Topic和Direct、Fanout匹配解析
107 Matching Annotations
- Dec 2022
-
blog.51cto.com blog.51cto.com
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
RabbitMQ 日志的初学者指南—如何查看、定位和分析日志
Tags
Annotators
URL
-
-
blog.apporc.org blog.apporc.org
-
RabbitMQ: 开启消息历史记录
-
-
www.51cto.com www.51cto.com
-
RabbitMQ是如何确定消息是否投递到队列中的
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
Rabbitmq消息确认机制,看完再也不怕Rabbitmq消息丢失了
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
Springboot中使用ConfirmCallback和ReturnCallback
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
RabbitTemplate的 发布确认 和 事务
Tags
Annotators
URL
-
-
www.yanzuoguang.com www.yanzuoguang.com
-
解决使用RabbitTemplate操作RabbitMQ,发生The channelMax limit is reached. Try later.问题
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
【RabbitMQ-9】自定义配置线程池(线程池资源不足-MQ初始化队列&&MQ动态扩容影响)
Tags
Annotators
URL
-
-
-
springboot整合rabbitmq和ThreadPool实现异步调用
Tags
Annotators
URL
-
-
www.cnblogs.com www.cnblogs.com
-
springboot 整合RabbitMQ yml配置文件配置交换机 队列信息
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
分布式事务之rabbitmq肉身实战
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
rabbitmq 怎么实现多个消费者同时接收一个队列的消息?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
RabbitMQ,ZeroMQ,Kafka 是一个层级的东西吗?相互之间有哪些优缺点?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
RabbitMQ在国内为什么没有那么流行?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
消息队列的使用场景是怎样的?
-
-
www.zhihu.com www.zhihu.com
-
学习哪个消息队列和 RPC 框架比较好呢?
-
- Aug 2022
-
mp.weixin.qq.com mp.weixin.qq.com消息队列设计精要3
-
顺序消息
顺序消息
-
长事务死锁等各种风险
-
只需要发布一个产品ID变更的通知,由下游系统来处理,可能更为合理
下游系统再去重新拉取上游数据。类似折上折活动数据更新解耦问题
Tags
Annotators
URL
-
-
mp.weixin.qq.com mp.weixin.qq.com
-
信息采集处理
生产快于消费,类似于日志收集
Tags
Annotators
URL
-
-
zhuanlan.zhihu.com zhuanlan.zhihu.com
-
Interface ApplicationContextAware 和 InitializingBean来获取我们在Configuration class中声明的exchange, queue, binding beans并调用channel的相应方法来声明
源码分析
Tags
Annotators
URL
-
-
help.aliyun.com help.aliyun.com
-
BasicRecover
重放unack的消息
-
消息重试
服务器端重试机制
Tags
Annotators
URL
-
-
www.cloudamqp.com www.cloudamqp.com
-
for the fastest possible throughput, manual acks should be disabled.
-
-
www.jianshu.com www.jianshu.com
-
