it allows each new key to be given a default value based on the type of dictionary being created
Difference between defaultdict and dict
it allows each new key to be given a default value based on the type of dictionary being created
Difference between defaultdict and dict
Memoization can be achieved through Python decorators
Example of memoization in Python:
import timeit
def memoize_fib(func):
cache = {}
def inner(arg):
if arg not in cache:
cache[arg] = func(arg)
return cache[arg]
return inner
def fib(num):
if num == 0:
return 0
elif num == 1:
return 1
else:
return fib(num-1) + fib(num-2)
fib = memoize_fib(fib)
print(timeit.timeit('fib(30)', globals=globals(), number=1))
print(timeit.timeit('fib(30)', globals=globals(), number=1))
print(timeit.timeit('fib(30)', globals=globals(), number=1))
Output:
4.9035000301955733e-05
1.374000021314714e-06
1.2790005712304264e-06
A deep copy refers to cloning an object. When we use the = operator, we are not cloning the object; instead, we reference our variable to the same object (a.k.a. shallow copy).
Difference between a shallow copy (=) and a deep copy:

Python 2 is entrenched in the software landscape to the point that co-dependency between several softwares makes it almost impossible to make the shift.
Shifting from Python 2 to 3 isn't always straight to the point
The @property decorator allows a function to be accessed like an attribute.
@property decorator
var = true_val if condition else false_val
Example of a ternary operator (one-line version of if-else):
to_check = 6
msg = "Even" if to_check%2 == 0 else "Odd"
print(msg)
Usual if-else:
msg = ""
if(to_check%2 == 0):
msg = "Even"
else:
msg = "Odd"
print(msg)
This method is automatically called to allocate memory when a new object/ instance of a class is created.
__init__ method in Python (which essentially all classes have)
decorator is a design pattern in Python that allows a user to add new functionality to an existing object without modifying its structure
Decorators
The philosophy behind Flask is that it gives only the components you need to build an app so that you have the flexibility and control. In other words, it’s un-opinionated. Some features it offers are a build-int dev server, Restful request dispatching, Http request handling, and much more.
Flask isn't as full of features as Django (which makes him lighter), but it still offers:
The only difference is that range returns a Python list object and xrange returns an xrange object. This means that xrange doesn’t actually generate a static list at run-time like range does.
Difference between range() and xrange()
NumPy is not just more efficient; it is also more convenient. You get a lot of vector and matrix operations for free, which sometimes allow one to avoid unnecessary work. And they are also efficiently implemented.
Main advantage of NumPy arrays over (nested) Python lists
process of retrieving original Python objects from the stored string representation
Unpickling
Pickle module accepts any Python object and converts it into a string representation and dumps it into a file by using dump function
Pickling
The beauty of lambda functions lies in the fact that they return function objects. This makes them helpful when used with functions like map or filter which require function objects as arguments.
When to use lambdas
In Python, the term monkey patch only refers to dynamic modifications of a class or module at run-time.
Monkey patching in Python
Python has a multi-threading package but if you want to multi-thread to speed your code up, then it’s usually not a good idea to use it. Python has a construct called the Global Interpreter Lock (GIL). The GIL makes sure that only one of your ‘threads’ can execute at any one time. A thread acquires the GIL, does a little work, then passes the GIL onto the next thread.
Multi-threading is available in Python but it;s often not a good idea
the only meditation I have EVER found effective in my life. 1:19:57 Intro and explanation + 1:27:51 Meditation start
Meditation with triphasic breathing (you won't fight with your thoughts)
It focuses on 6 steps (feel a stop between each phase):
Beginning:
Repeat:
Ending:
Video material
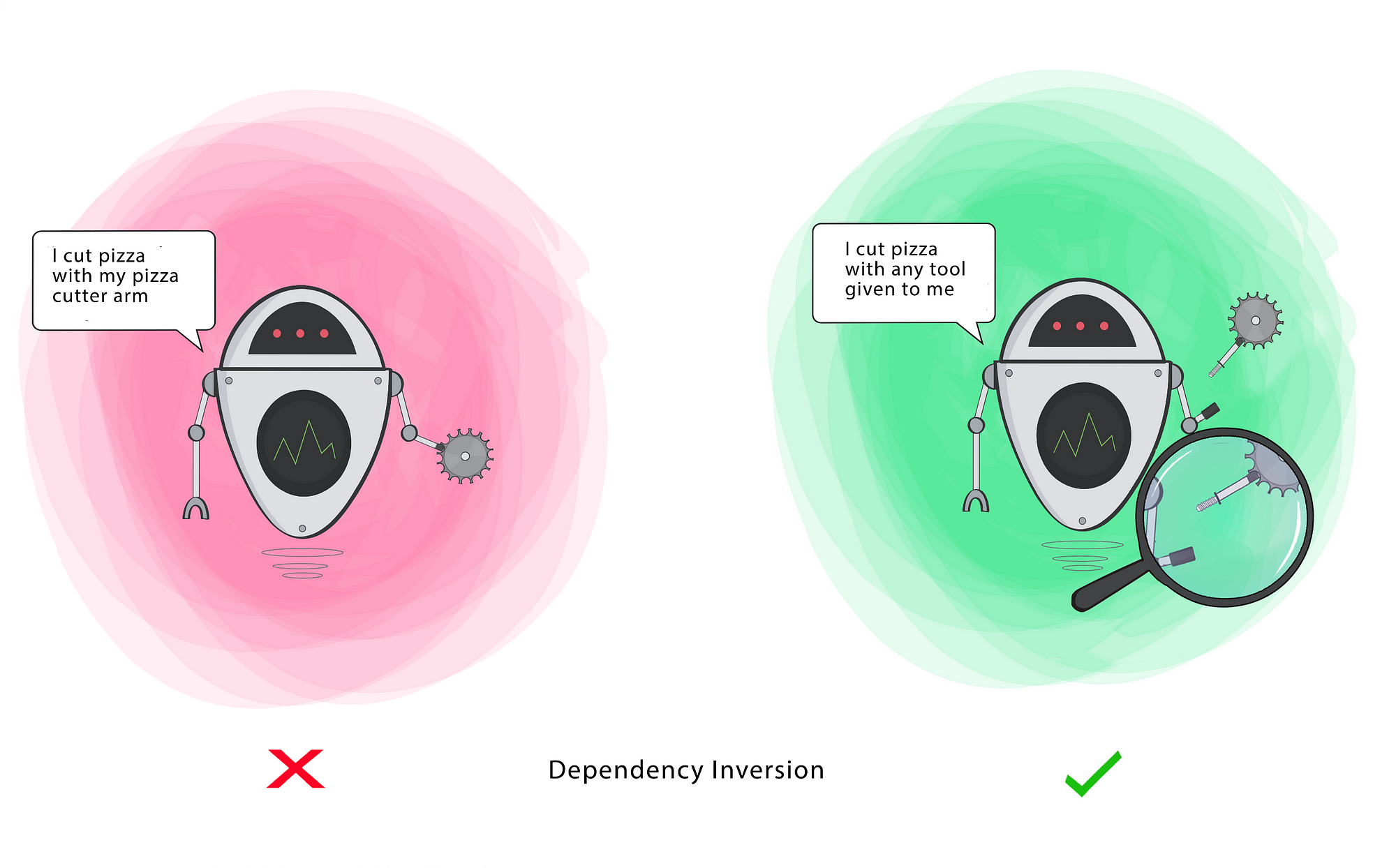
- High-level modules should not depend on low-level modules. Both should depend on the abstraction.- Abstractions should not depend on details. Details should depend on abstractions.
