [8]. We expressed WT and Y304A/G306E ETFDH mutant in ETFDH KO HCT116 colorectal cancer cells and confirmed that they are expressed to a comparable level (Supplementary Figure 6C). Re-expression of WT decreased proliferation, while suppressing mTORC1 signaling and increasing 4E-BP1 levels relative to control (vector infected) ETFDH KO EV HCT116 cells (Supplementary Figure 6D). In contrast, proliferation rates, mTORC1 signaling and 4E-BP1 levels remained largely unchanged upon Y304A/G306E ETFDH mutant expression in ETFDH KO HCT116 cells (Supplementary Figure 6D). Similarly, re-expression of WT ETFDH disrupted the bioenergetic phenotype associated with ETFDH loss, in contrast to re-expression of Y304A/G306E ETFDH mutant, which exhibited similar bioenergetic profiles as ETFDH KO control (Supplementary Figure 6E-F). Collectively these findings argue that the ETFDH activity is required for its tumor suppressive effects.
If nucleotide pool and labeling data are available, or can be obtained readily, this would significantly strengthen the tracing data already obtained.
We followed Reviewer’s suggestion and measured nucleotide levels. This revealed that loss of ETFDH results in increase in steady-state nucleotide pools (Supplementary Figure 2K), consistent with increased aspartate labelling and accelerated tumor growth.
References
(1) Morita, M. et al. mTORC1 controls mitochondrial activity and biogenesis through 4EBP-dependent translational regulation. Cell Metab 18, 698-711 (2013). https://doi.org/10.1016/j.cmet.2013.10.001
(2) Valenstein, M. L. et al. Structural basis for the dynamic regulation of mTORC1 by amino acids. Nature 646, 493-500 (2025). https://doi.org/10.1038/s41586-025-09428-7
(3) Appuhamy, J. A., Knoebel, N. A., Nayananjalie, W. A., Escobar, J., & Hanigan, M. D. Isoleucine and leucine independently regulate mTOR signaling and protein synthesis in MAC-T cells and bovine mammary tissue slices. J Nutr 142, 484-491 (2012). https://doi.org/10.3945/jn.111.152595
(4) Herningtyas, E. H. et al. Branched-chain amino acids and arginine suppress MaFbx/atrogin-1 mRNA expression via mTOR pathway in C2C12 cell line. Biochim Biophys Acta 1780, 1115-1120 (2008). https://doi.org/10.1016/j.bbagen.2008.06.004
(5) Jewell, J. L. et al. Metabolism. Differential regulation of mTORC1 by leucine and glutamine. Science 347, 194-198 (2015). https://doi.org/10.1126/science.1259472
(6) Tan, H. W. S., Sim, A. Y. L. & Long, Y. C. Glutamine metabolism regulates autophagy-dependent mTORC1 reactivation during amino acid starvation. Nat Commun 8, 338 (2017). https://doi.org/10.1038/s41467-017-00369-y
(7) Chen, R. et al. The general amino acid control pathway regulates mTOR and autophagy during serum/glutamine starvation. J Cell Biol 206, 173-182 (2014).https://doi.org/10.1083/jcb.201403009
(8) Herrero Martin, J. C. et al. An ETFDH-driven metabolon supports OXPHOS efficiency in skeletal muscle by regulating coenzyme Q homeostasis. Nat Metab 6, 209-225 (2024). https://doi.org/10.1038/s42255-023-00956-y
one of the cofounders of thegaming site Kongregate, Emily Greer, posted about the harassmentshe has received for her participation in the game industry. Promptedby GamerGate to reflect on the difference between messages sent toher and her brother, she wrote that she had assumed the harassmentshe received was “normal for a co-founder of a game site” and wassurprised to hear that her brother and fellow cofounder did not havethe same experience. Counting up their messages, she found that shereceives about four times as much harassment as her male sibling.
I've cut other examples for brevity.
The most frequently cited touch point for GamerGaters was theinsistence that a key part of their movement was about journalismethics.70 The most constructive read of the group is as a consumerboycott of people concerned about journalistic coverage that insultedtheir target audience instead of providing objective coverage of rele-vant news.71 The most common flashpoint in this regard was a flurry ofarticles that appeared shortly after the #GamerGate hashtag was bornthat decried the death of the gamer. The two most widely circulatedand referenced essays were those by Leigh Alexander and Dan Gold-ing.72 The argument about the end of gamers had three key claims.First, video games were reaching a broader audience than ever beforeand, as such, game publishers need not focus on the classic gamer ste-reotypes as their primary audience. This argument largely followed ina tradition of cultural criticism that proclaimed the death of the authoror a variety of other subject positions, and was backed up by data thatclearly indicate the audience of videogame players is far more diverse agroup than the white males of means who match the typical stereotypeof a group of gamers.73 Second, the term “gamer” was at one point akey reclamation of space that reframed people away from being a nerdor some other insulting label into something more positive.
Third and last argument is that they were scolded and told racist but that didn't sit with their views of themselves or their field. They aimed to protect it, and dismissed other cases as cherry picked anecdotes or as being a necessary part of the system, their system, their identity.
community, fueled by a strong desire to re-tain what already exists. Typically, the cases are carefully swaddled inappeals to skill, to being good enough, and to working hard enoughto make it. All these tropes are at the center of any sort of merito-cratic appeal. If the harassed were tough enough to take it, then theywould be able to reap the rewards of success. Systemic harassment setsthe terms on which players engage, giving stark advantage to thosewho are not targeted and retaining power for those who have alreadyclimbed the ladder.
There's this non-homogeneous group of white privilege people that yearn to continue playing these types of games, and that may even see themselves as activists when buying them. These may be big mainstream titles, but much like in cinema and TV, their budgets are also big. They know, and they don't mind, they wish these games be as larger and ambitious as possible, ever bigger, and more complex, and continuously "improving", and "innovating" in this sense. They see defending this kind of consumption as defending their identity, defending who they are, defending dark comedy and freedom of speech... freedom of speech, at which point does it become hate speech? Why should their tone for people that have no skin in the game and who aim to get rid of their identity, of their way of living, without asking? You see how both sides have self-reinforcing narratives, and they may even acknowledge this, and although many left-wingers would love to parse out this radically big titles, instead of talking it out and recognising the current exclusionary and biased present (not perpetuating endless debates), some prominent white privilege people push a zero-sum incompatibility competition narrative where one must survive, and it will be them.
You can't expect a person who's played 5000 hours, to quit Fifa overnight.
eLife Assessment
This manuscript investigates the extremely interesting and important claim that the human hippocampus represents interactions with multiple social interaction partners on two relatively abstract social dimensions - and that this ability correlates with the social network size of the participant. This research potentially demonstrates the intricate role of the hippocampus in navigating our social world. While most of the results are solid, the paper requires some further clarification.
Reviewer #1 (Public review):
Schafer et al. tested whether the hippocampus tracks social interactions as sequences of neural states within an abstract social space defined by the dimensions of affiliation and power, using a narrative-based task in which participants engaged in dynamic social interactions. The study showed that individual social relationships were represented as distinct trajectories of hippocampal activity patterns. These neural trajectories systematically reflected trial-by-trial changes in affiliation and power between the participant and each character, suggesting that the hippocampus encodes sequences of socially relevant events and their relational structure, extending its well-established role beyond spatial representations.
A major strength of this study is the use of a richly structured, narrative-based task that allows social relationships to evolve dynamically over time. The use of representational similarity analysis provides a principled framework for linking behavioral trajectories in social space to neural pattern dynamics.
One potential limitation concerns temporal autocorrelation in the neural data, as nearby trials are inherently related both behaviorally and temporally within a continuous narrative. Although the authors carefully attempted to control for temporal distance and related confounds, fully disentangling representational similarity driven by social structure from similarity driven by temporal proximity remains challenging within a single-session task design.
While the findings of a two-dimensional representational structure is an important contribution, it remains an open question whether such a representation reflects an inherent property of how the human brain encodes social relationships, or whether it is partly driven by task constraints in which social interactions were limited to changes along two (affiliation and power) dimensions. Future studies that allow social relationships to vary along richer or higher-dimensional feature spaces will be necessary to determine the generality of low dimensional representations.
Reviewer #2 (Public review):
The substantially revised paper has increased in clarity and is much more accessibe and straightforward than the first version. The analyses are now clearer and support the conclusions better. There are however some remaining methodological weakness, which in my mind still renders the evidence to not be entirely convincing.
(1) The temporal autocorrelation concern is not fully convincingly addressed. The temporal autocorrelation curves supplied in the supplements are really helpful, but linearly regressing out the temporal distance from the neural distance clearly does not work, as one can see from the right panel of supplementary Figure 1. If the method had worked correctly the line should have been flat. The analysis however shows that decision trials with a lag > 2 are basically independent - so a simple way to address this is to restrict the RSA analysis to trials with a decision lag of > 2. This analysis would strengthen the paper a lot.
(2) In the final analysis, the authors use all the trials to make the claim that the hippocampus represents the characters in a shared social space. However, as within-character distances are still included in the analysis, this result could still be driven by the effects of within-character representations that are not shared across characters. A simple way of addressing this concern would be to only include between-character distances in this analysis, making it truly complementary to the previous within-character analysis. It would also be very interesting to compare the the within- and between-character analyses in the hippocampus directly.
(3) Overall, the correction for multiple comparisons in the fMRI and the resulting corrected p-values are not sufficiently explained and documented in the paper. What was exactly permuted in the tests? Was correction applied in a voxel-wise or cluster-wise fashion? If cluster-wise, the cluster-wise p-values need to be reported.
Author response:
The following is the authors’ response to the original reviews.
Public reviews:
Reviewer #1 (Public review):
Summary:
Schafer et al. tested whether the hippocampus tracks social interactions as sequences of neural states within an abstract social space defined by dimensions of affiliation and power, using a task in which participants engaged in narrative-based social interactions. The findings of this study revealed that individual social relationships are represented by unique sequences of hippocampal activity patterns. These neural trajectories corresponded to the history of trial-to-trial affiliation and power dynamics between participants and each character, suggesting an extended role of the hippocampus in encoding sequences of events beyond spatial relationships.
The current version has limited information on details in decoding and clustering analyses which can be improved in the future revision.
Strengths:
(1) Robust Analysis: The research combined representational similarity analysis with manifold analyses, enhancing the robustness of the findings and the interpretation of the hippocampus's role in social cognition.
(2) Replicability: The study included two independent samples, which strengthens the generalizability and reliability of the results.
Weaknesses:
I appreciate the authors for utilizing contemporary machine-learning techniques to analyze neuroimaging data and examine the intricacies of human cognition. However, the manuscript would benefit from a more detailed explanation of the rationale behind the selection of each method and a thorough description of the validation procedures. Such clarifications are essential to understand the true impact of the research. Moreover, refining these areas will broaden the manuscript's accessibility to a diverse audience.
We thank the reviewer for these comments and have addressed them in various ways.
First, we removed the spline-based decoding and spectral clustering analyses. As we detail in our response to the recommendations, these approaches were complex and raised legitimate interpretational concerns, making it unclear how they supported our core claims. The revised manuscript now focuses on a set of representational similarity analyses to show representations consistent with social dimension similarity (affiliation vs. power decision trials) and social location similarity (trajectory/map-like coding based on participant choices).
Second, we expanded the Methods and Results to more clearly explain the analyses, the questions they address, and associated controls and robustness tests. The dimension similarity analysis tests whether hippocampal patterns differentiate affiliation and power decisions in a way consistent with an abstract dimension representation. The location similarity RSAs test whether within-character neural pattern distances scale with Euclidean distance in social space (relationship-specific trajectories), and whether pattern distances across all characters scale with location distances when distances are globally standardized, consistent with a shared map-like coordinate system.
Third, we emphasize new controls. For the dimension similarity RSA, we test for potential confounds such as word count, text sentiment, and reaction time differences between affiliation and power trials. For the location similarity RSA, we control for temporal distance between trials and show (in the Supplement) that the reported effects cannot be explained by temporal autocorrelation in the fMRI data or by the relationship between temporal distance and behavioral location distance.
We believe that these changes address the reviewer’s request for clearer rationale and validation.
Reviewer #2 (Public review):
Summary:
Using an innovative task design and analysis approach, the authors set out to show that the activity patterns in the hippocampus related to the development of social relationships with multiple partners in a virtual game. While I found the paper highly interesting (and would be thrilled if the claims made in the paper turned out to be true), I found many of the analyses presented either unconvincing or slightly unconnected to the claims that they were supposed to support. I very much hope the authors can alleviate these concerns in a revision of the paper.
Strengths & Weaknesses:
(1) The innovative task design and analyses, and the two independent samples of participants are clear strengths of the paper.
We thank the reviewer for this comment.
(2) The RSA analysis is not what I expected after I read the abstract and tile of the result section "The hippocampus represents abstract dimensions of affiliation and power". To me, the title suggests that the hippocampus has voxel patterns, which could be read out by a downstream area to infer the affiliation and power value, independent of the exact identity of the character in the current trial. The presented RSA analysis however presents something entirely different - namely that the affiliation trials and power trials elicit different activity patterns in the area indicated in Figure 3. What is the meaning of this analysis? It is not clear to me what is being "decoded" here and alternative explanations have not been considered. How do affiliation and power trials differ in terms of the length of sentences, complexity of the statements, and reaction time? Can the subsequent decision be decoded from these areas? I hope in the revision the authors can test these ideas - and also explain how the current RSA analysis relates to a representation of the "dimensions of affiliation and power".
We agree that this analysis needed to be better justified and explained. We have revised the text to clarify that by “represents the interaction decision trials along abstract social dimensions” we mean that hippocampal multivoxel patterns differentiate affiliation and power decisions in a way consistent with the conceptual framework of underlying latent dimensions. The analysis tests one simple prediction of this view – that on average these trial types are separable in the neural patterns. We have added details to the Methods, showing how the affiliation and power trials do not differ in word count or in sentiment, but do differ in their semantics, as assessed by a Large Language Model, as we expect from our task assumptions. Thanks to the reviewer’s comment, we also tested for and found a reaction time difference between affiliation and power trials, that we now control for.
(3) Overall, I found that the paper was missing some more fundamental and simpler RSA analyses that would provide a necessary backdrop for the more complicated analyses that followed. Can you decode character identity from the regions in question? If you trained a simple decoder for power and affiliation values (using the LLE, but without consideration of the sequential position as used in the spline analysis), could you predict left-out trials? Are affiliation and power represented in a way that is consistent across participants - i.e. could you train a model that predicts affiliation and power from N-1 subjects and then predict the Nth subject? Even if the answer to these questions is "no", I believe that they are important to report for the reader to get a full understanding of the nature of the neural representations in these areas. If the claim is that the hippocampus represents an "abstract" relationship space, then I think it is important to show that these representations hold across relationships. Otherwise, the claim needs to be adjusted to say that it is a representation of a relationship-specific trajectory, but not an abstract social space.
We appreciate this comment and agree on the value of clear, conceptually simple analyses. To address this concern, we have simplified our main analysis significantly by removing the spline-based analysis and substituting it with a multiple regression representational similarity analysis approach. We test whether within-character neural pattern distances scale with distance in social space (relationship-specific trajectories), and whether pattern distances across all characters scale with location distances when distances are globally standardized. We find evidence for both, consistent with a shared map-like coordinate system.
We agree that decoding character identity and an across-participant decoding approach could be informative. However, our current task is not well designed for such analyses and as such would complicate the paper. Although we agree that these questions are interesting, they would test questions that are outside the scope of this paper.
(4) To determine that the location of a specific character can be decoded from the hippocampal activity patterns, the authors use a sequential analysis in a lowdimensional space (using local linear embedding). In essence, each trial is decoded by finding the pair of two temporally sequential trials that is closest to this pattern, and then interpolating the power/affiliation values linearly between these two points. The obvious problem with this analysis is that fMRI pattern will have temporal autocorrelation and the power and affiliation values have temporal autocorrelation. Successful decoding could just reflect this smoothness in both time series. The authors present a series of control analyses, but I found most of them to not be incisive or convincing and I believe that they (and their explanation of their rationale) need to be improved. For example, the circular shifting of the patterns preserves some of the autocorrelation of the time series - but not entirely. In the shifted patterns, the first and last items are considered to be neighboring and used in the evaluation, which alone could explain the poor performance. The simplest way that I can see is to also connect the first and last item in a circular fashion, even when evaluating the veridical ordering. The only really convincing control condition I found was the generation of new sequences for every character by shuffling the sequence of choices and re-creating new artificial trajectories with the same start and endpoint. This analysis performs much better than chance (circular shuffling), suggesting to me that a lot of the observed decoding accuracy is indeed simply caused by the temporal smoothness of both time series.
We thank the reviewer for emphasizing this important concern; we agree that we did not sufficiently address this in the initial submission. This concern is one main reason we removed the spline-based analysis and now use regression-based representational similarity analyses in its place. In the revision, we report autocorrelation-related analyses in the supplement, and via controls and additional analysis show that temporal distance (or its square) cannot explain the location-like effects. This substantially improves our ability to interpret the findings.
(5) Overall, I found the analysis of the brain-behavior correlation presented in Figure 5 unconvincing. First, the correlation is mostly driven by one individual with a large network size and a 6.5 cluster. I suspect that the exclusion of this individual would lead to the correlation losing significance. Secondly, the neural measure used for this analysis (determining the number of optimal clusters that maximize the overlap between neural clustering and behavioral clustering) is new, non-validated, and disconnected from all the analyses that had been reported previously. The authors need to forgive me for saying so, but at this point of the paper, would it not be much more obvious to use the decoding accuracy for power and affiliation from the main model used in the paper thus far? Does this correlate? Another obvious candidate would be the decoding accuracy for character identity or the size of the region that encodes affiliation and power. Given the plethora of candidate neural measures, I would appreciate if the authors reported the other neural measures that were tried (and that did not correlate). One way to address this would have been to select the method on the initial sample and then test it on the validation sample - unfortunately, the measure was not pre-registered before the validation sample was collected. It seems that the correlation was only found and reported on the validation sample?
We agree that this analysis was too complicated and under constrained, and thus not convincing. We think that removing this cluster-based analysis is the most conservative response to the reviewer’s concerns and have removed it from the revised paper.
Recommendations to the authors:
Reviewer #1 (Recommendations for the authors):
The manuscript's description of the shuffling analysis performed during decoding is currently ambiguous, particularly concerning the control variables. This ambiguity is present only in the Figure 4 legends and requires a more detailed explanation within the methods section. It is essential to clarify whether the permutation process was conducted within each character's data set or across multiple characters' data sets. If permutations were confined to within-character data, the conclusion would be that the hippocampus encodes context-specific information rather than providing a twodimensional common space.
We thank the reviewer for this comment. We have now removed the spline analysis due to these and other problems and have replaced it with representational similarity analyses that are both more rigorous and easier to interpret. We think these analyses allow us to make the claim that the characters are represented in a common space.
In the methods, we explain the analyses (page 23-24, lines 475-500):
“We also expected the hippocampus to represent the different characters’ changing social locations, which are implicit in the participant’s choices. We used multiple regression searchlight RSA to test whether hippocampal pattern dissimilarity increases with social location distance, based on participant-specific trial-wise beta images where boxcar regressors spanned each trial’s reaction time.”
