这将按该顺序打印 1、0 和 2
future thread : -------- inc - print ----500ms---- inc print
main thread : --------- ---250ms--- print
运行顺序是: future的1,main的0,future的2
这一段,作者表述有误,主线程不是无权访问 counter,而是事务没有完成没有提交,ref 的值仍然没有改变,因此还是 0.
这将按该顺序打印 1、0 和 2
future thread : -------- inc - print ----500ms---- inc print
main thread : --------- ---250ms--- print
运行顺序是: future的1,main的0,future的2
这一段,作者表述有误,主线程不是无权访问 counter,而是事务没有完成没有提交,ref 的值仍然没有改变,因此还是 0.
Clojure Vars can have thread-local bindings. binding uses these, while with-redefs actually alters the root binding (which is someting like the default value) of the var. Another difference is that binding only works for :dynamic vars while with-redefs works for all vars.
user=> (def ^:dynamic *a* 1)
#'user/*a*
user=> (binding [*a* 2] *a*)
2
user=> (with-redefs [*a* 2] *a*)
2
user=> (binding [*a* 2] (doto (Thread. (fn [] (println "*a* is " *a*))) (.start) (.join)))
*a* is 1
#<Thread Thread[Thread-2,5,]>
user=> (with-redefs [*a* 2] (doto (Thread. (fn [] (println "*a* is " *a*))) (.start) (.join)))
*a* is 2
#<Thread Thread[Thread-3,5,]>
意思是说
binding 绑定的值是线程间不可见的with-redefs 绑定的值是线程间可见的binding 可以构造 thread-local var; with-redefs 构造的是 thread-shareing var .
dotoclojure.coreAvailable since 1.0 (source) (doto x & forms)Evaluates x then calls all of the methods and functions with the value of x supplied at the front of the given arguments. The forms are evaluated in order. Returns x. (doto (new java.util.HashMap) (.put "a" 1) (.put "b" 2))
doto 不同于 do:
doto 是 (doto x & forms) 计算第一个表达式 x,一般是构建对象或者线程。之后的所有表达式都是对 x 的调用: x.expr1 x.expr2, 并且最后返回的仍然是 x.doto 把 x 对象作为后面方法的所属对象(一般对象调用方法,在 clojure 的写法中都是 (.method object &arguments))。进行调用,整体表达式仍然返回 x 对象。
因此这种方法通常用来对 x 对象的属性,进行批量修改(如果 x 对象有多个属性),或者是调用 x 的方法,对 x 进行某些改变。
do 是 (do & forms) 只是按顺序执行每一个表达式,并返回最后一个表达式的结果 Clojure’s four reference types are listed across the top, with their features listed down the left. Atoms are for lone synchronous objects. Agents are for asynchronous actions. Vars are for thread-local storage. Refs are for synchronously coordinating multiple objects.
四种mutable object分别适用不同的并发处理情形:
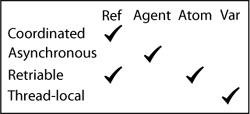
Coordinate :意思是读写多个refs可以保障无冲突
Asynchronous : 意思是更新请求会在另一个线程排队等待稍后执行。
Retriable : 对 reference value 的更新如果遇到异常会重试
Thread-local: 每个线程有单独的数据拷贝,对状态的更改都是独立的
Barging refers to some careful logic in the STM implementation allowing an older transaction to continue running while younger transactions retry.
clojure 可以通过两种方式对治这种问题,一是事务重启会引发错误,二是通过 barging --- 一种 STM 的小新的逻辑让新事务 retry 的时候,老事务引燃可以继续运行
ACID, which refers to the properties ensuring transactional reliability. Clojure’s STM provides the first three properties: atomicity, consistency, and isolation. The other, durability, is missing due to the fact that Clojure’s STM resides in-memory and is therefore subject to data loss in the face of catastrophic system failure.
DataBase 有一个衡量数据库系统好坏的指标:
统称为 ACID, clojure 的并发特性,支持(1)(2)(3),但是由于 clojure 并发以 STM 为基础 --- 一种存于内存的机制,因此不具备 "D" --- durability 。这部分就交给程序员来维护了。可以通过 DB,序列化,或者其他程序的logs。
Clojure has but one transaction per thread, thus causing all subtransactions to be subsumed into the larger transaction. Therefore, when a restart occurs in the (conceptual) subtransaction clojure.b, it causes a restart of the larger transaction
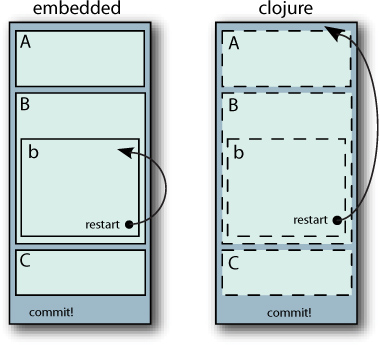
在 clojure 中,每个 root 事务分配一个线程,因此该‘根事务’中的内嵌事务(子事务)最终都要回归到根事务中,也因此一旦内嵌事务产生 restart,会使得整个事务 restart,而非仅仅子事务 restart
Another advantage that STM provides is that in the case of an exception during a transaction, its in-transaction values are thrown away and the exception propagated outward.
CMVV 的另一个好处是: 某个事务执行过程中一旦发生异常(exception),该事务中的 reference value 会被直接丢弃。
An example of a simple possible conflict is if another transaction B committed a change to a target reference during the time that transaction A was working, thus causing A to retry.
一个可能发生的异常是:当事务B执行结束准备提交改动后的 reference value 的时候,事务A正在执行,一旦提交会引发事务 A 重试(retry)
Within the first few moments of using Clojure’s STM, you’ll notice something different than you may be accustomed to: no locks. Consequently, because there’s no need for ad-hoc locking schemes when using STM, there’s no chance of deadlock. Likewise, Clojure’s STM doesn’t require the use of monitors and as a result is free from lost wakeup conditions. Behind the scenes, Clojure’s STM uses multiversion concurrency control (MVCC) to ensure snapshot isolation.
几个关键词:
Before we dive into the details of Clojure’s reference types, let’s start with a high-level overview of Clojure’s software transactional memory (STM).
引入了一个非常底层的定义:STM(software transactional memory) 软件事务内存
when dealing with identities, it’s receiving a snapshot of its properties at a moment in time
当 clojure 处理 identity的时候,他必然获取了其当下的属性
Time—The relative moments when events occur State—A snapshot of an entity’s properties at a moment in time Identity—The logical entity identified by a common stream of states occurring over time
clojure 状态管理和更改模型,包含三个核心概念:
Software transactional memory with multiversion concurrency contr- rol and snapshot isolation
这个标题,完全看不懂,google 翻译的不错:具有多版本并发控制和快照隔离的软件事务内存
Vars and the Global Environment
vars 的本质是 mutable 的,clojure 通过线程间隔离,来实现对 vars 的安全使用。相关的函数是:
如果 vars 想做线程间信息传递(binding conveyance),需要使用:
(set! var-symbol expr) Assignment special form. When the first operand is a symbol, it must resolve to a global var. The value of the var’s current thread binding is set to the value of expr. Currently, it is an error to attempt to set the root binding of a var using set!, i.e. var assignments are thread-local. In all cases the value of expr is returned. Note - you cannot assign to function params or local bindings. Only Java fields, Vars, Refs and Agents are mutable in Clojure.
在 clojure 中只有四种 mutable 对象:
可以通过 (set! var-symbol expr) 对他们进行 thread-loca 更改。
half your city would be dead by then!
hah, :)
http://www.qingpingshan.com/bc/jsp/321361.html
这篇文章关于美团推荐系统的,相当不错
这个图也不错。
http://www.404wx.com/read/9L2Y0zmAeP8EpRO09Dn57rZg6OGqwjdv
http://blog.sina.com.cn/s/blog_61c4630901017257.html
这里有如何设计 A/B test 的方法
数据结构可视化
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
在线绘制函数模型
https://www.html5tricks.com/demo/html5-xcalc-demo/index.html
在线数学公式编辑器
https://www.jiqizhixin.com/technologies/6ca1ea2d-6bca-45b7-9c93-725d288739c3
https://blog.csdn.net/zhufenglonglove/article/details/51602162
关于推荐的多种形式,看一看 coursera 这一节课: Movielens Tour
https://www.coursera.org/learn/recommender-systems-introduction/lecture/HcINn/movielens-tour
movielens 网址: https://movielens.org/
很经典
https://github.com/alonsoir/awesome-recommendation-engine
https://github.com/alonsoir/recomendation-spark-engine
http://ceur-ws.org/Vol-1609/16090628.pdf
DONE: 5. 国内博客非常好: spark-streaming 实时推荐系统
User don't really know what they are looking for this is where recommendations coming from.
这个系列总共讲几个内容:
Formal Model
C = sett of Customers S = sett of Items
Utility function ~u: C X S -> R~
Utility matrix
| | Avatar | LOTR | Matrix | Pirates | |-------+--------+------+--------+---------| | Alice | 1 | | 0.2 | | | Bob | | 0.5 | | 0.3 | | Carol | 0.2 | | 1 | | | David | | | | 0.4 |
The key problem of recommendations system is to fill the null value of the Utility Matrix.
这包含如下几个问题:
Gathering Ratings
Explicit way:
Implict way:
Learn ratings from user actions.
e.g. purchase implies high rating
What about low ratings.
implict way 很那去学习用户不喜欢的, 你没有什么比较好的指标来 implies low rating.
Extrapolateing Utilities
Key problem: matrix U is sparse.
most people have not rated most items.
Cold start problem:
Three approaches to recommender systems
Main idea:
Recommend items to customer x, similar to previous items rated highly by x.
Examples:
Movies
Same actor, director, genre...
Websites, blogs, news
Articles with similar content
People
Recommend people with many common friends.
Item Profiles
For each item, create an item profile, which we can then use to build user profiles. So the profile is a sett of features about the item.
Convenient to think of the item profile as a vector:
Text features: <- 从文本挖掘中获取经验
Profile = sett of "important" words in item(document)
How to pick important words!
Usual heuristic from text mining is TF-IDF (~Term frequency * Inverse Doc Frequence~)
Sidenote: TF-IDF
TF-IDF 把 具体的东西抽象化(向量化) 的方法, 用 独特且多次 的 要素 代表 整体.
[[file:Content based systems/screenshot_2018-12-06_23-19-54.png]]
TFij 整体就是在说, 这个单词 i 在这个文章 j 中出现的(相对) 次数 到底多不多.
[[file:Content based systems/screenshot_2018-12-06_23-24-05.png]]
IDFi 就是在说这个单词 i 是否是足够 独特.
TF-IDF score: wij = TFij * IDFi
Doc(or item) profile = set of words(feature) with highest TF-IDF scores, together with their scores.
User Profiles
User has rated items with profiles ~i_i, ..., i_n~. (items like the document refer below, so they are all vectors.)
有了这些向量之后,如何构建这个用户的 profile 呢. 最简单的就是把取平均: ~(i1 + i2 + ... +in)/n~ 但这个没有考虑到用户的喜好, 直接取平均, 于是可以使用 weighed average.
Normalize weights using average rating of user.
Example1: Boolean Utility Matrix
Items are movies, only feature is "Actor"
Making Predictions
User profile x, Item profile i.
Estimate $U(x,i)=cos(\theta)=\frac{(x\cdot{i})}{|x||i|}$ , by cosie similarity.
Then recommend the item with high ~U(x,i)~ value, in the catalog to this user.
Technically, the cosine distance is actually the angle $\theta$, and cosine similarity is the angle 180-$\theta$
如何保证, user profile 与 item profile 是同一个维度的向量呢.
TF-IDF -----find top k feature-----> item profile --- \ -----> item profile --- | -----> item profile --- | ---> average ---> user profile ... | -----> item profile --- /
以上这些就是 COntent based method.
pros:
No need for data on other users.(你不需要其他用户的数据来给这个用户做推荐.)
Able to recommend to users with unique tastes.
when you get to collaborative filtering, you'll see that CF make recommendations to one user by other similar users. 协同过滤的问题就是如果某 些用户的爱好很独特, 与他相似的用户很少或不存在, 那么协同过滤就会失效. Content based 方法是直接结算 用户与商品之间的相似度,不需要仰赖其他用户的相似度.
Able to recommend new & unpopular items.
explanations for recommended items
Cons:
finding the appropriate feature is hard.
Overspecialization
[[file:Content based systems/screenshot_2018-12-07_06-38-53.png]]
Cold-start problem for new users.
How to build a user profile
http://html.rhhz.net/buptjournal/html/20160205.htm
https://arxiv.org/pdf/1409.2762.pdf
http://www.inf.unibz.it/~ricci/papers/RecSys9-CR.pdf
https://juejin.im/entry/58f4906fb123db632b426cca
https://www.youtube.com/watch?v=eIJwplMTEFs
Collaborative filtering, especially latent factor model, has been popularly used in personalized recommendation. Latent factor model aims to learn user and item latent factors from user-item historic behaviors. To apply it into real big data scenarios, efficiency becomes the first concern, including offline model training efficiency and online recommendation efficiency. In this paper, we propose a Distributed Collaborative Hashing (DCH) model which can significantly improve both efficiencies. Specifically, we first propose a distributed learning framework, following the state-of-the-art parameter server paradigm, to learn the offline collaborative model. Our model can be learnt efficiently by distributedly computing subgradients in minibatches on workers and updating model parameters on servers asynchronously. We then adopt hashing technique to speedup the online recommendation procedure. Recommendation can be quickly made through exploiting lookup hash tables. We conduct thorough experiments on two real large-scale datasets. The experimental results demonstrate that, comparing with the classic and state-of-the-art (distributed) latent factor models, DCH has comparable performance in terms of recommendation accuracy but has both fast convergence speed in offline model training procedure and realtime efficiency in online recommendation procedure. Furthermore, the encouraging performance of DCH is also shown for several real-world applications in Ant Financial.
天净沙`秋
整体思路:基于物品的 协同过滤推荐itembase-CF
主要分三个模块:
[ 冷启动 ], 冷启动,对没有行为或者第一次登陆的用户的推荐规则,单独生成表。
一、离线部分: 物品相似度计算: * 1.1 商品数量:
1.2 用户历史商品打分表: UserID-ItemID-Ranting 至少一个月内浏览,搜索,加车,未购的商品加权打分,取 topk个 1.3 商品相似度矩阵: | | Item1 | Item2 | Item3 | |-------+-------+-------+-------| | Item1 | | 0.8 | 0.3 | | Item2 | | | 0.5 | | Item3 | | | |
*** 1.4商品相似度排序表: itemID-rank1-rank2…rankN每个商品取前topN个相似商品
用户一周对商品打分和偏好计算: * 2.1用户一周商品打分表, user-item-ranting 根据打分表取topk个商品排序得到
*** 2.2用户一周商品偏好表 表结构:userID-item1-item2…itemK
** 3离线推荐结果计算: 根据用户一周商品偏好表topk个商品关联物品相似度表,每个user推荐X个item,得到离 线推荐表,每日更新
*** 3.1离线推荐表:userID-rec1-rec2-rec3…recX
根据实时流数据处理成user-item-rating(rating根据浏览搜索次数,时长,排序)关联离线 一周商品打分表user-item-rating,加权(实时的比重大,离线小)更新新的rating关联商品 相似度排序表,得到实时推荐商品粗排序打分表userID-ItemID-rating(离线+实时)
** 排序阶段:
对粗排序打分表进行精准排序,得到实时推荐商品表userID-rec1-rec2-rec3…recX方法: LR或者简单逻辑
** 实时推荐商品更新
三、冷启动: 主要是对无行为和第一次登陆的用户推荐X商品离线处理,表结构user- rec1-rec2-rec3…recX逻辑
根据实时推荐表计算当前推荐商品的最热商品TopX
properties or constructor arguments
在基于XML配置元数据,在bean的配置信息中我们可以使用<constructor-arg>和<property>属性来实现Spring的依赖注入。</property></constructor-arg>
You can let Spring resolve collaborators (other beans) automatically
在基于XML配置元数据,在bean的配置信息中我们可以使用<constructor-arg/> 和 <property/> 属性来实现Spring的依赖注入(DI)。Spring 容器也可以在不使用<constructor-arg>和<property>元素下自动装配各个bean之间的依赖关系。</property></constructor-arg>
这个就是 Spring 提供的 @Autowiring annotation
Request对象实现请求转发 4.1、请求转发的基本概念 请求转发:指一个web资源收到客户端请求后,通知服务器去调用另外一个web资源进行处理。
Request对象实现请求转发 4.1、请求转发的基本概念
请求转发:指一个web资源收到客户端请求后,通知服务器去调用另外一个web资源进行处理。
HTTP请求头中的所有信息都封装在这个对象中
HTTP【请求头】中的所【有信息】都封装在这个对象中
在服务器端使用getParameter方法和getParameterValues方法接收表单参数,代码如下
在服务器端使用getParameter方法和getParameterValues方法接收表单参数,代码如下
可以看到,之所以会产生乱码,就是因为服务器和客户端沟通的编码不一致造成的,因此解决的办法是:在客户端和服务器之间设置一个统一的编码,之后就按照此编码进行数据的传输和接收。
可以看到,之所以会产生乱码,就是因为服务器和客户端沟通的编码不一致造成的,因此解决的办法是:在客户端和服务器之间设置一个统一的编码,之后就按照此编码进行数据的传输和接收。
ModelMap对象主要用于传递控制方法处理数据到结果页面,类似于request对象的setAttribute方法的作用。 用法等同于Model
* ModelAndView主要有两个作用 设置转向地址和传递控制方法处理结果数据到结果页面
* Model本身不能设置页面跳转的url地址别名或者物理跳转地址,那么我们可以通过控制器方法的返回值来设置跳转url * 地址别名或者物理跳转地址
Multi-dimensional scaling (MDS) and Principla Coordinate Analysis(PCoA) are very similar to PCA, except that instead of converting correlations into a 2-D graph, they convert distance among the samples into a 2-D graph.
So, in order to do MDS or PCoA, we have to calculate the distance between Cell1 and Cell2, and distance between Cell1 and Cell3...