SOLI(D)
Dependency Inversion
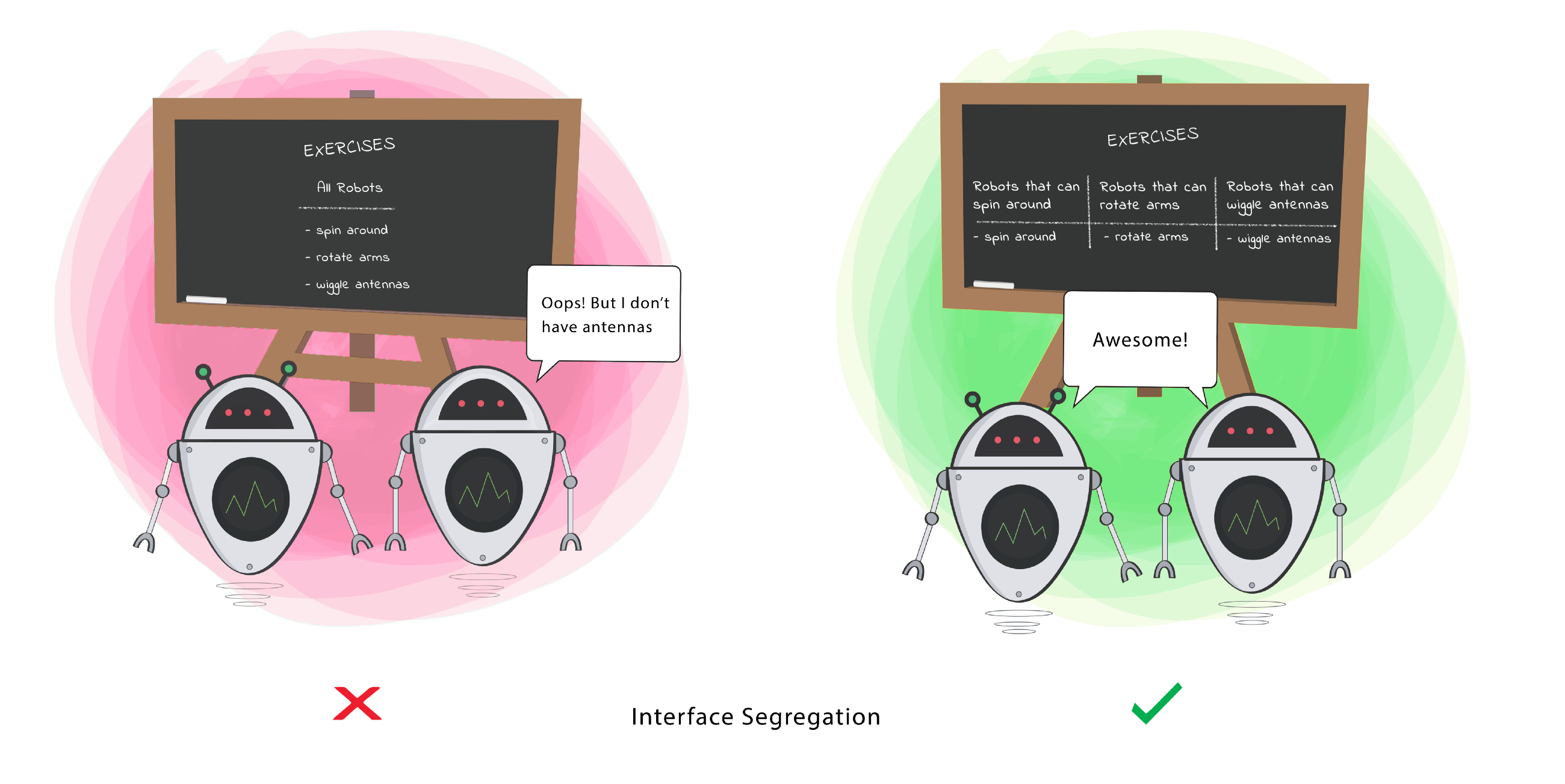
Clients should not be forced to depend on methods that they do not use.
SOL(I)D
Interface Segregation
If S is a subtype of T, then objects of type T in a program may be replaced with objects of type S without altering any of the desirable properties of that program.
SO(L)ID
Liskov Substitution

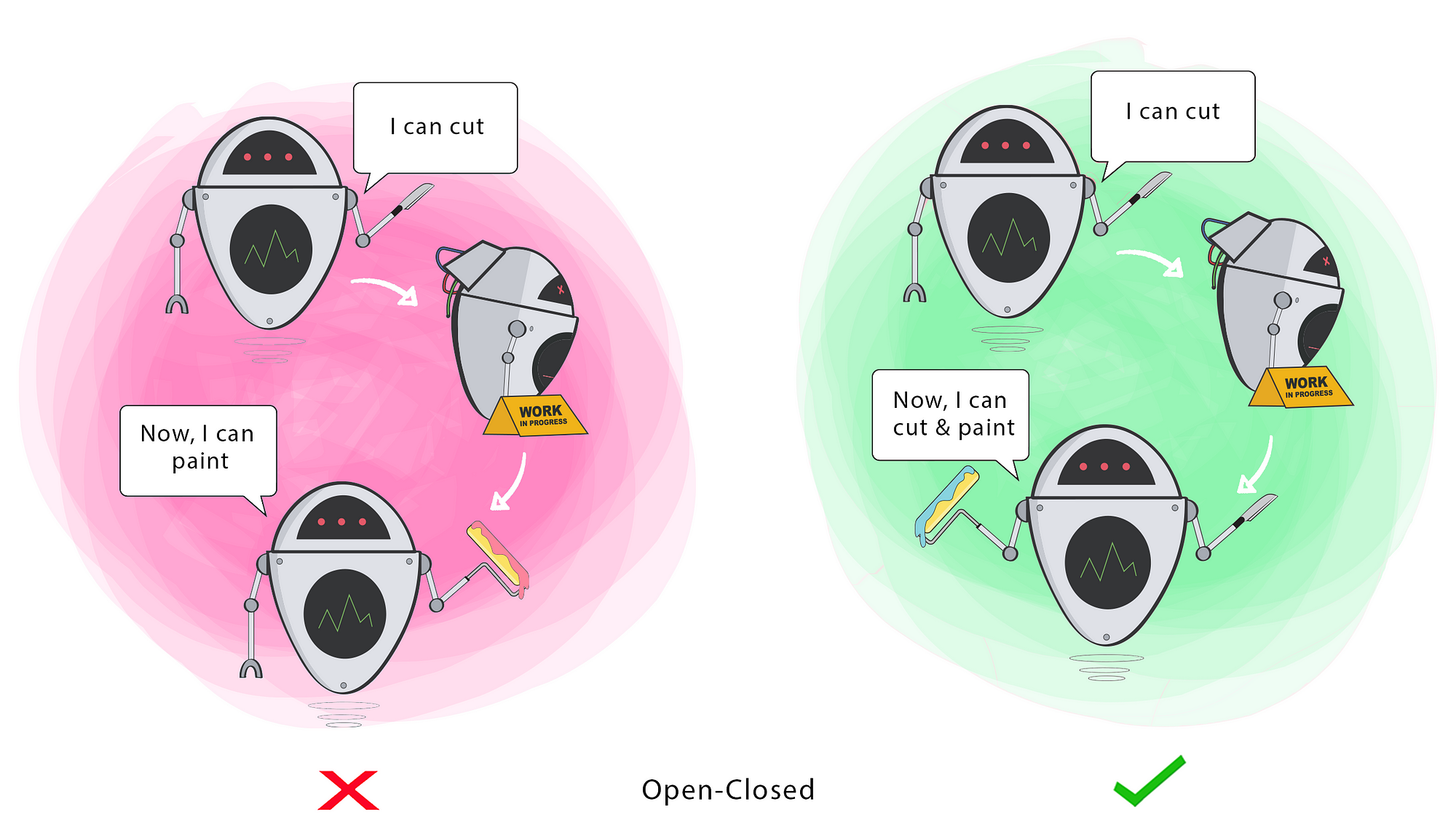
Classes should be open for extension, but closed for modification
S(O)LID
Open-Closed
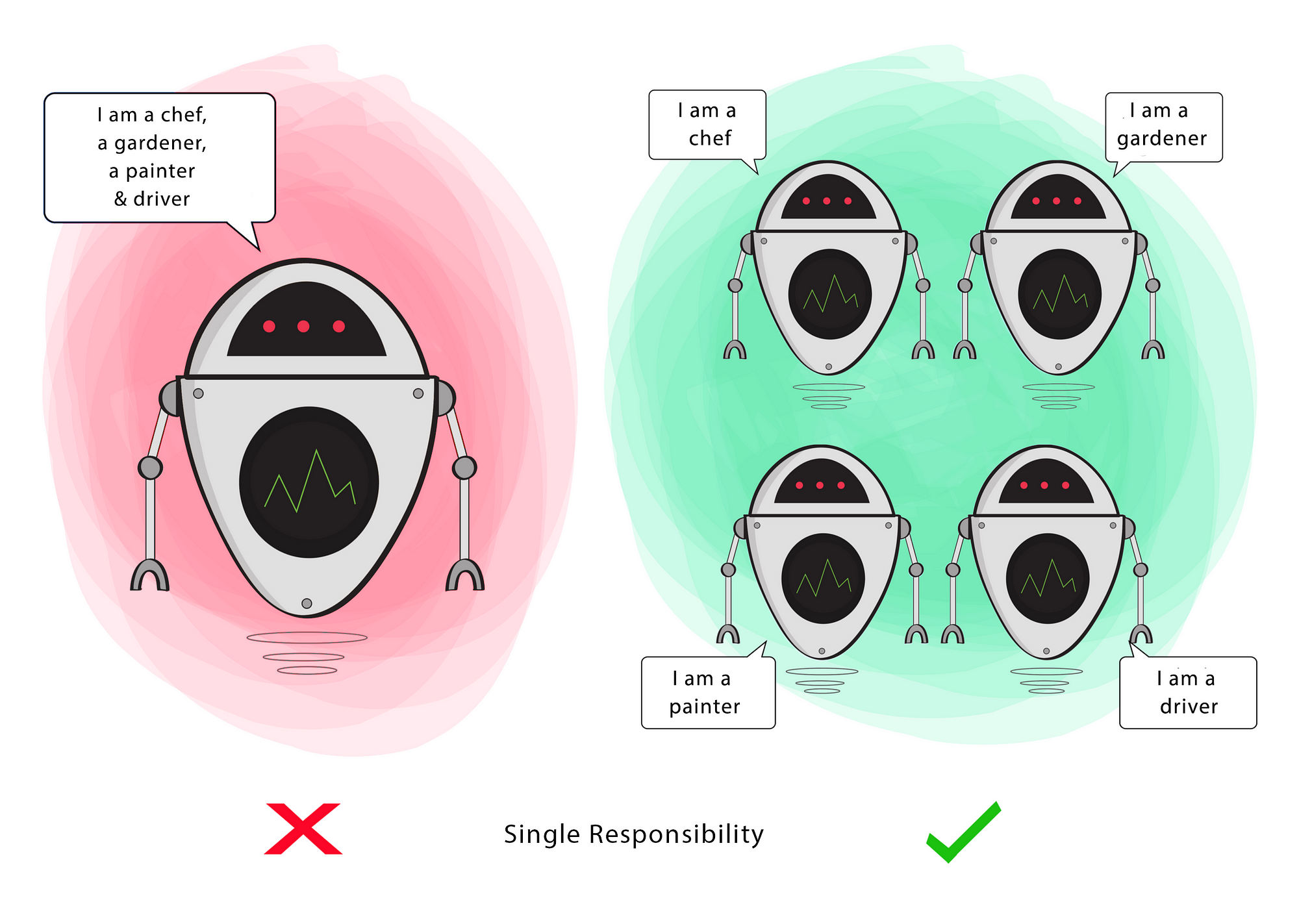
A class should have a single responsibility
(S)OLID
Single Responsibility
Alternatively, think about the decision in different timelines. Ask yourself: What will be the consequences of this decision in 10 minutes? 10 months? 10 years?
