‘convolution’ (as in, each of the folds of the brain)
overlap (ha!) with signals theory?
‘convolution’ (as in, each of the folds of the brain)
overlap (ha!) with signals theory?
Example 1. For example, suppose that the input volume has size [32x32x3], (e.g. an RGB CIFAR-10 image). If the receptive field (or the filter size) is 5x5, then each neuron in the Conv Layer will have weights to a [5x5x3] region in the input volume, for a total of 5*5*3 = 75 weights (and +1 bias parameter). Notice that the extent of the connectivity along the depth axis must be 3, since this is the depth of the input volume. Example 2. Suppose an input volume had size [16x16x20]. Then using an example receptive field size of 3x3, every neuron in the Conv Layer would now have a total of 3*3*20 = 180 connections to the input volume. Notice that, again, the connectivity is local in 2D space (e.g. 3x3), but full along the input depth (20).
These two examples are the first two layers of Andrej Karpathy's wonderful working ConvNetJS CIFAR-10 demo here
input (32x32x3)max activation: 0.5, min: -0.5max gradient: 1.08696, min: -1.53051Activations:Activation Gradients:Weights:Weight Gradients:conv (32x32x16)filter size 5x5x3, stride 1max activation: 3.75919, min: -4.48241max gradient: 0.36571, min: -0.33032parameters: 16x5x5x3+16 = 1216
The dimensions of these first two layers are explained here
Since all neurons in a single depth slice share the same parameters, the forward pass in each depth slice of the convolutional layer can be computed as a convolution of the neuron's weights with the input volume.[nb 2] Therefore, it is common to refer to the sets of weights as a filter (or a kernel), which is convolved with the input. The result of this convolution is an activation map, and the set of activation maps for each different filter are stacked together along the depth dimension to produce the output volume. Parameter sharing contributes to the translation invariance of the CNN architecture. Sometimes, the parameter sharing assumption may not make sense. This is especially the case when the input images to a CNN have some specific centered structure; for which we expect completely different features to be learned on different spatial locations. One practical example is when the inputs are faces that have been centered in the image: we might expect different eye-specific or hair-specific features to be learned in different parts of the image. In that case it is common to relax the parameter sharing scheme, and instead simply call the layer a "locally connected layer".
important terms you hear repeatedly great visuals and graphics @https://distill.pub/2018/building-blocks/
Here's a playground were you can select different kernel matrices and see how they effect the original image or build your own kernel. You can also upload your own image or use live video if your browser supports it. blurbottom sobelcustomembossidentityleft sobeloutlineright sobelsharpentop sobel The sharpen kernel emphasizes differences in adjacent pixel values. This makes the image look more vivid. The blur kernel de-emphasizes differences in adjacent pixel values. The emboss kernel (similar to the sobel kernel and sometimes referred to mean the same) givens the illusion of depth by emphasizing the differences of pixels in a given direction. In this case, in a direction along a line from the top left to the bottom right. The indentity kernel leaves the image unchanged. How boring! The custom kernel is whatever you make it.
I'm all about my custom kernels!
Kervolutional Neural Networks
卷积神经网络(CNN)能够在诸多计算机视觉任务中实现当前最优性能。但是,在非线性空间中建立卷积的研究投入很少。目前的研究主要利用激活层(activation layer),这样仅能提供逐点非线性。 为了解决这个问题,一种新的运算ker-volution(核卷积)被引入,其利用核方法(kernel trick)来近似人类感知系统的复杂行为。通过补丁级(patch-wise)核函数,核卷积神经网络(KNN)泛化卷积,增强模型能力,获取特征的高阶交互,但同时又没有引入附加参数。大量的实验表明,核卷积神经网络获得了较基线CNN更高的准确率和更快的收敛速度。
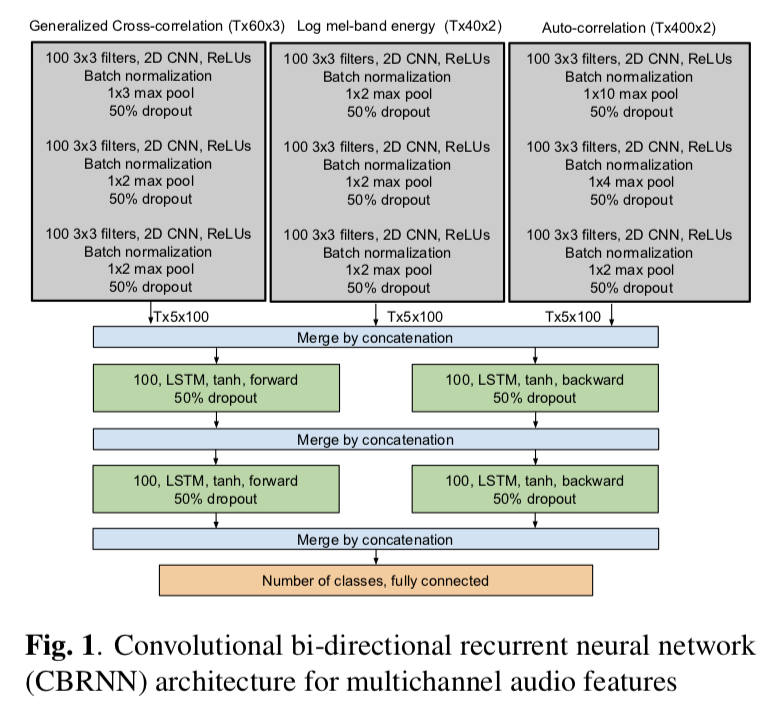
Sound Event Detection Using Spatial Features and Convolutional Recurrent Neural Network.