“We ran two complementary regression analyses to address two related questions. First, we asked whether the hippocampus represents how a specific relationship changes over time. For this analysis, for each participant and each searchlight, we computed character-specific (i.e., only for same character trial pairs) correlation distances between trial-wise beta patterns and Euclidean distances between the social location behavioral coordinates. Distances were zscored within character trial pairs to isolate character-specific changes. The second analysis asked whether the there is a common map-like representation, where all trials, regardless of relationship, are represented in a shared coordinate system. Here, we included all trial pairs and z-scored the distances globally. For both regression analyses, we included control distances to control for possible confounds. To account for generic time-related changes, we controlled for absolute scan-time difference, as this correlated with location distance across participants (see Temporal autocorrelation of hippocampal beta patterns in the supplement). Although the square of this temporal distance did not explain any additional variance in behavioral distances, we ran a robustness analysis including both temporal distance and its square and saw qualitatively the same clusters with similar effect sizes. As such, we report the main analysis only. We included binary dimension difference (0 = trial pairs of different dimension, 1 = trials pairs of the same dimension), to ensure effects could not be explained by dimension-related effects. In the group-level model, we controlled for sample and the average reaction time between affiliation and power decisions.”
In the results, we describe the results and our interpretation (pages 11-12, lines 185208):
“We have shown that the left hippocampus represents the affiliation and power trials differently, consistent with an abstract dimensional representation. Does it also represent the changing social coordinates of each character? To test this, we multiple-regression RSA searchlight to test whether left hippocampus patterns represent the characters’ changing social locations across interactions (see Figure 3). We restricted the distances to those from trial pairs from the same character and standardized the distances within character (see Figure 3BD). We controlled for temporal distance to ensure the effect was not explainable by the time between trials, and for whether the trials shared the same underlying dimension (affiliation or power; see Location similarity searchlight analyses for more details). At the group level, we controlled for sample and the average reaction time difference between affiliation and power trials. Using the same testing logic as the dimensionality similarity analysis, we first tested our hypothesis in the bilateral hippocampus and found widespread effects in both the left (peak voxel MNI x/y/z = -35/-22/-15, cluster extent = 1470 voxels) and right (peak voxel MNI x/y/z = 37/-19/-14, cluster extent = 1953 voxels) hemispheres. The whole-brain searchlight analysis revealed additional clusters in the left putamen (-27/-3/14, cluster extent = 131 voxels) and left posterior cingulate cortex (-10/-28/41, cluster extent = 304 voxels).”
“We then asked a second, complementary question: does the hippocampus represent all interactions, across characters, within a shared map? To test for this map-like structure, we repeated the analysis but now included all trial pairs, z-scoring distances globally rather than within character (Figure 3E-F). The remainder of the procedure followed the same logic as the preceding analysis. The hippocampus analysis revealed an extensive right hippocampal cluster (27/27/-14, cluster extent = 1667 voxels). The whole-brain analysis did not show any significant clusters.”
We also describe the results in the discussion (page 12, lines 220-226):
“Then, we show that the hippocampus tracks the changing social locations (affiliation and power coordinates), above and beyond the effects of dimension or time; the hippocampus seemed to reflect both the changing within-character locations, tracking their locations over time, and locations across characters, as if in a shared map. Thus, these results suggest that the hippocampus does not just encode static character-related representations but rather tracks relationship changes in terms of underlying affiliation and power.”
The manuscript's description of the decoding analysis is unclear regarding the variability of the decoded positions. The authors appear to decode the position of a character along a spline, which raises the question of whether this position correlates with time, since characters are more likely to be located further from the center in later trials. There is a concern that the decoded position may not solely reflect the hippocampal encoding of spatial location, but could also be influenced by an inherent temporal association. Given that a character's position at time t is likely to be similar to its positions at t−1 and t+1, it is crucial that the authors clearly articulate their approach to separating spatial representation from temporal autocorrelation. While this issue may have been addressed in the construction of the test set, the manuscript does not seem to adequately explain how such biases were mitigated in the training set.
We agree that temporal confounding needs to be better accounted for, as our claims depend on space-like signals being separable from time-like ones. We address this in several ways in the revised manuscript.
First, we emphasize that this is a narrative-based task, where temporal structure is relevant. As such, our analyses aim to demonstrate that effects go beyond simple temporal confounds, like trial order or time elapsed.
Despite the temporal structure to the task, the decisions for the same character are spaced in time, and interleaved with other characters’ decisions, reducing the chance that a simple temporal confound could explain trajectory-related effects. We now describe the task better in the revised methods (page 16, lines 314-318):
“All six characters’ decision trials are interleaved with one another and with narrative slides. On average, after a decision trial for a given character, participants view ~11 narrative slides and complete ~3 decisions for other characters before returning to that same character, such that each character’s choices are separated by an average of ~20 seconds (range 12 seconds to 10 min).”
To address temporal autocorrelation in the fMRI time series, we used SPM’s FAST algorithm. Briefly, FAST models temporal autocorrelation as a weighted combination of candidate correlation functions, using the best estimate to remove autocorrelated signal.
We also now report the temporal autocorrelation profile of the hippocampal beta series in the supplement, including (pages 29-31, lines 593-656):
“The Social Navigation Task is a narrative-based task, where the relationships with characters evolve over time; trial pairs that are close in time may have more similar fMRI patterns for reasons unrelated to social mapping (e.g., slow drift). It is important to account for the role of time in our analyses, to ensure effects go beyond simple temporal confounds, like the time between decision trials. To aid in this, we quantified how fMRI signals change over time using a pattern autocorrelation function across decision trial lags. We defined the left and right hippocampus and the left and right intracalcarine cortex using the HarvardOxford atlas and thresholded them at 50% probability. We chose intracalcarine corex as an early visual control region that largely corresponds to primary visual cortex (V1), as it is likely to be driven by the visually presented narrative. We used the same trial-wise beta images as in the location similarity RSA (boxcar regressors spanning each decision trial’s reaction time). For each participant and region-of-interest (ROI), we extracted the decision trial-by-voxel beta matrix and quantified three kinds of temporal dependence: beta autocorrelation, multivoxel pattern correlation and multivoxel pattern correlation after regressing out temporal distance.”
“To estimate the temporal autocorrelation of the trial-wise beta values, we treated each voxel’s beta values as a time series across trials and measured how much a voxel’s response on one trial correlated (Pearson) with its response on previous trials. We averaged these voxel wise autocorrelations within each ROI. At one trial apart (lag 1), both the hippocampus and V1 showed small positive autocorrelations, indicating modest trial-to-trial carryover in response amplitude (see Supplemental figure 1) that by three trials apart was approximately 0.”
“Because our representational similarity analyses depend on trial-by-trial pattern similarity, we also estimated how multivoxel patterns were autocorrelated over time. For each lag, we computed the Pearson correlation between each trial’s voxelwise pattern and the pattern from the trial that many trials earlier, then averaged those correlations to obtain a single autocorrelation value for that lag. At one trial apart, both regions showed positive autocorrelation, with V1 having greater autocorrelation than the hippocampus; pattern correlations between trials 3 or 4 trials apart reduced across participants, settling into low but positive values. Then, for each participant and ROI, we regressed out the effect of absolute trial onset differences from all pairwise pattern correlations, to mirror the effects of controlling for these temporal distances in regressions. After removing this temporal distance component, the short lag pattern autocorrelation dropped substantially in both regions. The similarity in autocorrelation profiles between the two regions suggests that significant similarity effects in the hippocampus are unlikely to be driven by generic temporal autocorrelation.”
“Relationship between behavioral location distance and temporal distance “
“We also quantified how temporal distances between trials relates to their behavioral location distances, participant by participant. Our dimension similarity analysis controls for temporal distance between trials by design (see Social dimension similarity searchlight analysis), but our location similarity analysis does not. To decide on covariates to include in the analysis, we tested whether temporal distances can explain behavioral location distances. For each participant, we computed the correlations between trial pairs’ Euclidean distances in social locations and their linear temporal distances (“linear”) and the temporal distances squared (“quadratic”), to test for nonlinear effects. We then summarized the correlations using one-sample t-tests. The linear relationship was statistically significant (t<sub>49</sub> = 12.24, p < 0.001), whereas the quadratic relationship was not (t<sub>49</sub> = -0.55, p = 0.586). Similarly, in participant specific regressions with both linear and quadratic temporal distances, the linear effect was significant (t<sub>49</sub> = 5.69, p < 0.001) whereas the quadratic effect was not (t<sub>49</sub> = 0.20, p = 0.84). Based on this, we included linear temporal distances as a covariate in our location similarity analyses (see Location similarity searchlight analyses), and verified that adding a quadratic temporal distance covariate does not alter the results. Thus, the reported location-related pattern similarity effects go beyond what can be explained by temporal distance alone.”
How the free parameter of spectral clustering was determined, if there is any?
The interpretation of the number of hippocampal activity clusters is ambiguous. It is suggested that this number could fluctuate due to unique activity patterns or the fit to behaviorally defined trajectories. A lower number of clusters might indicate either a noisier or less distinct representation, raising the question of the necessity and interpretability of such a complex analysis. This concern is compounded by the potential sensitivity of the clustering to the variance in Euclidean distances of each trial's position relative to the center. If a character's position is consistently near the center, this could artificially reduce the perceived number of clusters. Furthermore, the manuscript should address whether there is any correlation between the number of clusters and behavioral performance. Specifically, what are the implications if participants are able to perform the task adequately with a smaller number of distinct hippocampal representation states?
The rationale for conducting both cluster analysis and position decoding as separate analyses remains unclear. While cluster analysis can corroborate the findings of position decoding, it is not apparent why the authors chose to include trials across characters for cluster analysis but not for decoding analysis. An explanation of the reasoning behind this methodological divergence would help in understanding the distinct contributions of each analysis to the study's findings.
The paper by Cohen et al. (1997), which provides the questionnaire for measuring the social network index, is not cited in the references. Upon reviewing the questionnaire that the author may have used, it appears that the term "social network size" does not refer to the actual size but to a score or index derived from the questionnaire responses. It may be more appropriate to replace the term "size" with a different term to more accurately reflect this distinction.
Thank you for seeking these clarifications. Given the complexity of this analysis, we have decided to drop it to focus instead on our dimension and location representational similarity analysis results.
Reviewer #2 (Recommendations for the authors):
How did the participants' decisions on previous trials influence the future trials that the subjects saw? If the different participants were faced with different decision trials, then how did you compare their decision? If two participants made the same decisions, would they have seen exactly the same sequence of trials (see point X on how the trial sequence was randomized).
All participants experience the same narrative, with the same decisions (i.e., the same available options); their choices (i.e., the options they select) are what implicitly shape each character’s affiliation and power locations, and thus each character’s trajectory. In other words, the narrative is fixed; what changes is the social coordinates assigned to each trial’s outcome depending on the participant’s choice of how to interact from the two narrative options. This means that we can meaningfully compare participants' neural patterns, given that every participant received the same text and images throughout.
We have now added details on the narrative structure, replacing more ambiguous statements with a clearer description (page 16, lines 309-318):
“The sequence of trials, including both narrative and decision trials, were fixed across participants; all that differs are the choices that the participants make. Narrative trials varied in duration, depending on the content (range 2-10 seconds), but were identical across participants. Decision trials always lasted 12 seconds, with two options presented until the participant made a choice, after which a blank screen was presented for the remainder of the duration. All six characters’ decision trials are interleaved with one another, and with the narrative slides. On average, after a decision trial for a given character, participants view ~11 narrative slides and complete ~3 decisions for other characters before returning to another decision with the same character, such that each character’s choices are separated by an average of ~20 seconds (ranging from 12 seconds to 10 min).”
Figure 2B: I assume that "count" is "count of participants"? It would be good to indicate this on the axis/caption.
Thank you for noting this. We have now removed this figure to improve the clarity of our figures.
We have shown that the hippocampus represents the interaction decision trials along abstract social dimensions, but does it track each relationship's unique sequence of abstract social coordinates?". Please clarify what you mean by "represents the interaction decision trials”.
By “represents the interaction decision trials along abstract social dimensions”, we mean that when the participant makes a choice during the social interactions the hippocampal patterns represent the current social dimension of the choice (affiliation vs power). In other words, the hippocampal BOLD patterns differentiate affiliation and power decisions, consistent with our hypothesis of abstract social dimension representation in the hippocampus. We have clarified this (page 11, lines 185-187):
“We have shown that the left hippocampus represents the affiliation and power trials differently, consistent with an abstract dimensional representation.”
Page 8: "Hippocampal sequences are ordered like trajectories": It is not entirely clear to me what is meant by the split midpoint. Is this the midpoint of the piece-wise linear interpolation between two points, or simply the mean of all piecewise splines from one character? If the latter, is the null model the same as simply predicting the mean affiliation and power value for this character? If yes, please clarify and simplify this for the reader.
Page 8: "Hippocampal sequences track relationship-specific paths". First, I was misled by the "relationship-specific". I first understood this to mean that you wanted to test whether two relationships (i.e. the identity of the partner) had different representations in Hippocampus, even if the power/affiliation trajectories are the same. I suggest changing the title of this section.
The analysis in this section also breaks any temporal autocorrelation of measured patterns - so I am not sure if this is a strong analysis that should be interpreted at all. This analysis seems to not address the claim and conclusion that is drawn from it. I assume that the random trajectories have different choices and different affiliation/power values than the true trajectories. So the fact that the true trajectories can be better decoded simply shows that either choices or affiliation and power (or both) are represented in the neural code - but not necessarily anything beyond this.
Page 9: "Neural trajectories reflect social locations, not just choices". The motivation of this analysis is not clear to me. As I understand this analysis, both social location and choices are changed from the real trajectories. How can it then show that it reflects social locations, not just the choices?
Figure 4 caption: "on the -based approximation" Is there a missing "point"-[based] here?
We agree with the reviewer that this analysis is hard to interpret and does not adequately address concerns regarding temporal autocorrelation, and as such we have removed it from the manuscript. We describe the new results that include controlling for temporal distance between trials (pages 11-12, lines 185-208):
“We have shown that the left hippocampus represents the affiliation and power trials differently, consistent with an abstract dimensional representation. Does it also represent the changing social coordinates of each character? To test this, we multiple-regression RSA searchlight to test whether left hippocampus patterns represent the characters’ changing social locations across interactions (see Figure 3). We restricted the distances to those from trial pairs from the same character and standardized the distances within character (see Figure 3BD). We controlled for temporal distance to ensure the effect was not explainable by the time between trials, and for whether the trials shared the same underlying dimension (affiliation or power; see Location similarity searchlight analyses for more details). At the group level, we controlled for sample and the average reaction time difference between affiliation and power trials. Using the same testing logic as the dimensionality similarity analysis, we first tested our hypothesis in the bilateral hippocampus and found widespread effects in both the left (peak voxel MNI x/y/z = -35/-22/-15, cluster extent = 1470 voxels) and right (peak voxel MNI x/y/z = 37/-19/-14, cluster extent = 1953 voxels) hemispheres. The whole-brain searchlight analysis revealed additional clusters in the left putamen (-27/-3/14, cluster extent = 131 voxels) and left posterior cingulate cortex (-10/-28/41, cluster extent = 304 voxels).”
“We then asked a second, complementary question: does the hippocampus represent all interactions, across characters, within a shared map? To test for this map-like structure, we repeated the analysis but now included all trial pairs, z-scoring distances globally rather than within character (Figure 3E-F). The remainder of the procedure followed the same logic as the preceding analysis. The hippocampus analysis revealed an extensive right hippocampal cluster (27/27/-14, cluster extent = 1667 voxels). The whole-brain analysis did not show any significant clusters.”
We emphasize that the results are robust to the inclusion of temporal distance squared, in the methods (pages 23-24, lines 493-496):
“Although the square of this temporal distance did not explain any additional variance in behavioral distances, we ran a robustness analysis including both temporal distance and its square and saw qualitatively the same clusters with similar effect sizes.”
Page 8: last paragraph: The text sounds like you have already shown that you can decode character identity from the patterns - but I do not believe you have it this point. I would consider this would be an interesting addition to the paper, though.
This section has been removed, and we have been careful to not imply this in the current version of the manuscript. While we agree a character identity decoding would enrich our argument, we do not believe our task is well-suited to capture a character identity effect. Each character only has 12 decision trials, and these trials are partially clustered in time - this is one problem of temporal autocorrelation that we thank the reviewers for pushing us to consider in more detail. Dimension and location patterns, on the other hand, are more natural to analyze in our task, especially in representational similarity analyses that test whether the relevant differences scale with neural distances.
Page 14ff: Why is "Analysis section" not part of "Materials and Methods"? I believe adding the analysis after a careful description of the methods would improve the clarity of this section.
We agree with the reviewer and have now consolidated these two sections.
Two or three examples of Affiliation and Power decision trials should be provided, so the reader can form a more thorough understanding of how these dimensions were operationalized. For the RSA analysis, it is important to consider other differences between these two types of trials.
We agree that adding examples will clarify the operationalization of these dimensions. We now include example affiliation and power trials in a table (page 17-18).
We thank the reviewer for noting the need to rule out alternative hypotheses; we have added several such tests. Affiliation and power trials were not different in word count (page 17, lines 329-332):
“To ensure that any observed neural or behavioral differences were not confounded by trivial features of the text, we tested for differences between the affiliation and power trials (where the two options are concatenated). There were no differences in word count (affiliation average = 26.6, power average = 25.6; t-test p = 0.56).”
They were also not different in their sentiment, as assessed by a Large Language Model (LLM) analysis (page 17, lines 332-335):
“The text’s sentiment also did not differ between these trial types (t-test p = 0.72), as quantified by comparing sentiment compound scores (from most negative, −1, to most positive, +1), using a Large Language Model (LLM) specialized for sentiment analysis [26]. “
The affiliation and power trials were different in terms of semantic content, consistent with our assumptions (page 17, lines 337-347):
“Our framework assumes that affiliation and power trials differ in their semantic content–that is, in the conceptual meaning of the text, beyond word count or sentiment. To test this assumption, we used an LLM-based semantic embedding analysis. Each decision trial was embedded into a semantic vector. We then measured the cosine similarity between pairs of trials and calculated the difference between average within-dimension similarity (affiliation-affiliation and power-power comparisons) and average between-dimension similarity (affiliationpower comparisons) and assessed its statistical significance with permutation testing (1,000 shuffles of trial labels). As expected, decision trials of the same dimension were more similar to each other than trials of different dimension, across multiple LLMs (OpenAI’s text-embedding-3-small [27]: similarity difference = 0.041, p < 0.001; all-MiniLM-L12-v2 [28]: similarity difference = 0.032, p < 0.001).”
The affiliation and power trials were different in average reaction time. To control for this difference in the dimension RSA analysis, we added each participant’s absolute value reaction time difference between the trial types as a covariate. The results were nearly identical to what they were before. We updated the text to reflect this new control (page 23, lines 471-474):
“However, there was a significant difference in the average reaction time between affiliation and power decisions across participants (t<sub>49</sub> = 6.92, p < 0.001; affiliation mean = 4.92 seconds (s), power mean = 4.51 s), so we controlled for this in the group-level analysis.”
The exact implementation and timing of the behavioral tasks should be described better. How many narrative trials were intermixed with the decision trials? Which characters were they assigned to? How was the sequence of trials determined? Was it fixed across participants, or randomized?