Another way of examining the second order of decision's consequences
Consider a decision you have to make. Start by looking at the most immediate effects of making this decision – the first order. Then for each of the effect ask yourself: "And then what?"
The way to examine the second order of decision's consequences
I've found that the most underrated problem solving tool is simply typing out my thought process.I used to be the type who asked a lot of questions until I realized that formulating the question was often more important than getting the answer.
You're asking a lot of questions? It might be also a sign of formulating/shaping your decisions
Amazon Machine Learning Deprecated. Use SageMaker instead.
Instead of Amazon Machine Learning use Amazon SageMaker
The MRI results showed that people for whom this effect was the strongest--those whose exposure to diverse experiences was more strongly associated with positive feeling ("affect")--exhibited greater correlation between brain activity in the hippocampus and the striatum. These are brain regions that are associated, respectively, with the processing of novelty and reward-- beneficial or subjectively positive experiences.
The interface is slightly less polished (and, unfortunately, I experience a delay between opening it and getting a chart), but the tracking works. Since it is in Vue I love, one day I might modify it to my needs.
Comparing ActivityWatch to RescueTime
It is a modern-day “memento mori”
Mortality - New Tab (browser extension)
With Intention I:know how much of my time is spent on distractions,decide how much time I need,I see the countdown (so I know if I need to wrap-up a reply, or if it makes sense to start writing a new one),it automatically blocks these sites,yet, it distinguishes between “normal use” of YouTube and e.g. using it for creating a workshop on deep learning (looking for video abstract of recent papers).
Intention is well recommended by Piotr Migdał for your productivity. More than toggl or RescueTime.
There are a few plugins (e.g. ColdTurkey) that are “too nuclear”. Being halted in the middle of writing a reply (on Facebook or Hacker News), with no prior warning, left me disturbed.
ColdTurkey is quite harsh in terms of making you more productive
Hot Reloading refers to the ability to automatically update a running web application when changes are made to the application’s code.
Hot Reloading is what provides a great experience with updating your Dash code inside the Jupyter Notebooks
JupyterDash supports three approaches to displaying a Dash application during interactive development.
3 display modes of Dash using Jupyter Notebooks:
# Run app and display result inline in the notebookapp.run_server(mode='inline')
Moreover, you can display your Dash result inside a Jupyter Notebook using IPython.display.IFrame with this line:
app.run_server(mode='inline')
If running the server blocks the main thread, then it’s not possible to execute additional code cells without manually interrupting the execution of the kernel.JupyterDash resolves this problem by executing the Flask development server in a background thread. This leaves the main execution thread available for additional calculations. When a request is made to serve a new version of the application on the same port, the currently running application is automatically shut down first. This makes is possible to quickly update a running application by simply re-executing the notebook cells that define it.
How Dash can run inside Jupyter Notebooks
You can also try it out, right in your browser, with binder.
Dash can be tried out inside a Jupyter Notebook right in your browser using binder.
Then, copy any Dash example into a Jupyter notebook cell and replace the dash.Dash class with the jupyter_dash.JupyterDash class.
To use Dash in Jupyter Notebooks, you have to import:
from jupyter_dash import JupyterDash
instead of:
import dash
Therefore, all the imports could look like that for a typical Dash app inside a Jupyter Notebook:
import plotly.express as px
from jupyter_dash import JupyterDash
import dash_core_components as dcc
import dash_html_components as html
from dash.dependencies import Input, Output
sci-hub is a service that lets you access research papers for free. It’s not quuiiiiiiiiite legal, but buying papers is super expensive, like fifty dollars per paper. Not something I can afford, and I think the entire industry is evil anyway.
Good point on the research industry & Sci-Hub
So instead I have it open up Frink. If Frink is already open, it activates it. If it’s already active, it minimizes it. Much better UX.3
Great AutoHotkey (AHK) script to open any app:
toggle_app(app, location)
{
if WinExist(app)
{
if !WinActive(app)
{
WinActivate
}
else
{
WinMinimize
}
}
else if location != ""
{
Run, %location%
}
}
Launch_App2::toggle_app("Frink", "\Path\to\frink.jar")
My friends ask me if I think Google Cloud will catch up to its rivals. Not only do I think so — I’m positive five years down the road it will surpass them.
GCP more popular than AWS in 2025?
So if GCP is so much better, why so many more people use AWS?
Why so many people use AWS:
As I mentioned I think that AWS certainly offers a lot more features, configuration options and products than GCP does, and you may benefit from some of them. Also AWS releases products at a much faster speed.You can certainly do more with AWS, there is no contest here. If for example you need a truck with a server inside or a computer sent over to your office so you can dump your data inside and return it to Amazon, then AWS is for you. AWS also has more flexibility in terms of location of your data centres.
Advantages of AWS over GCP:
I would argue that there isn’t any other company on the planet that does scalability and global infrastructure better than Google (although CloudFlare definitely gives it a run for its money in some areas).
Scalability of Google's service is still #1
Both AWS and GCP are very secure and you will be okay as long as are not careless in your design. However GCP for me has an edge in the sense that everything is encrypted by default.
Encryption is set to default in GCP
I felt that performance was almost always better in GCP, for example copying from instances to buckets in GCP is INSANELY fast
Performance wise GCP also seems to outbeat AWS
AWS charges substantially more for their services than GCP does, but most people ignore the real high cost of using AWS, which is; expertise, time and manpower.
AWS is more costly, requires more time and manpower over GCP
GCP on the other hand has fewer products but the ones they have (at least in my experience) feel more complete and well integrated with the rest of the ecosystem
GCP has less but more effective products
GCP provides a smaller set of core primitives that are global and work well for lots of use cases. Pub/Sub is probably the best example I have for this. In AWS you have SQS, SNS, Amazon MQ, Kinesis Data Streams, Kinesis Data Firehose, DynamoDB Streams, and maybe another queueing service by the time you read this post. 2019 Update: Amazon has now released another streaming service: Amazon Managed Streaming Kafka.
Pub/Sub of GCP might be enough to replace most (all?) of the following Amazon products: SQS, SNS, Amazon MQ, Kinesis Data Streams, Kinesis Data Firehose, DynamoDB Streams, Amazon Managed Streaming Kafka
At the time of writing this, there are 169 AWS products compared to 90 in GCP.
AWS has more products than GCP but that's not necessarily good since some even nearly duplicate
Spinning an EKS cluster gives you essentially a brick. You have to spin your own nodes on the side and make sure they connect with the master, which a lot of work for you to do on top of the promise of “managed”
Managing Kubernetes in AWS (EKS) also isn't as effective as in GCP or GKE
You can forgive the documentation in AWS being a nightmare to navigate for being a mere reflection of the confusing mess that is trying to describe. Whenever you are trying to solve a simple problem far too often you end up drowning in reference pages, the experience is like asking for a glass of water and being hosed down with a fire hydrant.