One very common way to calculate distance between two things is to calculate the Euclidian distance.





And once we calculated the distance between every pair of cells, MDS and PCoA would reduce them to a 2-D graph.

The bad news is that if we used the Euclidean Distance, the graph would be identical to a PCA graph!!

In other words, clustering based on minimizing the linear distances is the same with maximzing the linear correlations.
我想这里也就是为什么,李宏毅老师在 t-SNE 课程一开始时说,其他非监督降维算法都只是专注于【如何让·簇内距小·】,而 t-SNE 还考虑了【如何让·簇间距大·】
也就是说,PCA 的本质(或者叫另一种解释)也只是【找到一种转换函数,他能让原空间中距离近的两点,转换后距离更近】,他压根就没有考虑【簇内or簇外】而是“通杀”所有点。

The good news is that there are tons of other ways to measure distance!!!
For example, another way to measure distances between cells is to calcualte between cells is to calculate the average of the absolute value of the log fold changes among genes.


Finally, we get a plot different from the PCA plot

A biologist might choose to use log fold change to calculate distance because they are frequently interested in log fold changes among genes...
But there are lots of distance to choose from...

In summary:


Textbook: chapter 1.7
前一节课已经介绍了如何判断【有没有解】:很多“换句话说”
有没有解 ---> 是不是线性组合 ---> 在不在span中。
现在要解决的是:如果有解,那么会有多少个解!
Textbook: chapter 1.6
\(Ax=b\)
能否找到一个 x 使得 \(Ax=b\) 成立.
有没有解这个问题非常重要:假设 Linear system 是一个电路,现在老板告诉你这个电路要输出 b 这么大的电流,你能不能找到合适的电压源or电流源,还是根本就找不到?
consistent
A system of linear equations is called consistent if it has one or more solutions。
只要有解就叫做 consistent.
inconsistent
A system of linear equations is called inconsistent if its solution set is empty(no solution)
没有解就叫做 inconsistent.
Naive 方法:线的交点
把 system of linear equations 的方程都画成直线,如果他们有交点,那么就是有解,否则无解。
General 方法
定义引入:Linear Combination
Given a vector set \(\{u_1,u_2,...,u_k\}\)
The linear combination of the vectors in the set: \(v=c_1u_1+c_2u_2+...+c_ku_k,\ c_1,c_2,...,c_k\ are\ scalars\ coefficients\ of\ linear\ combination\)
linear combination is a vector.
有了 Linear combination 的定义之后,我们再回一下 lec5 篇末讲解的关于 使用 column view of product of matrix and vector 所以我们可以得到的结论是:
\(Ax\) 其本质就是一个 linear combination, 他是
矩阵与向量的乘法就是对矩阵的列做线性组合。
对于 \(Ax=b\) 是否有解(x是变量)这件事,实际就是在问:b 是否是columns of A的所有可能的线性组合中的一种。
从是否有解到是否是线性组合
如果两个向量不是平行的同时不是0向量,那么他们可以组合出二维空间中所有可能的向量(亦即,线性组合的所有可能性覆盖整个2D空间)。
【判断题】:如上所说,如果非零非平行的两个向量的线性组合可以覆盖整个二维空间的话,那么非零非平行的三个向量的线性组合是否可以覆盖整个三维空间呢?
【答案】:否
引入 independent 向量
在三维空间中对参与线性组合的向量不能仅仅给出【非零】【非平行】两个限制,还得加上一个【不在同一个二维平面】。试想,如果三个向量处在同一平面的话,那么不论如何线性组合都不可能与第三维有任何关系。
引入 反之不反
非零非平行 ===> 有解;有解 ==X==> 非零非平行。
引入 span
vector set 的所有可能的 linear combination (另一个vector set)就是这组 vector set 的 span。
\(v = c_1u_1+c_2u_2+...+c_ku_k\)
\(v\) 毫无疑问是一个向量。
如果我们穷举所有可能的\(c_1,c_2,...,c_k\),他们所得到的向量的集合(vector set \(V\))就是\(x_1,x_2,...,x_k\)的span,同时,\(x_1,x_2,...,x_k\) 叫做 vector set \(V\) 的 generating set.
引入 generating set
\(if\ Vector\ set\ V=Span(S),\ then\ V\ is\ Span\ of\ S, also\ S\ is\ a\ generating\ set\ for\ V,\ or\ S\ generates\ V\)
\(S\) 可以作为一种描述 \(V\) 特性的方法。为什么我们需要这种描述方法呢?因为 \(V\) 作为一个 span,他通常都非常非常的大(一般都是无穷多个),如果我们想要描述这种无穷大(“无穷”都意味着抽象)的向量的集合,最好的方法就是找到一个更具体(“有限”意味着具体)的可联想的“指标” --- generating set --- 这个向量集合是由什么样的向量集合生成的。
相同的向量集(span)可能由不同的向量集(generating set)产生:
\(S_1=\begin{vmatrix} 1 \\ -1\end{vmatrix}\)
同
\(S_2=\{\begin{vmatrix}1\\-1\end{vmatrix},\begin{vmatrix}-2\\2\end{vmatrix}\}\)
产生的向量集是相同的。
引入 span of standard vector
standard vector 其实就是 one-hot encoding vector. 可以见下:
\(e_1=\begin{vmatrix}1\\0\\0\end{vmatrix}, e_1=\begin{vmatrix}0\\1\\0\end{vmatrix}, e_1=\begin{vmatrix}0\\0\\1\end{vmatrix}\)
\(span(e_1)=one\ R^1\ in\ R^3\), one axis in 3D-space \(span(e_1,e_2)=one\ R^2\ in\ R^3\), one 2D-space in 3D-space \(span(e_1,e_2,e_3)=R^3\), whole 3D-space.
其实今天学的东西就是“换句话说”,
换句话说
换句话说
第三节课讲过,一个线性系统不仅仅是一条“直线”,直线只是一种特殊到不能再特殊的情况。线性系统的本质是:
'->' 以下表示线性系统
符合加法性:x->y ==> x1+x2->y1+y2
符合乘法(scalar)性:x->y ==> x1k->yk
再结合一个超级牛逼的观点广义向量 --- 函数也是一种向量。我们就把线性系统是一条直线的观点边界向外扩展了一些:
线性系统是以向量(亦即,包含函数和数字和普通向量)作为输入
现实世界中的很多东西都可以表示为向量,就连函数也不例外。
他可以造就这样的奇迹:
加法性:fn->fc ===> fn1 + fn2-> fc1+fc2
乘法性:fn->fc ===> fn1k->fc1k
也就是说,线性系统接收的输入和输出都是一个向量,而数字和函数只是特殊的向量。,满足这一特殊性质的线性系统就是【微分】and【积分】。微分和积分更像是一种【功能】而不是一个【函数】,这也是为什么我们不把系统说成函数的原因,因为他强调功能而不是记号表示性,或者说函数只是功能的一个可记号话的特例
线性代数这门学科研究的主要目标就是线性系统。
于是新的关于线性系统的定义至此形成:
\(vector\ \Rightarrow LinearSystem\ \Rightarrow vector\)
\(domain\ \Rightarrow LinearSystem\ \Rightarrow co-domain\)
可以证明的是(in lec3)任何线性系统都可以表示为联立线性等式,也就是说联立等式与线性系统是等价的
Linear system is equal to System of linear equations.
因为
矩阵=线性系统,
联立方程=线性系统,
所以
矩阵=联立方程。
联立方程式 ---> 按列看待matrix的 product of matrix and vector ---> 联立方程式可以写成 Product of matrix and vector. 因为之前说过任何一个线性系统都可以写成联立方程式,那么矩阵就是一个线性系统。
\(Ax=b\) 中的 \(A\) 就是一个线性系统
方差、平均值这些统计量的计算,都只能算是【叙述统计】。真正统计的核心在于【推理统计】,推理统计有两个学派:frequentist vs. bayesian (频率统计学派 vs. 贝叶斯学派)。
bayes 实际解决的是一个【推论 inference --- 我们想知道大自然是什么样子的,于是 collect 很多 data,根据这些data做推断,这就是 Inference】的问题。
【注意:教授说,预测和推断是有区别的, prediction and inference is different】
【注:这里从参数模型parameters model 来考虑】
a particular mathematical approach to apply probability to statistical problems.
incorporating our prior beliefs and evidence, to produce new posterior beliefs.
这是bayes学派的思路。而频率学派的思路是:对于模型的某个参数,先得到其【点估计】,然后给出这个点估计的【准确度 confidence?】, bayes 不是得到一个点估计,而是得到一个【distribution】
\(P(A|B) = \frac{P(B|A)P(A)}{P(B)}\)
\(P(B|A) = \frac{P(A|B)P(B)}{P(A)}\)
bayes 来自于 bayes' Rule --- 一个条件概率计算式子。
顺序:今天下雨,我带伞的概率; 逆序:今天带伞,外面下雨的概率;
\(P(\Theta|D)=\frac{P(D|\Theta)P(\Theta)}{P(D)}\)
因为 evidence 可以消掉,所以我们经常把 bayesian inference 写作:
\(P(\Theta|D)\propto P(D|\Theta)P(\Theta)\)
posterior propto likelihood * prior
频率学派和贝叶斯学派最大的不同在于,random 来自哪里,前者认为其来自 data,后者认为其来自 parameter
一般大学的统计学教学都是 频率学派,杜克大学是个例外,他是bayes学派。MLE 就是典型的频率学派的研究对象。这个学派的特点是得到的是模型参数的【点估计】,它认为在宇宙表象之后有一个【绝对的公理】在支配宇宙万事的运行,它认为 random 来自于 data,比如 linear model 只有两个参数 w and b,\(y = wx+b\),这个 linear model 的 w 和 b 是有两个绝对正确的量的(标准答案)。那为什么我学习or估测的这两个参数的结果会与标准答案不符合呢,是因为我的 data 来自于 random sample。
亦即:parameter is fixed, data is random.
所以,这也就解释了
why get a value not a distribution --- parameter is fixed.
Bayesian statistics: preserve and refine uncertainty by adjusting individual beliefs in light of new evidence.
bayes 学派得到的是模型参数的【分布】,认为这个参数并不是一个 fix 的值,这体现了统计学中 random 这一概念。与频率学派不同的是,bayes学派认为 data 已经在那了,我不可能去改 data 来 fit parameter,所以它认为: data is fixed, parameter is random. 它认为 parameter 不是固定的,而是符合某种分布的。比如 Linear model 的两个参数 w 和 b, bayesian 认为他们【没有绝对正确】的值,所以我寻找他的先验估计,通过 fitting 不同的 data 对其进行 update (ps:怎么看着有点像是 iterative 优化方法)从而得到 posterior, 而 posterior 就是模型对这个参数的估计。
Linear Regression model: \(y_i = w_0 + \sum_jw_jx_{ij}=w_0+w^Tx_i\)
Maximum Likelihood Estimation(MLE):
美国调查研究表明,一个人会更喜欢喜欢自己的人。
求人帮一个忙,是一种交换‘尊敬’的方法。
以此发展出的推销方法:
真理:当一个人帮过你一个忙,这个人就倾向于帮您一个更大的忙。
罗胖分享的第二个故事:
大妈出钱帮助创业公司,从中体会出一个特别重要的道理:
无论你在什么样的局面里,不论谁,会在你多么急迫的时刻,会冲出来帮你一把。所以,成为一个受欢迎的人,这不是你想讨好这个世界,是你想过好自己的一生,把这局无限游戏玩下去的必要条件。
找人帮忙,别人帮你一个忙,就会倾向于帮你一个更大的忙
尊重每一个人,喜欢别人。人的互惠天性导致会喜欢那些喜欢我们的人。
永远不要鄙视别人,这将永远得不到原谅
有实力,有用处,能够提供交换价值,这也是人生的意义所在。你的存在要能够改变一些东西的价值。
尊重要落到实处,要真诚,尽量不假手于他人。
之前介绍的所有方法都存在相同的弊病:
similar data are close, but different data may collapse,亦即,相似(label)的点靠的确实很近,但不相似(label)的点也有可能靠的很近。