We agree that additional details are helpful. In the Methods, we now describe this with more detail (page 16, lines 301-318):
“There are two types of trials: “narrative” trials where background information is provided or characters talk or take actions (a total of 154 trials), and “decision” trials where the participant makes decisions in one-on-one interactions with a character that can change the relationship with that character (a total of 63 trials). On each decision, participants used a button response box to select between the two options. The options (1 or 2, assigned to the index and middle fingers) choice directions (+/-1 arbitrary unit on the current dimension) were counterbalanced.”
“The sequence of trials, including both narrative and decision trials, were fixed across participants; all that differs are the choices that the participants make. Narrative trials varied in duration, depending on the content (range 2-10 seconds), but were identical across participants. Decision trials always lasted 12 seconds, with two options presented until the participant made a choice, after which a blank screen was presented for the remainder of the duration. All six characters’ decision trials are interleaved with one another, and with the narrative slides. On average, after a decision trial for a given character, participants view ~11 narrative slides and complete ~3 decisions for other characters before returning to another decision with the same character, such that each character’s choices are separated by an average of ~20 seconds (ranging from 12 seconds to 10 min).”
What is the exact timing of trials during fMRI acquisition - i.e. how long were the trials, what was the ITI, were there long phases of rest to determine the resting baseline? These are all important factors that will determine the covariance between regressors and should be reported carefully. Ideally, I would like to see the trial-by-trial temporal auto-correlation structure across beta-weights to be reported.
We thank the reviewer for asking for this clarification. We have added the following text to clarify the trial timing (page 16, lines 314-318):
“All six characters’ decision trials are interleaved with one another and with narrative slides. On average, after a decision trial for a given character, participants view ~11 narrative slides and complete ~3 decisions for other characters before returning to that same character, such that each character’s choices are separated by an average of ~20 seconds (range 12 seconds to 10 min).”
We now describe the temporal autocorrelation patterns in the supplement, including how we decided on how to control for temporal distance in representational similarity analyses (pages 29-31, lines 593-656):
“The Social Navigation Task is a narrative-based task, where the relationships with characters evolve over time; trial pairs that are close in time may have more similar fMRI patterns for reasons unrelated to social mapping (e.g., slow drift). It is important to account for the role of time in our analyses, to ensure effects go beyond simple temporal confounds, like the time between decision trials. To aid in this, we quantified how fMRI signals change over time using a pattern autocorrelation function across decision trial lags. We defined the left and right hippocampus and the left and right intracalcarine cortex using the HarvardOxford atlas and thresholded them at 50% probability. We chose intracalcarine corex as an early visual control region that largely corresponds to primary visual cortex (V1), as it is likely to be driven by the visually presented narrative. We used the same trial-wise beta images as in the location similarity RSA (boxcar regressors spanning each decision trial’s reaction time). For each participant and region-of-interest (ROI), we extracted the decision trial-by-voxel beta matrix and quantified three kinds of temporal dependence: beta autocorrelation, multivoxel pattern correlation and multivoxel pattern correlation after regressing out temporal distance.”
“To estimate the temporal autocorrelation of the trial-wise beta values, we treated each voxel’s beta values as a time series across trials and measured how much a voxel’s response on one trial correlated (Pearson) with its response on previous trials. We averaged these voxel wise autocorrelations within each ROI. At one trial apart (lag 1), both the hippocampus and V1 showed small positive autocorrelations, indicating modest trial-to-trial carryover in response amplitude (see Supplemental figure 1) that by three trials apart was approximately 0.”
“Because our representational similarity analyses depend on trial-by-trial pattern similarity, we also estimated how multivoxel patterns were autocorrelated over time. For each lag, we computed the Pearson correlation between each trial’s voxelwise pattern and the pattern from the trial that many trials earlier, then averaged those correlations to obtain a single autocorrelation value for that lag. At one trial apart, both regions showed positive autocorrelation, with V1 having greater autocorrelation than the hippocampus; pattern correlations between trials 3 or 4 trials apart reduced across participants, settling into low but positive values. Then, for each participant and ROI, we regressed out the effect of absolute trial onset differences from all pairwise pattern correlations, to mirror the effects of controlling for these temporal distances in regressions. After removing this temporal distance component, the short lag pattern autocorrelation dropped substantially in both regions. The similarity in autocorrelation profiles between the two regions suggests that significant similarity effects in the hippocampus are unlikely to be driven by generic temporal autocorrelation.”
“Relationship between behavioral location distance and temporal distance “
“We also quantified how temporal distances between trials relates to their behavioral location distances, participant by participant. Our dimension similarity analysis controls for temporal distance between trials by design (see Social dimension similarity searchlight analysis), but our location similarity analysis does not. To decide on covariates to include in the analysis, we tested whether temporal distances can explain behavioral location distances. For each participant, we computed the correlations between trial pairs’ Euclidean distances in social locations and their linear temporal distances (“linear”) and the temporal distances squared (“quadratic”), to test for nonlinear effects. We then summarized the correlations using one-sample t-tests. The linear relationship was statistically significant (t<sub>49</sub> = 12.24, p < 0.001), whereas the quadratic relationship was not (t<sub>49</sub> = -0.55, p = 0.586). Similarly, in participant specific regressions with both linear and quadratic temporal distances, the linear effect was significant (t<sub>49</sub> = 5.69, p < 0.001) whereas the quadratic effect was not (t<sub>49</sub> = 0.20, p = 0.84). Based on this, we included linear temporal distances as a covariate in our location similarity analyses (see Location similarity searchlight analyses), and verified that adding a quadratic temporal distance covariate does not alter the results. Thus, the reported location-related pattern similarity effects go beyond what can be explained by temporal distance alone.”
Peut-être un lien avec la fin de période CEE ?
autre possibilité : les études de marché mentionne que les PAC sont liées au cycle de construction immo. -> s'il y a un effet où certains équipements sont difficile à installer dans des logements anciens (ou inversement) = effet hétérogène de MP/de la crise immo 2022-
Briefing : Feuille de Route de l'Éducation Nationale pour les Droits et le Bien-être des Enfants
Ce document synthétise les axes stratégiques et les constats chiffrés présentés par Édouard Geffray, ministre de l'Éducation nationale, lors de son audition devant la délégation aux droits des enfants.
L'école y est définie par deux fonctions cardinales : instruire et protéger. Les priorités ministérielles s'articulent autour de trois piliers majeurs : la santé mentale des élèves, la lutte contre le harcèlement scolaire et la sécurisation des parcours pour les enfants les plus vulnérables (situation de handicap ou sous protection).
Le ministre souligne une situation alarmante de la santé mentale des jeunes, exacerbée par les usages numériques, et propose des mesures systémiques : déploiement du programme "Phare", interdiction du portable au lycée, et création d'un cadre de "scolarité protégée".
Malgré une baisse démographique drastique (un million d'élèves en moins d'ici 2029), le ministère affirme vouloir maintenir une trajectoire de recrutement pour les personnels médico-sociaux afin de répondre à l'explosion des besoins de détection et d'orientation.
--------------------------------------------------------------------------------
Le ministre place la santé mentale parmi ses trois priorités absolues, s'appuyant sur des indicateurs de détresse psychologique en forte hausse.
• Risques de dépression : 14 % des collégiens et 15 % des lycéens présentent un risque important.
• Idées suicidaires : 24 % des lycéens déclarent avoir eu des pensées suicidaires au cours des 12 derniers mois.
• Harcèlement : Environ 5 % des élèves (soit un élève par classe en moyenne) sont victimes de harcèlement chaque année.
• Urgences : Augmentation de 80 % des passages aux urgences pour intentions ou tentatives de suicide depuis la crise du COVID-19.
• Désanonymisation des questionnaires : Le questionnaire annuel de harcèlement (rempli du CE2 à la Terminale) permet désormais aux élèves de décliner leur identité en fin de document pour être recontactés par l'équipe enseignante.
• Formation des personnels : L'objectif est de former deux personnels "sentinelles" par établissement pour repérer et orienter les élèves. Actuellement, la moyenne est de 1,6 personnel formé.
• Dispositif "Coupe-file" : Un mécanisme est en cours de finalisation avec le ministère de la Santé pour garantir aux infirmiers et médecins scolaires une prise de rendez-vous rapide vers les Centres Médico-Psychologiques (CMP) ou la médecine de ville, évitant des délais d'attente de 3 à 6 mois.
• Arsenal répressif : La loi du 2 mars 2022 fait du harcèlement un délit. 10 000 affaires ont été enregistrées par les parquets depuis 2022. Le décret du 16 août 2023 permet désormais de changer d'école l'élève auteur de harcèlement ou de violences intentionnelles.
--------------------------------------------------------------------------------
L'école s'affirme comme le premier émetteur d'informations préoccupantes (IP) et d'articles 40 en France.
• Signalements : Le nombre d'informations préoccupantes émises par l'école est passé de 50 000 à 80 000 en deux ans. Un guide national de standardisation des alertes est en cours de publication.
• Circulaire "Scolarité Protégée" : Publiée prochainement, elle vise à garantir la continuité pédagogique des enfants confiés à l'Aide Sociale à l'Enfance (ASE), dont 70 % sortent actuellement du système sans diplôme. Elle prévoit :
◦ Un suivi individuel par les services départementaux (DASEN).
◦ Des appuis scolaires spécifiques pour éviter les ruptures liées aux changements de foyers ou de familles d'accueil.
◦ Un soutien renforcé à l'orientation et à l'estime de soi.
--------------------------------------------------------------------------------
Le ministre distingue les élèves "non accompagnés" (disposant d'une solution pédagogique mais attendant une aide humaine) des élèves "sans solution" (exclus du système faute de structure adaptée).
• De la compensation à l'accessibilité : Le ministère souhaite sortir d'un modèle basé uniquement sur l'aide humaine systématique (AESH) pour privilégier l'accessibilité pédagogique et matérielle. L'objectif est d'éviter "l'externalisation" du handicap à l'intérieur de la classe.
• Pôles d'Appui à la Scolarité (PAS) : Déployés pour favoriser l'intervention du médico-social directement dans les murs de l'école et fluidifier les parcours entre le milieu ordinaire et les structures spécialisées.
• Besoins : 42 000 élèves seraient encore en attente d'accompagnement après les vacances de la Toussaint, malgré la création de 1 200 postes d'AESH supplémentaires pour 2026.
--------------------------------------------------------------------------------
Le ministre défend une interdiction stricte du portable au lycée (prévue pour 2026), justifiée par des enjeux cognitifs et de santé publique :
• Corrélation scientifique : La dégradation psychique des élèves est proportionnelle à la consommation d'écrans (le risque de troubles anxio-dépressifs passe de 30 % à 60 % pour les gros utilisateurs).
• Conscience avant contenu : Le ministre souhaite rétablir une primauté de l'éducation aux risques numériques avant l'exposition massive aux contenus violents ou faux.
Éducation à la vie affective, relationnelle et sexuelle (EVARS)
• Obligation : Les trois séances annuelles sont présentées comme "non négociables", tant dans le public que dans le privé sous contrat.
• Constats : 15 % des filles et 12 % des garçons au collège déclarent avoir subi une forme de violence sexuelle.
• Déploiement : Au 31 décembre, 66 % des écoles et 48 % des collèges publics avaient réalisé au moins une séance.
• Formation des enseignants : Le ministère reconnaît la nécessité de protéger les personnels qui, étant parfois eux-mêmes d'anciennes victimes, pourraient subir des traumatismes en dispensant ces enseignements.
--------------------------------------------------------------------------------
Le système éducatif fait face à une chute démographique sans précédent :
• Données : Perte d'un million d'élèves entre 2019 et 2029 dans le premier degré. Une génération de 200 000 élèves "disparaît" tous les quatre ans.
• Ajustements : Le ministre justifie les suppressions de postes d'enseignants (4 000 prévus) par cette baisse, tout en souhaitant augmenter progressivement les effectifs médico-sociaux (300 à 500 postes par an) pour compenser l'explosion des besoins en santé mentale.
Le ministre admet que la carte actuelle, figée depuis 2015, est obsolète. Cependant, il refuse une révision avant 2027 pour deux raisons :
1. Technique : Le processus de concertation avec les collectivités et les syndicats nécessite 15 à 18 mois.
2. Démocratique : Il considère que ce débat doit appartenir à la prochaine échéance présidentielle et refuse de "figer" une carte qui s'imposerait au futur gouvernement.
Un adjoint à la médiatrice de l'Éducation nationale sera spécifiquement chargé de la protection de l'enfance. Sa mission sera de traiter les litiges entre scolaire et périscolaire pour assurer une sécurité "de la porte à la porte" et de produire un rapport annuel dédié à ces enjeux.
--------------------------------------------------------------------------------
| Indicateur | Donnée Statistique | | --- | --- | | Élèves victimes de harcèlement | 5 % (stable du CE2 à la Terminale) | | Lycéens avec idées suicidaires | 24 % | | Passage aux urgences (suicide) | \+ 80 % depuis le Covid | | Information préoccupantes (École) | 80 000 / an (en hausse de 30 000) | | Sortie de l'ASE sans diplôme | 70 % | | Couverture EVARS (Écoles) | 66 % (au 31/12) | | Élèves en attente d'AESH | 42 000 (Toussaint 2025) |
eLife Assessment
This study presents a potentially valuable exploration of the role of thalamic nuclei in language processing. The results will be of interest to researchers interested in the neurobiology of language. However, the evidence is incomplete to support robust conclusions at this point.
Reviewer #1 (Public review):
Summary:
The manuscript by Mengxing et al., reports an assessment of three first-order thalamic nuclei (auditory, visual, somatosensory) in a 3 x 2 factorial design to test for specificity of responses in first-order thalamic nuclei to linguistic processing particularly in the left hemisphere. The conditions are reading, speech production, and speech comprehension and their respective control conditions. The authors report the following results:
(1) BOLD-response analyses: left MGB linguistic vs non-linguistic significant; left LGN linguistic vs non-linguistic significant. There is no hemisphere x stimulus interaction.
(2) MVPA: left MGB linguistic vs. non-linguistic significant; bilateral VLN linguistic vs. non-linguistic significant; significant lateralisation in MGB (left MGB responses better classified linguistic vs. non-linguistic in contrast to right).
(3) Functional connectivity: there is, in general, connectivity between the thalamic ROIs and the respective primary cortices independent of linguistics.
Strengths:
The study has a clear and comprehensive design and addresses a timely topic. First-order thalamic nuclei and their interaction with the respective cerebral cortex area are likely key to understanding how perception works in a world where one has to compute highly dynamic stimuli often in an instant. Speech is a prime example of an ecologically important, extremely dynamic, and complex stimulus. The field of the contribution of cerebral cortex-thalamic loops is wide open, and the study presents a solid approach to address their role in different speech modalities (i.e., reading, comprehension, production).
Weaknesses:
I see two major overall weaknesses in the manuscript in its current form:
(1) Statistics:
Unfortunately, I have doubts about the solidity of the statistics. In the analyses of the BOLD responses, the authors do not find significant hemisphere x stimulus interactions. In my view, such results would pre-empt doing a post-hoc t-test. Nevertheless, the authors motivate their post-hoc t-test by 'trends' in the interaction and prior hypotheses. I see two difficulties with that. First, the origin of the prior hypotheses is somewhat unclear (see also the comment below on hypotheses), and the post-hoc t-test is not corrected for multiple comparisons. I find that it is a pity that the authors did not derive more specific hypotheses grounded in the literature to guide the statistical testing, as I think these would have been available, and the response properties of the MGB and LGN also make sense in light of them. In addition, I was wondering whether the MVPA results would also need to be corrected for the three tests, i.e., the three ROIs.
Hypotheses:
In my view, it is relatively unclear where the hypotheses precisely come from. For example, the paragraph on the hypotheses in the introduction (p. 6-7) is devoid of references. I also have the impression that the hypotheses are partly not taking into account previous reports on first-order thalamic nuclei involvement in linguistic vs. non-linguistic processing. For example, the authors test for lateralisation of linguistic vs. non-linguistic responses in all nuclei. However, from previous literature, one could derive the hypothesis that the lateralisation in MGB for speech might be there - previous work shows, for example, that speech recognition abilities consistently correlate with left MGB only (von Kriegstein et al., 2008 Curr Biol; Mihai et al., 2019 eLife). In addition, the involvement of the MGB in speech in noise processing is present in the left MGB (Mihai et al., 2021, J Neuroscience). Developmental dyslexia, which is supposed to be based on imprecise phonological processing (Ramus et al., 2004 TiCS), has alterations in left MGB (Diaz et al., 2012 PNAS; Galaburda et al., 1994 PNAS) and left MGB connections to planum temporale (Tschentscher et al., 2019 J Neurosci) as well as altered lateralisation (Müller-Axt et al., 2025 Brain). Conversely, in the LGN, I'm not aware of any studies showing lateralisation for speech. See, for example, Diaz et al., 2018, Neuroimage, where there are correlations of LGN task-dependent modulation with visual speech recognition behaviour in both LGNs. Thus, based on this literature, one could have predicted the result pattern displayed, for example, in Figure 3A at least for MGB and LGN.
In summary, the motivation for the different hypotheses needs to be carved out more and couched into previous literature that is directly relevant to the topic. The above paragraph is, of course, my view on the topic, but currently, the paper lacks different literature as references to fully understand where the hypotheses are derived from.
Reviewer #2 (Public review):
Summary:
This study investigates the involvement of first-order thalamic nuclei in language-related tasks using task-based fMRI in a 3 × 2 design contrasting linguistic and non-linguistic versions of reading, speech comprehension, and speech production. By focusing on the LGN, MGN, and VLN and combining activation, connectivity, lateralization, and multivariate pattern analyses, the authors aim to characterize modality-specific and language-related thalamic contributions.
Strength:
A major strength of the work is its hypothesis-driven and multimodal analytical approach, and the modality-specific engagement of first-order thalamic nuclei is robust and consistent with known thalamocortical organization. This is a very sound study overall.
Weaknesses:
However, several conceptual issues complicate the interpretation of the results as evidence for linguistic modulation per se. A central concern relates to the operationalization of the linguistic versus non-linguistic contrast. In the present design, linguistic and non-linguistic stimuli differ along multiple dimensions beyond linguistic content. For example, written words and scrambled images differ in spatial frequency structure, edge composition, contrast regularities, and familiarity, while intelligible speech and acoustically scrambled sounds differ substantially in temporal and spectral statistics. This is particularly relevant given that first-order thalamic nuclei such as the LGN are known to be highly sensitive to low-level sensory properties. As a result, observed differences in thalamic responses may reflect sensitivity to stimulus properties rather than linguistic processing per se, and this limits the specificity of claims regarding linguistic modulation.
Relatedly, although the manuscript frequently refers to effects "depending on the linguistic nature of the stimuli," the statistical evidence for linguistic versus non-linguistic modulation is uneven across analyses. Whole-brain contrasts collapse across stimulus type and primarily test modality effects. Similarly, the primary ROI analyses of activation amplitude are collapsed across linguistic and non-linguistic conditions and convincingly demonstrate modality-specific engagement of thalamic nuclei, but do not in themselves provide evidence for linguistic modulation. Linguistic effects emerge only in later, more targeted analyses focusing on hemispheric lateralization and multivariate pattern classification, and these effects are nucleus-, modality-, and analysis-specific rather than general. Taken together, these results suggest that linguistic modulation constitutes a secondary and selective finding, whereas modality-specific task engagement represents the primary and most robust outcome of the study.