Great documentation is contextual, not referential (like AWS's)
Jeff Bezos is an infamous micro-manager. He micro-manages every single pixel of Amazon’s retail site. He hired Larry Tesler, Apple’s Chief Scientist and probably the very most famous and respected human-computer interaction expert in the entire world, and then ignored every goddamn thing Larry said for three years until Larry finally — wisely — left the company. Larry would do these big usability studies and demonstrate beyond any shred of doubt that nobody can understand that frigging website, but Bezos just couldn’t let go of those pixels, all those millions of semantics-packed pixels on the landing page. They were like millions of his own precious children. So they’re all still there, and Larry is not.
Case why AWS doesn't look as it supposed to be
The AWS interface looks like it was designed by a lonesome alien living in an asteroid who once saw a documentary about humans clicking with a mouse. It is confusing, counterintuitive, messy and extremely overcrowded.
:)
After you login with your token you then need to create a script to give you a 12 hour session, and you need to do this every day, because there is no way to extend this.
One of the complications when we want to use AWS CLI with 2FA (not a case of GCP)
In GCP you have one master account/project that you can use to manage the rest of your projects, you log in with your company google account and then you can set permissions to any project however you want.
Setting up account permission to the projects in GCP is far better than in AWS
It’s not that AWS is harder to use than GCP, it’s that it is needlessly hard; a disjointed, sprawl of infrastructure primitives with poor cohesion between them.
AWS management isn't as straightforward as the one of GCP
So be careful running editing a bash script that may be currently executing. It could execute an invalid command, or do something very surprising.
Never modify a running bash command as it can execute something surprising
“If you are a non-college graduate man you have a less than 50/50 shot of ever being married in your life” – Andrew YangIn the 1970s and ‘80s, there were about 17 million manufacturing jobs in the USToday, there are about 12 million of those jobsMore women are graduating from college than men58% of college graduates in the US are women
Today, 40% of children are born to unmarried mothersBack in the 70s and 80s, it was only 15%
The most common method of preventing CSRF is by generating a secret random string, known as a CSRF token, on the server, and checking for that token when the client performs a write.
To completely defend the CSRF attack, one needs to generate a CSRF token
CORS relaxes the Same-Origin Policy (SOP), a critical security measure that prevents scripts on one site (e.g. the attacker’s site) from accessing sensitive data on another site (e.g. the Definitely Secure Bank portal). If something was protecting you from CSRF, it would be the SOP.
Thanks to Cross-Origin Resource Sharing (CORS), Same-Origin Policy (SOP) is being relaxed and CSRF is blocked from cross-origin reads, but not from writes (so POST is still effective but attacker cannot read the response)
Cross-Site Request Forgery is a web security exploit where an attacker induces a victim to perform an action they didn’t mean to. In this case, the attacker tricked you into unintentionally transferring them money.
Cross-Site Request Forgery (CSRF) attack example: sending cookies to the origin (bank site) even when the request originates from a different origin
This might be super basic, but... assume positive intent.Your parent is not your enemy. Your teacher is not your enemy. Your boss is not your enemy. The other team at work is not your enemy.
Idea that changed your life: assuming positive intent
We present results from technical experiments which reveal that WeChat communications conducted entirely among non-China-registered accounts are subject to pervasive content surveillance that was previously thought to be exclusively reserved for China-registered accounts.
WeChat not only tracks Chinese accounts
So write with a combination of short, medium, and long sentences. Create a sound that pleases the reader’s ear. Don’t just write words. Write music.”
Try writing fewer commas and using more periods. Make your sentences simpler, vary their lengths and your sentences will be like music
You can create estimation plots here at estimationstats.com, or with the DABEST packages which are available in R, Python, and Matlab.
You can create estimation plots with:
Relative to conventional plots, estimation plots offer five key benefits:
Estimation plots > bars-and-stars or boxplot & P.
They:
For comparisons between 3 or more groups that typically employ analysis of variance (ANOVA) methods, one can use the Cumming estimation plot, which can be considered a variant of the Gardner-Altman plot.
Cumming estimation plot

Efron developed the bias-corrected and accelerated bootstrap (BCa bootstrap) to account for the skew whilst obtaining the central 95% of the distribution.
Bias-corrected and accelerated bootstrap (BCa boostrap) deals with skewed sample distributions. However; it must be noted that it "may not give very accurate coverage in a small-sample non-parametric situation" (simply said, take caution with small datasets)
We can calculate the 95% CI of the mean difference by performing bootstrap resampling.
Bootstrap - simple but powerful technique that creates multiple resamples (with replacement) from a single set of observations, and computes the effect size of interest on each of these resamples. It can be used to determine the 95% CI (Confidence Interval).
We can use bootstrap resampling to obtain measure of precision and confidence about our estimate. It gives us 2 important benefits:
Bootstrap resampling can be used for such an example:

Computers can easily perform 5000 resamples:

Shown above is a Gardner-Altman estimation plot.
Gardner-Altman estimation plot shows all the relevant information:

Jitter plots avoid overlapping datapoints (i.e. datapoints with the same y-value) by adding a random factor to each point along the orthogonal x-axes.
Jitter plots displays all datapoints but it might not accurately depict the underlying distribution of the data:

Unfortunately, the boxplot still doesn't show all our data.
Boxplots may be better than barplots (they introduce medians, quartiles, minima and maxima), but still doesn't show all the information:

The barplot has several shortcomings, even though its use in academic journals is endemic.
Barplots are not the best choice for data visualisation:

Continuous Delivery of Deployment is about running as thorough checks as you can to catch issues on your code. Completeness of the checks is the most important factor. It is usually measured in terms code coverage or functional coverage of your tests. Catching errors early on prevents broken code to get deployed to any environment and saves the precious time of your test team.
Continuous Delivery of Deployment (quick summary)
Continuous Integration is a trade off between speed of feedback loop to developers and relevance of the checks your perform (build and test). No code that would impede the team progress should make it to the main branch.
Continuous Integration (quick summary)
A good CD build: Ensures that as many features as possible are working properly The faster the better, but it is not a matter of speed. A 30-60 minutes build is OK
Good CD build
A good CI build: Ensures no code that breaks basic stuff and prevents other team members to work is introduced to the main branch Is fast enough to provide feedback to developers within minutes to prevent context switching between tasks
Good CI build
The idea of Continuous Delivery is to prepare artefacts as close as possible from what you want to run in your environment. These can be jar or war files if you are working with Java, executables if you are working with .NET. These can also be folders of transpiled JS code or even Docker containers, whatever makes deploy shorter (i.e. you have pre built in advance as much as you can).
Idea of Continuous Delivery
Continuous Delivery is about being able to deploy any version of your code at all times. In practice it means the last or pre last version of your code.
Continous Delivery
Continuous Integration is not about tools. It is about working in small chunks and integrating your new code to the main branch and pulling frequently.
Continuous Integration is not about tools
The app should build and start Most critical features should be functional at all times (user signup/login journey and key business features) Common layers of the application that all the developers rely on, should be stable. This means unit tests on those parts.
Things to be checked by Continous Integration
Continuous Integration is all about preventing the main branch of being broken so your team is not stuck. That’s it. It is not about having all your tests green all the time and the main branch deployable to production at every commit.
Continuous Integration prevents other team members from wasting time through a pull of faulty code
If knowledge of one item makes it harder to remember another item, we have a case of memory interference.
Memory interference - once it happens you need to detect it and eliminate
Here again are the twenty rules of formulating knowledge.
If you see a word and immediately check it's translation, you'll hardly memorize it at all. If you try your best to recall what the word means before checking the translation, the chances of memorization are much better. It is much easier to memorize a word's meaning when you know how to pronounce it corretly, so get it right.
2 important tips for learning languages:
Somewhere between too hard and too easy, there’s a sweet-spot where reviews are challenging enough to hold your interest, but not so hard that it feels like torture. When the challenge of reviews is just right, you’ll actually get a sense of accomplishment and a little jolt of dopamine as you do them. Our brains actually enjoy challenges as long as they aren’t too hard or too easy. As I see it, this level of challenge is where you want to be.
The sweet spot is between 80 - 90% of right answers
Researchers have found that reviews are more effective when they’re difficult. That is, if you have to work at remembering a card, it’ll have a stronger effect on your memory. The harder a review is, the more it boosts your memory. This is called “desirable difficulty” in the literature.
Desirable difficulty
Kolejna zmienna - "Recency", czyli informacja o tym, jak dawno klient robił zakupy w sklepie.
To calculate RFM we need recency value. Firstly, we shall specify the most recent transaction as "today" and then to find the latest transaction of a specific client:
df['Recency'] = (today - df.InvoiceDate)/np.timedelta64(1,'D')
Calculating frequency and aggregating data of each client may be done with the groupby method:
abt = df.groupby(['CustomerID']).agg({'Recency':'min', 'MonetaryValue':'sum', 'InvoiceNo':'count'})
lastly, we can update the column names and display RFM data:
abt = df.groupby(['CustomerID']).agg({'Recency':'min', 'MonetaryValue':'sum', 'InvoiceNo':'count'})
abt.rename(columns = {'InvoiceNo':'Frequency'}, inplace = True)
abt = abt[['Recency', 'Frequency', 'MonetaryValue']]
abt.head()
Będę oceniać klientów kryteriami, jakie zakłada metoda RFM.