\(x \rightarrow z\)
t-SNE 一样是降维,从 x 向量降维到 z. 但 t-SNE 有一步很独特的标准化步骤:
一, t-SNE 第一步:similarity normalization
这一步假设我们已经知道 similarity 的公式,关于 similarity 的公式在【第四步】单独讨论,因为实在神妙。
这一步是对任意两个点之间的相似度进行标准化,目的是尽量让所有的相似度的度量都处在 [0,1] 之间。你可以把他看做是对相似度进行标准化,也可以看做是为求解KL散度做准备 --- 求条件概率分布。
compute similarity between all pairs of x: \(S(x^i, x^j)\)
我们这里使用 Similarity(A,B) 来近似 P(A and B), 使用 \(\sum_{A\neq B}S(A,B)\) 来近似 P(B)
\(P(A|B) = \frac{P(A\cap B)}{P(B)} = \frac{P(A\cap B)}{\sum_{all\ I\ \neq B}P(I\cap B)}\)
\(P(x^j|x^i)=\frac{S(x^i, x^j)}{\sum_{k\neq i}S(x^i, x^k)}\)
假设我们已经找到了一个 low dimension z-space。我们也就可以计算转换后样本的相似度,进一步计算 \(z^i\) \(z^j\) 的条件概率。
compute similarity between all pairs of z: \(S'(z^i, z^j)\)
\(P(z^j|z^i)=\frac{S(z^i, z^j)}{\sum_{k\neq i}S(z^i, z^k)}\)
Find a set of z making the two distributions as close as possible:
\(L = \sum_{i}KL(P(\star | x^i)||Q(\star | z^i))\)
二, t-SNE 第二部:find z
我们要找到一组转换后的“样本”, 使得转换前后的两组样本集(通过KL-divergence测量)的分布越接近越好:
衡量两个分布的相似度:使用 KL 散度(也叫 Infomation Gain)。KL 散度越小,表示两个概率分布越接近。
\(L = \sum_{i}KL(P(\star | x^i) || Q(\star | z^i))\)
find zi to minimize the L.
这个应该是很好做的,因为只要我们能找到 similarity 的计算公式,我们就能把 KL divergence 转换成关于 zi 的相关公式,然后使用梯度下降法---GD最小化这个式子即可。
三,t-SNE 的弊端
因为 t-SNE 要求我们计算数据集的两两点之间的相似度,所以这是一个非常高计算量的算法。同时新数据点的加入会影响整个算法的过程,他会重新计算一遍整个过程,这个是十分不友好的,所以 t-SNE 一般不用于训练过程,仅仅用在可视化中,即便在可视化中也不会仅仅使用 t-SNE,依旧是因为他的超高计算量。
在用 t-SNE 进行可视化的时候,一般先使用 PCA 把几千维度的数据点降维到几十维度,然后再利用 t-SNE 对几十维度的数据进行降维,比如降到2维之后,再plot到平面上。
四,t-SNE 的 similarity 公式
之前说过如果一种 similarity 公式:计算两点(xi, xj)之间的 2-norm distance(欧氏距离):
\(S(x^i, x^j)=exp(-||x^i - x^j||_2)\)
一般用在 graph 模型中计算 similarity。好处是他可以保证非常相近的点才会让这个 similarity 公式有值,因为 exponential 会使得该公式的结果随着两点距离变大呈指数级下降。
在 t-SNE 之前有一个算法叫做 SNE 在 z-space 和 x-space 都使用这个相似度公式。
similarity of x-space: \(S(x^i, x^j)=exp(-||x^i - x^j||_2)\) similarity of z-space: \(S'(z^i, z^j)=exp(-||z^i - z^j||_2)\)
t-SNE 神妙的地方就在于他在 z-space 上采用另一个公式作为 similarity 公式, 这个公式是 t-distribution 的一种(t 分布有参数可以调,可以调出很多不同的分布):
\(S(x^i, x^j)=exp(-||x^i - x^j||_2)\) \(S'(z^i, z^j)=\frac{1}{1+||z^i - z^j||_2}\)
可以通过函数图像来理解为什么需要进行这种修正,以及这种修正为什么能保证x-space原来近的点, 在 z-space 依旧近,原来 x-space 稍远的点,在 z-space 会拉的非常远:
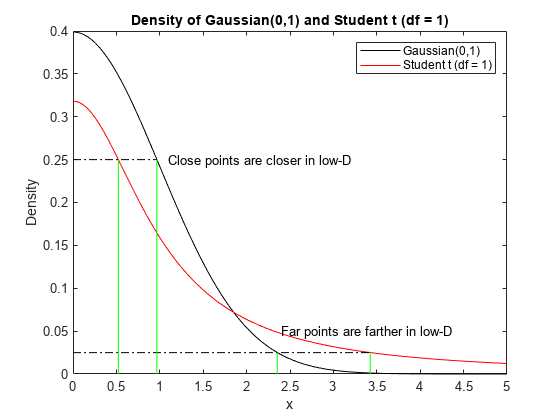
也就是说,原来 x-space 上的点如果存在一些 gap(similarity 较小),这些 gap 就会在映射到 z-space 后被强化,变的更大更大。