retry只能在自动ack模式下使用。如果一定要在手动ack模式下使用retry功能,需保证消息能在有限次重试过程中可以重试成功,否则超过重试次数,又没办法执行ack或者nack,消息就会一直处于unack,并不会转发到死信队列
manul模式下重试可能还有bug:
recover与manual模式也有关系(是否是bug、按理manul不能被自动ack/reject)
重试机制下: 1. 默认情况,manual模式的消息会最终处于unack状态; 1. ImmediateRequeueMessageRecoverer,manual消息会被重新requeue; 1. RejectAndDontRequeueRecoverer,manual模式的消息会最终处于unack状态;
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
-
#onMessage() from ChannelAwareMessageListener class. Then you can do it this way
新的扩展点,manual也可以不用手工确认
-
-
cloud.tencent.com cloud.tencent.com
-
跟rabbitmq比的优势:
- 消息回溯
- 有push/pull模型
- 简化了direct、topic模式(可以只有topic,没有queue)
- raft优化,可用性提高
- 性能优化
- 有可见性概念、简化了消费者确认模型
- 可以批量处理
-
可从队列删除 Message A,以避免一旦取出消息隐藏时长过期后该消息被再次接受并处理
需要主动删除消息
Tags
Annotators
URL
-
-
cloud.tencent.com cloud.tencent.com
-
跟rabbitmq比的优势:
- 消息回溯
- 有push/pull模型
- 简化了direct、topic模式(可以只有topic,没有queue)
- raft优化,可用性提高
- 性能优化
- 有可见性概念
-
长轮询
阻塞
-
采取 Pull 的方式问题就简单了许多,由于 Consumer 是主动到服务端拉取数据,此时只需要降低自己访问频率即可。举例:如前端是 flume 等日志收集业务,不断向 CMQ 生产消息,CMQ 向后端投递,后端业务如数据分析等业务,效率可能低于生产者。
pull适用于日志分析等实时性不高的、吞吐量大的场景
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
auto默认的重试机制中,messageReCoverer为设置消息ack状态(即正常确认状态)
-
MessageReCoverer
recover与manul模式也有关系(是否是bug、按理manul不能被自动ack/reject)
重试机制下: 1. 默认情况,manul模式的消息会最终处于unack状态; 1. ImmediateRequeueMessageRecoverer,manul消息会被重新requeue; 1. RejectAndDontRequeueRecoverer,manul模式的消息会最终处于unack状态;
-
五次重试后,消费处于一个未被确认的状态。因为需要你手动 ack!下次服务重启的时候,会继续消费这条消息。
- manul模式下,如果没有手工ack/reject,服务器治不会将消息从unack状态变为其他状态(比如抛出异常)。
- auto模式正常情况下(即包括抛出异常情况下,除非出现故障)会将消息设置为ack/reject状态。
-
仅仅是消费者内部进行了重试,换句话说就是重试跟mq没有任何关系。上述消费者代码不能添加try{}catch(){},一旦捕获了异常,在自动 ack 模式下,就相当于消息正确处理了,消息直接被确认掉了,不会触发重试的。
如果没有异常,消费者也不会进行重试。只有抛出异常,消费者才会进行重试
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
它会根据方法的执行情况来决定是否确认还是拒绝
重试机制会有单独的recoverer,优先级高于默认的确认机制
-
AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且 requeue = false(不重新入队列)
auto模式下,可以用这个异常来控制消息进入死信队列
-
则消息会被拒绝,且 requeue = true(如果此时只有一个消费者监听该队列,则有发生死循环的风险,多消费端也会造成资源的极大浪费,这个在开发过程中一定要避免的)。可以通过 setDefaultRequeueRejected(默认是true)去设置
在开启重试的情况下,默认变成ack。(即不会重新入列),设置不同的recoverer,会有不同的表现:比如 1. RejectAndDontRequeueRecoverer即nack,且requue为false。 1. ImmediateRequeueMessageRecoverer即nack,且requue为true。