RFM is a method used for analyzing customer value:
In the RFM method we usually analyse only the last 12 months since this is the most relevant data of our products.
We also have other RFM variants:
Usuwam brakujące wartości w zmiennej "CustomerID".
Deleting rows where value is null:
df = df[~df.CustomerID.isnull()]
Assigning different data types to columns:
df['CustomerID'] = df.CustomerID.astype(int)
Deleting irrelevant columns:
df.drop(['Description', 'StockCode', 'Country'], axis = 1, inplace = True)
Sprawdzam braki danych.
Checking the % of missing data:
print(str(round(df.isnull().any(axis=1).sum()/df.shape[0]*100,2))+'% obserwacji zawiera braki w danych.')
Sample output:
24.93% obserwacji zawiera braki w danych.
Buduję prosty data frame z podstawowymi informacjami o zbiorze.
Building a simple dataframe with a summary of our columns (data types, sum and % of nulls):
summary = pd.DataFrame(df.dtypes, columns=['Dtype'])
summary['Nulls'] = pd.DataFrame(df.isnull().any())
summary['Sum_of_nulls'] = pd.DataFrame(df.isnull().sum())
summary['Per_of_nulls'] = round((df.apply(pd.isnull).mean()*100),2)
summary.Dtype = summary.Dtype.astype(str)
print(summary)
the output:
Dtype Nulls Sum_of_nulls Per_of_nulls
InvoiceNo object False 0 0.000
StockCode object False 0 0.000
Description object True 1454 0.270
Quantity int64 False 0 0.000
InvoiceDate datetime64[ns] False 0 0.000
UnitPrice float64 False 0 0.000
CustomerID float64 True 135080 24.930
Country object False 0 0.000
An animated step-by-step guide to improving your pie charts.
How to improve 3D pie charts (turn them back into horizontal bar graphs) ;)
If you, on the other hand, want to go the student-like route (living in Wohngemeinschaft, not eating out too much) and try to save, you can easily live on 1,500-2,000 CHF per month and save the majority of your salary.
If you leave cheaply, you can spend around 1500 - 2000 CHF a month and save majority of your salary
We are now cooperating with Credit Agricole Bank and Revolut - if you have already moved to Switzerland you can open a free bank account and get 100 CHF bonus - email us to get the bonus code.
100 CHF bonus for opening a bank account in Switzerland
120,000 CHF annually according to this calculator gets you 7,746.20 CHF net per month.
120 000 CHF gets you around 7 746 CHF net per month
2) Rent only a room - it might be a good option if you come without family (in Switzerland it’s called living in a Wohngemeinschaft).
Renting a room in Switzerland = Living in a Wohngemeinschaft :o
Choose health insurance (Krankenkasse) - in Switzerland you have to pay your health insurance separately (it’s not deducted from your salary). You can use the Comparis website to compare the options. You have 3 months to choose both the company and your franchise.
Choosing health insurance in Switzerland
Other important things - if you plan to use public transport, we recommend you to buy the Half Fare card. It gives you a 50% discount on most public transport in Switzerland (it costs 185 CHF per year).
Recommendation to buy a Half Fare Card for a public transport discount
There are also some general expat groups like Zurich Together
Zurich Together <--- expat group for Zurich
WHERE clause introduces a condition on individual rows; HAVING clause introduces a condition on aggregations, i.e. results of selection where a single result, such as count, average, min, max, or sum, has been produced from multiple rows. Your query calls for a second kind of condition (i.e. a condition on an aggregation) hence HAVING works correctly. As a rule of thumb, use WHERE before GROUP BY and HAVING after GROUP BY. It is a rather primitive rule, but it is useful in more than 90% of the cases.
Difference between WHERE and HAVING in SQL:
WHERE is used for individual rowsHAVING is used for aggregations (result of a selection), such as: COUNT, AVERAGE, MIN, MAX or SUMWHERE before GROUP BY and HAVING after GROUP BY (works in 90% of the cases)Scrum means that “you have to get certain things done with those two weeks.” Kanban means “do what you can do in two weeks.”
If you get a choice, push for Kanban over Scrum
What people will say is that estimates are for planning – that their purpose is to figure out how long some piece of work is going to take, so that everybody can plan accordingly. In all my five years shipping stuff, I can only recall one project where things really worked that way.
Project estimations are just energy drainers and stress producers
Be explicit about the difference between hard deadlines
Different types of deadlines:
If you delegate all your IT security to the InfoSec, they will come up with draconian rules
Try to do some of your own security before delegating everything to InfoSec that will come with draconian restrictions
you should always advocate for having a dedicated SRE if there’s any real risk of after-hours pages that are out of your control.
Site Reliability Engineers (ideally from different time zones) should've been settled when we might expect after-hours errors
I try to write a unit test any time the expected value of a defect is non-trivial.
Write unit tests at least for the most important parts of code, but every chunk of code should have a trivial unit test around it – this verifies that the code is written in a testable way, which indeed is extremely important
I’m defining an integration test as a test where you’re calling code that you don’t own
When to write integration tests:
Which database technology to choose
Which database to choose (advice from an Amazon employee):
I would use a serverless function when I have a relatively small and simple chunk of code that needs to run every once in a while.
When to make a serverless function (advice from an Amazon employee)
Programming languages These will probably expose my ignorance pretty nicely.
When to use different programming languages (advice from an Amazon employee):
Now, a couple of years later, my guidelines for JS are:
Advices on using JavaScript from a long time programmer:
Consuming media (books, blogs, whatever) is not inherently a compounding thing. Only if you have some kind of method to reflect, to digest, to incorporate your knowledge into your thoughts. If there is anything valuable in this post, you, reader, will probably not benefit from it unless you do something active to “process” it immediately.
Consuming books/blogs is not as compounding as we think
if you have an amazing manager at a shit company you’ll still have a shit time. In some ways, it’ll actually be worse. If they’re good at their job (including retaining you), they’ll keep you at a bad company for too long. And then they’ll leave, because they’re smart and competent. Maybe they’ll take you with them.
Danger of working with a great manager at a shit company
Some of the people in the company are your friends in the current context. It’s like your dorm in college.
"Company is like a college dorm"... interesting comparison
It’s also okay to take risks. Staying at a company that’s slowly dying has its costs too. Stick around too long and you’ll lose your belief that you can build, that change is possible. Try not to learn the wrong habits.
Cons of staying too long in the same company
I do think when a lot of managers realized they’ve hit their peak or comfort level, they then start to focus on playing politics instead of delivering results to hold onto their position. These are also the kind of managers who would only hire people less capable than them, for fear of being replaced.
The way corporate world works
“In practice people gravitate to, hire and promote individuals they like to be around, not people who demand accountability.”
Everybody likes having an agreeable and flattering person around them
Dr. Peter advises creative incompetence — pretending to be incompetent but doing it in an area or manner where it doesn’t actually impair your work.
Creative incompetence
Dr. Peter also surmised that “super competent” people tend to “disrupt the hierarchy.” I suppose that’s a nice way of saying you’ve made your boss look bad by being more capable.In such situations, you’ll probably find yourself deliberately suppressed or edged out sooner or later — for some stupid reason or blame pushing.
Being overly competent may get you fired
So if you’re a highly competent and aggressive individual, it’s best you find yourself a job in a startup, be an entrepreneur, or work in a company that needs turning around.
Advice to competitive workers
Dr. Peter also had another interesting theory about getting promoted. He considered working hard and improving your skill sets not as effective as something called pull promotion. That’s when you get promoted — faster than usual — when a mentor or patron pulls you up.No wonder there’s so much butt kissing in the corporate world. They must have read Dr. Peter’s research from the ‘60s.
Pull promotion
competency doesn’t factor as much as likability in most corporate promotions, especially when the ship is smooth sailing.
Another truth of the corporate world
Find a results-oriented job if you’re fiercely independent and opinionated. Climb the ladder in a big corporation if you’re highly diplomatic or a crowd-pleaser.
Advice for two different working profiles
managers fail to see and address this problem is that they are used to looking at communication and assume it's a good thing. Because they see activity
Managers in general perceive meetings as a good thing
A study conducted by Gloria Marks, a Professor of Informatics at the University of California, revealed that it takes us an average of 23 minutes and 15 seconds to refocus on a task after an interruption, and even when we do, we experience a decrease in productivity
23 minutes and 15 seconds - average time to refocus on task after an interruption
It doesn't mean that we ignore all messages and only look up from our work when something is on fire – but the general expectation is that it's okay to not be immediately available to your teammates when you are focusing on your work
One of the rules of "Office time"
Working in an open office renders us even more vulnerable
Like single standup meeting, open office doesn't improve the productivity of makers
Office hours are chunks of time that makers set aside for meetings, while the rest of the time they are free to go into a Do Not Disturb mode
"Office hours" - technique to improve makers schedule

People think it’s efficient to distribute information all at the same time to a bunch of people around a room. But it’s actually a lot less efficient than distributing it asynchronously by writing it up and sending it out and letting people absorb it when they’re ready to so it doesn’t break their days into smaller bits.”