本节介绍三个相互依存的概念:单位向量,span,线性无关。
是一种新的看待线性代数的观点,非常重要的三个知识点,至此向量的表示可以变成在各个单位向量做放缩然后取和,或者,单位向量的线性组合:
\((-5)\hat{i} + (2)\hat{j}\)
可以表示为:
$$ \begin{vmatrix} -5 \\ 2 \end{vmatrix} $$
虽然不论使用什么方向的两个单位向量,其线性组合始终可以覆盖全部二维空间,但是我们仍然得到了同一个向量的两个不同的表示:
although \((3.1)\hat{i} + (-2.9)\hat{j} = \(-0.8)\hat{i}+(1.3)\hat{j}\) 但是该向量的实际表示却完全不同:
$$ \begin{vmatrix} -0.8 \\ 1.3 \end{vmatrix} \neq \begin{vmatrix} 3.1 \\ -2.9 \end{vmatrix} $$
所以这里需要给出一种关于线性代数的数字表示法\([3.1, -2.9]\)的一个基本条件:每当使用这种表示法时都必须明确单位向量是什么。
可以想象的是:
引入概念span
The "span" of \(\vec{v}\) and \(\vec{w}\) is the set of all their linear combinations:
\(a\vec{v} + b\vec{w}\)
let \(a\) and \(b\) vary over all linear numbers.
两个向量的 span 与另一个表述是等价的,仅仅通过加法和乘法两种操作可以产生的所有向量
【tips】如果仅仅考虑一个向量,经常将向量想象成带箭头线段;如果考虑一堆向量的集合,经常将向量想象成点。
任何时候如果你有多个向量,但是去掉其中一个或几个,前者和后者的span没有减少(span is essencially a set --- set of all possible linear combination)
\(span(\vec{v},\vec{w},\vec{u})=span(\vec{v},\vec{w})\)
那么就可以说这个向量与其他向量是 Linear dependent (线性相关), 或者说这个(可以去掉的)向量可以表示为其他向量的线性组合, 因为这个可以去掉的向量处在其他向量的span中。
\(redundant\ \vec{u} \in span(\vec{v}, \vec{w})\)
或者说,他对扩大span(set of linear combination of vectors)没有作用。
由此衍生出另一个概念:Linearly independent
\(\vec{u} \neq a\vec{v} + b\vec{w},\ for\ all\ values\ of\ a\ and\ b\)
如果某个单位向量无法通过其他单位向量的任何一种系数的线性组合来得到,那么就说这个向量与其他向量都是线性无关的
有了之前的 span linearly dependent 两个概念,下面才能正式定义第三个概念:何为 basis vector ?
The basis of a vector space is a set of linearly independent vectors that span the full space
ws---1 tb ----6 zs ---5 51 ---5 zhongyou---2 jd ---0.6 yr--- 7 ------- 26.6
xm---0.8 xykd---1.1 xhy ---0.89 wld---4.1 ppd---1.1 hb---1 msjr---2.2 suning-2 laifenqi---1 baidu---0.3 zljr---1.3 ------------16.8
total: 43.4
著名的 tSNE 算法('NE' --- Neighbor Embedding)
什么是 manifold,manifold 其实就是一个 2D 平面被卷曲起来成为一个3D物体,其最大的特点是3D空间中的两点之间Euclidean distance并不能衡量两者在(卷曲前)2D空间中的'远近',尤其是两者距离较大的时候,欧式几何不再适用 --- 3D远距离情况下欧式几何失效问题,在3D空间中欧式几何只能用在距离较近的时候。
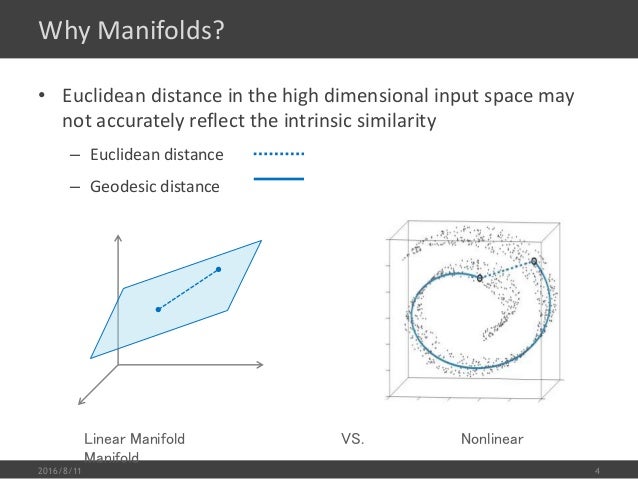
manifold learning 就是针对3D下欧式几何失效问题要做的事情就是把卷曲的平面摊平,这样可以重新使用欧式几何求解问题(毕竟我们的很多算法都是基于 Euclidean distance)。这种摊平的过程也是一种降维过程。
又是一种“你的圈子决定你是谁”的算法
第一步, 计算 w
针对每个数据集中的点,【选取】他的K(超参数,类似KNN中的K)个邻居,定义名词该\(x^i\)点与其邻居\(x^j\)之间的【关系】为:\(w_{ij}\), \(w_{ij}\) represents the relation between \(x^i\) and \(x^j\)
\(w_{ij}\) 就是我们要寻找的目标,我们希望借由 \(w_{ij}\) 使得 \(x^i\) 可以被K个邻居通过\(w_{ij}\)的加权和来近似,使用 Euclidean distance 衡量近似程度:
given \(x_i, x_j\),, find a set of \(w_{ij}\) minimizing
\(w_{ij} = argmin_{w_{ij},i\in [1,N],j\in [1,K]}\sum_i||x^i - \sum_jw_{ij}x^j||_2\)
第二步, 计算 z 做降维,keep \(w_{ij}\) unchanged, 找到 \(z_{i}\) and \(z_{j}\)将 \(x^i, x^j\) 降维成\(z^i, z^j\), 原则是保持 \(w_{ij}\) 不变,因为我们要做的是 dimension reduction, 所以新产生的 \(z_i, z_j\) 应该比 \(x_i, x_j\) 的维度要低:
given \(w_{ij}\), find a set of \(z_i\) minimizing
\(z_{i} = argmin_{z_{i},i\in [1,N],j\in [1,K]}\sum_i||z^i - \sum_jw_{ij}z^j||_2\)
LLE 的特点是:它属于 transductive learning 类似 KNN 是没有一个具体的函数(例如: \(f(x)=z\))用来做降维的.
LLE 的一个好处是:看算法【第二步】,及时我们不知道 \(x_i\) 是什么,但只要知道点和点之间的关系【\(w_{ij}\)】我们依然可以使用 LLE 来找到 \(z_i\) 因为 \(x_i\) 起到的作用仅仅是找到 \(w_{ij}\)
LLE 的累赘:必须对 K(邻居数量)谨慎选择,必须刚刚好才能得到较好的结果。
K 太小,整体 w (模型参数)的个数较少,能力不足,结果不好
K 太大,离 \(x_i\) 较远距离的点(x-space 就是卷曲的 2D 平面)也被考虑到,之前分析过 manifold 的特点就是距离太大的点 Euclidean distance 失效问题。而我们的公式计算 w 的时候使用的就是 Euclidean distance,所以效果也不好。
这也就是为什么 K 在 LLE 中非常关键的原因。
Graph-based approach, to solve manifold
算数据集中点的两两之间的相似度,如果超过某个阈值就连接起来,如此构造一个 graph。得到 graph 之后,【两点之间的距离】就可以被【连线的长度】替代,换言之 laplacian eigenmaps 并不是计算两点之间的直线距离(euclidean distance)而是计算两点之间的曲线距离:
回忆我们之前学习的 semi-supervised learning 中关于 graph-based 方法的描述:如果 x1 和 x2 在一个 high-density region 中相近,那么两者的标签(分类)相同,我们使用的公式是:
\(L=\sum_{x^r}C(y^r, \hat{y}^r)\) + \lambda S
\(S=\frac{1}{2}\sum_{i,j}w_{i,j}(y^i - y^j)^2=y^TLy\)
\(L = D - W\)
\(w_{i,j} = similarity between i and j if connected, else 0\)
同样的方法可以用在 unsupervised learning 中, 如果 xi 与 xj 的 similarity(\(w_{i,j}\)) 值很大,降维之后(曲面摊平之后)zi 和 zj 的距离(euclidean distance)就很近:
\(S=\frac{1}{2}\sum_{i,j}w_{i,j}(z^i - z^j)^2\)
但是仅仅最小化这个 S 会导致他的最小值就是 0,所以要给 z 一些限制 --- 虽然我们是把高维的扭曲平面进行摊平,但我们不希望摊平(降维)之后他仍然可以继续'摊'(曲面 ->摊平,依然是曲面 -> 继续摊), 也就是说我们这次摊平的结果应该是【最平的】,也就是说:
if the dim of z is M, \(Span{z^1, z^2, ..., z^N} = R^M\)
【给出结论】可以证明的是,这个 z 是 Laplacian (\(L\)) 的比较小的 eigenvalues 的 eigenvectors。所以整个算法才叫做 Laplacian eigenmaps, 因为他找到的 z 就是 laplacian matrix 的最小 eigenvalue 的 eigenvector.
结合刚才的 laplacian eigenmaps, 如果对 laplacian eigenmaps 找出的 z 做 clustering(eg, K-means) 这个算法就是 spectral clustering.
spectral clustering = laplacian eigenmaps reduction + clustering
Word Embedding 是 Diemension Reduction 一个非常好,非常广为人知的应用。
1-of-N Encoding 及其弊端
apple = [1 0 0 0 0]
bag = [0 1 0 0 0]
cat = [0 0 1 0 0]
dog = [0 0 0 1 0]
elephant = [0 0 0 0 1]
这个 N 就是这个世界上所有的单词的数量,或者你可以自己创建 vocabulary, 那么这个 N 就是 vocabulary 的 size.但是这样向量化的方式,太众生平等了,原本有一定关系的单词,比如 cat 和 dog 都是动物,这根本无法从 [0 0 1 0 0] 和 [0 0 0 1 0] 中看出任何端倪。
解决这件事情的一个方法是 Word Class
Word Class 及其弊端
先把所有的单词 cluster 成簇,然后用簇代替 1-of-N encoding 来表示单词。
虽然 Word Class 保留了单词的词性信息使得同类单词聚在一起,但是不同词性之间的关系依旧无法表达:名词 + 动词 + 名词/代词, 这种主谓宾的关系就没法用 Word Class 表示。
这个问题可以通过 Word Embedding 来解决
Word Embedding 把每个单词的 1-of-N encoding 向量都 project 到一个低维度空间中(Dimension Reduction),这个低维度空间就叫做 Embedding. 这样每个单词都是低维度空间中的一个点,我们希望:
相同语义的单词,在该维度空间中也相互接近
不但如此,当 Embedding 是二维空间(能够可视化)时,所有的点及其原本单词画在坐标图上之后,很容易就可以看到这个低维度的空间的每个维度(x,y轴)都带有具体的某种含义. 比如,dim-x 可能表示生物,dim-y 可能表示动作。
Word Embedding 本质上是【非监督降维】,我们之前学习的方法最直接的就是使用 autoencoder, 但用在这里很显然是无效的。因为你的输入是 1-of-N encoding 向量,在这种向量表示下每个输入样本都是 independent 的,也就是单个样本之间没有任何关系 --- 毫无内在规律的样本,你怎么可能学出他们之间的关系呢?(ps, 本来无一物,何处惹尘埃。)
我们的目的是让计算机理解单词的意思,这个完全不可能通过常规语言交流达此目的,所以需要曲径通幽,你只能通过其他方法来让计算机间接理解。最常用的间接的方法就是:understand word by its context.
及其肯定不知道马英九和蔡英文到底是什么,但是只要他读了【含有‘马英九’和‘蔡英文’的】大量的文章,知道马英九和蔡英文的前后经常出现类似的文字(similar context),机器就可以推断出“马英九”和“蔡英文”是某种相关的东西。
这种方法最经典的做法叫做 Glove Vector https://nlp.stanford.edu/projects/glove/
代价函数与 MF 和 LSA 的一模一样,使用 GD 就可以解,目标是找到越是经常共同出现在一篇文章的两个单词(num. of occur),越是具有相似的word vector(inner-product)。
这种【越是。。。越是。。。】的表达方式,就可以使用前一个“越是”的量作为后一个“越是”的目标去优化。
越是 A,越是 B ===> \(L = \sum(A-B)^2\)
if two words \(w_i\) and \(w_j\) frequently co-occur(occur in the same document), \(V(w_i)\) and \(V(w_j)\) would be close to each other.
核心思想类似 MF 和 LSA:
\(V(w_i) \cdot V(w_j) \Longleftrightarrow N_{i,j}\)
\(L = \sum_{i,j}(V(w_i)\cdot V(w_j) - N_{i,j})^2\)
find the word vector \(V(wi)\) and \(V(w)\), which can minimize the distance between inner product of thses two word vector and the number of times \(w_i\) and \(w_j\) occur in the same document.
prediction based 获取 word vector 是通过训练一个 单层NN 用 \(w_{i-1}\) 预测 \(w_i\) 单词的出现作为样本的数据和标签(\(x=w_{i-1}, y=w_i\)),选取第一层 Hiden layer 的输入作为 word vector.
【注意】:上面不是刚说过 autoencoder 学不到任何东西么,那是因为 autoencoder 的input 和 output 都是单词 \(w_i\),亦即(\(x=w_i, y=w_i\)),但是这里 prediction-based NN 用的是下一个单词的 1-of-encoding 作为label.
本质是用 cross-entropy 作为loss-fn训练一个 NN,这个 NN 的输入是某个单词的 1-of-encoding, 输出是 volcabulary-size 维度的(概率)向量--- 表示 volcabulary 中每个单词会被当做下一个单词的概率。
$$ Num.\ of\ volcabulary\ = 10w $$
$$ \begin{vmatrix} 0 \\ 1 \\ 0 \\ 0 \\ 0 \\.\\.\\. \end{vmatrix}^{R^{10w}} \rightarrow NN \rightarrow \begin{vmatrix} 0.01 \\ 0.73 \\ 0.02 \\ 0.04 \\ 0.11 \\.\\.\\. \end{vmatrix}^{R^{10w}} $$
训练好这个 prediction-based NN 之后,一个新的词汇进来就可以直接用这个词汇的 1-of-N encoding 乘以第一层隐含层的权重,就可以得到这个单词的 word vector.
$$ x_i = 1-of-N\ encoding\ of\ word\ i $$
$$ W = weight\ matrix\ of\ NN\ between\ input-layer\ and\ 1st-hidden-layer $$
$$ WordVector_{x_i} = W^Tx_i $$
【注意】虽然这里的例子不是单词,但意会一下即可。
因为 “马英九” 和 “蔡英文” 后面跟的都是 “520宣誓就职”,所以用在 prediction-based NN 中
也就是说给 prediction-based NN 输入 马英九 or 蔡英文的时候 NN 会“努力”把两个不同的输入 project 到同一个输出上。那么之后的每一层都会做这件事情,所以我们可以使用第一层的输入来做为 word vector.
一般情况下我们不会只用前一个单词去预测下一个单词(\(w_{i-1} \Rightarrow w_i\)),并抽取 1st layer's input 作为 word vector, 我们会使用前面至少10个词汇来预测下一个词汇(\([w_{i-10}, w_{i-9}, ..., w_{i-1}] \Rightarrow w_i\))
如果使用不同的权重,(以前两个预测下一个为例)
[w1:马英九] + [w2:宣誓就职时] => [w3:说xxxx]
[w1:宣誓就职时] + [w2:马英九] => [w3:说xxxx]
如果使用不同的权重,那么 [w1:马英九] + [w2:宣誓就职时] 和 [w1:宣誓就职时] + [w2:马英九] 就会产生不同的 word vector.
具体过程描述如下:
|z| : word vector size, the dimension of embedding space
the length of \(x_{i-1}\) and \(x_{i-2}\) are both |V|.
How to make wi equal to wj?
Given wi and wj the same initialization, and the same update per step.
\(w_0 = w_0\)
\(w_i \leftarrow w_i - \eta \frac{\partial C}{\partial w_i} - \eta \frac{\partial C}{\partial w_i}\)
\(w_i \leftarrow w_i - \eta \frac{\partial C}{\partial w_i} - \eta \frac{\partial C}{\partial w_i}\)
\([w_{i-1}, w_{i+1}] \Rightarrow w_i\)
\(w_i \Rightarrow [w_{i-1}, w_{i+1}]\)
有了 word vector, 很多关系都可以数字化(向量化)
两类词汇的 word vector 的差值之间存在某种平行和相似(相似三角形or多边形)性,可以据此产生很多应用。
\(WordVector_{China} - WordVector_{Beijing} // WordVector_{Spain} - WordVector_{Madrid}\)
for \(WordVector_{country} - WordVector_{capital}\), if a word A \(\in\) country, and word B \(\in\) capital of this country, then \(A_0 - B_0 // A_1 - B_1 // A_2 - B_2 // . ..\)
问题回答也是这个思路---利用word vector差值是相互平行的。
\(V(Germany) - V(Berlin) // V(Italy) - V(Rome)\)
\(vector = V(Berlin) + V(Italy) - V(Rome)\)
\(find\ a\ word\ from\ corpus\ whose\ word\ vector\ closest\ with\ 'vector'\)
学习 word embedding prediction-based NN 的网络原理(单层; 前后单词为一个样本;取第一层输入)可以实现更进一步的应用。
先获取中文的 word vector, 然后获取英文的 word vector, (这之后开始使用 prediction-based NN 的原理)然后 learn 一个 NN 使得他能把相同意思的中英文 word vector 投影到某个 space 上的同一点,这之后提取这个网络的第一层 hidden layer 的输入权重,就可以用来转换其他的英文和中文单词到该 space 上,通过就近取意的方法获取该单词的意思。
这里也是学习 word embedding prediciton-based NN 的网络原理,他可以实现扩展型图像识别,一般的图像识别是只能识别数据集中已经存在的类别,而通过 word embedding 的这种模式,可以实现对图像数据集中不存在(但是在 word 数据集中存在)的类别也正确识别(而不是指鹿为马,如果image dataset 中原本没有 ‘鹿’ 的话,普通的图像识别会就近的选择最'像'的类别,也就是他只能在指定的类别中选最优的)。
先通过大量阅读做 word vector, 然后训练一个 NN 输入为图片,输出为(与之前的 word vector)相同维度的 vector, 并且使得 NN 把与 word(eg, 'dog') 相同类型的image(eg, dog img) project 到该word 的 word vector 附近甚至同一点上。
如此面对新来的图片比如 '鹿.img', 输入给这个 NN 他就会 project 到 word vector space 上的 “鹿” 周围的某一点上。
如何把 document 变成一个 vector 呢?
首先把 document 用 bag of word(a vector) 来表示,然后将其输入给一个 auto encoder , autoencoder 的 bottle-neck layer 就是这篇文章的 embedding vector。
这里与使用 autoencoder 无法用来做 word embedding 的道理是一样的,只不过对于 word embedding 来说 autoencoder 面对的是完全相互 independent 的 1-of-N encoding, 其本身就无规律可言,所以 autoencoder 不可能学到任何东西,所以没有直接规律,就寻找间接规律 通过学习 context 来判断单词的语义。
这里 autoencoder 面对的是 document(bag-of-word), bag of word 中包含的信息仅仅是单词的数量 (大概是这样的向量\([22, 1, 879, 53, 109, ....]\))不论 bag-of-word(for document) 还是 1-of-N encoding(for word) 都是语义缺乏的编码方式。所以想通过这种编码方式让NN萃取有价值的信息是不可能的。
还是那个原则没有直接规律,就寻找间接规律:
1-of-N encoding, lack of words relationship, what we lack, what we use NN to predict, we discover(construct) some form of data-pair (x -> y) who can represent the "relationship" to train a NN , and the BY-PRODUCT is the weight of hiden layer --- a function(or call it matrix) who can project the word to word vector(a meaningful encoding)
bag-of-word encoding, lack of words ordering(another relationship), using (李宏毅老师没有明说,只列了 reference)
white blood cells destroying an infection
an infection destroying white blood cells
they have same bag-of-words, but vary differentmeaning.
word embedding, 降维,创造关系,非监督
似乎非监督真的很有用。再思考思考
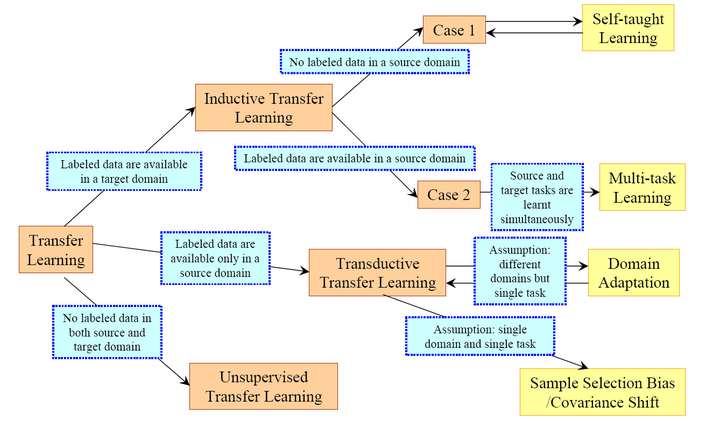
其中,后五者其实都可以看做迁移学习的子类。
转导学习的典型算法是 KNN:
由上述过程可见:
我们使用了 unlabeled data 作为测试集数据,并使用之决定新的中心点(新的分类簇)
这就是课件中所说的:
Transfuctive learning: unlabeled data is the testing data.
归纳学习的典型算法是 Bayes:
\(P(y|x) = \frac{P(x|y)P(y)}{P(x)=\sum^K_{i=1}{P(x|y_i)P(y_i)}}\)
通过 count-based method 和 Naive Bayes 或者 Maximum Likelihood(详见 lec5 笔记)(
\(P([1,3,9,0] | y_1)=P(1|y_1)P(3|y_1)P(9|y_1)P(0|y_1)\) ) 先计算出:
\(P(x|y_1)P(y_1)\)
\(P(x|y_2)P(y_2)\)
\(P(x|y_3)P(y_3)\)
...
然后就可以带入 Bayes 公式,就可以得到一个模型公式。
\(P(y|x) = \frac{P(x|y)P(y)}{P(x)=\sum^K_{i=1}{P(x|y_i)P(y_i)}}\)
由此可见,inductive 和 transductive 最大的不同就是,前者会得到一个通用的模型公式,而后者是没有模型公式可用的。新来的数据点对于 inductive learning 可以直接带入模型公式计算即可,而 transductive learning 每次有新点进来都需要重新跑一次整个计算过程。
对于通用模型公式这件事,李宏毅老师 lec5-LogisticRegression and Generative Model 中提到:
Bayes model 会脑补出数据集中没有的数据。
这种脑补的能力会使得他具有一些推理能力,但同时也会犯一些显而易见的错误。
而 transudctive learning 则是针对特定问题域的算法。
在 inductive learning 中,学习器试图自行利用未标记示例,即整个学习过程不需人工干预,仅基于学习器自身对未标记示例进行利用。
transductive learning 与 inductive learning 不同的是
transfuctive learning 假定未标记示例就是测试例,
即
学习的目的就是在这些未标记示例上取得最佳泛化能力。
换句话说:我处理且只处理这些点。
inductive learning 考虑的是一个“开放世界”,即在进行学习时并不知道要预测的示例是什么,而直推学习考虑的则是一个“封闭世界”,在学习时已经知道了需要预测哪些示例。
实际上,直推学习这一思路直接来源于统计学习理论[Vapnik],并被一些学者认为是统计学习理论对机器学习思想的最重要的贡献1。其出发点是不要通过解一个困难的问题来解决一个相对简单的问题。V. Vapnik认为,经典的归纳学习假设期望学得一个在整个示例分布上具有低错误率的决策函数,这实际上把问题复杂化了,因为在很多情况下,人们并不关心决策函数在整个示例分布上性能怎么样,而只是期望在给定的要预测的示例上达到最好的性能。后者比前者简单,因此,在学习过程中可以显式地考虑测试例从而更容易地达到目的。这一思想在机器学习界目前仍有争议
有时候你会有两种 object, 他们之间由某种共通的 latent factor 去操控。
比如我们都会喜欢动漫人物,但我们不是随随便便就喜欢的,而是说在我们自己的性格和动漫人物的性格背后隐含着某个相同的“属性列表”
每个人根据自己的【特点】都可以看成是【属性列表】中的一个向量或是高维空间中的一个点(向量),每个动漫人物也可以根据其【特点】看成是【属性列表】中的一个向量或高维空间中的一个点(向量)。
如果这两个向量很相似的话,那么两者 match,就会产生【喜欢】
假设:
现在:
【注意】这个 latent vector 的数目是试出来的,一开始我们并不知道。
比如 latent attribute = ['傲娇', '天然呆']
person A : \(r^A = [0.7, 0.3]\)
character 1: \(r^1 = [0.7, 0.3]\)
\(r^A \cdot r^1 = 0.58\)
$$ X \in R^{M*N} \approx \begin{vmatrix} r^A \\ r^B \\r^C\\.\\.\\. \end{vmatrix}^{M*K} * \begin{vmatrix} r^1 & r^2 & r^3 &.&.&. \end{vmatrix}^{K*N} $$
这个问题可以直接使用 SVD 来解决,虽然SVD分解得到的是三个矩阵,你可以视情况将中间矩阵合并给前面的或后面的
上面的是理想情况:table X 中所有的值都完备;
现实情况是:tabel X 通常是缺值的,有很多 Missing value. 那该如何是好呢?
使用 GD,来做,目标函数是:
\(L = \sum_{(i,j)}(r^i \cdot r^j - n_{ij})^2\)
通过对这个目标函数最小化,就可以求出 r.
然后就可以用这些 r 来求出 table 中的每一个值。
MF 的求值函数(table X 的计算函数,我们之前一直假设他是两个 latent vector 的匹配程度)可以考虑更多的因素。他不仅仅可以表示匹配程度。
从: \(r^A \cdot r^1 \approx 5\) 到更精确的: \(r^A \cdot r^1 + b_A + b_1\approx 5\)
如此新的 GD 优化目标就变成:
\(L = \sum_{(i,j)}(r^i \cdot r^j + b_i + b_j - n_{ij})^2\)
也可以加 L1 - Regularization, 比如 \(r^i, r^j\) 是 sparse 的---喜好很明确,要么天然呆,要么就是傲娇的,不会有模糊的喜好。
MF 技术用在语义分析就叫做 LSA(latent semantic analysis):
注意:通常我们在做 LSA 的时候还会加一步操作,term frequency always weighted by inverse document frequency, 这步操作叫做 TF-IDF.
也就是说,你用作 \(L = \sum_{(i,j)}(r^i \cdot r^j + b_i + b_j - n_{ij})^2\) 中的 \(n_{ij}\) 不是原始的某篇文章中的某个单词的出现次数,而是出现次数乘以包含这个单词的文章数的倒数亦即,
(n_{ij} = \frac{TF}{IDF})\
如此当我们通过 GD 找到 latent vector 时,这个向量的每一个位表示的是 topics(财经,政治,娱乐,游戏等)
根据之前通过 SVD 矩阵分解得到的结论: u = w
和公式:\(\hat{x} = \sum_{k=1}^Kc_kw^k \approx x-\bar{x}\)
再结合线性代数的知识,我们可以得到,能让 reconstruction error 最小的 c 就是:
\(c^k = (x-\bar{x})\cdot w^k\)
结合这两个公式,我们就可以找到一个 Autoencoder 结构:
$$ \begin{vmatrix} x_1 - \bar{x} \\ x_2 - \bar{x} \\ .\\.\\. \end{vmatrix} \Rightarrow \begin{vmatrix} c^1 \\ c^2 \end{vmatrix} \Rightarrow \begin{vmatrix} \bar{x_1} \\ \bar{x_2} \\ .\\.\\. \end{vmatrix} $$
autoencoder 的缺点 --- 无法像 PCA 一样得到完美的数学解
这样一个线性的 autoencoder 可以通过 Gradient Descent 来求解,但是 autoencoder 得到的解只能无限接近 PCA 通过 SVD 或者 拉格朗日乘数法的解,但不可能完全一致,因为 PCA 得到的 W 矩阵是一个列和列之间都相互垂直的矩阵,autoencoder 确实可以得到一个解,但无法保证参数矩阵 W 的列之间相互垂直。
autoencoder 的优点 --- 可以 deep,形成非线性函数,面对复杂问题更 power
PCA 只能做压扁不能做拉直
就像下面显示的这样,PCA 处理这类 manifold(卷曲面)的数据是无能为力的。他只能把数据都往某个方向压在一起。