An additional interpretational issue concerns task engagement and attention. The tasks differ substantially in cognitive demands (e.g., passive reading and listening versus overt speech production), and linguistic and non-linguistic blocks may differ systematically in salience or engagement. This is particularly important given prior evidence, cited by the authors, that LGN and MGN activity can be modulated by task demands and attention. In the absence of behavioral measures indexing task engagement or compliance, it is difficult to determine whether differences between linguistic and non-linguistic conditions reflect linguistic processing per se or are mediated by attentional factors.
Finally, while the manuscript emphasizes the novelty of evaluating thalamic involvement in language, thalamic contributions to language have been documented previously in both lesion and functional imaging studies. The contribution of the present work, therefore, lies less in establishing thalamic involvement in language per se, and more in its focus on specific first-order nuclei, its multimodal design, and its combination of univariate, connectivity, and multivariate analyses. Moderating claims of novelty would help place the findings more clearly within the existing literature.
Author response:
We acknowledge the concerns raised by both reviewers and plan to address them in our revision:
Regarding Reviewer #1's comments: We will strengthen the statistical framework and address the concerns about multiple comparison corrections. We will also expand our literature review to better motivate our hypotheses, particularly incorporating the work on lateralization patterns in MGN/LGN and the existing evidence on first-order thalamic nuclei in linguistic processing.
Regarding Reviewer #2's comments: We acknowledge the valid concern that linguistic and non-linguistic stimuli differ beyond linguistic content, including some low-level sensory properties. We will elaborate on the creation and properties of these stimuli in the Methods section and upload stimuli examples to an online repository to provide transparency about differences. We will also add a discussion of this limitation in the Discussion section, acknowledging that disentangling effects of linguistic processing from low-level stimulus properties will require further testing in future research. Additionally, we will moderate part of our claims and reorganize the presentation of results as suggested, and clarify our contribution relative to existing literature.
Preferimos pocos principios de funcionamiento y componentes que se interconectan formas poderosas y que funcionan en una amplia varidad de máquinas, desde memorias USB, hasta computadoras modestas o servidores potentes
En mi caso personal lo que importa es la versatilidad y la eficiencia que se logra con una base bien diseñada.
eLife Assessment
This manuscript reports high-resolution cryo-EM structures of a trimethylamine N-oxide demethylase and advances the intriguing hypothesis that the enzyme is bifunctional, coupling TMAO demethylation to formaldehyde capture at a distal tetrahydrofolate-binding site via an enclosed intramolecular tunnel. Supported by biochemical assays and molecular dynamics simulations, the structural findings are valuable and potentially of broad interest, particularly the unusual oligomeric architecture and the proposed conduit for a reactive intermediate. However, the mechanistic framework is considered incomplete, raising substantial concerns regarding the proposed catalytic mechanism, metal/cofactor requirements, and the interpretation of biochemical data supporting formaldehyde channelling.
Reviewer #1 (Public review):
Summary:
Thach et al. report on the structure and function of trimethylamine N-oxide demethylase (TDM). They identify a novel complex assembly composed of multiple TDM monomers and obtain high-resolution structural information for the catalytic site, including an analysis of its metal composition, which leads them to propose a mechanism for the catalytic reaction.
In addition, the authors describe a novel substrate channel within the TDM complex that connects the N-terminal Zn²-dependent TMAO demethylation domain with the C-terminal tetrahydrofolate (THF)-binding domain. This continuous intramolecular tunnel appears highly optimized for shuttling formaldehyde (HCHO), based on its negative electrostatic properties and restricted width. The authors propose that this channel facilitates the safe transfer of HCHO, enabling its efficient conversion to methylenetetrahydrofolate (MTHF) at the C-terminal domain as a microbial detoxification strategy.
Strengths:
The authors provide convincing high-resolution cryo-EM structural evidence (up to 2 Å) revealing an intriguing complex composed of two full monomers and two half-domains. They further present evidence for the metal ion bound at the active site and articulate a plausible hypothesis for the catalytic cycle. Substantial effort is devoted to optimizing and characterizing enzyme activity, including detailed kinetic analyses across a range of pH values, temperatures, and substrate concentrations. Furthermore, the authors validate their structural insights through functional analysis of active-site point mutants.
In addition, the authors identify a continuous channel for formaldehyde (HCHO) passage within the structure and support this interpretation through molecular dynamics simulations. These analyses suggest an exciting mechanism of specific, dynamic, and gated channeling of HCHO. This finding is particularly appealing, as it implies the existence of a unique, completely enclosed conduit that may be of broad interest, including potential applications in bioengineering.
Weaknesses:
Although the idea of an enclosed channel for HCHO is compelling, the experimental evidence supporting enzymatic assistance in the reaction of HCHO with THF is less convincing. The linear regression analysis shown in Figure 1C demonstrates a THF concentration-dependent decrease in HCHO, but the concentrations used for THF greatly exceed its reported KD (enzyme concentration used in this assay is not reported). It has previously been shown that HCHO and THF can couple spontaneously in a non-enzymatic manner, raising the possibility that the observed effect does not require enzymatic channeling. An additional control that can rule out this possibility would help to strengthen the evidence. For example, mutating the THF binding site to prevent THF binding to the protein complex could clarify whether the observed decrease in HCHO depends on enzyme-mediated proximity effects. A mutation which would specifically disable channeling could be even more convincing (maybe at the narrowest bottleneck).
Another concern is that the observed decrease in HCHO could alternatively arise from a reduced production of HCHO due to a negative allosteric effect of THF binding on the active site. From this perspective, the interpretation would be more convincing if a clear coupled effect could be demonstrated, specifically, that removal of the product (HCHO) from the reaction equilibrium leads to an increase in the catalytic efficiency of the demethylation reaction.
While the enzyme kinetics appear to have been performed thoroughly, the description of the kinetic assays in the Methods section is very brief. Important details such as reaction buffer composition, cofactor identity and concentration (Zn²⁺), enzyme concentration, defined temperature, and precise pH are not clearly stated. Moreover, a detailed methodological description could not be found in the cited reference (6), if I am not mistaken.
The composition of the complex is intriguing but raises some questions. Based on SDS-PAGE analysis, the purified protein appears to be predominantly full-length TDM, and size-exclusion chromatography suggests an apparent molecular weight below 100 kDa. However, the cryo-EM structure reveals a substantially larger complex composed of two full-length monomers and two half-domains.
Given the lack of clear evidence for proteolytic fragments on the SDS-PAGE gel, it is unclear how the observed stoichiometry arises. This raises the possibility of higher-order assemblies or alternative oligomeric states. Did the authors attempt to pick or analyze larger particles during cryo-EM processing? Additional biophysical characterization of particle size distribution - for example, using interferometric scattering microscopy (iSCAT)-could help clarify the oligomeric state of the complex in solution.
The authors mention strict symmetry in the complex, yet C2 symmetry was enforced during refinement. While this is reasonable as an initial approach, it would strengthen the structural interpretation to relax the symmetry to C1 using the C2-refined map as a reference. This could reveal subtle asymmetries or domain-specific differences without sacrificing the overall quality of the reconstruction.
In this context, the proposed catalytic role of Zn²⁺ raises additional questions. Why is a 2:1 enzyme-to-metal stoichiometry observed, and how does this reconcile with previous reports? This point warrants discussion. Does this imply asymmetric catalysis within the complex? Would the stoichiometry change under Zn²⁺-saturating conditions, as no Zn²⁺ appears to be added to the buffers? It would be helpful to clarify whether Zn²⁺ occupancy is equivalent in both active sites when symmetry is not imposed, or whether partial occupancy is observed.
The divalent ion Zn2+ is suggested to activate water for the catalytic reaction. I am not sure if there is a need for a water molecule to explain this catalytic mechanism. Can you please elaborate on this more? As one aspect, it might be helpful to explain in more detail how Zn-OH and D220 are recovered in the last step before a new water molecule comes in.
Overall, the authors were successful in advancing our structural and functional understanding of the TDM complex. They suggest an interesting oligomeric complex composition which should be investigated with additional biophysical techniques.
Additionally, they provide an intriguing hypothesis for a new type of substrate channeling. Additional kinetic experiments focusing on HCHO and THF turnover by enzymatic proximity effects would strengthen this potentially fundamental finding. If this channeling mechanism can be supported by stronger experimental evidence, it would substantially advance our understanding and knowledge of biologic conduits and enable future efforts in the design of artificial cascade catalysis systems with high conversion rate and efficiency, as well as detoxification pathways.
Reviewer #2 (Public review):
Summary:
The manuscript reports a cryo-EM structure of TMAO demethylase from Paracoccus sp. This is an important enzyme in the metabolism of trimethylamine oxide (TMAO) and trimethylamine (TMA) in human gut microbiota, so new information about this enzyme would certainly be of interest.
Strengths:
The cryo-EM structure for this enzyme is new and provides new insights into the function of the different protein domains, and a channel for formaldehyde between the two domains.
Weaknesses:
(1) The proposed catalytic mechanism in this manuscript does not make sense. Previous mechanistic studies on the Methylocella silvestris TMAO demethylase (FEBS Journal 2016, 283, 3979-3993, reference 7) reported that, as well as a Zn2+ cofactor, there was a dependence upon non-heme Fe2+, and proposed a catalytic mechanism involving deoxygenation to form TMA and an iron(IV)-oxo species, followed by oxidative demethylation to form DMA and formaldehyde.
In this work, the authors do not mention the previously proposed mechanism, but instead say that elemental analysis "excluded iron". This is alarming, since the previous work has a key role for non-heme iron in the mechanism. The elemental analysis here gives a Zn content of about 0.5 mol/mol protein (and no Fe), whereas the Methylocella TMAO demethylase was reported to contain 0.97 mol Zn/mol protein, and 0.35-0.38 mol Fe/mol protein. It does, therefore, appear that their enzyme is depleted in Zn, and the absence of Fe impacts the mechanism, as explained below.
The proposed catalytic mechanism in this manuscript, I am sorry to say, does not make sense to me, for several reasons:
(i) Demethylation to form formaldehyde is not a hydrolytic process; it is an oxidative process (normally accomplished by either cytochrome P450 or non-heme iron-dependent oxygenase). The authors propose that a zinc (II) hydroxide attacks the methyl group, which is unprecedented, and even if it were possible, would generate methanol, not formaldehyde.
(ii) The amine oxide is then proposed to deoxygenate, with hydroxide appearing on the Zn - unfortunately, amine oxide deoxygenation is a reductive process, for which a reducing agent is needed, and Zn2+ is not a redox-active metal ion;
(iii) The authors say "forming a tetrahedral intermediate, as described for metalloproteinase", but zinc metalloproteases attack an amide carbonyl to form an oxyanion intermediate, whereas in this mechanism, there is no carbonyl to attack, so this statement is just wrong.
So on several counts, the proposed mechanism cannot be correct. Some redox cofactor is needed in order to carry out amine oxide deoxygenation, and Zn2+ cannot fulfil that role. Fe2+ could do, which is why the previously proposed mechanism involving an iron(IV)-oxo intermediate is feasible. But the authors claim that their enzyme has no Fe. If so, then there must be some other redox cofactor present. Therefore, the authors need to re-analyse their enzyme carefully and look either for Fe or for some other redox-active metal ion, and then provide convincing experimental evidence for a feasible catalytic mechanism. As it stands, the proposed catalytic mechanism is unacceptable.
(2) Given the metal content reported here, it is important to be able to compare the specific activity of the enzyme reported here with earlier preparations. The authors do quote a Vmax of 16.52 µM/min/mg; however, these are incorrect units for Vmax, they should be µmol/min/mg. There is a further inconsistency between the text saying µM/min/mg and the Figure saying µM/min/µg.
(3) The consumption of formaldehyde to form methylene-THF is potentially interesting, but the authors say "HCHO levels decreased in the presence of THF", which could potentially be due to enzyme inhibition by THF. Is there evidence that this is a time-dependent and protein-dependent reaction? Also in Figure 1C, HCHO reduction (%) is not very helpful, because we don't know what concentration of formaldehyde is formed under these conditions; it would be better to quote in units of concentration, rather than %.
(4) Has this particular TMAO demethylase been reported before? It's not clear which Paracoccus strain the enzyme is from; the Experimental Section just says "Paracoccus sp.", which is not very precise. There has been published work on the Paracoccus PS1 enzyme; is that the strain used? Details about the strain are needed, and the accession for the protein sequence.
Author response:
Public Reviews:
Reviewer #1 (Public review):
Summary:
Thach et al. report on the structure and function of trimethylamine N-oxide demethylase (TDM). They identify a novel complex assembly composed of multiple TDM monomers and obtain high-resolution structural information for the catalytic site, including an analysis of its metal composition, which leads them to propose a mechanism for the catalytic reaction.
In addition, the authors describe a novel substrate channel within the TDM complex that connects the N-terminal Zn²-dependent TMAO demethylation domain with the C-terminal tetrahydrofolate (THF)-binding domain. This continuous intramolecular tunnel appears highly optimized for shuttling formaldehyde (HCHO), based on its negative electrostatic properties and restricted width. The authors propose that this channel facilitates the safe transfer of HCHO, enabling its efficient conversion to methylenetetrahydrofolate (MTHF) at the C-terminal domain as a microbial detoxification strategy.
Strengths:
The authors provide convincing high-resolution cryo-EM structural evidence (up to 2 Å) revealing an intriguing complex composed of two full monomers and two half-domains. They further present evidence for the metal ion bound at the active site and articulate a plausible hypothesis for the catalytic cycle. Substantial effort is devoted to optimizing and characterizing enzyme activity, including detailed kinetic analyses across a range of pH values, temperatures, and substrate concentrations. Furthermore, the authors validate their structural insights through functional analysis of active-site point mutants.
In addition, the authors identify a continuous channel for formaldehyde (HCHO) passage within the structure and support this interpretation through molecular dynamics simulations. These analyses suggest an exciting mechanism of specific, dynamic, and gated channeling of HCHO. This finding is particularly appealing, as it implies the existence of a unique, completely enclosed conduit that may be of broad interest, including potential applications in bioengineering.
Weaknesses:
Although the idea of an enclosed channel for HCHO is compelling, the experimental evidence supporting enzymatic assistance in the reaction of HCHO with THF is less convincing. The linear regression analysis shown in Figure 1C demonstrates a THF concentration-dependent decrease in HCHO, but the concentrations used for THF greatly exceed its reported KD (enzyme concentration used in this assay is not reported). It has previously been shown that HCHO and THF can couple spontaneously in a non-enzymatic manner, raising the possibility that the observed effect does not require enzymatic channeling. An additional control that can rule out this possibility would help to strengthen the evidence. For example, mutating the THF binding site to prevent THF binding to the protein complex could clarify whether the observed decrease in HCHO depends on enzyme-mediated proximity effects. A mutation which would specifically disable channeling could be even more convincing (maybe at the narrowest bottleneck).
We agree with the reviewer that HCHO and THF can react spontaneously in a non-enzymatic manner, and our experiments were not intended to demonstrate enzymatic channeling. The linear regression analysis in Figure 1C was designed solely to confirm that HCHO reacts with THF under our assay conditions. Accordingly, THF was titrated over a broad concentration range starting from zero, and the observed THF concentration–dependent decrease in HCHO reflects this chemical reactivity.
We do not interpret these data as evidence that the enzyme catalyzes or is required for the HCHO–THF coupling reaction. Instead, the structural observation of an enclosed channel is presented as a separate finding. We have clarified this point in the revised text to avoid overinterpretation of the biochemical data (page 2, line 16).
Another concern is that the observed decrease in HCHO could alternatively arise from a reduced production of HCHO due to a negative allosteric effect of THF binding on the active site. From this perspective, the interpretation would be more convincing if a clear coupled effect could be demonstrated, specifically, that removal of the product (HCHO) from the reaction equilibrium leads to an increase in the catalytic efficiency of the demethylation reaction.
We agree that, in principle, a decrease in detectable HCHO could also arise from an indirect effect of THF binding on enzyme activity. However, in our study the experiment was not designed to assess catalytic coupling or allosteric regulation. The assay in question monitors HCHO levels under defined conditions and does not distinguish between changes in HCHO production and downstream consumption.
Additionally, we do not interpret the observed decrease in HCHO as evidence that THF binding enhances catalytic efficiency, or that removal of HCHO shifts the reaction equilibrium. Instead, the data are presented to establish that HCHO can react with THF under the assay conditions. Any potential allosteric effects of THF on the demethylation reaction, or kinetic coupling between HCHO removal and catalysis, are beyond the scope of the current study, and are not claimed.
While the enzyme kinetics appear to have been performed thoroughly, the description of the kinetic assays in the Methods section is very brief. Important details such as reaction buffer composition, cofactor identity and concentration (Zn<sup>2+</sup>), enzyme concentration, defined temperature, and precise pH are not clearly stated. Moreover, a detailed methodological description could not be found in the cited reference (6), if I am not mistaken.
Thank you for the suggestion. We have added reference [24] to the methodological description on page 8. The Methods section has been revised accordingly on page 8 under “TDM Activity Assay,” without altering the Zn<sup>2+</sup> concentration.
The composition of the complex is intriguing but raises some questions. Based on SDS-PAGE analysis, the purified protein appears to be predominantly full-length TDM, and size-exclusion chromatography suggests an apparent molecular weight below 100 kDa. However, the cryo-EM structure reveals a substantially larger complex composed of two full-length monomers and two half-domains.
We appreciate the reviewer’s careful analysis of the apparent discrepancy between the biochemical characterization and the cryo-EM structure. This issue is addressed in Figure S1, which may have been overlooked.
As shown in Figure S1, the stability of TDM is highly dependent on protein and salt conditions. At 150 mM NaCl, SEC reveals a dominant peak eluting between 10.5 and 12 mL, corresponding to an estimated molecular weight of ~170–305 kDa (blue dot, Author response image 1). This fraction was explicitly selected for cryo-EM analysis and yields the larger complex observed in the reconstruction. At lower salt concentrations (50 mM) or higher (>150 mM NaCl), the protein either aggregates or elutes near the void volume (~8 mL).
SDS–PAGE analysis detects full-length TDM together with smaller fragments (~40–50 kDa and ~22–25 kDa). The apparent predominance of full-length protein on SDS–PAGE likely reflects its greater staining intensity per molecule and/or a higher population, rather than the absence of truncated species.
Author response image 1.
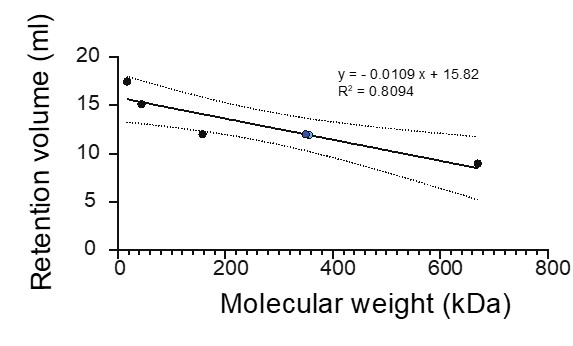
Given the lack of clear evidence for proteolytic fragments on the SDS-PAGE gel, it is unclear how the observed stoichiometry arises. This raises the possibility of higher-order assemblies or alternative oligomeric states. Did the authors attempt to pick or analyze larger particles during cryo-EM processing? Additional biophysical characterization of particle size distribution - for example, using interferometric scattering microscopy (iSCAT)-could help clarify the oligomeric state of the complex in solution.