Async > meetings
it's a matter of culture. None of these rules would work if the management fails to see that makers need to follow a different schedule
Change in the work environment needs acknowledgement of managers
context switching between communication and creative work only kills the quality of both
Context switching lowers the quality
since most powerful people operate on the manager schedule, they're in a position to force everyone to adapt to their schedule
Managers highly affect makers schedule
The most straightforward way to address this is to build a team knowledge base. Not only does that minimize the number of repetitive questions bounced around the office, it allows new team members to basically onboard themselves.
Building a team knowledge base
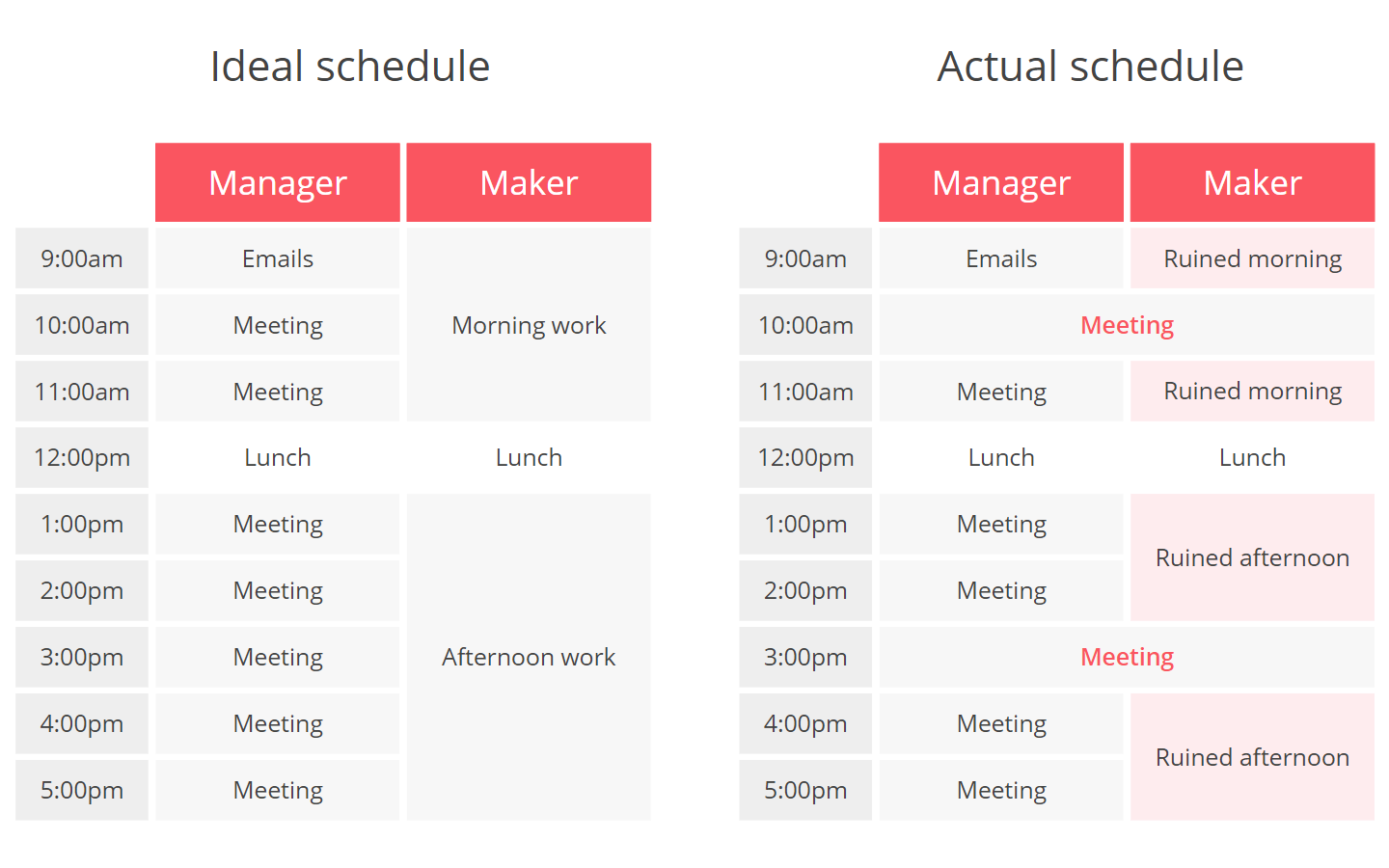
almost no organizations today support maker schedules
Unfortunate truth
For managers, interruptions in the form of meetings, phone calls, and Slack notifications are normal. For someone on the maker schedule, however, even the slightest distraction can have a disruptive effect
How ideal schedule should look like:
Immediate response becomes the implicit expectation, with barely any barriers or restrictions in place
Why Slack is a great distraction:
in the absence of barriers convenience always wins
In our experience, the best way to prevent a useless meeting is to write up our goals and thoughts first. Despite working in the same office, our team at Nuclino has converted nearly all of our meetings into asynchronously written reports.
Weekly status report (example):
For many data scientists, the finished product of a work session is a business analysis. They need to show team members—who oftentimes aren’t technical—how their data became a specific recommendation or insight.
Usual final product in Data Science is the business analysis which is perfectly explained with notebooks
Work never ends. No matter how much you get done there will always be more. I see a lot of colleagues burn out because they think their extra effort will be noticed. Most managers appriciate it but do not promote their employees.
Common reality of overworking
Don't focus too much on the salary. It's just one tiny part of the whole package.Your dev job pays your rent, food and savings. I assume that most dev jobs do this quite well.Beyond this, the main goal of a job is to increase your future market value, your professional network and to have fun. So. basically it's about how much you are worth in your next job and that you enjoy your time.A high salary doesn't help you if you do stuff which doesn't matter in a few years.
Don't focus on the salary in your dev job.
COVID-19 has spurred a shift to analyze things like supply chain disruptions, speech analytics, and filtering out pandemic-related behavior, such as binge shopping, Burtch Works says. Data teams are being asked to create new simulations for the coming recession, to create scorecards to track pandemic-related behavior, and add COVID-19 control variables to marketing attribution models, the company says.
How COVID-19 impacts activities of data positions
Data scientists and data engineers have built-in job security relative to other positions as businesses transition their operations to rely more heavily on data, data science, and AI. That’s a long-term trend that is not likely to change due to COVID-19, although momentum had started to slow in 2019 as venture capital investments ebbed.
According to a Dice Tech Jobs report released in February, demand for data engineers was up 50% and demand for data scientists was up 32% in 2019 compared to the prior year.
Need for Data Scientist / Engineers in 2019 vs 2018
70% async using Twist, Github, Paper25% sync using something like Zoom, Appear.in, or Google Meet5% physical meetings, e.g., annual company or team retreats
Currently applied work structure at Doist
According to the Harvard Business Review article “Collaborative Overload”, the time employees spend on collaboration has increased by 50% over the past two decades. Researchers found it was not uncommon for workers to spend a full 80% of their workdays communicating with colleagues in the form of email (on which workers’ spend an average of six hours a day); meetings (which fill up 15 percent of a company’s time, on average); and more recently instant messaging apps (the average Slack user sends an average of 200 messages a day, though 1,000-message power users are “not the exception”)
Time spent in the office
we think the async culture is one of the core reasons why most of the people we’ve hired at Doist the past 5 years have stayed with us. Our employee retention is 90%+ — much higher than the overall tech industry. For example, even a company like Google — with its legendary campuses full of perks from free meals to free haircuts — has a median tenure of just 1.1 years. Freedom to work from anywhere at any time beats fun vanity perks any day, and it costs our company $0 to provide
Employee retention rate at Doist vs Google
I also recently took about 10 months off of work, specifically to focus on learning. It was incredible, and I don’t regret it financially. I would often get up at 6 in the morning or even earlier (which I never do) just from excitement about what I was going to learn about and accomplish in the day. Spending my time focused Only on what I was most interested in was incredibly rewarding.
Approach of taking 10 months off from work just to learn something new
I'm working for myself right now, but if one day I needed to go get a full-time job again, I would almost certainly not go to big tech again. I'd rather get paid a fifth of what I was doing, but do something that leaves me with some energy after I put in a day's work
Reflections after working for FAANG
more money comes at the cost of very high expectations and brutal deadlines
Second, in my experience working with ex-FAANG - these engineers, while they all tend to be very smart, tend to be borderline junior engineers in the real world. They simply don't know how to build or operate something without the luxury of the mature tooling that exists at FAANG. You may be in for a reality shock when you leave the FAANG bubble
Working with engineers out of FAANG can be surprising
Things to consider when crafting out Job Ads and descriptions

Truth be told, we found that most companies we worked with preferred to own the analytical backend.