而 deep autoencoder 可以处理这类复杂的降维问题:

你要把数据降到几维度,是你可以自己决定的,但是有没有什么比较好的数学依据来hint这件事情呢?
常用的方法是:
\(eigen\ ratio\ = \frac{\lambda_i}{\lambda_1 + \lambda_2 + \lambda_3 + \lambda_4 + \lambda_5 + \lambda_6}\)
我们求解 PCA 的函数的时候给出的结论是:
W 的列是 \(S=Cov(x)\) 的topmost K 个 eignen values 对应的 eigen vectors.
eigen values 的物理意义是降维后的 z 空间中的数据集在这一维度的 variance。
在决定 z 空间的维度之前,我们引入一个指标: eigen ratio,这个指标有什么用呢?他能帮助我们估算出前多少个 eigen vector 是比较合适的。
假设我们预先希望降维到 6 dimension,那么我们就可以通过之前学到的方法得到 6 个 eigen vector 和 6 个 eigen value, 同时也可以得到 6 个 eigen ratio.
通过这 6 个 eigen ratio 我们就可以看出谁提供的 variance 是非常小的(而我们的目标是找到最大 Variance(z))。eigen ration 太小表示映射之后的那个维度,所有的点都挤在一起了,他没什么区别度,也就是提供不了太多有用的信息。
之前没有提过,component 的维度应该是与原始 x 样本的维度是一致的,因为你可以把 component 看成是原始维度的一种组合(笔画 <- 像素)。
以宝可梦为例,说明: 如果把原本 6 个维度的宝可梦,降维到4维度,可以发现的是这个 4 个 componets 大概的物理意义是:
'component' 不一定是 ‘部分’。
对手写数字图片进行降维
对人脸图片进行降维

上面的图片所展示的似乎异于我们期望看到的啊!
我们一直强调 component 似乎是一种部分与整体的感觉,而这里给出的图片似乎是一种图层的感觉 --- 每一张 'component' 给出的不是笔画和五官,而是完整的数字和脸的不同颜色or阴影。
提出一种可能性:先看之前的公式,
$$ img_9 = c_1w_1 + c_2w_2 + ... $$
由于我们并没有限制,factor 系数的符号(factor 可正可负),所以他极有可能做的一件事情是,
为了生成图片 数字9,我的第一个component可以比较复杂,比如图片数字8,给与其正的factor,第二个component可以是一个0,给与其正的factor,第三个component可以是一个 6,给与其负值的factor
这样 img8 + img0 - img6 看上去就约等于 img9 了。
PCA 我们使用的分解是 SVD 或者 lagrange multiplier. 这种方法无法保证我得到的 component 和 其对应的 factor 都是正的。于是可以使用 NMF(non-negative matrix factorization)
NMF:
李宏毅老师没有具体讲解这个方法,只列出索引:
Algorithms for non-negative matrix factorization
如下图, NMF 使用的 components 更像是 ‘部分’ 而不是 ‘滤镜’

Basic Component can ba analogy to sample after projection
可以从比较形象的角度来理解 PCA,之前的角度是从x -> z , PCA 其本质就是一个线性函数,把 x 空间中一点,转换到 z 空间中一点。
$$ img_{28*28} \rightarrow x = \begin{vmatrix} 204 \\ 102 \\ 0 \\ 1 \\ . \\ . \\ . \end{vmatrix}^{784*1} \rightarrow z = \begin{vmatrix} 1 \\ 0.5 \\ 0 \\ 1 \\ 0.3 \end{vmatrix} $$
如果把 z 的每一位都看成是某种笔画的系数,那么我们就可以用另外一种方式来表示一张图片:
$$ x - \bar{x} \approx c_1u_1 + c_2u_2 + ... + c_ku_k = \hat{x} $$
这就提供了另一种看待问题的视角:
于是优化目标的函数也就改变了:
$$ argmax_{w_i} Var(x) = \sum_x(x-\bar{x})^2, with\ ||w_i||_2 = 1, and\ w_i \cdot \{w_j\}_{j=1}^{i-1} = 0 $$
\(argmin_{u_1, ..., u_K}\sum||(x-\bar{x}) - (\sum_{k=1}^Kc_ku_k)||_2\)
\(\sum_{k=1}^Kc_ku_k = \hat{x}\)
可以证明的是:这个 \(\{u_k\}_{k=1}^K\) 就是我们要找的 \(\{w_k\}_{k=1}^K\)
$$ \begin{vmatrix} z_1 \\ z_2 \\ . \\. \\. \\z_K \end{vmatrix} = \begin{vmatrix} w_1 \\ w_2 \\ . \\. \\. \\w_K \end{vmatrix} x = \begin{vmatrix} u_1 \\ u_2 \\ . \\. \\. \\u_K \end{vmatrix} x $$
$$ x^1 - \bar{x} \approx c_1^1u^1 + c_2^1u^2 + ... $$
$$ x^2 - \bar{x} \approx c_1^2u^1 + c_2^2u^2 + ... $$
$$ x^3 - \bar{x} \approx c_1^3u^1 + c_2^3u^2 + ... $$
【注意】component 对任意样本都是一样的,样本之间不同的是component的系数(权重)
我们可以把上面 3 个式子组合成矩阵的形式:
可以写成 向量 = 矩阵 * 向量
$$ c_1^2u^1 + c_2^2u^2 + ... = \sum_{k=1}^Kc_k^1u^k = [u^1, u^2, ...] \cdot \begin{vmatrix}c_1^1\\c_2^1\\.\\.\\.]\end{vmatrix} $$
可以写成 矩阵 = 矩阵 * 矩阵
$$ \underbrace{[x^1 - \bar{x}, x^2-\bar{x}, x^3-\bar{x}, ...]}_{\text{dataset:X}} \approx \underbrace{[u^1, u^2, ...]}_{\text{components matrix}} \cdot \underbrace{ \begin{vmatrix} c_1^1 & c_1^2 & c_1^3\\ c_1^1 & c_1^2 & c_1^3\\ c_1^1 & c_1^2 & c_1^3\\ .&.&.\\ .&.&.\\ .&.&. \end{vmatrix}}_{\text{factor matrix}} \text{how to find the best u to make two side of approx as near as possible?} $$
我们可以使用 SVD 矩阵分解,对 X 进行分解:
X 可以分解成3个矩阵的乘积:
\(X_{m*n} \approx U_{m*k} \Sigma_{k*k}V_{k*n}\)
这里直接给出答案,具体过程见线性代数课程。
K columns of U: a set of orthonormal eigen vectors corresponding to the k largest eigenvalues of \(XX^T\)
这个 \(XX^T\) 就是 \(Cov(x)\) , 因为这里的 X 是由 \(x - \bar{x}\) 得到的。所以,u = w。
再回忆下我们对于 u w 和 z 的定义:
启示:PCA 找出的那些 w(转换矩阵 W 的 columns) 就是 components
一,例子1 为什么 Dimension Reduction 可能是有用的,如下图示:

如果我们用 3 dimension 的样本维度去描述他其实是非常浪费的,因为很明显他是卷曲在一起的,如果我们有办法把他展平,不同类型(不同颜色代表不同类型)就很容易区隔开,而展平之后我们只需要 2 dimension 的样本维度。所以根本不需要把这个问题放在 3d 中去考虑,2d 就可以了。