-
channel.basicNack 与 channel.basicReject 的区别在于basicNack可以批量拒绝多条消息,而basicReject一次只能拒绝一条消息。
比当前消息的delivertag数更小的消息都会被拒绝
-
如果某个服务忘记确认 ACK 了,则 RabbitMQ 不会再发送此消息数据给它,只要程序还在运行,没确认的消息就一直是 Unacked 状态,无法被 RabbitMQ 重新投递。
即unack的消息是blocked状态 如果connect断开,unack消息会被释放,则消息会被服务器重新投递
-
抛出异常
如果抛出异常,且设置了重试机制,消费者会在客户端自动进行重试(即不通过rabbitmq服务器)
-
requeue:被拒绝的是否重新入队列
默认不会重新进入队列, 但basicNack不会造成message在web界面被呈现unacked状态。只有发生异常的消息会在web界面变为unacked状态
-
broker回传给生产者的确认消息中deliver-tag域包含了确认消息的序列号,此外broker也可以设置basic.ack的multiple域,表示到这个序列号之前的所有消息都已经得到了处理。
事务消息中有用
-
-
juejin.cn juejin.cn
-
对象内部只有一个 id 属性,用来表示当前消息的唯一性
数据是自定义的
-
-
juejin.cn juejin.cn
-
:队列名称
应该是路由key(只是路由key和queue的名称一致),背后隐含有个默认的exchange来路由发送数据
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
清除给定队列的消息。
不能清空unack的消息
-
-
www.jianshu.com www.jianshu.com
-
如果channel.basicNack(8, false, false);表示deliveryTag=8的消息处理失败且将该消息直接丢弃。
basicNack的requeue为false情况下,数据会被直接丢弃
-
-
www.csdn.net www.csdn.net
-
当consumer对消息进行ack以后就会将此消息移除,从而放入新的消息
如果是nack,且可重试,则重试完也会被移除
Tags
Annotators
URL
-
-
-
Jackson2JsonMessageConverter
如果传递的是string,需要加引号:(实际上是json解析的事情,jackson只认带引号的基本类型)
 如果是template中发送,则不用:
如果是template中发送,则不用:

-
-
www.jianshu.com www.jianshu.com
-
会触发: channel.basicNack(tag, false, true);, 这样会告诉rabbitmq该消息消费失败, 需要重新入队
重试次数跟max-attempts的配置有关,并且因为网络等原因,会导致重试次数高于设定次数, 例子:图中设置为2次,实际执行4次

-
可以看到, 虽然消息确实被消费了, 但是由于是手动确认模式, 而最后又没手动确认, 所以, 消息仍被rabbitmq保存
并且不会被重新requeue
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
CorrelationData correlationData = new CorrelationData(correlationDataId.toString());
不设置,是个空的
-
在需要使用消息的return机制时候,mandatory参数必须设置为true
- //常用的三个配置如下
- //1---设置手动应答(acknowledge-mode: manual)
- // 2---设置生产者消息发送的确认回调机制 ( #这个配置是保证提供者确保消息推送到交换机中,不管成不成功,都会回调
// publisher-confirm-type: correlated
// #保证交换机能把消息推送到队列中
// publisher-returns: true
// template:
// #以下是rabbitmqTemplate配置
// mandatory: true) * // 3---设置重试
-
-
stackoverflow.com stackoverflow.com
-
Routing key does not match but still message gets sent to queue
如果是延时队列,x-delayed-type: direct的模式下,也会出现
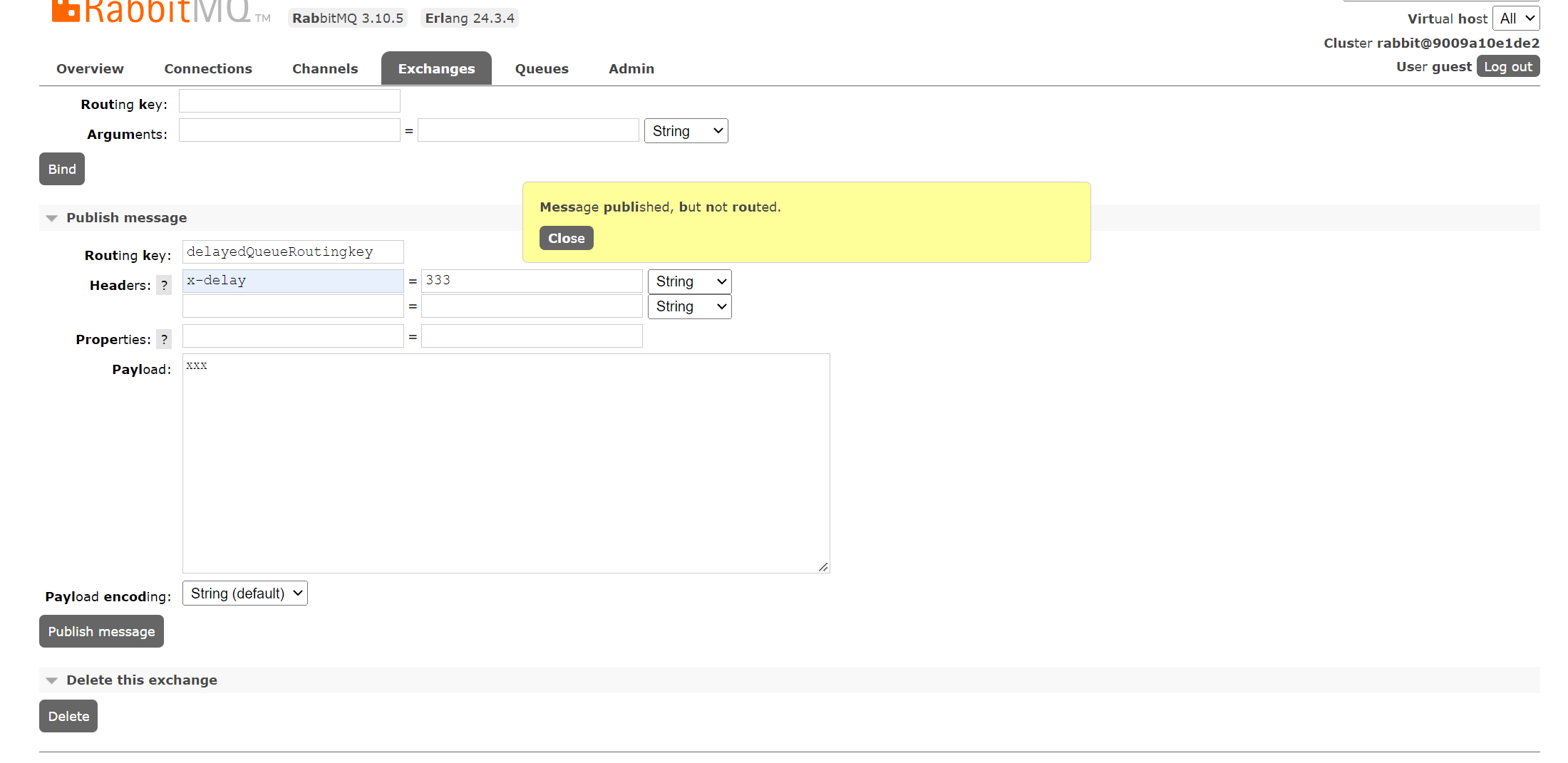
-
-
-
java.net.SocketException: Connection reset