Cryo-EM data were collected exclusively from the size-exclusion chromatography fraction eluting between 10.5 and 12 mL. This fraction was selected to isolate the dominant assembly in solution. Extensive 2D and 3D particle classification did not reveal distinct classes corresponding to smaller species or higher-order oligomeric assemblies. Instead, the vast majority of particles converged to a single, well-defined structure consistent with the 2 full-length + 2 half-domain stoichiometry.
A minor subpopulation (~2%) exhibited increased flexibility in the N-terminal region of the two full-length subunits, but these particles did not form a separate oligomeric class, indicating conformational heterogeneity rather than alternative assembly states (Author response image 2). Together, these data support the 2+2½ architecture as the predominant and stable complex under the conditions used for cryo-EM. Additional techniques, such as iSCAT, would provide complementary information, but are not required to support the conclusions drawn from the SEC and cryo-EM analyses presented here.
Author response image 2.
The authors mention strict symmetry in the complex, yet C2 symmetry was enforced during refinement. While this is reasonable as an initial approach, it would strengthen the structural interpretation to relax the symmetry to C1 using the C2-refined map as a reference. This could reveal subtle asymmetries or domain-specific differences without sacrificing the overall quality of the reconstruction.
We thank the reviewer for this thoughtful suggestion. In standard cryo-EM data processing, symmetry is typically not imposed initially to minimize potential model bias; accordingly, we first performed C1 refinement before applying C2 symmetry. The resulting C1 reconstructions revealed no detectable asymmetry or domain-specific differences relative to the C2 map. In addition, relaxing the symmetry consistently reduced overall resolution, indicating lower alignment accuracy and further supporting the presence of a predominantly symmetric assembly.
In this context, the proposed catalytic role of Zn<sup>2+</sup> raises additional questions. Why is a 2:1 enzyme-to-metal stoichiometry observed, and how does this reconcile with previous reports? This point warrants discussion. Does this imply asymmetric catalysis within the complex? Would the stoichiometry change under Zn<sup>2+</sup>-saturating conditions, as no Zn<sup>2+</sup> appears to be added to the buffers? It would be helpful to clarify whether Zn<sup>2+</sup> occupancy is equivalent in both active sites when symmetry is not imposed, or whether partial occupancy is observed.
The observed ~2:1 enzyme-to-Zn<sup>2+</sup> stoichiometry likely reflects the composition of the 2 full-length + 2 half-domain (2+2½) complex. In this assembly, only the core domains that are fully present in the complex contribute to metal binding. The truncated or half-domains lack the Zn<sup>2+</sup> binding domain. As a result, only two metal-binding sites are occupied per assembled complex, consistent with the measured stoichiometry.
We note that Zn<sup>2+</sup> was not deliberately added to the buffers, so occupancy may not reflect full saturation. Based on our cryo-EM and biochemical data, both metal-binding sites in the full-length subunits appear to be occupied to an equivalent extent, and no clear evidence of asymmetric catalysis is observed under these current experimental conditions. Full Zn<sup>2+</sup> saturation could potentially increase occupancy, but was not explored in these experiments.
The divalent ion Zn<sup>2+</sup> is suggested to activate water for the catalytic reaction. I am not sure if there is a need for a water molecule to explain this catalytic mechanism. Can you please elaborate on this more? As one aspect, it might be helpful to explain in more detail how Zn-OH and D220 are recovered in the last step before a new water molecule comes in.
Thank you for your suggestion. We revised our text in page 2 as bellow.
Based on our structural and biochemical data, we propose a structurally informed working model for TMAO turnover by TDM (Scheme 1). In this model, Zn<sup>2+</sup> plays a non-redox role by polarizing the O–H bond of the bound hydroxyl, thereby lowering its pK<sub>a</sub>. The D220 carboxylate functions as a general base, abstracting the proton to generate a hydroxide nucleophile. This hydroxide then attacks the electrophilic N-methyl carbon of TMAO, forming a tetrahedral carbinolamine (hemiaminal) intermediate. Subsequent heterolytic cleavage of the C–N bond leads to the release of HCHO. D220 then switches roles to act as a general acid, donating a proton to the departing nitrogen, which facilitates product release and regenerates the active site. This sequence allows a new water molecule to rebind Zn<sup>2+</sup>, enabling subsequent catalytic turnovers. This proposed pathway is consistent with prior mechanistic studies, in which water addition to the azomethine carbon of a cationic Schiff base generates a carbinolamine intermediate, followed by a rate-limiting breakdown to yield an amino alcohol and a carbonyl compound, in the published case, an aldehyde (Pihlaja et al., J. Chem. Soc. Perkin Trans. 2, 1983, 8, 1223–1226).
Overall, the authors were successful in advancing our structural and functional understanding of the TDM complex. They suggest an interesting oligomeric complex composition which should be investigated with additional biophysical techniques.
Additionally, they provide an intriguing hypothesis for a new type of substrate channeling. Additional kinetic experiments focusing on HCHO and THF turnover by enzymatic proximity effects would strengthen this potentially fundamental finding. If this channeling mechanism can be supported by stronger experimental evidence, it would substantially advance our understanding and knowledge of biologic conduits and enable future efforts in the design of artificial cascade catalysis systems with high conversion rate and efficiency, as well as detoxification pathways.
Reviewer #2 (Public review):
Summary:
The manuscript reports a cryo-EM structure of TMAO demethylase from Paracoccus sp. This is an important enzyme in the metabolism of trimethylamine oxide (TMAO) and trimethylamine (TMA) in human gut microbiota, so new information about this enzyme would certainly be of interest.
Strengths:
The cryo-EM structure for this enzyme is new and provides new insights into the function of the different protein domains, and a channel for formaldehyde between the two domains.
Weaknesses:
(1) The proposed catalytic mechanism in this manuscript does not make sense. Previous mechanistic studies on the Methylocella silvestris TMAO demethylase (FEBS Journal 2016, 283, 3979-3993, reference 7) reported that, as well as a Zn2+ cofactor, there was a dependence upon non-heme Fe<sup>2+</sup>, and proposed a catalytic mechanism involving deoxygenation to form TMA and an iron(IV)-oxo species, followed by oxidative demethylation to form DMA and formaldehyde.
In this work, the authors do not mention the previously proposed mechanism, but instead say that elemental analysis "excluded iron". This is alarming, since the previous work has a key role for non-heme iron in the mechanism. The elemental analysis here gives a Zn content of about 0.5 mol/mol protein (and no Fe), whereas the Methylocella TMAO demethylase was reported to contain 0.97 mol Zn/mol protein, and 0.35-0.38 mol Fe/mol protein. It does, therefore, appear that their enzyme is depleted in Zn, and the absence of Fe impacts the mechanism, as explained below.
The proposed catalytic mechanism in this manuscript, I am sorry to say, does not make sense to me, for several reasons:
(i) Demethylation to form formaldehyde is not a hydrolytic process; it is an oxidative process (normally accomplished by either cytochrome P450 or non-heme iron-dependent oxygenase). The authors propose that a zinc (II) hydroxide attacks the methyl group, which is unprecedented, and even if it were possible, would generate methanol, not formaldehyde.
(ii) The amine oxide is then proposed to deoxygenate, with hydroxide appearing on the Zn - unfortunately, amine oxide deoxygenation is a reductive process, for which a reducing agent is needed, and Zn2+ is not a redox-active metal ion;
(iii) The authors say "forming a tetrahedral intermediate, as described for metalloproteinase", but zinc metalloproteases attack an amide carbonyl to form an oxyanion intermediate, whereas in this mechanism, there is no carbonyl to attack, so this statement is just wrong.
So on several counts, the proposed mechanism cannot be correct. Some redox cofactor is needed in order to carry out amine oxide deoxygenation, and Zn<sup>2+</sup>cannot fulfil that role. Fe<sup>2+</sup> could do, which is why the previously proposed mechanism involving an iron(IV)-oxo intermediate is feasible. But the authors claim that their enzyme has no Fe. If so, then there must be some other redox cofactor present. Therefore, the authors need to re-analyse their enzyme carefully and look either for Fe or for some other redox-active metal ion, and then provide convincing experimental evidence for a feasible catalytic mechanism. As it stands, the proposed catalytic mechanism is unacceptable.
We thank the reviewer for the detailed and thoughtful mechanistic critique. We fully agree that Zn<sup>2+</sup> is not redox-active, and cannot directly mediate oxidative demethylation or amine oxide deoxygenation. We acknowledge that the oxidative step required for the conversion of TMAO to HCHO is not explicitly resolved in the present study. Accordingly, we have revised the manuscript to remove any implication of Zn<sup>2+</sup>-mediated redox chemistry, and have eliminated the previously imprecise analogy to zinc metalloproteases.
We recognize and now discuss prior biochemical work on TMAO demethylase from Methylocella silvestris (MsTDM), which proposed an iron-dependent oxidative mechanism (Zhu et al., FEBS 2016, 3979–3993). That study reported approximately one Zn<sup>2+</sup> and one non-heme Fe<sup>2+</sup> per active enzyme, implicated iron in catalysis through homology modeling and mutagenesis, and used crossover experiments suggesting a trimethylamine-like intermediate and oxygen transfer from TMAO, consistent with an Fe-dependent redox process. However, that system lacked experimental structural information, and did not define discrete metal-binding sites.
In contrast,
(1) Our high-resolution cryo-EM structures and metal analyses of TDM consistently reveal only a single, well-defined Zn<sup>2+</sup>-binding site, with no structural evidence for an additional iron-binding site as in the previous report (Zhu et al., FEBS 2016, 3979–3993).
(2) To investigate the potential involvement of iron, we expressed TDM in LB medium supplemented with Fe(NH<sub>4</sub>)<sub>2</sub>SO<sub>4</sub> and determined its cryo-EM structure. This structure is identical to the original one, and no EM density corresponding to a second iron ion was observed. Moreover, the previously proposed Fe<sup>2+</sup>-binding residues are spatially distant (Figure S6).
(3) ICP-MS analysis shows undetectable Iron, and only Zinc ion (Figure S5).
(4) Our enzyme kinetics analysis with the TDM without Iron is comparable to that of from MsTDM (Figure 1A). The differences in Km and Vmax we propose is due to the difference in the overall sequence of the enzymes. Please also see comment at the end on a new published paper on MsTDM.
While we cannot comment on the MsTDM results, our ‘experimental’ results do not support the presence of an iron-binding site. Our data indicate that this chemistry is unlikely to be mediated by a canonical non-heme iron center as proposed for MsTDM. We therefore revised our model as a structural framework that rationalizes substrate binding, metal coordination, and product stabilization, while clearly delineating the limits of mechanistic inference supported by the current data.
The scheme 1 and proposal mechanism section were revised in page 4. Figure S6 was added.
(2) Given the metal content reported here, it is important to be able to compare the specific activity of the enzyme reported here with earlier preparations. The authors do quote a Vmax of 16.52 µM/min/mg; however, these are incorrect units for Vmax, they should be µmol/min/mg. There is a further inconsistency between the text saying µM/min/mg and the Figure saying µM/min/µg.
Thank you for the correction. We converted the V<sub>max</sub> unit to nmol/min/mg. and revised the text in page 2. We also compared with the value of the previous report in the TDM enzyme by revising the text on page 2. See also the note on a newly published manuscript and its comparison.
(3) The consumption of formaldehyde to form methylene-THF is potentially interesting, but the authors say "HCHO levels decreased in the presence of THF", which could potentially be due to enzyme inhibition by THF. Is there evidence that this is a time-dependent and protein-dependent reaction? Also in Figure 1C, HCHO reduction (%) is not very helpful, because we don't know what concentration of formaldehyde is formed under these conditions; it would be better to quote in units of concentration, rather than %.
We appreciate this important point. We have revised Figure 1C to present HCHO levels in absolute concentration units. While the current data demonstrate reduced detectable HCHO in the presence of THF, we agree that distinguishing between HCHO consumption and potential THF-mediated enzyme inhibition would require dedicated time-course and protein-dependence experiments. We have therefore revised the description to avoid overinterpretation and limit our conclusions to the observed changes in HCHO concentration in page 2, line 18-19.
(4) Has this particular TMAO demethylase been reported before? It's not clear which Paracoccus strain the enzyme is from; the Experimental Section just says "Paracoccus sp.", which is not very precise. There has been published work on the Paracoccus PS1 enzyme; is that the strain used? Details about the strain are needed, and the accession for the protein sequence.
Thank you for this comment. We now indicate that the enzyme is derived from Paracoccus sp. DMF and provide the accession number for the protein sequence (WP_263566861) in the Experimental Section (page 8, line 4).
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
(1) The ITC experiment requires a ligand-into-buffer titration as an additional control. Also, maybe I misunderstood the molar ratio or the concentrations you used, but if you indeed added a total of 4.75 μL of 20 μM THF into 250 μL of 5 μM TDM, it is not clear to me how this leads to a final molar ratio of 3.
We thank the reviewer for this suggestion. A ligand-into-buffer control ITC experiment was performed and is now included in Figure S8C, which shows no realizable signal.
Regarding the molar ratio, it is our mistake. The experiment used 2.45 μL injections of 80 μM THF into 250 μL of 5 μM TDM. This corresponds to a final ligand concentration of ~12.8 μM, giving a ligand-to-protein molar ratio of ~2.6. We revised our text in page 9, ITC section.
(2) Characterization/quality check of all mutant enzymes should be performed by NanoDSF, CD spectroscopy or similar techniques to confirm that proteins are properly folded and fit for kinetic testing.
We appreciate the reviewer’s suggestion. All mutant proteins, including D220A, D367A, and F327A, were purified with yields similar to the wild-type enzyme. Additionally, cryo-EM maps of the mutants show well-defined density and overall structural integrity consistent with the wild-type. These findings indicate that the introduced mutations do not significantly affect protein folding, supporting their use for kinetic analysis. While NanoDSF might reveal differences in thermal stability due to mutations, it does not provide structural information. Our conclusions are not based on minor differences in thermostability. Our cryo-EM structures of the mutants offer much more reliable structural data than CD spectroscopy.
(3) Best practice would suggest overlapping pH ranges between different buffer systems in the pH-dependence experiments to rule out buffer-specific effects independent of pH.
We thank the reviewer for this helpful suggestion. We agree that overlapping pH ranges between different buffer systems can be valuable for excluding buffer-specific effects. In this study, the pH-dependence experiments were intended to provide a qualitative assessment of pH sensitivity rather than a detailed analysis of buffer-independent pKa values. While we cannot fully exclude minor buffer-specific contributions, the overall trends observed were reproducible and sufficient to support the conclusions drawn. We have added a clarifying statement to the revised manuscript to reflect this consideration, page 2, line 12.
(4) Structural comparison revealed high similarity to a THF-binding protein, with superposition onto a T protein.": It would be nice to show this as an additional figure, as resolution and occupancy for THF are low.
We thank the reviewer for this suggestion. To address this point, we have revised Figure S6 by adding an additional panel (C, now is Figure S7C) showing the structural superposition of TDM with the THF-binding T protein. This comparison is included to better illustrate the structural similarity, despite the limited resolution and partial occupancy of THF density in our map.
(5) Editing could have been done more thoroughly. Some spelling mistakes, e.g. "RESEULTS", "redius", "complec"; kinetic rate constants should be written in italic (not uniform between text and figures); Prism version is missing; Vmax of 16.52 µM/min/mg - doublecheck units; Figure S1B: The "arrow on the right" might have gone missing.
We corrected the spelling in page 2 ~ line 10, page 5 ~ line 34, page 6 ~ line40. Prism version was added. The arrow was added into figure S1B. The Vmax unit is corrected to nmol/min/mg.
Reviewer #2 (Recommendations for the authors):
(1) The authors must re-examine the metal content of their purified enzyme, looking in particular for Fe or another redox-active metal ion, which could be involved in a reasonable catalytic mechanism.
We thank the reviewer for this suggestion and have carefully re-examined the metal content of TDM. Elemental analyses by EDX and ICP-MS consistently detected Zn<sup>2+</sup> in purified TDM (Zn:protein ≈ 1:2), whereas Fe was below the detection limit across multiple independent preparations (Fig. S5A,B). To assess whether iron could be incorporated or play a functional role, we expressed TDM in E. coli grown in LB medium supplemented with Fe(NH<sub>4</sub>SO<sub>4</sub>)<sub>2</sub> and performed activity assays in the presence of exogenous Fe<sup>2+</sup>. Neither condition resulted in enhanced enzymatic activity.
Consistent with these biochemical data, all cryo-EM structures reveal a single, well-defined metal-binding site coordinated by three conserved cysteine residues and occupied by Zn<sup>2+</sup>, with no evidence for an additional iron species or other redox-active metal site.
(2) The specific activity of the enzyme should be quoted in the same units as other literature papers, so that the enzyme activity can be compared. It could be, for example, that the content of Fe (or other redox-active metal) is low, and that could then give rise to a low specific activity.
Thank you for the suggestion, we quoted the enzyme units as similar with previous report. and revised the text in in page 2.
Since the submission of our paper a new report on MsTDM has been published (Cappa et al., Protein Science 33(11), e70364). It further supports our findings. First, the reported kinetic parameters using ITC (Vmax = 0.309 μmol/s, approximately 240 nmol/min/mg; Km = 0.866 mM) are comparable to our observed (156 nmol/min/mg and 1.33 mM, respectively) in the absence of exogenous iron. Second, the optimal pH for enzymatic activity similar to that observed in our paraTDM. Third, the reported two-state unfolding behavior is consistent with our cryo-EM structural observations, in which the more dynamic subunits appear to destabilize prior to unfolding of the core domains. Based on these findings, we now propose that Zn<sup>2+</sup> appears to function primarily as an organizational cofactor at the core catalytic domain (revised Scheme 1).
https://pchat-chi.vercel.app/chat/8ce08ack11ec6pgfiak
pChat
chat app using svelte
If you look at Daoism, everything is the Dao expressing itself in 10,000 forms.
10:55
If you look at hermetic texts all 10:55 is one
10:55
you are not a drop in the ocean. You are the entire ocean in a drop.
10:48
10:26 basically means you are that not connected to it, not loved by it. You 10:33 are the divine wearing this [music] human costume.
tat wa masi
You are not separate. You 10:09 never were and you never could be
never could be
tat wa masi
gone the farthest away from
yep
Here's what they all agreed
The five truths
completing each other
9:31

empirical psychology can-not fully account for consolation and desolation.
Ignatius’s consolation and desolation can’t be fully explained by psychology because they affect a person’s whole outlook, not just one isolated feeling. Still, they are not totally separate from ordinary emotions, so we should avoid both reducing them to mental states OR treating them as purely miraculous experiences.
The success has been such that the foursome joined forces with two others to create Julia Computing, the commercial advisory arm for the language. Setting up the commercial arm was a positive but nerve-racking moment, Shah said. Indeed, he pegged it as the most difficult time for Julia: “It was less to do with Julia and more [to do with] how we can make it self-sustaining. We knew it was the right time, but at the same time, it was scary to imagine doing that.”