二,例子2
在手写数字辨识的任务中,你或许根本用不到 28*28 的维度,比如数字 3 他可能有很多形态,但其实大部分都是旋转一下角度而已,所以对于辨识 3 这件事可能需要的维度仅仅是一个旋转角度而已(1维度)
对数据降维就是找一个function
\(f(x) \rightarrow x', dim(x) >> dim(x')\)
PCA 的本质就是通过一个一次线性函数 \(W^Tx\)把高维度的数据样本转换为低维度的数据样本。就像 \(w^Tx\) 如果\(W^T\)矩阵只有一行,这个函数就是两个向量的内积 --- 结果是一个(一维)数值,如果 \(W^T\) 是一个矩阵,那么 \(W^T\) 有多少行最终内积结果就有多少维:
$$ R_W^{1*N} \cdot R_x^{N*1} = R_{x'}^{1*1} R_W^{2*N} \cdot R_x^{N*1} = R_{x'}^{2*1} ... $$
\(f(x) \rightarrow x', dim(x) >> dim(x')\)
\(z = Wx, to\ find\ 'W'\)
该如何找到 W 呢,从最简单的开始,我们假设 :
如此一来,'z' 就可以看做是 'x' 在 'w' 方向上的投影(内积的几何意义)。
所有的 x: \(x^1, x^2, x^3,...\) 都在 w 方向上做投影就得到了 z: \(z^1, z^2, z^3,...\) , 而我们要做的就是从:
如何找到 W 变成 找到一个 x 的更好的投影方向
we want the variance of \(z_1\) as large as possible.
variance 在图像上的表现就是,投影之后的 z 的取值范围(值域),取值范围越大variance越大。
对于投影到一维空间,找到最佳的 w('w' is a row vector) 使得 x('x' is N dimension) 投影到该方向得到的 z ('z' is a digit)的 variance 是最大的, 用公式表示就是:
\(find\ a\ w\ to\ maximize:\)
\(Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2)\)
\(with\ constaint\ :\ ||w_1||_2=1\)
对于投影到二维(甚至多维)空间,我们要给每个后面的w一个限制就是: 后面的 w(n+1 th row) 要跟前面的所有 w({1~n} rows) 相互垂直, \(w_{n+1} \cdot \{w_{i}\}_{i=1}^n = 0\).
整体来看就是:
the 1st row of W should be:
\(w_1 = argmax(Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2)\)
\(constraint:\ ||w_1||_2=1\)
the 2nd row of W should be:
\(w_2 = argmax(Var(z_2) = \sum_{z_2}(z_2 - \bar{z_2})^2)\)
\(constraint:\ ||w_2||_2=1, w_2 \cdot w_1 = 0\)
the 3rd row of W should be:
\(w_3 = argmax(Var(z_3) = \sum_{z_3}(z_3 - \bar{z_3})^2)\)
\(constraint:\ ||w_3||_2=1, w_3 \cdot w_1 = 0, w_3 \cdot w_2 = 0\)
.......
then the W should be:
$$ W = \begin{vmatrix} (w_1)T \\ (w_2)T \\ . \\ . \\ . \end{vmatrix}\quad $$
这里 W 会是一个 Orthogonal matrix, 因为每一行的 norm 都等于1,并且行行之间相互垂直。
Lagrange multiplier 可以把带限制条件的优化问题转换>为无限制优化问题: target - a(zero_form of >constraint1) - b(zero_form of constraint2)
无限制的优化问题,就可以通过
偏微分=0来找到最优解
如果 W 矩阵只有一行
$$ one\ x\ one\ z_1 \bar{z_1} = \sum{z_1} = \sum{w_1 \cdot x} = w_1 \cdot \sum x = w_1 \cdot \bar{x} Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 $$
对于 \(w \cdot (x - \bar{x})\), 他是两个向量的内积,对于这种内积的平方,要注意如下的惯用转换公式(值得记住)。
$$ (a \cdot b)^2 = (a^Tb)^2 $$
因为 \(a \cdot b\) 是内积,是一个数值,数值的平方无关乎顺序,所以可以写成:
$$ (a^Tb)^2 = a^Tba^Tb $$
因为 \(a \cdot b\) 是内积,是一个数值,数值的转置还是自身,所以可以写成:
$$ (a^Tba^Tb = a^Tb(a^Tb)^T $$
化简之后:
$$ a^Tb(a^Tb)^T = a^Tbb^Ta $$
所以之前 var 的式子可以化简为:
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 $$
因为是对 x 来求和,所以 w 可以提出去:
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 = (w_1)^T(\sum_x(x-\bar{x})(x-\bar{x})^T)w_1 $$
其中 \(\sum_x(x-\bar{x})(x-\bar{x})^T\) 是什么,这个是 x 向量(样本都是向量)的 covariance matrix. covariance 是对称且半正定对的, 也就是说所有的 eigenvalues 都是非负的
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 = (w_1)^T(\sum_x(x-\bar{x})(x-\bar{x})^T)w_1 = (w_1)^TCov(x)w_1 $$
我们设 \(S = Cov(x)\) ,于是我们得到了一个新的优化问题:
find w1 maximizing:
\(w_1^T S w_1, with\ constraint\ ||w_1||_2 = 1, means\ w_1^Tw_1 = 1\)
Lagrange multiplier is target - zero_form of constraints
之前说明过 \(w_1\) 是 W 矩阵的第一个row,再次提醒下。
\(g(w_1) =w_1^TSw_1 - \alpha(w_1^Tw_1 - 1)\)
\(\frac{\partial g(w_1)}{\partial w_{11}} = 0\)
\(\frac{\partial g(w_1)}{\partial w_{12}} = 0\)
....
通过对 Lagrange 式子 \(g(w_1)\) 的微分为0来求最大最优的w,可以得到如下化简后的式子:
\(Sw_1 - \alpha w_1 = 0\)
\(Sw_1 = \alpha w_1\)
这种形式我们就熟悉了,\(w_1\) 是 S 的 eigen vector
但是这样的 w1 有很多,因为 S 的 eigen vector 有很多,所以 w1 的潜在选择也很多,哪一个是最好的选择呢?通过我们的优化目标来判断。
\(w_1^TSw_1 = \alpha w_1^Tw_1 = \alpha\)
而这里的 \(\alpha\) 是 eigen value,
所以,因为我们要最大化的目标最后等于 alpha, 而 alpha 是 eigen value, 所以我们选择最大的 eigen value, 一个 eigen value 对应一个 eigen vector, 所以最优的 w1 就是最大的 eigen value 对应的那个 eigen vector.
之前分析过, Find w2 的情况与 Find w1 略有不同,不同在优化问题的限制条件多出一个与之前所有的w都垂直,那么就是:
\(Find\ w_2\ maximizing: w_2^TSw_2, w_2Tw_2=1, w_2^Tw_1=0\)
按照 目标函数 - 系数*zero_form of 限制条件 的拉格朗日使用方法,可以得到如下无限制条件的优化问题:
如果 W 矩阵有多行
对于 W 矩阵有多行的情况,优化目标函数需要改变, 要增加限制条件,如果不加改变的话你得到的 wn 永远与 w1 一样,增加的这个限制条件是:后面的每个w都要与前面的所有w相互垂直 --- 内积为0。
\(Find\ w_2\ maximizing:\)
$$ g(w_2) = w_2^TSw_2 - \alpha(w_2^Tw_2-1)-\beta(w_2^Tw_1-0) $$
同样的通过微分等于0来求无限制条件的优化问题:
\(\frac{\partial g(w_1)}{\partial w_{11}} = 0\)
\(\frac{\partial g(w_1)}{\partial w_{12}} = 0\)
化简上述结果可以得到:
\(Sw_2 - \alpha w_2 - \beta w_1 = 0\)
上述等式两边同时乘以 w1:
\(w_1^TSw_2 - \alpha w_1^Tw_2 - \beta w_1^Tw_1 = 0\)
\(w_1^TSw_2 - \alpha * 0 - \beta * 1 = 0\)
因为 \(w_1^TSw_2\) 本身是一个 向量矩阵向量 的形式,他是一个数值,数值的转置还是自身:
\(w_1^TSw_2 = (w_1STw_2)^T = w_2^TS^Tw_1\)
因为 S 是 Covariance Matrix of x, 是对称的,所以 \(S^T=S\)
\(w_2^TS^Tw_1= w_2^TSw_1\)
使用 w1 的结论,\(Sw_1 = \lambda_1w_1\), 所以有
\(w_2^TSw_1=\lambda_1w_2^Tw_1=0\)
所以,综合起来看:
\(w_1^TSw_2 - \alpha w_1^Tw_2 - \beta w_1^Tw_1 = 0\)
\(w_1^TSw_2 - \alpha * 0 - \beta * 1 = 0\)
\(0 - \alpha * 0 - \beta * 1 = 0\)
所以:
\(\beta=0\)
所以:
\(Sw_2 - \alpha w_2= 0\)
\(Sw_2 = \alpha w_2\)
由于 w2 也是 eigen vector, 同样有很多选择,与 w1 选择的依据一样,我们只能选择剩下最大的那个 eigenvalue of S 对应的 eigenvector
so,结论是:
$$ z = Wx $$
$$ W = \begin{vmatrix} (w_1)T \\ (w_2)T \\ . \\ . \\ . \end{vmatrix}\quad $$
$$ W = \begin{vmatrix} 1st\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ 2nd\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ 3rd\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ ...\end{vmatrix} $$
数据点的各个维度互相垂直
用数学语言来表述就是
数据点的协方差矩阵是一个 Diagonal matrix
也就是
数据点的各个维度之间没有 correlation
这样有什么作用呢?
一个很好的作用是,原来的 data 经过 PCA 之后输出的新的 data 可以接其他较为简单的(或是对数据点维度要求无 correlation 的)model ---> eg. Naive Bayes.
$$ Cov(z) = \sum(z - \bar{z})(z-\bar{z})^T $$
这一项,可以可以展开合并后成为下面这种形式:
$$ Cov(z) = \sum(z - \bar{z})(z-\bar{z})^T = WSW^T,\ \ S = Cov(x) $$
$$ W^T=\begin{vmatrix} w_1 \\ .\\.\\.\\ w_k \end{vmatrix}^T= [w_1, ..., w_k] $$
注意转置之前 w1 是 W矩阵的行向量,转置后,w1 是 W^T 的 列向量:
$$ \begin{vmatrix} 1 & 2 & 3 & \rightarrow w_1\\ 4 & 5 & 6 & \rightarrow w_2 \\ 7 & 8 & 9 & \rightarrow w_3 \end{vmatrix}^T \rightarrow \begin{vmatrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \\ \downarrow & \downarrow & \downarrow \\ w_1 & w_2 & w_3 \end{vmatrix} $$
$$ WSW^T = WS[w_1, ..., w_k] = W[Sw_1, ..., Sw_k] $$
利用之前的结论:
\(Sw_1 = \lambda_1 w_1\)
$$ W[Sw_1, ..., Sw_k] = W[\lambda_1 w_1, ..., \lambda_k w_k] = [\lambda_1Ww_1, ..., \lmabda_kWw_k] = [\lambda_1e_1, ..., \lambda_ke_k] $$
其中 \(e_i\) 是指第 \(i\) 位为 1, 其余位都为 0 的列向量。
所以 \(Cov(z)\) 就是一个 Diagonal matrix.
PCA 关键词:
一个重要的结论需要记住: Covariance Matrix is a symmetric, positive-semidefinite matrix, so it has non-negative eigenvalues
一个重要的技术:
带限制条件优化
--- Lagrange multiplier ---> 无限制条件优化
--- partial dirivitive = 0 --->
求解。
一个重要的机器学习常识:
数据点的各个维度互相垂直
用数学语言来表述就是
数据点的协方差矩阵是一个 Diagonal matrix
也就是
数据点的各个维度之间没有 correlation
\(b_i^n = 1\ if\ x^n\ is\ most\ close\ to\ c_i,\ else\ 0\)
\(c_i = \sum_{x^n}b_i^nx^n/\sum_{x^n}b_i^n\)
一, build a tree
把原来的样本都看作叶子节点,merge 后的样本看成父亲节点,这样一直做下去直到产生root,这样就构成了一棵树。
二,pick a threshold
这一刀切在哪里就决定了你有多少个分类。比如下图所示,在第二层节点下切一刀就产生出四个簇。
如果只做 clustering 就像是我们做的非黑即白假设一样,未免过于武断,所以这里引入了Distribution representation .
英雄包含7个种类: [强化系,放出系,变化系,操作系,具现化系,特质系]
Cluster Representation: clustering 方法要求所有样本都属于并且必须只能属于一个簇,
\(Noxus\ of\ LOL \in Strength\)
但有时候这样做未免武断,所以考虑用概率分布的形式来表示一个样本,同时这种表示样本的方法也可以用在 Dimension reduction 中。
Distribution Representation: [0.7, 0.25, 0.05, 0.0, 0.0, 0.0, 0.0]
Distribution Representation 还一个作用,就是用作降维。这个东西与 Dimension reduction 有莫大的关系,对于一个有很高维度的向量样本而言,如果我们用一些特点来描述他,那就可以大幅度的减少样本的维度。
半监督学习的第一个假设是 非黑即白,进阶版是未必非黑即白,也差不多,基于这个假设我们有了算法 self-training(hard-label) 和 entropy-based regularization。
半监督学习的第二个知名假设是 近朱者赤,近墨者黑。
不精确的说法: Assumption: "similar" x has the same y.
精确的说法:
解释下上面这句话的意思:
如果 x 的分布是不平均的,有些地方很集中,某些地方很分散。如果两个 x 样本,x1 x2 在一个高密度区域内很近的话,那么他们的标签应该一样。
一言以蔽之,相近一个必须的前提是:这两个点必须经过一个稠密区间相连。 connected by high density region.
形象一点该如何理解 稠密区间 呢?也就是一个样本和另一个样本之间存在连续的渐进变换的很多样本,那么就说明两者之间存在稠密区间。
举例说明:
1 <====> 11 <-------> 15
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ___, 15
<====> 表示这里有很多渐变的无标数据点<-------> 表示这里几乎没有无标数据点我们如何判断无标数据 11 的标签?
‘1’ 和 ‘11’ 之间存在稠密区间,则两者的label应该是一样的。‘11’ 和 ‘15’ 之间不存在稠密区间。
这招在文档分类中,作用颇大。Classify astronomy vs. Travel articles.我们做文档分类是基于文档的vocabulary是否存在较大重叠,但是由于人类使用的词汇是如此的多,不同的人对同一个意思会使用不同的词汇去表达,所以文档之间的单词重叠的非常少,这时候就可以借助high density region的假设,只要两个文档之间(一个带标一个无标)存在连续的渐变的很多文档,就可以判断两个数据点具有相同的标签。
天文:文档1 = [asteroid, bright]
_ :文档2 = [bright,comet]