设置vitual host
-
-
www.jianshu.com www.jianshu.com
-
Consumer utilisation
-
而 fanout 的广播模式不利于增加多个 Queue
采用的是轮训机制
Tags
Annotators
URL
-
-
www.cnblogs.com www.cnblogs.com
-
增加fetch值(这个根据我们的实际经验,lan内影响很有限)
提高吞吐量
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
消息消费速度变慢
prefetch将队列适当堆叠在消费者中
-
-
www.jianshu.com www.jianshu.com
-
使用@Input和@output都是用MessageChannel,这是不对的。@Output对MessageChannel,@Input对应SubscribableChannel
使用@Input和@output都是用MessageChannel,这是不对的。@Output对MessageChannel,@Input对应SubscribableChannel
-
最好不要自定义输入输出在同一个类里面。这样,如果我们只调用生产者发送消息。会导致提示Dispatcher has no subscribers for channel
-
会导致提示Dispatcher has no subscribers for channel。并且会让我们发送消息的次数莫名减少几次
Dispatcher has no subscribers for channel
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
第四个参数是autoDelete:true表示服务器不在使用这个队列是会自动删除它
自动删除
-
第三个参数是exclusive:true表示一个队列只能被一个消费者占有并消费
Tags
Annotators
URL
-
-
developer.51cto.com developer.51cto.com
-
MQ中间件与最终用户提供的应用程序代码(生产者/消费者)之间的桥梁
代码和配置中自定义设置的output或input binding
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
juejin.cn juejin.cn
-
The index is the index of the input or output binding. It is always 0 for typical single input/output function, so it’s only relevant for Functions with multiple input and output arguments.
序号的作用在哪里
-
StreamBridge模式
主动发送
-
函数式消息队列的步骤: * 声明supplier或者consumer(function name) * 配置中声明:且将destination设置为同一个,input亦可声明group: 1. * input - functionName+ -in- + index 1. * output - functionName + -out- + index * 配置声明function的definition:名字为function的name
-
output - <functionName> + -out- + <index>
output以-out-相连
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
@EnableBinding:将定义通道的接口绑定到某个 Bean 以便于我们可以通过该 Bean 操作通道进行发送和接收消息。
注解的参数是class,class实例化成一个bean,通过bean来操作消息
-
发送延迟消息非常简单,首先我们需要在生产者、消费者的配置文件中指定交换机的类型是延迟交换机
rabbitmq特有的机制
-
'''demoRoutingKey'''
用的是双引号:'"demoRoutingKey"'
Tags
Annotators
URL
-
-
github.com github.com
-
spring.cloud.stream.rocketmq.bindings..producer.sync=true
delay
-
-
stackoverflow.com stackoverflow.com
-
Since it's an expression, you'll need quotes: 'cities' or if the same producer sends to both, something like headers['whereToSendHeader'].