La verdadera ruptura fue la transición de un proyecto entre amigos a una compañía auténtica, para Shah y su equipo, el desafío no consistía en el aspecto técnico del lenguaje, que ya era excelente; sino en cómo hacer que sobreviviera: convertir un código gratuito en una empresa sostenible. Fue una decisión, abandonar el experimento académico y transformarlo en un instrumento profesional que hoy emplean empresas de gran tamaño en cualquier parte del mundo.
That such a language didn’t exist frustrated Karpinski, and he expressed the sentiment to his friend Viral Shah toward the end of his time at UC Santa Barbara. Shah, who had previously worked at Interactive Supercomputing for Alan Edelman—an MIT professor and world-renowned mathematician responsible for Edelman’s law—and had since moved to Bengaluru, India, to work on a countrywide biometric identification project, agreed. So did Jeff Bezanson, a colleague of Shah’s at Interactive Supercomputing, as well as Edelman himself.
Básicamente, fue una "frustración colectiva" entre amigos, que unió a mentes brillantes Karpinski expresó su inconformidad a Shah, quien a su vez convenció a Bezanson y Edelman, decidieron dejar de esperar que no existiera una la herramienta tecnológica perfecta y crearon su propia solución .
“We were really just building something for ourselves,” said Julia co-creator Stefan Karpinski, a Harvard Mathematics alum with a PhD in computer science from the University of California, Santa Barbara. (Karpsinki also set a Guinness World Record in 2006 for the fastest single-fare journey across the whole of New York City’s subway system; he’s a determined guy who doesn’t like to waste time.)
Esta anécdota de Karpinski lo dice todo, Julia fue creado por gente que odiaba perder el tiempo, en otras palabras Julia es el resultado de expertos que se cansaron de esperar y decidieron construir un diseño mas ágil en el mundo de programación.
Like many revolutionary changes in human history, it started with a flash of frustration. Today, Julia is ranked among the top programming languages, and is deployed by the likes of Amazon, Apple, Facebook, NASA, and Uber. But when its creators started building it nearly a decade ago, their goal was a lot smaller.
A veces la frustración en cualquier campo es el combustible de las mejores innovaciones tecnológicas y el caso Julia y sus creadores no es exención.
Julia is constantly evolving, buoyed by its open-source ethos and the broad range of voices in its contributor base. “They enrich Julia in ways we could never have imagined ourselves,” said Shah
El conocimiento no se termina, lo que permite ver que Julia siempre estará en constante mejora, pues al ser código abierto tendrá siempre un aporte nuevo, sin embargo también estará abierto a posibles errores. Se podría llegar a pensar también que con el tiempo pueda ser reemplazado o superado por algún otro lenguaje innovador que se base en el lenguaje de Julia como este se inspiró en otros lenguajes para su creación.
Piercing that veil between the user and the developer has been really eye-opening
La colaboración entre comunidad y desarrolladores es imprescindible ya que estos mismos usuarios al encontrarse con necesidades propias y la adaptabilidad de las herramientas en condición de software libre genera una distribución y una evolución del proyecto de una manera que el equipo original jamás hubiera logrado. Es importante contar con el desarrollo y ayuda de cualquier persona interesada ya que al fin y al cabo de esa misma manera se hace la ciencia, mediante comunicación y aportando a lo ya existente.
creando algoritmos utilizando MATLAB, C y R
Hasta ahora no sabía de lenguajes de programación creados a partir de combinar varios lenguajes existentes y establecidos para transformar algo nuevo, ya ahora se me hace una idea muy interesante que se alinea con el objetivo que se planteó al principio el cual era hacer un lenguaje accesible para todos, cómodo para los principiantes y completo para los veteranos, por lo que este esfuerzo de crear algo nuevo con bases de otros se entiende como tomar los mejor de cada uno y crear algo nuevo mas allá de la suma de sus partes.
“Sin esas contribuciones, creo que sería muy difícil para Julia ser lo que es.”
Cuando Julia es puesta en código abierto, se convierte en un espacio donde muchas personas pueden contribuir y también proponer una mejora continua. Considero que de esta manera los usuarios dejan de solo consumir información a crear nuevo conocimiento a partir de sus intervenciones.
Scheme
Lenguaje de programación precursor
El objetivo del equipo de crear un lenguaje aficionado que pudiera combinar velocidad y profundidad fue recibido inicialmente con escepticismo
Creo que el hecho de siempre crear algo para hacer un cambio mayor en el mundo, trae muchos problemas como el hecho de no querer usarlo por ser nuevo, pero por lo que se nos cuenta, realmente era algo diferente a lo que ya habia
Por la noche, pasaba horas frente a su ordenador de casa, intentando programar un sistema que acabaría reemplazando los lenguajes de programación que usaba en su trabajo diurno
Es curioso como en algunas historias tambien se escuchan temas similares, una persona que tiene un trabajo en una empresa haciendo una labor, pero cuando tienen tiempo a solas, y esa libertad de crear, es cuando avanzan en su proyecto personal
Pero cuando sus creadores empezaron a construirlo hace casi una década, su objetivo era mucho menor
Normalmente los proyectos siempre empiezan para un grupo pequeño, pero a medica avanza, el objetivo cambia al darse cuenta del potencial que hay
Lo que nos mantiene unidos es el objetivo de construir el mejor software numérico y matemático posible, mucho mejor que cualquier cosa que exista hoy en día
Me encanta esta frase ya que resalta que lo que realmente une a las personas no es solo la tecnología en sí, sino un propósito compartido y no individual.
Como muchos cambios revolucionarios en la historia humana, comenzó con un destello de frustración
Me gusta mucho como inicia la lectura ya que nos muestra que Julia no fue una línea perfecta , si no que fueron trazos no lineales , pero necesarios , vemos que las mejores cosas no salen de la perfección si no de frustraciones o incomodidades .
Modernize
US spelling 🤮
Heb dit al eens eerder gevonden. Nu zie ik dat inmiddels: [[Gerard Kema p]] van Prov FRL hierin getraind is, evenals Genien Pathuis [[Willy Tadema p]] staat genoemd, evenals [[Rob van Kranenburg p]]
z-inspection is a tool (CC by nc sa) to assess trustworthy AI using applied ethics. Wordt gebruikt door Rijks ICT-Gilde en door DataFryslan
wereldwijd behaalde winst
Dit is echter niet het bedrag dat werkelijk belast wordt. Binnenlandse belastingplichtigen hebben de objectvrijstelling voor buitenlandse ondernemingswinsten (art. 15e lid 1 Vpb)
OECD catalogue of AI tools en metrics for trustworthy AI.
Inmiddels is DataFryslân een coöperatie met veertien leden, waaronder zeven Friese gemeenten en de Provinsje Fryslân. Nieuw Elan Juni 2024 Nee./PODIUM Geen. Ntb. Ntb. Geen. Geen.Geen. Huurdersbelang Fryslân december 2023 Nee./PODIUM Geen. Ntb. Ntb. Geen. Geen.Geen. De Friesland november 2023 Nee./PODIUM. Geen. Ntb. Ntb. Geen. Geen.Geen. Gemeente Tytsjerksteradiel november 2023 Nee./HUB Geen. Ntb. Ntb. Geen. Geen.Geen. Provinsje Fryslân februari 2019 Ja./HUB Drs. Arjan SchepersAlgemeen Directeur Provinsje Fryslân Mark StuijtAdviseur Provinsje Fryslân Berend TirionAdviseur Provinsje Fryslân Diederik Scepter (februari 2019 - december 2021) Regina Bouius (februari 2019 - juni 2022) Geen.Geen. Gemeente Leeuwarden februari 2019 Ja./HUB Drs. Eelke de JongBestuursvoorzitter DataFryslânVoorzitter ALV DataFryslânGemeentesecretaris Gemeente Leeuwarden Gijs ScholtenWethouder gemeente Leeuwarden Elsbeth van HaselenHoofd Informatiemanagement Mr. Ir. Reindert Hoek (februari 2019)... Gemeente Súdwest-Fryslân februari 2019 Ja./HUB Drs. Kristiaan StrijkerPenningmeester DataFryslânGemeentesecretaris gemeente Súdwest-Fryslân Michiel RietmanWethouder gemeente Súdwest-Fryslân Rob JanssenTeammanager Informatiemanagement Pieter Zondervan (februari 2019 - december 2021)... Gemeente Smallingerland februari 2019 Ja./HUB Siebren van den BergSecretaris bestuur DataFryslânGemeentesecrataris gemeente Smallingerland Sipke HoekstraWethouder gemeente Smallingerland Mariska van Nijen, Teammanager Informatiemanagement (2025 - ) Jelmer Mulder (februari 2019 - december... Rijksuniversiteit Groningen februari 2019 Ja./HUB Prof. Dr. Anne BeaulieuAletta Jacobs chair of Knowledge InfrastructuresDirector of the Data Research Centre at Campus Fryslan Prof. Dr. Andrej ZwitterDean Campus Fryslân Dr. Oscar GstreinProgramme Director Campus Fryslân Jouke de Vries (februari... NHL STENDEN februari 2019 Ja./HUB Drs. Peter MulderProgrammamanager Ecosystemen Erica SchaperBestuursvoorzitter van NHL Stenden Frank GortProgrammamanager NHL Stenden Soon Hee Santema (februari 2019 - december 2021) Geen.Geen. Planbureau Friesland februari 2019 Ja./PODIUM Geen Geen Chaïm La Roi Drs. Ingrid de VegteDirecteur/Bestuurder FSP(2019 - 2023) Jornt OzengaRaad van Toezicht FSPGemeentesecretaris van gemeente Lelystad(2019 - 2023) Marijn Mollema (2022-2024) Gemeente Waadhoeke mei 2022 Ja./LAB Geen. Jeroen IJkemaGemeentesecretaris gemeente Waadhoeke Jan-Daem de LangeTeammanager Informatiemanagement Geen. Geen.Geen. ROS Friesland Mei 2022 Nee./PODIUM Geen Sandra ScherstraDirecteur ROS Friesland Jildou de JongAdviseur Geen. Geen.Geen. Tresoar September 2019 Nee./PODIUM Geen. Arjan DijkstraDirecteur Tresoar Olav KwakmanTeammanager ICT Geen. Geen.Geen. Elkien September 2019 Nee./HUB Drs. Peter van er WegDirecteur/bestuurder Elkien Janine Koning, MSc, Manager ICT, Data en Digitalisering (januari 2025 - ) Dennis Feenstra (2022 - ) Geen. Geen. Roel Vuursteen (2022 - 2024) Gemeente Ooststellingwerf November 2022 Nee./PODIUM Geen. Geen. Geen. Geen. Geen.Geen. Gemeente Weststellingwerf November 2022 Nee./PODIUM Geen. Geen Geen Geen. Geen.Geen. Gemeente Noardeast-Fryslân Juni 2024 Nee./HUB Geen. Henk Verbunt MBA, gemeentesecretaris Noardeast-Fryslân Herman Buikema Geen. Geen.Geen. Gemeente Heerenveen Maart 2023 Nee./PODIUM Geen. Geen. Geen. Geen. Geen.Geen.
De DataFryslan cooperatie heeft 20 leden,
eLife Assessment
This study provides a useful contribution to understanding how wearable augmentation devices interact with human proprioception, using a longitudinal design over a single session. Results demonstrate that the perceptual representation of the biological finger and augmentation device changes across different phases of device exposure and use. The evidence supporting a representational change over time is solid, although it is still not clear whether these changes reflect three distinct phases of sensorimotor plasticity, as argued, versus 'washout' or adaptation effects. This work will be of interest to researchers studying body representation, sensorimotor learning, and human-technology interaction.
Reviewer #1 (Public review):
This study by Radziun and colleagues investigates the effects of using a hand-augmentation device on mental body representations. The authors use a proprioceptive localisation task to measure metric representations of finger length before and after participants wear the device, and then before and after they learn to use the device, which extends the lengths of the fingers by 10 cm. The authors find changes between different time points, which they interpret as evidence for three distinct forms of plasticity: one related to simply wearing the device, one related to learning to use it, and an aftereffect after taking the device off. A control experiment with a similar device, which does not lengthen the fingers, showed the first and third of these forms of plasticity, but not the second.
This study takes an interesting approach to a timely and theoretically significant issue. The study appears to be appropriately designed and conducted. There are, however, some points which require clarification.
(1) The nature of the localization task is unclear. On its face, the task appears to involve localization of each landmark within the 2-dimensional surface of the touchscreen. However, the regression analysis presupposes that localization is made in a 1-dimensional space. Figure S2 shows that three lines are presented on the screen above the index, middle, and ring fingers, which I imagine the participant is meant to use as a guide. But it is at least conceivable that the perceived location or orientation of the finger might not correspond exactly to these lines. While the method can deal gracefully with proximal-distal translations of the fingers (i.e., with the intercept parameter of the regression), it isn't clear how the participant is supposed to respond if their proprioceptive perception of finger location is translated left-right or rotated relative to the lines on the screen. I also worry that presenting a long, thin line to represent each finger on the screen may not be a neutral method and may prime participants to represent the finger as long and thin.
(2) The task used here fits within a wider family of tasks in the literature using localization judgments of multiple landmarks to map body representations. I feel that some discussion of this broader set of tasks and their use to measure body representation and plasticity is notably absent from the paper. It is also striking to me that some of the present authors have themselves recently criticized the use of landmark localization methods as a measure of represented body size and shape (Peviani et al, 2024, Current Biology). It is therefore surprising to see them use this task here as a measure of represented finger length without commenting on this issue.
(3) 18 participants strikes me as a relatively small sample size for this type of study. It weakens the manuscript that the authors do not provide any justification, or even comment on, the sample size. This is especially true as participants are excluded from the entire sample, and from specific analyses, on rather post-hoc grounds.
(4) I have some concerns about the interpretation of contraction in stage 2. The authors claim that wearing the finger extended produces "a contraction",i.e., an "under-representation" (page 12). But in both experiments, regression slopes in stage 2 were not significantly different from 1 (i.e., 0.98 [SE: 0.07] in Exp 1a and 1.04 [SE: 0.09] in Experiment 1b). So how can that be interpreted as "under-representation"?
(5) I also have concerns about the interpretation of the stretch that is claimed to occur following training. In Exp 1a, regression slopes in stage 3 are on average 1.15. That is LESS than in the pretest at stage 1 (mean: 1.16). The idea of stretch only comes about because of the lower slopes in stage 2, which the authors have interpreted as reflecting contraction. So what the authors call stretch and a 2nd form of plasticity could just be the contraction from stage 2 wearing off or dissipating, since perceived finger length in stage 3 just appears to return to the baseline level seen in stage 1. While the authors describe their results in terms of three distinct forms of plasticity, these are not in fact statistically independent. The dip in regression slopes in stage 2 is interpreted as evidence for two distinct plasticity effects, which I do not find convincing.
(6) The distinction between plasticity at stage 3 (which appears specific to augmentation) and plasticity at stage 4 (which does not appear specific, as it also occurs in Experiment 1b) feels strained. This feels like a very subtle distinction, and the theoretical significance of it is not convincingly developed.
(7) The reporting of statistics is not always consistent. For example, 95%CIs are presented for regression slopes in stages 1, 3, and 4, but not for stage 2. Statistics are performed on regression slopes, except for one t-test on page 7 comparing lengths in cm. Estimates of effect size would be nice additions to statistical tests.
(8) Minor point: On page 4, the authors write, "These included sorting colored blocks, stacking a Jenga tower, and sorting pegs into holes; the latter task required fine-grained manipulation and was used as our outcome measure of motor learning." This suggests that peg sorting was the outcome measure, but in Figure 1D, Jenga is presented as the outcome measure.
Reviewer #2 (Public review):
Summary:
This study aimed to explore dynamic changes in the somatosensory representation of both the body and artificial body parts. The study investigated how proprioceptive localisation along the finger changes when participants wear, actively use, and then remove a hand augmentation device - a rigid finger-extension. By mapping perceived target locations along the biological finger and the extension across multiple stages, the authors aim to characterise how the somatosensory system updates our spatial body representation during and after interaction with body augmentation technology.
Strengths:
The manuscript addresses an interesting question of how augmentation devices alter proprioceptive localisation abilities. Conceptually, the work moves beyond classic tool-use paradigms by focusing on a device that is used with the hand to extend the fingers' abilities (versus a tool that is simply used by the hand), and by attempting to map perceived spatial structure across both biological and artificial segments within the same framework.
A major strength is the multi-stage design, which samples localisation abilities at baseline, the beginning of device wear, post-training, and immediately post-removal. This provides a richer characterisation of short-term adaptation compared to a simple pre/post comparison. The dense sampling across stages and target locations generates a rich behavioural dataset that will be valuable to readers interested in somatosensory body representation. The within-subject, counterbalanced control session further strengthens interpretability, providing a useful comparison for interpreting stage-dependent effects, and to probe how functional training shapes changes in the perceptual representations. Finally, the augmentation device itself appears carefully engineered, with thoughtful design decisions regarding wearability, including comfort and customised fit. The manuscript is also communicated clearly, with transparent reporting of analyses and succinct figures that make the pattern changes across stages straightforward to evaluate.
Weaknesses:
There is conceptual ambiguity in how the regression outcomes are interpreted in relation to perceived length and spatial integration. The manuscript treats regression slope as a proxy for "length perception" and discards the intercept as "spatial bias," but in this localisation task translation (intercept) and scaling (slope) are coupled: changes in anchoring at the proximal baseline (intercept) or distal endpoint can generate slope differences without uniform rescaling across the mapped surface. Relatedly, the analyses do not establish whether the reported effects are global across targets or disproportionately driven by the most distal locations. This limits the strength of inferences about "partitioning" or "reallocation" of representational space across biological and artificial segments. Some interpretive statements also appear stronger than the evidence supports (e.g., describing the stage 2 bio-extension map as "geometrically accurate", despite Bayes factors that provide only anecdotal support for no difference from true length). Extensive repeated judgements to a fixed set of locations may additionally stabilise response strategies or anchoring even without feedback, complicating the separation of body-representation change from task-specific calibration.
The manuscript would also benefit from clearer conceptual framing of what the device is and what its training probes are. The device is described variably as an "artificial finger" versus a rigid "finger extension," with different implications for perception and function. In addition, the training tasks appear to emphasise manipulation and dexterity more than scenarios requiring an extended reachable workspace (indeed, participants appear to have performed at least as well, if not better, in the control training), which brings into question whether participants explored the device's intended functionality and possible proprioceptive consequences. The control experiment is thoughtfully designed to test whether functional training contributes to the stage 3 changes, but because localisation is not performed while wearing the short device, the design does not resolve whether the stage 2 change and the post-removal aftereffect are specific to the augmentative extension versus more general consequences of wearing a device on the finger (and the following possible distorted distal cues).
Finally, the immediate post-removal aftereffects are intriguing, but the mechanistic interpretation remains underspecified. As presented within the internal model framework, the magnitude and consistency of the aftereffect following brief exposure are difficult to reconcile with the stability expected from a lifetime biological finger model, and because the aftereffect is assessed only immediately after removal, its time course and functional significance remain unclear.
Reviewer #3 (Public review):
Summary:
The study aims to investigate sensorimotor plasticity mechanisms by exposing a cohort of 20 subjects to manipulation activities while using wearable finger extensions. With a series of experiments involving localization and motor tasks, the authors provide evidence that the finger extensions are integrated into the body representation of the subjects.