From the experience of Plotly Team
Talented people flock to employers that promise to invest in their development whether they will stay at the company or not.
Cannot agree more on that
We want to learn, but we worry that we might not like what we learn. Or that learning will cost us too much. Or that we will have to give up cherished ideas.
I believe it is normal to worry about the usage of a new domain-based knowledge
The two things I really like about working for smaller places or starting a company is you get very direct access to users and customers and their problems, which means you can actually have empathy for what's actually going on with them, and then you can directly solve it. That cycle is so powerful, the sooner you learn how to make that cycle happen in your career, the better off you'll be. If you can make software and make software for other people, the outcome truly is hundreds of millions of dollars worth of value if you get it right. That's where I'm here to try and encourage you to do. I'm not really saying that you shouldn't go work at a big tech company. I am saying you should probably leave before it makes you soft.
What are the benefits of working at the smaller companies/startups over the tech giants
afternoons are spent reading/researching/online classes.This has really helped me avoid burn out. I go into the weekend less exhausted and more motivated to return on Monday and implement new stuff. It has also helped generate some inspiration for weekend/personal projects.
Learning at work as solution to burn out and inspiration for personal projects
When People Work Together
How to lay off your lovely co-workers

Praca w Facebooku - doskonała znajomość JSa, React, zarządzanie projektem OSS na GitHubie, prowadzenie społeczności, pisanie dokumentacji i wpisów na blogu.Szkolenia - dobra znajomość JSa, React, tworzenie szkoleń (struktura, zadania, itd), uczenie i swobodne przekazywanie wiedzy, marketing, sprzedaż.Startupy - dobra znajomość JSa, React, praca w zespole, rozmawianie z klientami, analiza biznesowa, szybkie dowożenie MVP, praca w stresie i dziwnych strefach czasowych.
Examples of restructuring tasks into more precise actions:
Defining what “time well spent” means to you and making space for these moments is one of the greatest gifts you can make to your future self.
Think really well what "time well spent" means to you
Research shows that humans tend to do whatever it takes to keep busy, even if the activity feels meaningless to them. Dr Brené Brown from the University of Houston describes being “crazy busy” as a numbing strategy we use to avoid facing the truth of our lives.
People simply prefer to be busy
A few takeaways
Summarising the article:
Simulations show that for most study designs and settings, it is more likely for a research claim to be false than true.
There is increasing concern that most current published research findings are false.
The probability that the research is true may depend on:
Research finding is less likely to be true when:
golden rule: If someone calls saying they’re from your bank, just hang up and call them back — ideally using a phone number that came from the bank’s Web site or from the back of your payment card.
Golden rule of talking to your bank
“When the representative finally answered my call, I asked them to confirm that I was on the phone with them on the other line in the call they initiated toward me, and so the rep somehow checked and saw that there was another active call with Mitch,” he said. “But as it turned out, that other call was the attackers also talking to my bank pretending to be me.”
Phishing situation scenario:
It is difficult to choose a typical reading speed, research has been conducted on various groups of people to get typical rates, what you regularly see quoted is: 100 to 200 words per minute (wpm) for learning, 200 to 400 wpm for comprehension.
On average people read:
DevOps tools enable DevOps in organizations
Common DevOps tools:
While talking about DevOps, three things are important continuous integration, continuous deployment, and continuous delivery.
DevOps process
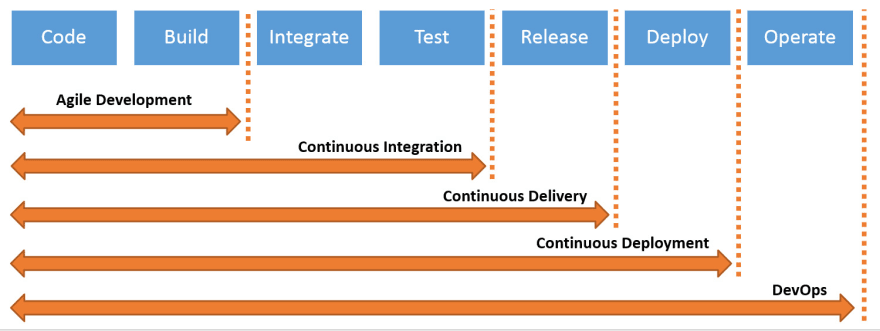
another version of the image:
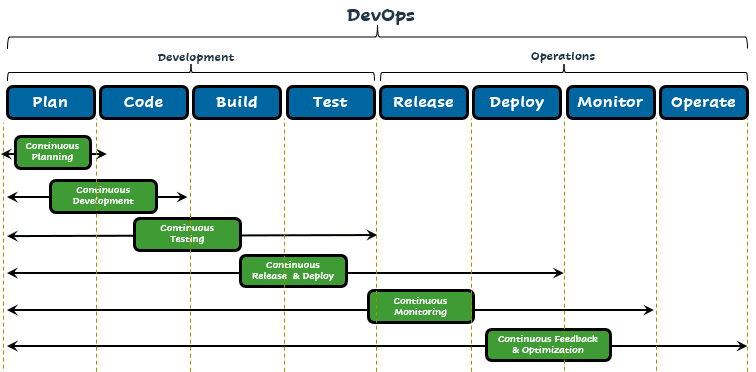 and one more:
and one more:
![]()
Basic prerequisites to learn DevOps
Basic prerequisites to learn DevOps:
DevOps benefits
DevOps benefits:
Operations in the software industry include administrative processes and support for both hardware and software for clients as well as internal to the company. Infrastructure management, quality assurance, and monitoring are the basic roles for operations.
Operations (1/2 of DevOps):
I set it with a few clicks at Travis CI, and by creating a .travis.yml file in the repo
You can set CI with a few clicks using Travis CI and creating a .travis.yml file in your repo:
language: node_js
node_js: node
before_script:
- npm install -g typescript
- npm install codecov -g
script:
- yarn lint
- yarn build
- yarn test
- yarn build-docs
after_success:
- codecov
I set it with a few clicks at Travis CI, and by creating a .travis.yml file in the repo
You can set CI with a few clicks using Travis CI and creating a .travis.yml file in your repo:
language: node_js
node_js: node
before_script:
- npm install -g typescript
- npm install codecov -g
script:
- yarn lint
- yarn build
- yarn test
- yarn build-docs
after_success:
- codecov
Continuous integration makes it easy to check against cases when the code: does not work (but someone didn’t test it and pushed haphazardly), does work only locally, as it is based on local installations, does work only locally, as not all files were committed.
CI - Continuous Integration helps to check the code when it :
In Python, when trying to do a dubious operation, you get an error pretty soon. In JavaScript… an undefined can fly through a few layers of abstraction, causing an error in a seemingly unrelated piece of code.
Undefined nature of JavaScript can hide an error for a long time. For example,
function add(a,b) { return + (a + b) }
add(2,2)
add('2', 2)
will result in a number, but is it the same one?
With Codecov it is easy to make jest & Travis CI generate one more thing:
Codecov lets you generate a score on your tests:

Continuous Deployment is the next step. You deploy the most up to date and production ready version of your code to some environment. Ideally production if you trust your CD test suite enough.
Continuous Deployment
the limitations of the PPS
Limitations of the PPS:
Although the PPS has many advantages over the correlation, there is some drawback: it takes longer to calculate.
PPS is slower to calculate the correlation.
How to use the PPS in your own (Python) project
Using PPS with Python
pip install ppscoreshellimport ppscore as pps
pps.score(df, "feature_column", "target_column")
pps.matrix(df)
The PPS clearly has some advantages over correlation for finding predictive patterns in the data. However, once the patterns are found, the correlation is still a great way of communicating found linear relationships.
PPS:
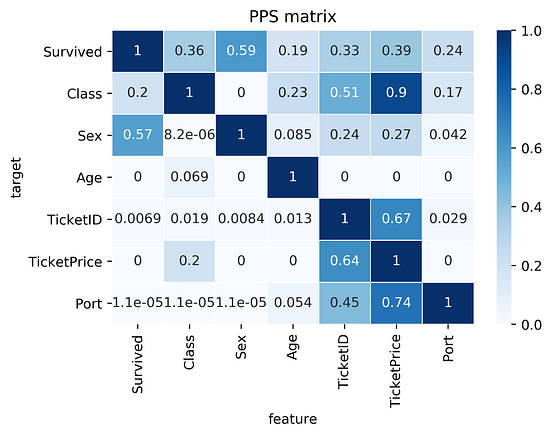
Let’s compare the correlation matrix to the PPS matrix on the Titanic dataset.