疑惑点
-
-
segmentfault.com segmentfault.com
-
安装插件后会生成新的Exchange类型x-delayed-message,该类型消息支持延迟投递机制,接收到消息后并未立即将消息投递至目标队列中,而是存储在mnesia(一个分布式数据系统)表中,检测消息延迟时间,如达到可投递时间时并将其通过x-delayed-type类型标记的交换机类型投递至目标队列。
Tags
Annotators
URL
-
-
www.liaoxuefeng.com www.liaoxuefeng.com
-
可以通过在类上监听队列,然后在类中写带有不同参数类型的方法,来接收不同的操作推送的信息
这种方式不行,找不到相应的messageconverter,会报错。具体原因:https://stackoverflow.com/questions/64029154/spring-amqp-rabbitmq-object-sent-as-one-type-gets-converted-to-map-in-listener
-
-
stackoverflow.com stackoverflow.com
-
It will work if the @RabbitListener is defined at the method level instead of the class level because we can infer the generic type from the listener method parameter.
@rabbitlistener在方法级别时,类型推导有用
-
-
juejin.cn juejin.cn
-
发布-订阅、消费组、分区
应该叫消费分区,(实际上就是queue)
-
实现延时队列的核心, 1. 安装插件 2,指明交换机为x-delayed-message。(指明x-delayed-type类型) 3,消息的header指明x-delay时间
-
rabbiimq延时插件
实现延时队列的核心, 1. 安装插件 2,指明交换机为x-delayed-message。(指明x-delayed-type类型) 3,消息的header指明x-delay时间
-
args.put("x-delayed-type", "direct");
路由type
-
编写配置类
连接问题导致无法创建队列
-
两者中较小的值,即队列无消费者连接的消息过期时间,或者消息在队列中一直未被消费的过期时间
队列或者消息的较小值被作为消息的真正的存活时间
Tags
Annotators
URL
-
-
-
我们看到两个消费者都收到了消息
每个消费者实例都产生一个匿名的queue
-
创建一个消费者组
实际上是将两个消费者实例绑定同一个queue
-
我们需要监听之前创建的通道greetingChannel。让我们为它创建一个绑定
如果消费者和生产者在同一个实例中,会优先走本地调用,不会产生队列消息。消费者能正常接收mq消息

-
使用SubscribableChannel和@Input注解连接到greetingChannel,消息数据将被推送这里
这里怎么让rabbitmq创建匿名的queue的
-
-
blog.csdn.net blog.csdn.net
-
发现是给用户授予了角色,只能登录控制台,但是没有给读写以及管理队列的权限,通过控制台admin按钮查看
rabbitmq的virtual host有权限配置
-
-
fangjian0423.github.io fangjian0423.github.io