Strengths:
The study deserves attention, and the psychophysical protocols are carefully designed, and the statistical analyses are solid.
Weaknesses:
However, the current version of the manuscript, in my opinion, makes an exaggerated use of the term plasticity, and this should be amended. This is because the authors support the plasticity claims with psychophysical experiments, without providing evidence of neural-plasticity mechanisms (e.g., neuroimaging methods are not used).
The authors are recommended to revise the wording of the manuscript and possibly perform additional experiments with brain imaging methods (e.g., EEG or fMRI).
DataFryslân is in 2019 ontstaan als samenwerkingsverband van zeven Friese maatschappelijke organisaties die tijdens hun gezamenlijke betrokkenheid bij de Kulturele Haadstêd 2018 ontdekten dat er mooie dingen kunnen ontstaan als partijen met diverse achtergronden kennis en ervaringen met elkaar delen en samen optrekken met een gemeenschappelijk doel: datagedreven werken organiseren, stimuleren en propageren.
DataFryslan begon als 7 maatschappelijke organisaties die elkaar rondom Culturele Hoofdstad 2018 troffen op datagedreven werken.
DataFryslân is een cooperatie (sinds 2022, daarvoor samenwerkingsverband)
web-trail://💻/thinkpad/🧊/me/📓/2026/02/15/translated/ady-endre-magyar-pimodan
TODO
maps to local.link
According to the new view, things arethe other way around: Huckleberry Finn performs an action with full moral worth,whereas Finn from Star Wars does not.
Is this true? It seems to me like Arpaly, for one, WOULD grant that the actions of Star Wars Finn have moral worth. What am I missing?
counterintuitiveclaims about examples like B URIED TREASURE , ACCIDENTAL SLAYER , and SEMAPHORE D AN-CER
Moral knowledge seems like it is importantly different from the kinds of knowledge involved in these examples.
Frysian Data Space FRLDS, datadeelomgeving voor leden van DataFryslân.
This video was generated with AI and is intended for entertainment purposes only.
Yep

is it AI generated?

hester.107 Bycontrast, while Llywelyn ap Gruffudd, the prince of Wales killed in1282, was commemorated in verse and music, notably a highlypopular cantata first performed at the National Eisteddfod in 1863,nothing came of periodic attempts from the 1850s onwards to raisesubscriptions for a monument in his honour.108 The same was largelytrue of calls for the raising of statues of other Welsh heroes. Thus itwas that Tom Ellis, Liberal Member of Parliament and leading lightof the Cymru Fydd or Young Wales movement, still felt it necessaryin 1892 to urge his compatriots to cherish "the
So welsh people didn;t do this as much as else where?
astle," submitted to the Llangolleneisteddfod of 1858 and published two years later, may have been setin the late fourteenth century but its subject was the ideal VictorianWelsh woman, and thus, as one of its adjudicators observed, offereda riposte to the Blue Books' slurs on Welsh w
POetry at the eisteddfod, while with a medieval flavour, sought to use the past to legitimise themselves
anwg. The Llangolleneisteddfod of 1858, masterminded by the Reverend John Williams(Ab Ithel; 1811-62), was the high tide of this ardent patriotism,prompting The Times to observe sourly: "For four days all that hastaken place in the world since the age of OWEN GLYNDWR isforgotte
Link to eistedfodd
o-Saxons. The popularity ofthis satirical characterization of the Blue Books testified to awidespread familiarity among the Welsh with legends about theirearly and medieval past.76 Indeed, one response to the Blue Bookswas to vindicate what was perceived to be traditional Welsh culturewith its roots in the Middle A
good quote!
on, which asserted that the early Welsh church windependent of Rome; thus the end of the period covered in the stusaw, to quote Rees, "the Welsh in the possession of a NationaChurch and in the enjoyment of religious liberty," subsequentrestored at the Refor
Medieval revival kinda was aided by the growth of nonconformity and scholarly thinking that medieval times saw welsh church og not affilitated with rome
f Anglicans were receptive to Pre-Raphaelite art, and byimplication its medieval exemplars, Evan Williams (18167-1878),Calvinist Methodist minister, artist, and pioneering Welsh-languageart critic was extremely hos
Interesting - did people even accept the pre-raphelite medieval revival? Had close links to catholicism.
ar. However, though it lacks anyobvious Welsh affinities, it provided a fitting setting for a landownerintent on proclaiming his status as a latter-day lord of the manor, notsimply in the general terms so common at the time wherebyVictorian gentlemen identified themselves with the ethos ofmedieval chivalry, but more specifically as the self-proclaimedtwenty-third lord in succession of Cemais - a lordship in nearbynorthern Pembrokeshire established in the early twelfth ce
The art style was also used to assert dominance - not exactly very nationalist is it
he early nineteenthcentury we find both established landed families and nouveau richeindustrialists following a wider trend of expressing their status by theerection of castles.
A popular archtectural style that was impressive - was this nationalism
edieval.13 Nevertheless,religious affiliations certainly influenced Welsh attitudes to theMiddle Ages. For one thing, despite the influx of Irish Catholicimmigrants, and the restoration of the Roman Catholic hierarchy inEngland and Wales in 1850, Wales offered poor prospects for large-scale attempts to revive medieval forms of Catholic devotion of thekinds seen in countries with large Catholic populations such asFranc
Medieval revival with william bute's castle possibly due to his catholic beliefs? idksome architect said that gothic was the true religious art style?
. While provoking widespread condemnation,the report also stimulated efforts to prove that the Welsh were notonly respectable but fully equipped to participate in the commercialand industrial progress of imperial Brit
SLAYYY very important
distorsions comportementales
Quelles sont-elles?
addiction croissante
Pathologie de l'usage d'internet en général
tout le monde
Usage du "tout le monde" comme généralité absolu sans fondement scientifique. En fait un simple avis.
eLife Assessment
This paper investigates the Achilles' heel of an aggressive pediatric bone cancer known as Ewing sarcoma. The authors aimed to better understand how its previously undruggable drivers mediate oncogenic mechanisms using several omics approaches. Transcriptomic changes aligned with their findings provide convincing evidence for the role of a short alpha helix in the DNA binding domain of FLI1 in modulating binding to GGAA microsatellites and promoting enhancer activity. The study provides valuable new insights into the underlying oncogenic mechanisms in Ewing sarcoma.
Reviewer #1 (Public review):
Summary:
Ewing sarcoma is an aggressive pediatric cancer driven by the EWS-FLI oncogene. Ewing sarcoma cells are addicted to this chimeric transcription factor, which represents a strong therapeutic vulnerability. Unfortunately, targeting EWS-FLI has proven to be very difficult and better understanding how this chimeric transcription factor works is critical to achieving this goal. Towards this perspective, the group had previously identified a DBD-𝛼4 helix (DBD) in FLI that appears to be necessary to mediate EWS-FLI transcriptomic activity. Here, the authors used multi-omic approaches, including CUT&tag, RNAseq, and MicroC to investigate the impact of this DBD domain. Importantly, these experiments were performed in the A673 Ewing sarcoma model where endogenous EWS-FLI was silenced, and EWS-FLI-DBD proficient or deficient isoforms were re-expressed (isogenic context). They found that the DBD domain is key to mediate EWS-FLI cis activity (at msat) and to generate the formation of specific TADs. Furthermore, cells expressing DBD deficient EWS-FLI display very poor colony forming capacity, highlighting that targeting this domain may lead to therapeutic perspectives.
Strengths:
The group has strong expertise in Ewing sarcoma genetics and epigenetics and also in using and analyzing this model (Theisen et al., 2019; Boone et al., 2021; Showpnil et al., 2022).
They aim at better understanding how EWS-FLI mediated its oncogenic activity, which is critical to eventually identifying novel therapies against this aggressive cancer.
They use the most recent state-of-the-art omics methods to investigate transcriptome, epigenetics, and genome conformation methods. In particular, Micro-C enables achieving up to 1kb resolved 3D chromatin structures, making it possible to investigate a large number of TADs and sub-TADs structures where EWS-FLI1 mediates its oncogenic activity.
They performed all their experiments in an Ewing sarcoma genetic background (A673 cells) which circumvents bias from previously reported approaches when working in non-orthologous cell models using similar approaches.
Weaknesses:
The main weakness stems from the poor reproducibility of the Micro-C data. Indeed, the distances and clustering observed between replicates appear to be similar to, or even greater than, those observed between biological conditions. For instance, in Figure 1B, we do not observe any clear clustering among DBD1, DBD2, DBD+1, and DBD+2. Although no further experiments were performed, the authors tempered their claims by rephrasing aspects related to this issue and the reviewer also acknowledged that the transcriptomic data are convincing and support their findings.
Regarding DBD stability and the cycloheximide experiments requested to rule out any half-life bias of DBD (as higher stability of the re-expressed DBD+ could also partially explain the results independently of a 3D conformational change), the reviewer acknowledged that the WB, RNA-seq data and agar assays presented by the authors appear reproducible across experiments.
Author response:
The following is the authors’ response to the previous reviews
Public Review:
Reviewer #1 (Public review):
Ewing sarcoma is an aggressive pediatric cancer driven by the EWS-FLI oncogene. Ewing sarcoma cells are addicted to this chimeric transcription factor, which represents a strong therapeutic vulnerability. Unfortunately, targeting EWS-FLI has proven to be very difficult and better understanding how this chimeric transcription factor works is critical to achieving this goal. Towards this perspective, the group had previously identified a DBD-𝛼4 helix (DBD) in FLI that appears to be necessary to mediate EWS-FLI transcriptomic activity. Here, the authors used multi-omic approaches, including CUT&tag, RNAseq, and MicroC to investigate the impact of this DBD domain. Importantly, these experiments were performed in the A673 Ewing sarcoma model where endogenous EWS-FLI was silenced, and EWS-FLI-DBD proficient or deficient isoforms were re-expressed (isogenic context). They found that the DBD domain is key to mediate EWS-FLI cis activity (at msat) and to generate the formation of specific TADs. Furthermore, cells expressing DBD deficient EWS-FLI display very poor colony forming capacity, highlighting that targeting this domain may lead to therapeutic perspectives.
This new version of the study comprises as requested new data from an additional cell line. The new data has strengthened the manuscript. Nevertheless, some of the arguments of the authors pertaining to the limitations of immunoblots to assess stability of the DBD constructs or the poor reproducibility of the Micro C data remain problematic. While the effort to repeat MicroC in a different cell line is appreciated, the data are as heterogeneous as those in A673 and no real conclusion can be drawn. The authors should tone down their conclusions. If DBD has a strong effect on chromatin organization, it should be reproducible and detectable. The transcriptomic and cut and tag data are more consistent and provide robust evidence for their findings at these levels.
We agree that the Micro-C data have more apparent heterogeneity within and across cell lines as compared to other analyses such as our included CUT&Tag and RNA-seq. We addressed the possible limitations of the technique as well as inherent biology that might be driving these findings in our previous responses. Despite the poor clustering on the PCA plots, our analysis on differential interacting regions, TADs and loops remain consistent across both cell lines. We are confident that these findings reflect the context of transcriptional regulation by the constructs, therefore the role of the alpha-helix in modulating chromatin organization. To address the concerns raised by the editors and reviewers for the strength of the conclusions we drew from the Micro-C findings we have made changes to the language used to describe them throughout the manuscript. Find these changes outlined below.
• On lines 70-71, "is required to restructure" was changed to "is implicated in restructuring of"
• On line 91, "is required for" was changed to "participates in"
• On line 98, "is required for" changed to "is potentially required for"
• On line 360-361, "is required for restructuring" changed to "participates in restructuring"
Concerning the issue of stability of the DBD and DBD+ constructs, a simple protein half-life assay (e.g. cycloheximide chase assay) could rule out any bias here and satisfactorily address the issue.
While we generally agree that a cycloheximide assay is a relatively simple approach to look at protein half-life, as we discussed last me the assays included in this paper are performed at equilibrium and rely on the concentration of protein at the me of the assay. This is particularly true for assays involving crosslinking, like Micro-C. As discussed in our prior response, western blots are semi quantitative at best, even when normalized to a housekeeping protein. In analyzing the relative protein concentration of DBD vs. DBD+ with relative protein intensities first normalized to tubulin and using the wildtype EWSR1::FLI1 rescue as a reference point, we find that there is no statistical difference in the samples used for micro-C here (Author responseimage 1A) or across all of the samples that we have used for publication (Author response image 1B). This does show that DBD generally has more variable expression levels relative to wildtype EWSR1::FLI1, and this is consistent with our experience in the lab.
Nonetheless, we did attempt to perform the requested cycloheximide chase experiment to determine protein stability. Unfortunately, despite an extensive number of troubleshooting attempts, we have not been able to get good expression of DBD for these experiments. The first author who performed this work has left the lab and we have moved to a new lab space since the benchwork was performed. We continue to try to troubleshoot to get this experimental system for DBD and DBD+ to work again. When we tried to look at stability of DBD+ following cycloheximide treatment, there did appear to be some difference in protein stability (Author response image 2). However, these conditions are not the same conditions as those we published, they do not meet our quality control standards for publication, and we are concerned about being close to the limit of detection for DBD throughout the later timepoints. Additional studies will be needed with more comparable expression levels between DBD and DBD+ to satisfactorily address the reviewer concerns.
Author response image 1.
Expression Levels of DBD and DBD+ Across Experiments. Expression levels of DBD and DBD+ protein based on western blot band intensity normalized by tubulin band intensity. Expression levels are relative to wildtype EWSR1::FLI1 rescue levels and are calculated for (A) A673 samples used for micro-C and (B) all published studies of DBD and DBD+. P-values were calculated with an unpaired t-test.
Author response image 2.
CHX chase assay to determine the stability of DBD and DBD+. (A) Knock-down of endogenous EWSR1::FLI1 detected with FLI1 ab and rescue with DBD and DBD+ detected with FLAG ab. (B) CHX chase assay to determine the stability of DBD and DBD+ in A-673 cells with quantification of the protein levels (n=3). Error bars represent standard deviation. The half-lives (t1/2) of DBD and DBD+ were listed in the table.
Suggestions:
The Reviewing Editor and a referee have considered the revised version and the responses of the referees. While the additional data included in the new version has consolidated many conclusions of the study, the MicroC data in the new cell line are also heterogeneous and as the authors argue, this may be an inherent limitation of the technique. In this situation, the best would be for the authors to avoid drawing robust conclusions from this data and to acknowledge its current limitations.
As discussed above, we have changed the language regarding our conclusions from micro-C data to soften the conclusions we draw per the Editor’s suggestion.
The referee and Reviewing Editor also felt that the arguments of the authors concerning a lack of firm conclusions on the stability of EWS-FLI1 under +/-DBD conditions could be better addressed. We would urge the authors to perform a cycloheximide chase type assay to assess protein half-life. These types of experiments are relatively simple to perform and should address this issue in a satisfactory manner.
As discussed above, we do not feel that differences in protein stability would affect the results here because the assays performed required similar levels of protein at equilibrium. Our additional analyses in this response shows that there are not significant differences between DBD and DBD+ levels in samples that pass quality control and are used in published studies. However, we attempted to address the reviewer and editor comments with a cycloheximide chase assay and were unable to get samples that would have passed our internal quality control standards. These data may suggest differences in protein stability, but it is unclear that these conditions accurately reflect the conditions of the published experiments, or that this would matter with equal protein levels at equilibrium.
3: Determine likelihood of occurrence
The Two Parts of Likelihood: Likelihood isn't just one number. It is calculated by combining two factors:
Likelihood of Initiation/Occurrence: Will the enemy try to attack? (Or will the hurricane happen?)
Likelihood of Resulting in Adverse Impact: If they do attack, will they succeed? (Will our defenses stop them, or will they break through?)
Overall Likelihood: You combine those two factors to get the final score (e.g., if they are likely to try, AND likely to succeed, the Overall Likelihood is High).
Why are mission and vision important for organizational goals and objectives?
to determine whether the strategy is on track
How do mission and vision relate to a firm’s strategy
relate to an organization’s purpose and aspirations, and are typically communicated in some form of brief written statements
Where does the purpose of mission and vision overlap?
Overlap in developing strategy
stock #6357
DOI: 10.3390/cells12081142
Resource: RRID:BDSC_6357
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_6357
stock #2475
DOI: 10.3390/cells12081142
Resource: RRID:BDSC_2475
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_2475
stock #33832
DOI: 10.3390/cells12081142
Resource: RRID:BDSC_33832
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_33832
Bloomington Stock Center, #5905
DOI: 10.1038/s41467-023-38414-8
Resource: RRID:BDSC_5905
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_5905
BL3605
DOI: 10.1038/s41467-023-38414-8
Resource: RRID:BDSC_3605
Curator: @scibot
SciCrunch record: RRID:BDSC_3605
BL51989
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51989
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51989
BL51993
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51993
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51993
BL51988
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51988
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51988
BL51992
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51992
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51992
BL25685
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_25685
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_25685
BL37516
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_37516
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_37516
BL51977
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51977
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51977
BL58769
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_58769
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_58769
BL51990
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51990
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51990
BL51975
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51975
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51975
BL25682
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_25682
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_25682
BL51970
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51970
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51970
BL51979
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51979
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51979
BL51980
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51980
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51980
BL6301
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_6301
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_6301
BL25684
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_25684
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_25684
BL51991
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51991
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51991
BL51972
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51972
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51972
BL51982
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51982
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51982
BL25683
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_25683
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_25683
BL51971
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51971
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51971
BL51981
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51981
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51981
BL52017
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_52017
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_52017
BL39283
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_39283
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_39283
BL6899
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_6899
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_6899
BL51987
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51987
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51987
BL25681
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_25681
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_25681
BL51978
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51978
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51978
BL51986
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51986
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51986
BL51985
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51985
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51985
BL5905
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_5905
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_5905
BL51984
DOI: 10.1016/j.cub.2023.04.055
Resource: RRID:BDSC_51984
Curator: @bdscstockkeepers
SciCrunch record: RRID:BDSC_51984
BL22044
DOI: 10.3390/ijms24098443
Resource: RRID:BDSC_22044
Curator: @scibot
SciCrunch record: RRID:BDSC_22044
RRID:AB_2892682
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_3718609
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_955447
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2753196
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2107448
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_302459
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2756528
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2894870
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_10597232
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2289842
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_3083804
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2210545
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2801561
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_955417
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2714032
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_2076150
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_10644283
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
RRID:AB_3678465
Traceback (most recent call last): File "/home/ubuntu/dashboard/py/create_release_tables.py", line 54, in format_anno_for_release parsedanno = HypothesisAnnotation(anno) File "/home/ubuntu/dashboard/py/hypothesis.py", line 192, in init t = row['document']['title'] TypeError: string indices must be integers
risk model and analysis approach
The Chain of Events (The Diagram)
The diagram flows from left to right, showing the "story" of how a risk happens. You should understand the relationship between these boxes:
Threat Source (The "Who" or "What"):
This is the adversary (e.g., a hacker, a dishonest employee) or a non-adversarial source (e.g., a power failure).
Key factors: They have capability (skill), intent (motivation), and targeting.
Threat Event (The "Action"):
The source initiates an event (e.g., sending a phishing email, launching malware).
