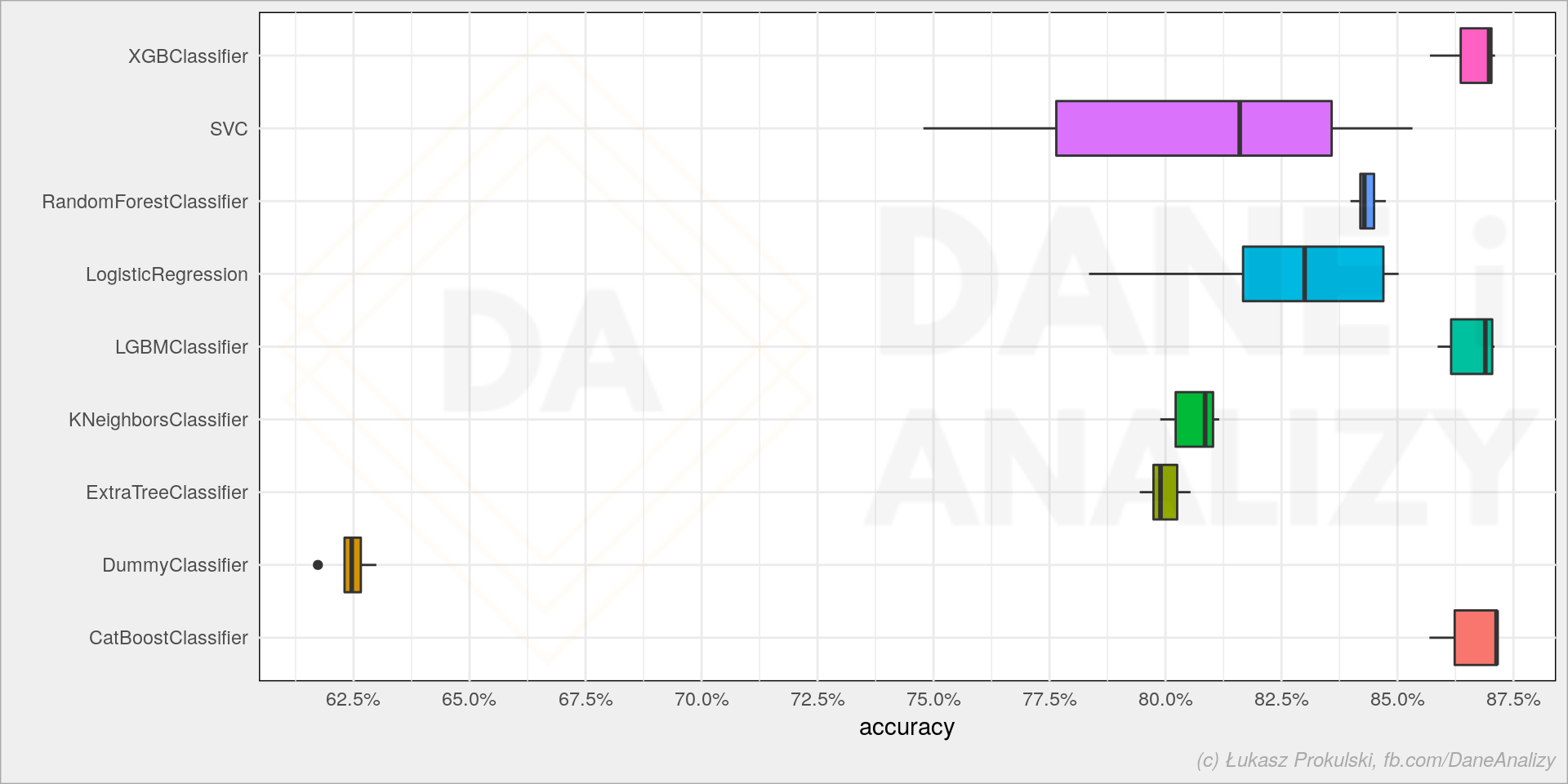
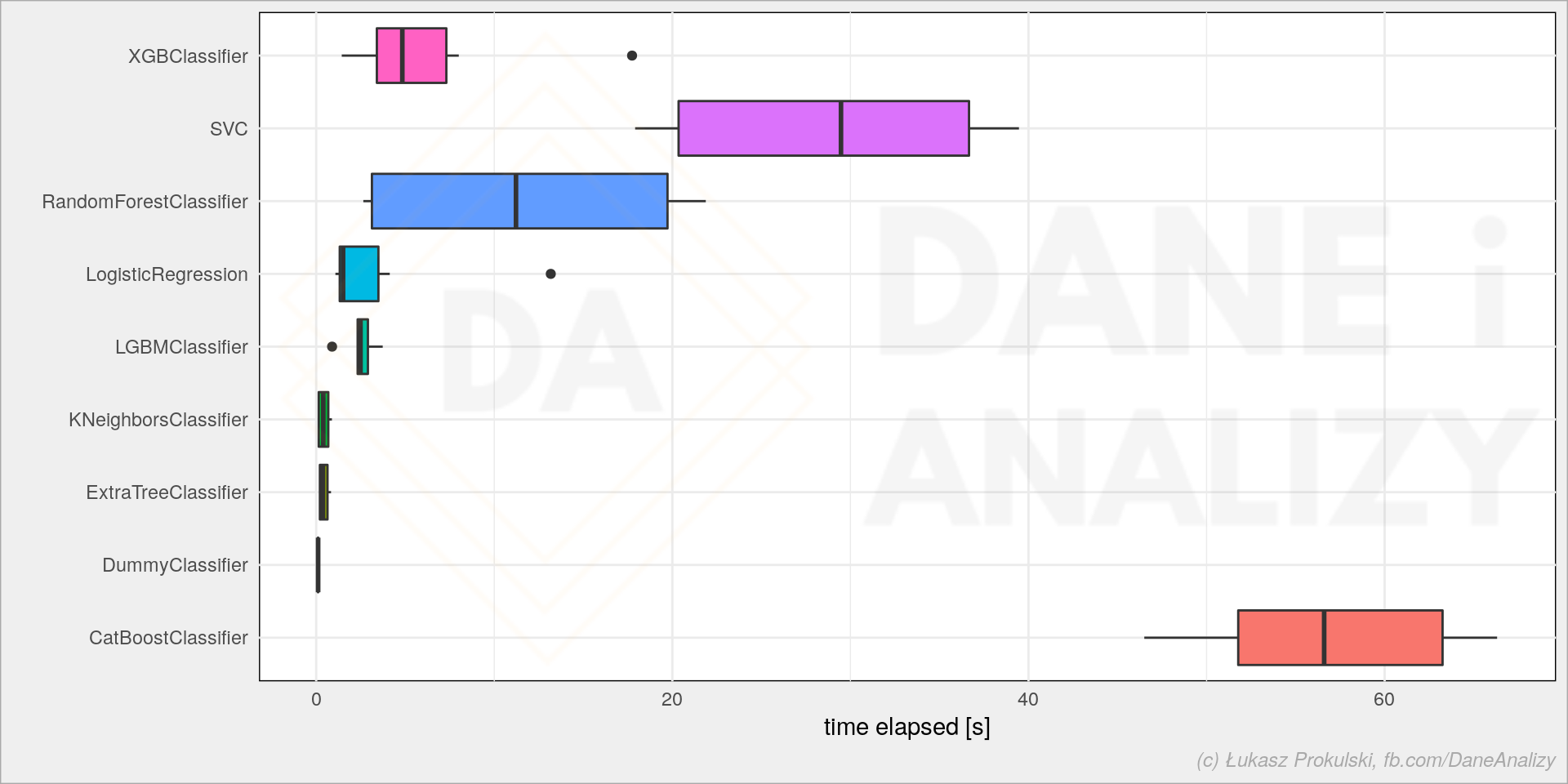
E) model = skl.LinearRegression().fit(x, y)
O LinearRegression() é usado para modelar a relação entre as variáveis de entrada e a variável de saída, e para fazer previsões sobre a saída em novos valores de entrada. O fit() encontra os parâmetros do modelo que melhor se ajustam aos dados de treinamento.