-
真正地消费/处理消息
-
UnicastingDispatcher,必然也会存在广播的消息分发器,那就是 BroadcastingDispatcher,它被 PublishSubscribeChannel 这个消息通道所使用。广播消息分发器会把消息分发给所有的 MessageHandler
-
黄色部分涉及到各消息中间件的 Binder 实现以及 MQ 基本的订阅发布功能
重点
-
-
segmentfault.com segmentfault.com
-
RabbitMQ的基因中没有延时队列这回事,它不能直接指定一个队列类型为延时队列,然后去延时处理,但是经过上面两节的铺垫,我们可以将TTL+DLX相结合,这就能组成一个延时队列。
现在rabbitmq有延时队列插件可以实现延时队列功能 https://juejin.cn/post/6844904163168485383
Tags
Annotators
URL
-
-
www.rabbitmq.com www.rabbitmq.com
-
The management plugin is included in the RabbitMQ distribution. Like any other plugin, it must be enabled before it can be used. That's done using rabbitmq-plugins:
rabbitmq的web界面需要先enable
-
-
zhuanlan.zhihu.com zhuanlan.zhihu.com
-
创建一个消费者,绑定消费队列及死信交换机,交换机默认为direct模型,死信交换机也是,arguments绑定死信交换机和key。(注解支持的具体参数文末会附上)
同一个queue也可以绑定不同的routingKey
-
如果配置了死信队列,它将被重新publish到死信交换机,死信交换机将死信投递到一个队列上,这个队列就是死信队列
在队列上配置死信队列
-
key = {"info","error","warning"}
同一个queue也可以绑定不同的routingKey
Tags
Annotators
URL
-
-
developer.51cto.com developer.51cto.com
-
集群消费
rabbitmq的topic模式、或者使用direct 同一个key加不同队列
-
广播消费
fanout
-
它采用pull机制,而 不是一般MQ的push模型
rabbitmq是push模型,kafka是pull模型
-
消息队列既可以做管子,也可以当做池子
消息短暂存储
-
RabbitMQ很优秀,但RabbitMQ对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降
消息堆积会对性能有不小影响
-
搜索团队从kafka直接消费消息
目前主流的操作方式
-
但第二个问题却让我束手无措
spring event也可以
Tags
Annotators
URL
-
-
-
都是可以根据 RoutingKey 把消息路由到不同的队列
direct模式下,同一个routingkey可以绑定不同的queue,这样路由器可以分别发送同样的消息到相应的两个queue中
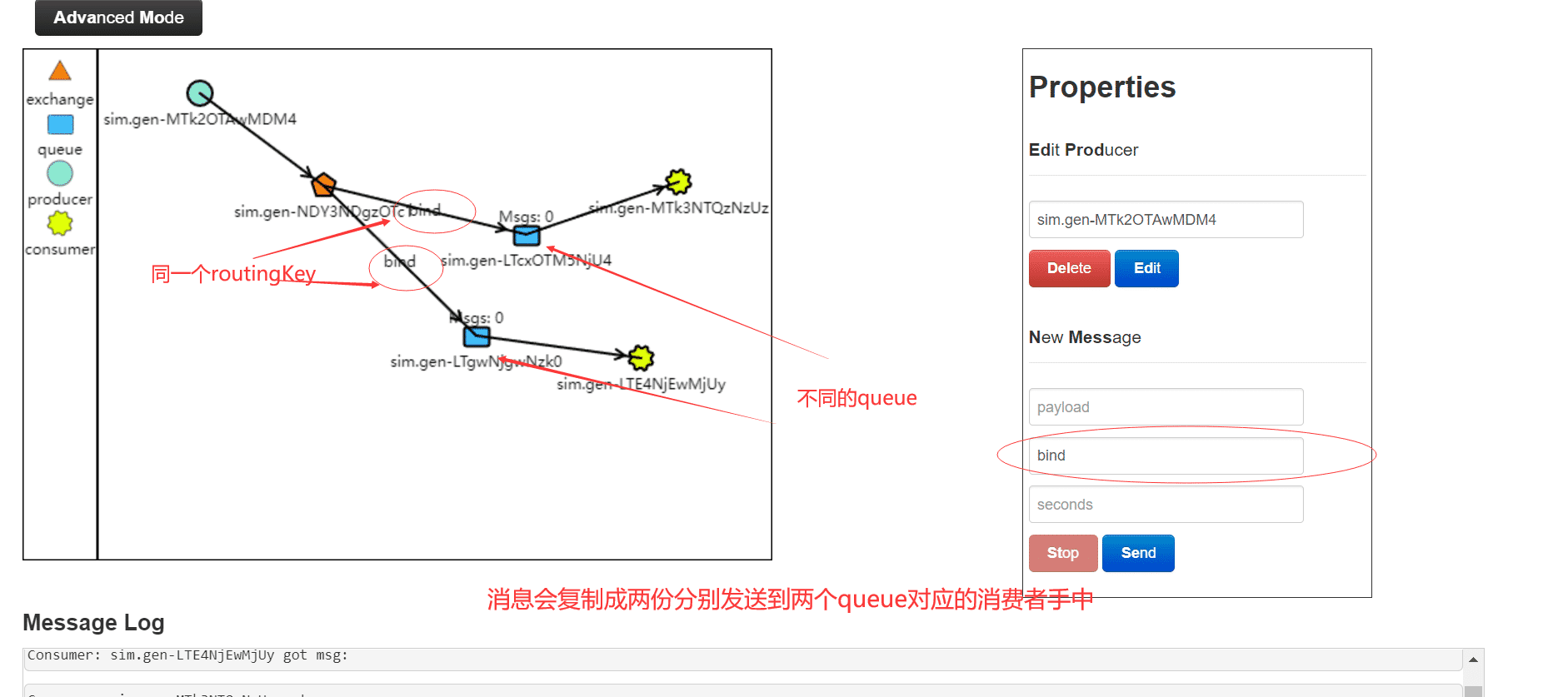
-
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割
消息队列
-