输入数据是多通道音频信号,网络是结合了CNN 和 LSTM。
How convolutional neural network see the world - A survey of convolutional neural network visualization methods
果断收藏并且要细读下。。。Paper Summary 准备!
这可是对 CNN 可视化方法的 review 啊!
一篇很棒的综述,专门说 CNN 的可视化的!要好好读读了!
Paper Summary 准备!
Deep convolutional Gaussian processes
似乎很有趣,可惜我统计没学好,没掌握到背后的本质,需要回炉重造了[委屈]~ 文章居然用的是今年年初发表的 UMAP 进行降维可视化,而不是 t-sne,这很新颖嘛!
Interpretable Convolutional Filters with SincNet
一篇值得我高度关注的 paper,来自 AI 三巨头之一 Yoshua Bengio!其背后的核心是将数字信号处理DSP中卷积的激励函数(滤波器)进行了重新设计,不仅会保留了卷积的特性(线性性+时间平移不变性)还在滤波器上添加待学习参数来学习合适的高低频截断位置。
DeepSphere: Efficient spherical Convolutional Neural Network with HEALPix sampling for cosmological applications
对具有方位信息的数据做卷积,实现了所谓的 3D 卷积,这对天文上的微博背景辐射(CMB)数据的应用很有意义。
Quaternion Convolutional Neural Networks
【卷积神经网络】Quaternion Convolutional Neural Networks
(ECCV 2018) 本文是上海交大和杜克大学发表于ECCV 2018的工作,论文提出了一种基于Quaternion的CNN——QCNN。QCNN将图像的RGB通道转换到Quaternion数域进行讨论,并由此给出了quaternion convolution layers,quaternion fully-connected layers等结构。文章从"微观"上进行改进,提出了新的卷积神经网络,在high-level vision task和low-level vision task都取得了不错的效果。
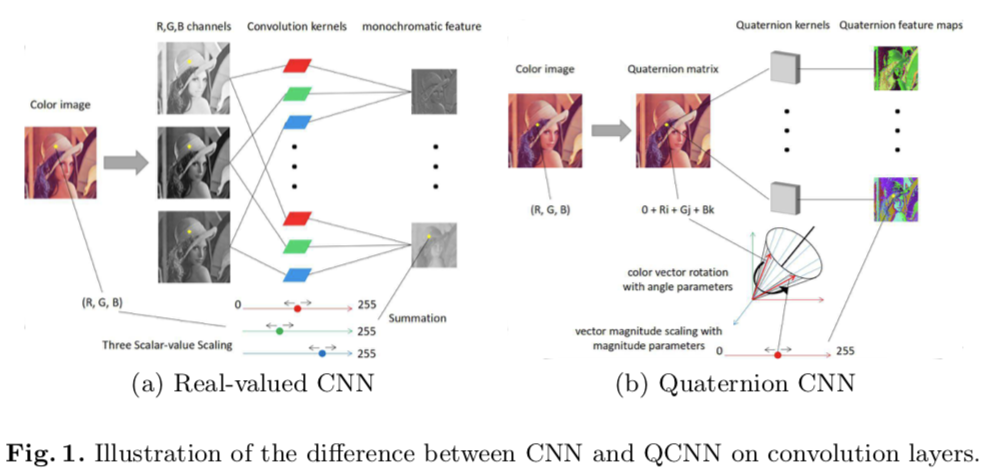
角度比较新颖。说白了就是把传统的RGB三个输入特征图用四元数在像素级别上混合表示。于是结果也就易被理解了,相当于把输入前3个独立特征图的假定换成了输入信息交叉后的单一特征图的假定~