Key factor: Likelihood of initiation (how likely are they to try?).
Vulnerability (The "Weakness"):
The threat event exploits a vulnerability (e.g., unpatched software, a weak password).
Predisposing Conditions: Things that make the weakness easier to exploit (e.g., the server is facing the public internet).
Security Controls: Things that block the attack (e.g., a firewall). These reduce the likelihood of success.
Adverse Impact (The "Consequence"):
If the vulnerability is exploited, it causes impact (e.g., data theft, system downtime).
Organizational Risk (The "Result"):
The combination of the likelihood of the attack succeeding and the severity of the impact produces the final risk level.
Risk
Step 1: Prepare for Assessment Before you start, you need a plan. You align the assessment with the organization's goals. (Slide 2 explains this in detail).
Step 2: Conduct Assessment (The Core) This is the "Execution" phase. Memorize this sequence inside the gray box, as it is often a quiz question:
Step 3: Communicate Results Notice the arrows go both ways. You don't just report at the end; you talk to stakeholders during the process to ensure facts are correct.
Step 4: Maintain Assessment Risk assessment is not a one-time event. You must monitor and update it over time as technology changes.
Tier 3
implementation layer - where hardware and software live
Tier 2
operational layer/middle management - bridge between top-lvl goals n actual tech - focuses on functions the business needs to perform to survive
Tier 1
decisions made here affect the entire company -- laws, budget, high-level policy
gouvernementalité numérique
Thème central avec l'opacité des processus de régulation
B07PGH9DLQ
Asins markiert
Compound heterozygous novel frameshift variants in the PROM1 gene result in Leber congenital amaurosis
PMID:31836589
Gene: ABCA4
HGNC ID: 34
Note d'Information : Priorités de la Protection de l’Enfance et Justice des Mineurs
Ce document synthétise les orientations stratégiques et les réformes engagées par le ministère de la Justice pour renforcer la protection de l’enfance et moderniser la justice des mineurs.
Les points clés incluent :
• Urgence et Rapidité : Réduction des délais de jugement (passés de 18 mois à 8,7 mois en quatre ans) et création d'une ordonnance de protection provisoire permettant au procureur de statuer en 72 heures.
• Refonte du Placement : Fermeture des Centres Éducatifs Fermés (CEF) publics au profit des Unités de Placement de la Jeunesse et de l'Éducation (UJPE), mettant l'accent sur la continuité pédagogique (52 semaines/an).
• Moyens Humains Massifs : Création de 1 600 postes au ministère de la Justice, dont 50 nouveaux cabinets de juges des enfants en deux ans et 70 postes à la Protection Judiciaire de la Jeunesse (PJJ).
• Évolutions Législatives : Soutien à l'imprescriptibilité des crimes sexuels sur mineurs, à la présence obligatoire de l'avocat pour l'enfant, et volonté de réformer l'« excuse de minorité » pour les crimes les plus graves.
• Protection contre les Fléaux Modernes : Lutte contre la prostitution des mineurs (6 prostituées sur 10 sont mineures), interdiction des téléphones portables en centres de placement, et encadrement du protoxyde d'azote.
--------------------------------------------------------------------------------
L'accent est mis sur la nécessité d'une justice qui s'adapte au rythme de l'enfant.
• Ordonnance de protection provisoire : Un nouveau dispositif permet au procureur d'agir en 72 heures pour protéger immédiatement un mineur, avec des interdictions de contact et l'attribution provisoire du logement au parent protecteur.
Le juge dispose ensuite de 8 jours pour être saisi et de 15 jours pour statuer.
• Loi du 18 mars 2024 : Prévoit le retrait automatique de l'autorité parentale pour les parents condamnés pour crime ou violence sexuelle sur leur enfant, ainsi que l'élargissement de la suspension de l'exercice de cette autorité dès la mise en examen.
• Avocat pour l'enfant : Soutien à la présence obligatoire d'un avocat en assistance éducative.
Une expérimentation avec les barreaux est envisagée avant une généralisation législative.
• Unités d'Accueil Pédiatrique (UAPED) : Déploiement en cours sur tout le territoire pour améliorer le recueil de la parole et le soin des victimes.
• Chiens d'assistance judiciaire : Passage de 10 à une trentaine de chiens actuellement, avec un objectif de 100 chiens (un par département) d'ici un à deux ans pour apaiser les enfants lors des procédures.
--------------------------------------------------------------------------------
La doctrine ministérielle refuse l'opposition entre ces deux concepts.
• La sanction comme acte éducatif : « La sanction fait partie de l'éducation. La sanction toute seule n'est pas un but en soi [...] et une éducation sans aucun interdit mène au n'importe quoi. »
• Efficacité du Code de la Justice Pénale des Mineurs (CJPM) : Les délais entre les faits et la sanction ont été divisés par deux en quatre ans (8,7 mois en 2024 contre 18 mois en 2020).
Le constat sur les Centres Éducatifs Fermés (CEF) est jugé sévère : coût élevé (30 à 50 % de plus), taux de fugue identique aux centres classiques, et déshérence éducative (seulement 5 à 10 heures de cours par semaine).
• Création des UJPE : Ces nouvelles unités fusionnent les anciens foyers et les CEF pour garantir un parcours de reconstruction pédagogique.
• Recrutement de professeurs techniques : Réouverture d'un concours pour 40 professeurs dépendant directement du ministère de la Justice afin d'assurer 26 heures de cours par semaine, 52 semaines sur 52, y compris durant les vacances scolaires.
• Santé et Addictions : Recrutement de 60 infirmiers pour pallier les carences de soins psychiatriques et de prise en charge des addictions dans les centres de placement.
--------------------------------------------------------------------------------
Le budget de la Justice permet une hausse inédite des moyens humains :
• Magistrature : Création de 50 cabinets de juges des enfants supplémentaires en deux ans (notamment à Bobigny, Cambrai, Alès).
Actuellement, certains cabinets gèrent entre 400 et 500 dossiers.
• PJJ : Recréation de 70 postes, permettant de renforcer les effectifs là où ils baissaient depuis 20 ans (ex: Marseille, Île-de-France).
• Milieu Ouvert : Réaffectation de 150 éducateurs vers le milieu ouvert pour ramener la charge de travail à environ 23 dossiers par agent (contre 25 auparavant).
Le système actuel est jugé trop fragmenté (plusieurs ministères concernés, compétences partagées avec les départements pour l'ASE).
Une volonté de meilleure coordination, voire d'unité de responsabilité, est exprimée.
--------------------------------------------------------------------------------
• Fin de la prescription : Avis favorable pour l'imprescriptibilité des crimes sexuels sur mineurs, ainsi que pour les crimes de sang (assassinats).
• Prostitution des mineurs : Un constat alarmant montre que 60 % des prostituées en France sont mineures.
Des unités dédiées au sein de la PJJ sont opérationnelles depuis trois mois pour lutter contre ce fléau et les réseaux de proxénétisme.
• Interdiction des téléphones : La nouvelle circulaire de politique éducative et pénale impose l'interdiction des téléphones portables dans les chambres des centres de placement pour protéger les mineurs des prédations numériques (trafiquants, proxénètes).
• Protoxyde d'azote : Soutien à la pénalisation du transport et de l'achat en ligne (en dehors du cadre médical), alors que les intoxications ont triplé entre 2020 et 2023.
• Excuse de minorité : Position favorable à la fin de l'automatisme de l'atténuation de peine pour les crimes les plus graves (assassinats, tortures) commis par des mineurs de 13 à 15 ans.
Cela nécessiterait une évolution constitutionnelle tout en préservant la spécialisation du jugement des mineurs.
--------------------------------------------------------------------------------
| Indicateur | Donnée Source | | --- | --- | | Délai moyen de jugement (2020) | 18 mois | | Délai moyen de jugement (2024) | 8,7 mois | | Dossiers par cabinet de juge des enfants | 400 à 500 (moyenne) | | Proportion de mineurs parmi les prostitués | 60 % | | Nombre de mineurs à l'ASE | 400 000 (dont 200 000 placés) | | Heures de cours en CEF | < 10h/semaine (contre 26h en milieu classique) | | Placements chez des tiers de confiance | < 9 % (19 000 jeunes) |
--------------------------------------------------------------------------------
« L'enfant ne vit pas au rythme d'un dossier administratif ou d'un dossier judiciaire. [...] 4 mois pour un mineur c'est une vie. »
« Nous devrions pouvoir en grande partie avoir honte de la façon dont on traite une partie de ces enfants notamment à l'aide sociale à l'enfance. »
« Le placement doit protéger et pas rendre encore plus vulnérable. »
« La sanction fait partie de l'éducation. [...] Une éducation sans jamais aucun interdit mène au n'importe quoi. »
Everyone brings something valuable to the community. I love this sentences and I believe it's something to remember not only for language learning but about all aspects of community building in international education.
There were no pathogenic variants or variants of unknown significance identified. Genes included in the testing: ABCA4
Case report no known pathogenic variants of ABCA4 found. subject had a diagnosis of stargardt disease
A case of pentosan polysulfate maculopathy originally diagnosed as stargardt disease
PMID:32043016
Gene: ABCA4
HGNC ID: 34
payment_id
payment_id will not be available in case of API Payment (non3p)
Sequencing of the coding region of ABCA4 and of the entire ABCA4 locus revealed one heterozygous ABCA4 variant c.3113C>T; p.(Ala1038Val). No other (likely) pathogenic coding or noncoding ABCA4 variants including copy number variants were identified.
ABCA4 variant revealed but not target of research and doesn't seem to amount to anything Variantc.3113C>T p.(Ala1038Val)
Functional characterization of novel MFSD8 pathogenic variants anticipates neurological involvement in juvenile isolated maculopathy
PMID:31721179
Gene: ABCA4
HGNC ID: 34
in
on
board
Should this be formatted as code like elsewhere?
In Atari,
"On Atari," is better. Same with further on "while in the other two", should be "while on the other two"
The Clojure workspaceThe Python workspace
The links didn't work for me
variant in exon 44 presented with contrasting phenotypes; from early‐onset cone‐rod dystrophy
Deletion on exon 44 resulting in dystrophy of parts of eye
Phenotype–genotype correlations in a pseudodominant Stargardt disease pedigree due to a novel ABCA4 deletion–insertion variant causing a splicing defect
PMID: 32627976
Gene: ABCA4
HGNC ID: 34
What value is printed when the following statement executes?
go up from 18 to 20. do 20 divided by 4 = 6. 6 - 4 = 2. 2 is the remainder and the answer to 18 % 4.
The question raisedby these critics is not only what modes of representation and what kindof aesthetic might adequately convey an understanding of nature thatreaches beyond conceptions of harmonious, balanced, and cyberneticallyself-regulating ecosystems to a more complex view of dynamic biologicaland ecological processes that often do not produce anything one wouldwant to refer to as harmonious or equilibrated.
Nature is not external to humanity and it is certainly not harmonious in the sense that everyone gets along, but ecologies function in a way where threads pulls every which way and affect every lifeform. We can prescribe that life is neutral and ecologies being "harmonious" is neutral, but we have to contend with our accountability ot each other and to the suffering of other humans and other species (read: individuals) that we can reasonably perceive as being harmed unnaturally.
Focal choroidal excavation in Stargardt’s dystrophy
PMID:328843395
Gene: ABCA4
HGNC ID: 34
Mandy says she would be afraid to go back without some proof that you were disposed to treat us justly and kindly; and we have concluded to test your sincerity by asking you to send us our wages for the time we served you.
I agree with this statement, I am proud of Jourdon for listening to his wife and being smart with his request. Not only is he aiming to get money, but he's doing it in a way that can be a double edge sword for the "master". this puts the master in a situation where he truly has to ponder. Dose he sacrifice his ego and put it to the side giving them their well-deserved money, or dose he reject their offer but lose the chance of them coming back.
Black Americans hoped that the end of the Civil War would create an entirely new world, while white southerners tried to restore the antebellum order as much as they could. Most former enslavers sought to maintain control over their laborers through sharecropping contracts. P.H. Anderson of Tennessee was one such former enslaver. After the war, he contacted his former enslaved laborer Jourdon Anderson, offering him a job opportunity. The following is Jourdon Anderson’s reply.
This sentence is important to me because it shows the fear of any parent right through is words of worry. The fear of their daughters being dishonored. In this day and age there are still cases such as where a woman is disrespected and or mistreated just because she is a woman, and this is today where society has changed its views and is less misogynistic. I can only imagine the scenarios that play in Jourdon Anderson mind back then. I believe He is a great father.
I have often felt uneasy about you
I figure the reason why this sentence confuses me is because usually after someone as powerful as a slave owner at the time had previously held control over u, one would usually coward. In this case this man was being blunt, why? is there a greater meaning than just wanting to stand grown. I wondered how he felt writing this letter. weather he was scared or worried, perhaps calm, maybe confident?
They have an obligation to consultIndigenous communities, but we do not have the power to say no.
relate the way the city is handled
“If everything is an archive, what meaning does the word have?
I really like this question because it challenges how loosely people use the word “archive.” If everything becomes an archive, then the term loses its power. She is defending the real labor and structure behind institutional archives.
Using the strategies in this chapter can help you overcome the fear of the blank page and confidently begin the writing process.
Although nothing will be perfect, it's important to remember use the resources given!
The younger one's lineage had a strange son with bird's eyes and bulging eyelids, broad forehead, turquoise eyebrows, elevated nose, conch shell teeth, webbed hand like a duck's limbs, and with a majestic look
one of the theories where Nyatri was a strange looking grandson of the Indian king who was cast to the Ganges river and grew up till fleeing to Tibet...
"When there was no difference of king and subject in Tibet, there in the Shakya lineage were: Great Shakyan, Shakya Lichhavi, and Shakya Ri bgrag. From them came sKyabs seng, whose one of the younger sons fled to the Himalayas with his platoon. From the summit of Lha ri rol po mountain of Yarlung in Tibet, he descended through lha skes [god's staircase] to the four Tsan sgo. The people proclaimed him as a King, who descended from the sky; they received him in a throne and took him on their shoulder to the land. Therefore, the name, Napeenthroned king, this was the first king of Tibet.
This text states that Nyati was the one of the younger sons of King Skyab seng of the Shakya lineage, who fled to the Himalayas with his platoons up the summut of Lha Ri pol of Yarlung Tibet before descended through god's staircase to the four Tsansgo where he was proclaimed king
Western non-White students are less likely to report science-related career aspirations as they age (Sheldrake, 2018). Social support from teachers or friends for a student’s STEM interests also declines after elementary school (Rice et al., 2013). Middle school STEM achievement fully explains racial and ethnic disparities in advanced high school STEM coursework
When you think about how students are moved through the school system, this makes sense. In elementary school, you spend a year with an entire teacher. It become a bi-directional relationship. Meaning that there is more of a relationship. Moving towards middle school, the teachers have more students, more classes to teach, and less time to get to know the students. The same can be said at a high school level unless students are going to smaller schools.
Yet to what extent Black, Hispanic, or AINAPI students in the United States are already less likely to display advanced STEM achievement during ele-mentary school is currently unknown
why? this seems to be like a equity issue, probably the root of the problem?
1.6 out of 1,000 later held patents.
Why use that ratio? Why not say 16 of 10,000? Why not just give a percentage? Was this done to make it "more digestible" for the reader?
Less than 1% of those with a bachelor’s degree in sci-ence or engineering are American Indian, Native American, or Pacific Islanders
One of the reasons of this must be that funding for STEM/STEAM programs are likely to get cut for schools that are in low-income neighborhoods. It should also be noted that the STEM/STEAM teaching positions are hard to fill.
national priority
Who made this a priority?
About 13% to 16% of White students versus 3% to 4% of Black or Hispanic students displayed advanced science or mathematics achievement during kindergarten.
I would be interested to see the location of this study. Was it for an entire district? a city? a state?
Badger Company Founder Walks the Walk
see website at https://www.badgerbalm.com/ Good products, see About and Healthy Business -- can be successful AND do business well! (not an either/or proposition).
Even beyond individual skills, there’s a bigger issue: what happens to innovation if AI users become passive consumers of machine-generated knowledge instead of active thinkers?
the true danger is a societal standstill where human progress altogether grinds to a halt.
If navigation apps weaken our spatial awareness and autopilot dulls a pilot’s situational awareness, what happens when AI starts handling intellectual tasks – writing reports, solving math problems, synthesising research?
Studies show that heavy GPS users have less activity in the mapping center
Ay, lord, she will become thy bed, I warrant, 1485 115 And bring thee forth brave brood.
We're all very sympathetic to Caliban, but he does attempt to use Miranda as a bargaining chip here, specifically selling her out for sexual purposes to Stephano. Its interesting that Miranda is made a sexual object by Caliban and Prospero, who hates Caliban for his attempted rape of her. Ferdinand isn't sexless, but is far less threatening as a white guy and prince. Prosper approves of him for those reasons, as well as the fact that he's in control, ]since he wants Ferdinand to fall in love with Miranda so he can exploit their courtship for power.
The Buddhist tradition of gSang ba chos lugs traces the origin of the first Tibetan King to Indian kings of Shakya lineage of Suryavamsa.
paragraph on Tibetan Buddhist theories on Nyatri
the Bon tradition here talks about the King coming from the Gods of thirtythird stages of heaven. A common Bon theory of the creation of the universe and the origin of the Bonpo gods by Phya Yekhen Chenpo [Tib:Phyva ye mkhyen chen po] have been narrated. There are two golden and two turquoise flowers, whereas in other sources, there is an account of a cosmic egg. Nyatri Tsanpo has been shown as the great-grandson of Bon god Yablha Daldrug residing in thirteenth stages of heaven. His father Khri bar gyi bdun tshig was sent to the land of rMu where he lived with the eldest daughter Dre rmu dre tsan mo of the Lord of rMu and Nyatri Tsanpo was born. Nyatri Tsanpo descended to the Mount Lha ri gyang tho to become the king of Tibet. He built the fort Yun bu bla sgang, defeated the king of Sumpa shang and took over the twelve regions of Tibet.
Bon theory of where Nyatri came from
Yang gsang the' u rang lugs means ultra-secret tradition of theurang [Tib: The'u rang] origin is that the king was said to be of Theurang [Goblin race] from sPu region of Tibet.
last theory says that Nyatri came from a goblin race
Tibetan scholars and historians have broadly categorized these theories on the basis of three traditional accounts: bsGrags pa bon lugs, gSang ba chos lugs and Yang gsang The'u rang lugs
these are the three theories made Tibetan scholars
gSang ba chos lugs means Secret Buddhist tradition and the origin of the king was attributed to the Shakya lineage of Indian kings and Mahabharata epic.
Secret Buddhist tradition attribute the king to Shakya lineage of Indian kings and Mahabharata epic
. bsGrags pa bon lugs means Bon tradition. It proclaims that the origin of Nyatri Tsanpo is traced to the genealogy of native Bon god Yablha Daldrug
Bon tradition says he came from the native Bon god Yablha Daldrug
They can be matched using an algorithm that often takes just fractions of a second to analyze millions of prints
Finger prints according to an algorithm
algorithm is technically a formally specified set of instructions used to analyze data and automate decisions.
Defining algorithm
big data is a data environment made possible by the mass digitization of information7Close and associated with the use of advanced analytics, including network analysis and machine learning algorithms.
Definition of big data for the article