Comparing correlation matrix and the PPS matrix of the Titanic dataset:
findings about the correlation matrix:
TicketPrice and Class. For PPS, it's a strong predictor (0.9 PPS), but not the other way Class to TicketPrice (ticket of 5000-10000$ is most likely the highest class, but the highest class itself cannot determine the price)findings about the PPS matrix:
Survived is the column Sex (Sex was dropped for correlation)TicketID uncovers a hidden pattern as well as it's connection with the TicketPrice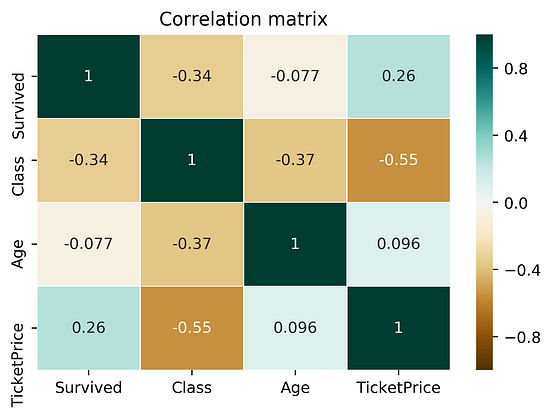
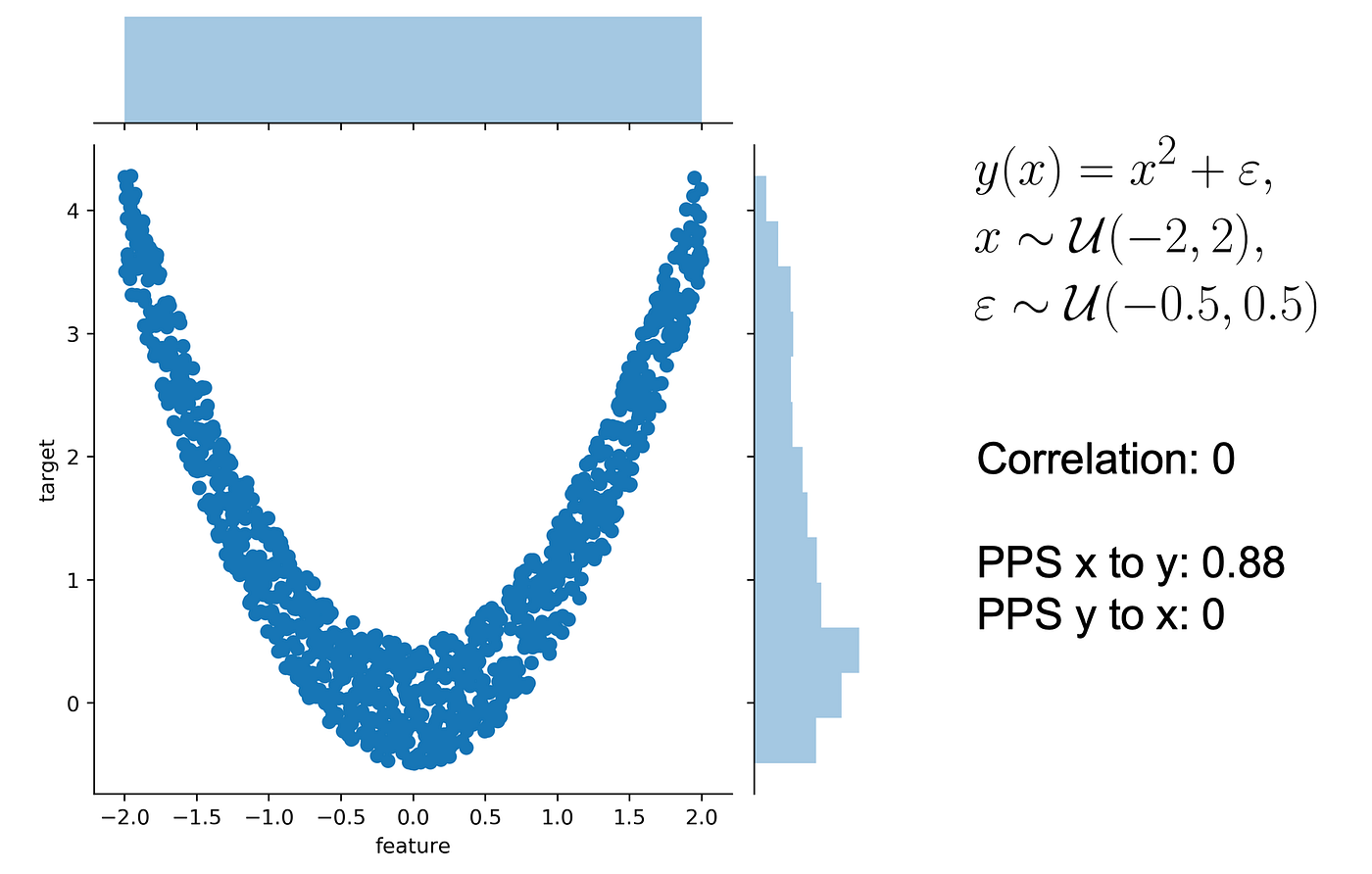
Let’s use a typical quadratic relationship: the feature x is a uniform variable ranging from -2 to 2 and the target y is the square of x plus some error.
In this scenario:
how do you normalize a score? You define a lower and an upper limit and put the score into perspective.
Normalising a score:
For a classification problem, always predicting the most common class is pretty naive. For a regression problem, always predicting the median value is pretty naive.
What is a naive model:
Let’s say we have two columns and want to calculate the predictive power score of A predicting B. In this case, we treat B as our target variable and A as our (only) feature. We can now calculate a cross-validated Decision Tree and calculate a suitable evaluation metric.
If the target (B) variable is:
More often, relationships are asymmetric
a column with 3 unique values will never be able to perfectly predict another column with 100 unique values. But the opposite might be true
there are many non-linear relationships that the score simply won’t detect. For example, a sinus wave, a quadratic curve or a mysterious step function. The score will just be 0, saying: “Nothing interesting here”. Also, correlation is only defined for numeric columns.
Correlation:
Examples:

There are many types of CRDTs
CRDTs have different types, such as Grow-only set and Last-writer-wins register. Check more of them here
Some of our main takeaways:CRDT literature can be relevant even if you're not creating a decentralized systemMultiplayer for a visual editor like ours wasn't as intimidating as we thoughtTaking time to research and prototype in the beginning really paid off
Key takeaways of developing a live editing tool
traditional approaches that informed ours — OTs and CRDTs
Traditional approaches of the multiplayer technology
Sometimes it's interesting to explain some code (How many time you spend trying to figure out a regex pattern when you see one?), but, in 99% of the time, comments could be avoided.
Generally try to avoid (avoid != forbid) comments.
Comments:
When we talk about abstraction levels, we can classify the code in 3 levels: high: getAdress medium: inactiveUsers = Users.findInactives low: .split(" ")
3 abstraction levels:
getAdressinactiveUsers = Users.findInactives.split(" ")Explanation:
searchForsomething()account.unverifyAccountmap, to_downncase and so on The ideal is not to mix the abstraction levels in only one function.
Try not mixing abstraction levels inside a single function
"The Big Picture" is one of those things that people say a whole lot but can mean so many different things. Going through all of these articles, they tend to mean any (or all) of these things
Thinking about The Big Picture:
In recent years we’ve also begun to see increasing interest in exploratory testing as an important part of the agile toolbox
Waterfall software development ---> agile ---> exploratory testing
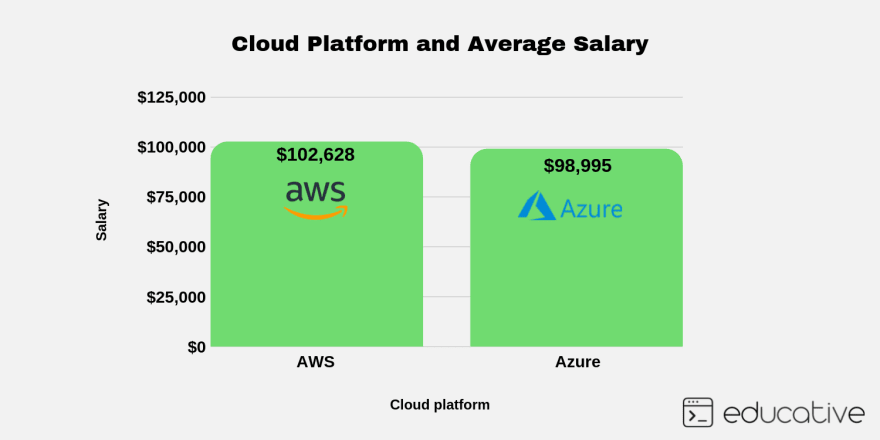
Developing in the cloud
Well paid cloud platforms:
First, you’ve spread the logic across a variety of different systems, so it becomes more difficult to reason about the application as a whole. Second, more importantly, the logic has been implemented as configuration as opposed to code. The logic is constrained by the ability of the applications which have been wired together, but it’s still there.
Why "no code" trend is dangerous in some way (on the example of Zapier):