_ :文档3 = [comet,year]
_ :文档4 = [year,zodiac]
文档1 与 文档2 标签一致;
文档2 与 文档3 标签一致;
文档3 与 文档4 标签一致;
所以 文档1 与 文档4 标签一致;
一,构建 pseudo 数据集阶段
二,supervised learning 算法阶段
注意:clustering then label, 这个方法未必会有用啊,只有在你可以把同一个类 cluster 在一起的时候才有可能有用,如果是图像分类并且用 pixel 做clustering,就非常苦难,基于像素的距离做 clustering 本身就不太可能把同一类 cluster 在一起(同一个 class 可能在像素级别很不像,比如数字识别中像‘1’的‘4’和像‘9’的‘4’;不同 class 可能像素级别很像‘1’和‘4’,‘9’和‘4’),这第一步误差就这么大(各种分类的数据点混在一起),第二步不论怎么搞都不可能有太好的准确率。
所以,如果要用这个 cluster then label 算法的话,你的 cluster 要非常强,也就是第一步的准确率要足够高。一般使用 deep autoencoder 中间的 code 做 cluster,而不是像素。
cluster, then label 是一种比较直觉的做法,另一种做法是通过引入 graph structure 来做。用 graph structure 来表达 connected by a high density path 这件事。
把数据集映射成一个 graph, 每个数据都是图中的一个点。你要做的就是定义并计算两两之间的 similarity,这个similarity就是 graph 中两点之间的边(连线)。
构建graph之后:
但是 similarity 也就是 “边” 很多时候不是那么明显的可以定义出来。如果是网页分类,那么网页之间的连接可以看做是一种similarity(医疗的网页应该不会连接到游戏网页),这很直觉。论文分类,论文的索引也可以用在“边”。但更多时候,你需要自己去定义。
graph construction: 该如何构造一张图呢?
一, define the similarity \(s(x_i, x_j)\) between xi and xj.
(可以基于像素或者更高阶的方法是用 deep autoencoder 来做相似度),李宏毅教授推荐使用 RBF function 定义相似度:
\(s(x_i, x_j) = exp(-\gamma||x_i - x_j||^2)\)
如果想使用欧几里得距离衡量相似度,最好使用 RBF function 作为 similarity function. 为什么呢?因为RBF是一个衰减很快的函数,只要 xi xj 距离稍微远一点相似度就急剧下降。只有具备这种性质,你才能构造出较好的 cluster,他虽然不能保证同簇的相似度高,但至少可以保证不同簇的相似度一定较低(跨簇的距离更大一些的话)。
二, add edge
方法1: 可以使用 KNN 建立“边”,每个点都与相似度最近的 K 个点相连: \(|V_{x_i->[x_j]_{j=1}^K}| = argmax_{D'\subset{D}, |D'|=K}s(x_i, x_j)\)
方法2: 可以使用 e-Neighborhood 方法建立“边”,所有与 xi 相似度大于 e 的数据点都与 xi 建立连接。
三,edge weightedge
可以带有权重,他可以与相似度成正比。
graph-based approach 方法的核心精神是标签传染: graph 中的带标节点会依据“边”来传递自己的“标”,而且会一直“传染”下去。
graph-based approach 方法的核心缺点是数据量必须够大: 基于图的传染机制,如果数据不够多,没收集到位,那么本来相连的图由于数据量不够就可能断连,一旦断连就没法传染了。
我们基于以下认知和观察,来定义 loss functin 用以衡量 DNN 训练出的模型的好坏:
是否可以直接使用 cross-entropy,不加任何“佐料”?
pseudo labels 是在近朱者赤近墨者黑的假设下产生的,不管产生的算法是什么,他都可以看成是一个函数,这个函数是如此特殊他就像是ground truth function(监督学习下,我们不知道的那个f) 一样产生了我们以为真实的标签,所以,我们需要做的是去逼近这样的函数
我们能做的是,通过 loss function 来“诱导”优化器往这个特殊的函数去优化。
我们像产生 pseudo labels 的算法那样利用数据集 x 的距离模拟 density 来增加限制,但我们可以通过对标签来近似这种限制,我们可以看到同一个类的标签之间差距很小,类和类之间的标签差距很大,但是(构造 pseudo label 时用到的边的weight)同类数据点的边的weight很大,而不同类的数据点的边的weight很小。我们设置两点之间的标签差值乘以两点之间的边的权重作为限制, 希望他不要太大,以此来近似同类标签数据是高密度的这件事,虽然这是一种普杀式的限制 --- 他同样会限制类间标签的差异,但是考虑不同类两点的边权重很小,相乘之后影响较少,这种方法还是可以接受的。
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2\)
这个值越小,说明越平滑。
进一步化简这个公式,用矩阵的形式书写(引入 Graph Laplacian):
把带标和无标的(预测)标签拼在一起,形成一个长向量: \(\vec{y} = [...y_i, ..., y_j...]^T\)
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2 = \vec{y}^TL\vec{y}\)
L: (R+U) * (R+U) matrix
L 可以写成两个矩阵相减: \(L = D - W\)
现在把这个 smoothness 公式与loss-fn 统合起来,形成一个新的代价函数:
\(L(\Theta) = \sum_{x^r}C(y^r, \hat{y}^r) + \lambdaS\)
这个 \(\lambdaS\) 有点像是一个正则项,你不仅仅要调整data 让那些 label data 与真正的 label 越接近越好,同时还要做到你预测的标签(包括代标数据和无标数据)要足够平滑。
在 DNN 中 smoothness 的计算不一定是在 output layer 哪里才计算,而是在任何隐含层都可以(就像 L2 正则项可以加载任何层一样,keras API)可以从某一层输出接触一个 embedding layer 保证这个 embedding layer 是 smooth 的即可, 也可以完全套用 L2 的模式 --- 在每一个隐含层都加入这个正则项,要求每一层的输出都是 smooth 的。
J.Weston, F.Ratle, "Deep learning via semi-supervised embedding," ICML, 2008
上面的算法框架中出现过两次 similarity 公式:
其中产生 pseudo 数据集部分,‘similarity’ 是 “similarity of x” --- 计算两个点之间的距离(eg,RBF function)以此作为是否连线两点的依据,而距离作为边的权重。
而在训练模型的部分,‘similarity’ 是 ‘similarity of y’ 我们用 y 之间的距离不宜过大来近似 'similarity of x'
Semi-supervised 部分我们介绍了两个假设,
两个假设都是为了通过有标数据产生无标数据的标签。这一步仅仅是准备数据集,并没有训练任何模型,他就像是监督学习中,产生数据集的那个我们不知道的函数。
而我们在训练模型时,必须要考虑到这个特殊的“函数”,也就是我们训练模型的时候需要让给与训练过程一些限制,让优化器朝着这两个假设的方向去优化函数:
\(L = \sum_{x^r}C(y^r, \hat{y}^r) + \lambda\sum_{x^u}E(y^u)\)
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2 = \vec{y}^TL\vec{y}\)
\(L(\Theta) = \sum_{x^r}C(y^r, \hat{y}^r) + \lambdaS\)
EM 系算法产生标签(边产生边更新) -----
|--- 生成模型: 初始化prior proba, 预测无标,更新 prior proba
|--- 归纳学习,产生model,标签为实数
|--- low density separation: 用带标产生 f,预测无标,更新 f
|--- 归纳学习,产生model,标签为整数
非 EM 系算法产生标签(先构造后产生)----
|--- high density region using **cluster and label**: 先构造簇,整簇分为标签最多者
|--- high density region using **graph-based algo**: 先构造图,相连的分为一类(同标签)
去芜存菁,化繁为简
他的核心要旨是:我们所见的世界虽然很复杂,但在复杂背后隐含着比较简单的要素(factor)在操控复杂的世界,如果能窥见一二就可以搞定。
这个 latent factors 就是 better representions.
low-density separation 这个假设的意思是说非黑即白, 亦即两个class的数据点之间有一条明显的鸿沟,亦即两个class之间的data量是很少的。
Low-density Separation Assumption 最具代表性的算法就是 self-training
关于这个 self-training 算法的几个注意点
self-training 是从带标数据集得到一个函数 f, 然后用这个函数去求一个值 y = f(x), x是无标数据, 然后再把这个 (x,y) 加入代标数据集中,这个 y 本身就是通过 f(x) 得到的,他怎么可能改变 f 呢。所以 f 根本就不会变。所以 regression 不能使用这个算法来做。为什么呢,因为 regression 得到的是一个实数,而不是离散的分类。
两者看起来相似:
EM-generative model算法(KNN算法,transductive 学习通用框架):
self-training 算法:
两者的不同在于,
举例:
毫无疑问,如果是 self-training 使用 DNN 来训练的化, soft-label 完全没用啊,这点和 regression 问题无法使用 self-training 的道理是一样的。你的标签本身就是你的NN得到的一模一样的值,你重新将其加入数据集,他根本不会更新 NN 的参数。
核心本质:
我们使用 Hard-label 时我们在使用什么?我们在使用假设 Low density separation* --- 非黑即白,中间地带无数据**.
如果觉得非黑即白太武断了,可以使用 Entropy-based Regularization 方法
Entropy-based regularization 的意思是 未必非黑即白但也差不多啦
以刚才的例子来说明:
这样规定x的标签太武断了,我们希望标签还是可以保留一些小数,亦即NN的输出还是一个正常的概率分布,但不能是下面这样:
我们希望可以通过加入某种限制,来实现增加区别度,使概率分布更集中的目标。这个限制叫做 entropy of distribution. 他可以告诉我们这个分布集中与否。
entropy 值越小说明越集中(激光小且集中),最小为0。
\(E(y^u) = - \sum_{m=1}^Uy_m^uln(y_m^u)\)
根据这个假设,我们可以重新设计 loss-function
labeled data:
\(L = \sum_{x^r}C(y^r, \hat{y}^r)\)
unlabeled data(这里是说之前讨论的通用算法框架步骤2中的预测无标数据的标签):
\(\lambda\sum_{x^u}E(y^u)\)
我们希望NN对于无标数据的预测结果(一个概率分布)应该越集中越好。
综合起来看,就是如下公式:
\(L = \sum_{x^r}C(y^r, \hat{y}^r) + \lambda\sum_{x^u}E(y^u)\)
参考论文:transductive inference for text classification using SVM
核心精神就是,
遗留问题:
穷举 怎么做?论文中给出了一个近似的方法,每次该一个无标数据点的标签,看看 SVM 是否会变好,如果可以的话就改。
unlabeled data 虽然只有数据没有标签,但是 unlabeled data 的分布可以告诉我们一些东西。比如可以告诉我们什么样的边界是更好的。
semi-supervised learning 使用 unlabeled data 的情况经常伴随一些假设。semi-supervised learning 有没有效果就取决于你的假设好不好。
semi-supervised learning 未必有用,这取决于你的假设是否足够好。
回忆之前讲过的 Supervised Generative Model, 我们假设每一个 class 的数据点的分布都是一个 gaussian distribution(类的分布共享 \(\Sigma\)):
\(P(x|y_1) \sim G(\mu_1, \Sigma)\) \(P(x|y_2) \sim G(\mu_2, \Sigma)\)
得到 prior proba 然后就可以根据公式得到 posterior proba:
\(P(y_1|x_{new}) = \frac{P(x_{new}|y_1)P(y_1)}{P(x_{new}|y_1)P(y_1) + P(x_{new}|y_2)P(y_2)}\)
对于 semi-supervised Generative Model, 由于我们多了很多 unlabeled data, 这回改变我们对原来(仅仅通过 supervised Generative Model)获取的分布的认知。就像 KNN 每个新来的数据都会改变原来的中心点的位置。
3.1 update prior proba:
\(P(C_1) = \frac{N_1 + \Sigma_{x^{\mu}}P(C_1|x^{\mu})}{N}\)
\(N\): total number of examples
\(N_1\): number of examples belonging to C1
\(x^u\): unlabeled data
这里注意,supervised learning 中计算 \(P(C_1)\)的公式是:
\(P(C_1) = \frac{N_1}{N}\)
现在需要考虑 unlabeled data 对于分类的贡献。
我们可以把 Posterior praba \(P(C_1|x^u)\) 近似的理解成 (xu贡献的)C1的出现次数,毕竟概率也可以看做是(0.7个,0.5个。。。),我们只要加总所有样本对于 C1 的后验概率,就可以将其近似的理解成 unlabeled data 贡献的分类数据。
\(\Sigma_{x^{\mu}}P(C_1|x^{\mu})\)
3.2 update \(\mu_1\)
这里注意,supervised learning 中计算 \(\mu_1\)的公式是:
\(\mu_1 = \frac{1}{N_1}\Sigma_{x^r\in{C_1}}x^r\)
现在需要考虑 unlabeled data 对于分类的贡献。
对于 unlabeled data 我们同样需要借用 posterior probability 来计算 unlabeled data 的 weighted sum 的平均。
\(\frac{1}{\sum_{x^u}P(C_1|x^u)}\sum_{x^u}P(C_1|x^u)x^u\)
理论上这个方法会收敛,但是初始值对结果的影响非常大。同时这个方法也可以理解为 EM 算法。
两者最大的区别是前者只能通过 EM 算法进行 iteratively 解;后者有公式解。
我们是通过【 Maximum likelihood 来找到分类为 Ci 的样本点的最有可能的高斯分布】来求得 Prior proba \(P(x|C_i)\), 我们优化的公式很好解:
\(logL(\Theta)=\sum_{x^r}logP_{\Theta}(x^r, \hat{y}^r)\)
但是对于 unlabeled data 我们怎么估测 \(logL(\Theta)\) 呢?
\(logL(\Theta) = \sigma_{x^r}logP_{\Theta}(x^r) + ?\)
这里的思想与【把\(P_{\Theta}(C_i|x^u)\)看做 \(x^u\) ‘贡献’的‘次数’】思想类似,只不过利用的是 Prior probability因为我们并不知道 \(x^u\)的分类是多少,所以他可能属于任何分类。
所以这里 \(P_{\Theta(x^u)}\) 应该等于 \(x^u\) 与每个分类的联合概率的和:
\(P_{\Theta}(x^u)=P_{\Theta}(x^u|C_1)P(C_1) + P_{\Theta}(x^u|C_2)P(C_2)\)
Unlabeled data: \(U\), from \(u=R\) to \(u=U+R\)
Labeled data: \(R\), from \(r=1\) to \(r=R\)
Supervised learning:
\( \{(x^r, \hat{y}^r)\}^R_{r=1}\)
Semi-supervised learning:
\( \{(x^r, \hat{y}^r)\}^R_{r=1}\) ,\(\{x^u\}^{R+U}_{u=R}\)
直接使用 testing data 不是作弊么,李宏毅老师说,使用 label of testing data 才是作弊。
transductive learning 的典型算法是 KNN,对于 unlabeled data 我们计算其距离各个中心点的距离。然后重新计算该簇的中心点。可见我们确实使用了 unlabeled data 来学习模型。
以 kaggle 竞赛为例,有些 kaggle 竞赛是直接可以下载 testing dataset 的,只是 testing data 没有 label 而已。
基于概率(Bayes)的分类问题解法 --- 生成模型:
蓝盒子,绿盒子,其中各置5个球,球也有蓝色和绿色。已知:
- 蓝盒:4蓝 + 1绿
- 绿盒:2蓝 + 3绿
问:现抽出一蓝球,问他来自两个盒子概率各是多少:P(blueBox | blueBubble)=?
这个问题使用 bayes 条件概率公式非常好求,只需要知道四个值:
类比:
蓝盒子 --- class 1;
绿盒子 --- class 2;
class 1,class 2,各有很多样本。已知:
- class 1:海龟,金枪鱼,
- class 2:老鹰,白鸽,
问:现有一鸭嘴兽,问他来自两个分类的概率各是多少?
我们同样需要知道 4 个值:
从训练集中,直接“数”出标签为 C1 的样本数量,和标签为 C2 的样本数量各是多少,记做 N1 , N2.
\(P(C1) = N1/(N1 + N2)\)
\(P(C2) = N2/(N1 + N2)\)
分类问题中的条件概率不同于“盒子抽球”的最大地方在于:你要计算的 \(P(x|C1)\) 中的 x 是现有样本集中没有的。
把当前 c1 样本 和 c2 样本都想象成概率分布,而当前数据集仅仅是根据概率分布做的抽样(全体中的部分)
如果我们能得到这个概率分布,我们就可以知道鸭嘴兽属于陆生和海生的概率各是多少。
假设:c1 和 c2 的概率分布是高斯分布,且他们都是高斯分布集合( gaussian distribution hypothesis )中的一个 gaussian distribution, 我们该如何找到这个高斯分布呢 --- 只需确定 \(\Sigma\) 和 \(\mu \), 就可以唯一确定一个高斯分布。
那如何通过样本来倒推出 \(\Sigma\) 和 \(\mu \) 呢?
找到一个 \(\mu, \Sigma\) ,由他确定的高斯分布在所有的高斯分布中,产生数据集的概率是最高的。
\(f_{\mu,\Sigma}(x) = \frac{1}{(2\pi)^{D/2}}\frac{1}{|\Sigma|^{1/2}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^-1(x-\mu))\)
\(L(\mu,\Sigma) =f_{\mu,\Sigma}(x^1)f_{\mu,\Sigma}(x^2)f_{\mu,\Sigma}(x^3)......f_{\mu,\Sigma}(x^N)\)
\(\mu^\star, \Sigma^\star = \arg\max_{\mu,\Sigma}L(\mu,\Sigma)\)
这个 \(argmax\) 有一个很直观的公式解,可以直接记住:
\(\mu^\star = \frac{1}{N}\sum_{n=1}^{N}x^n\)
\(\Sigma^\star = \frac{1}{N}\sum_{n=1}^{N}(x^n-\mu^\star)(x^n-\mu^\star)^T\)
如果不适用极大似然估计,也可以使用 Naive Bayes 方法来推算 Prior probability.
\(P(y|x) = \frac{P(x|y)P(y)}{P(x)=\sum^K_{i=1}{P(x|y_i)P(y_i)}}\)
通过 count-based method 和 Naive Bayes(
\(P([1,3,9,0] | y_1)=P(1|y_1)P(3|y_1)P(9|y_1)P(0|y_1)\) ) 先计算出:
\(P(x|y_1)P(y_1)\)
\(P(x|y_2)P(y_2)\)
\(P(x|y_3)P(y_3)\)
...
一旦得到了这个 \(\mu,\Sigma\) 我们就可以得到分类1 产生 x 的概率(即便他不存在于数据集中)的概率:
\( P(x | C_1) = P(x | Gaussian_1(\mu_1, \Sigma_1))\)
分类2 产生 x 的概率, 也很容易得到:
\( P(x | C_2) = P(x | Gaussian_2(\mu_2, \Sigma_2))\)
根据 bayes 公式:
\(P(C_1 | x) = \frac{P(x | C_1) * P(C_1)}{P( x | C_1) * P(C_1) + P(x | C_2) * P(C_2)}\)
\(width_{output} = \frac{width_{img} - width_{kernel} + width_{padding}}{width_{strides}} + 1\)
在 keras 中 fit 给 CNN 的数据集的形状必须是:
theano: (-1, channel, height, width)
tensorflow: (-1, height, width, channel)
如果不是必须reshape到这个形状,第一层卷积层的声明一般为:
model.add( Conv2D(kernelNum, (kernelHeight, kernelWidth), input_shape=(dataPointChannel, dataPointHeight, dataPointWidth), data_format='channels_first'))
切记,切记
一列数字,如果每个数字都减去平均值,则新形成的数列均值为0.
一列数字,如果每个数字都除以标准差,则新形成的数列标准差为1.
\(x_i \leftarrow x_i - \mu\)
\(x_i \leftarrow x_i / \sigma\)
\(x_i \leftarrow x_i * 0.1\)
经过这三步归一化的动作,既能保持原来分布的特点,又能做到归一化为均值为0,标准差为 0.1 的分布。
模组化的意思是不直接解原始问题,而是找到一些中间量作为推论'桥'再过渡到原始问题。
每多一层隐含层,就多了一次 萃取 和 推理
1 hidden layer: 原始数据 -> 解析特征 -> 通过特征推理结果
2 hidden layer: 原始数据 -> 解析特征的特征 -> 通过特征的特征推理特征 -> 通过特征推理结果
...
每多一层隐含层,就多了一次抽取特征 和 通过特征进行推理。
实例说明:
四分类问题,把样本分成四类:
no hidden layer: dataset -> [1|2|3|4]
很显然,由于分类1的样本太少,分类器处理分类1的错误率就会很高。整体错误率也会较高。
1 hidden layer: dataset -> [长发|短发] + [男|女] -> [1|2|3|4]
这样一来,就可以避免某些样本过少会削弱分类器的问题,虽然长发男很少,但是长发vs短发两者几乎相等,男vs.女也几乎相等,也就是 [长|短] 分类器和 [男|女] 分类器都很强。
把这两个子分类器的结果作为新的样本(new dataset)学出[长发男]的分类器也就很强。
模组化(modularize) 在这里就是指可以直接利用子分类器的结果作为新的输入,这就有点像是\(f(g(h(x)))\)一样。
deep learning 可以只给出 input(样本) 和 output(标签) 而我们并不参与中间具体函数的设计,这些具体的函数是自动学出的,这就是 end to end learning。
现实问题中经常会遇到:
哈士奇和狼的图片作为输入,标签一个是狗,一个是狼
正面的火车和侧面的火车作为输入,标签却都是火车
如果你的NN只有一层,你大概只能做简单的转换,没办法形成层次结果和复用。
记忆: 小抠样
记忆:small, regions, subsampling
这个是说 filter 一般采取小于整张图片的形状
这个是说 filter 会逐行逐列移动扫描整张图片
这个是说 pooling 是切割图片为多块,每块只取一格(1 pixel)
这里的意思是说,对于 featuremap 如果池化层 size = 2*2 , maxpooling 会只去最大的一个值(averagePooling 会取平均,但也只是一个值)而忽略其他值。这件事情的物理意义是:featuremap 是由 filter 扫描整张图片得到的,某个pattern(pattern较大,stride较小时)可能被多次扫描到并体现在 featuremap 中类似于 \([0,1,2,5,2,1,0]\),直接丢弃这种长尾效应的尾对判定该某个pattern的位置以及匹配程度是没有任何影响的,他完全可以被最大的那个 5 hold住。
围棋(连续型pattern) vs. 图像识别(离散型pattern)
图像识别就是这种最大值可以完全hold位置以及匹配程度信息的任务。可是对于其他任务比如围棋,他的核心任务虽然也是识别某个模式,但长尾效应的尾部是有作用的。
在图像识别中被识别的模式是独立的或者叫离散的 --- 一个圆的是形状是眼睛,3/4个圆就不是眼睛了。在围棋中 \([0,1,2,5,2,1,0]\) 那些\(0,1,2\)对判断当前棋子所处的状态是有影响的,甚至他可能更重视长尾效应中的尾。
所以,对于是否使用 maxpooling 层要根据你的具体任务来做具体对待:
当任务识别的pattern‘’比较离散”---目标仅仅是寻找和定位pattern,别无其他 适合加上 maxpooling,让模型更专注,也让模型参数更少。
当任务识别的pattern“比较连续”---长尾效应之尾会影响任务目标 最好不加 maxpooling,这样模型可以保存更多现场信息,让结果更精确。
像围棋这种任务,显然就不能使用纯粹的CNN(包含 maxpooling),所以 alpha-go 中没有使用 maxpooling.
google 的 deepdream 的核心思想就是借用最大化某个filter or neuron.不同的是 deepdream 不是单纯“最大化某个filter or neuron的输出”,而是针对某层,让该层神经元原本输出大的更大,原本输出小的更小。,亦即,
CNN of deepdream exaggerates what it sees
assume output of k-th hidden layer is
\(output_k = [3.9, -1.5, 2.3, ...]\)
正的扩大,负的缩小
\([3.9\Uparrow, -1.5\Downarrow, 2.3\Uparrow, ...]\)
成为
\(output_k' = [10, -5, 8, ...]\)
以其为目标,找到 \(x^\star\)
\(x^\star = argmin_x(output_k - output_k')\)
之前都是只考虑了输出这件事,不论是 filter or neuron 还是某一层 hidden layer 我们关注的都是输出。现在如果我们把filter 和 filter 之间的 correlation 纳入考虑范畴。就可以实现风格迁移,这就是 deepstyle 的核心思想。
一个训练好的 CNN,输入某张图片,获取某一层 hidden layer 的输出(取内容);
一个训练好的 CNN,输入某张图片,获取某一层 hidden layer 的correlation(取风格);
目标是:找到一个 \(x\),他经过CNN得到的相同层 hidden layer 的内容像步骤1中的;风格像步骤2中的。
也就是什么样的图片可以让 filter 被激活(度高)
定义: 核的激活度
Degree of the activation of k-th filter, 核激活度表示这个 filter 被激活的程度, 他等于该filter输出的 featuremap 矩阵的所有元素的和(一个 filter 只会生成dim=1的featuremap)。
\(k-th\ filter\ is\ a\ matrix : A^k\)
assum \(A^k\) is a 11 * 11 matrix
\(element\ of\ A^k: a_{ij}^k\)
\(degree\ of\ activation\ of\ k-th\ filter: a^k = \sum_{i=1}^{11}\sum_{j=1}^{11}a_{ij}^k\)
我们的目标是:找一张img,他可以让这个filter被激活度最大
\(img^\star = argmax_{img}a^k\) , 亦即
\(x^\star = argmax_{x}a^k\)
我们使用 Gradient Ascent 去更新 \(x\) 使得某个filter的被激活度 \(a^k\) 最大。
也就是什么样的屠屏可以让 neuron 被激活。
定义:神经元的激活度
某个神经元的激活度,很简单,就是这个神经元的输出。
第 j 个神经元的输出记做 \(a^j\)
我们的目标是: 找一张img, 他可以让这个neuron的输出最大
\(img^\star = argmax_{img}a^j\) , 亦即
\(x^\star = argmax_{x}a^j\)
同上,也使用 Grandient Ascent.
其他同上
\(img^\star = argmax_{img}a^j\) , 亦即
\(x^\star = argmax_{x}y^j\)
由于是输出层神经元,如果我们在做手写数字识别mnist的话,那么输出层神经元应该有10个(对应数字 0~9),我们是否可以据此产生图片了?类似生成模型。
但结果并不如人意料,机器学出的东西与人类理解的东西有非常大的不同。我们确实可以通过这种GradientAscent的方法找到10张图片,他们也确实可以被模型正确分类到10个类别中,但这10张图片却无法被人类识别。
但我们依然可以对这些数字做一些处理(对 \(x^\start\) 做一些限制 --- 加一些 constraints),让他看起来像是数字:
\(x^\star = argmax_{x}y^j\)
change to:
\(x^\star = argmax_{x}(y^i - \sum_{i,j}|x_{ij}|)\)
类比 L1-regularization of GD on w:
\(||\Theta||_1 = |w_1| + |w_2| + ...... + |w_N|\)
\(L^{'}(\Theta) = L(\Theta) + \lambda ||\Theta||_1\)
\(w^\star = argmin_wL'(\Theta))\)
\(w^\star = argmin_{w}(L + \sum_{i=1}^{dim}|w_{i}|)\)
加上这个限制的意思是,人类可以识别的数字图片(灰度图)应该是大部分为0,小部分为正,并且为正的部分应该相连。
我们给原始的 \(argmax\) 公式加入 \(L1\) 正则项,让这个 x 可以尽量的稀疏(这是 L1 的特点),也就是大部分 x 的元素是 0,少量为1.
model.add( Convolution2D(25, 3, 3, input_shape=(1,28,28)) )
model.add( MaxPooling2D((2,2)) )
我们平时表示RGB彩图时,习惯将 通道 维度放在最后: (高,宽,通),opencv/pil/numpy/scikit 处理图片都是采用这种方式,但在 tensorflow/keras 中使用的是 (通,高,宽) 的表达方式。所以:
Convolution2D(25,3,3, input_shape=(1,28,28))
25 个 size=3*3 的 filter(channel_dim=1), 图片 size=28*28对比 Dense Layer:
Dense(input_shape=(1,28,28), units=800, activation='relu')
可以看出,
卷积层只是说明了本层权重的一些信息(filter就是权重) ,而神经元数目则交给系统自动推算; 全连接层则直接指明了本层神经元的数目。
Convolution2D(25,3,3, input_shape=(1,28,28))
会输出一个形状为 (25, (28-3+1), (28-3+1)) 的 feature map。
卷积层输出形状推算公式为:
\(Convol:\) \(feature \ map \ size =(filterNumber_i, imgHeight_{i-1} - filterHeight_i + 1, imgWidth_{i-1} - filterWidth_i + 1)\)
MaxPooling2D((2,2))
会输出一个形状为 (25, 13, 13) 的 feature map.
池化层输出形状推算公式为:
\(Pooling:\) \(feature\ map\ size= (filterNumber_{i-1}, imgHeight_{i-1}//poolHeight_i, imgWidth_{i-1} // poolWidth_i)\)
// 的意思是 celing division, 5//2=2
卷积层参数量推算公式:
\(Convol_{paraNum}=filterNumber_{i-1} * filterNumber_i * filterHeight_i * filterWidth_i\)
model.add(Convolution2D(25,3,3,input_shape=(1,28,28)))
model.add(MaxPooling2D((2,2)))
model.add(Convolution2D(50,3,3))
第一个卷积层的总参数量为: 1 25 3 * 3
第二个卷积层的总参数量为: 25 50 3 * 3
简单记忆训练 DNN 的技巧:
对于坏习惯, 早弃则自活
前三个针对训练误差小测试误差大的情况;
后两个针对训练误差就很大的情况;
tips for good training but bad testing
tips for bad training
每一次更新参数之前(我们一般一个 mini-batch 更新一次参数,也就是每个 mini-batch 都对神经元做一次随机丢弃),对每一个神经元(包括input layer,这点要注意)做丢弃:
1 mini-batch -> 1 dorpout -> 1 thin-network
每一个神经元都有 p% 几率被丢弃,所有与被丢弃的神经元相连的权重 w 也都会被丢弃,这样整个网络的结构就变了,深度不变宽度变窄。
dropout 毫无疑问会让训练结果变差,因为整体模型复杂度降低了。
需要注意两点:
假设 dropout rate 设为 50%, 在训练的时候我们得到的某个神经元的输出 \(z\) ,是丢弃了输入层一半的神经元及权重得到的:
\(z=f([x1,x2,x3,x4])\) --> \(z=f([x1,x4])\)
在测试的时候这个由于不做任何丢弃:
\(z=f([x1,x2,x3,x4])\))
该神经元的输出大约会是原来的两倍:
\(f(\vec{x}) = w * x + b\)
\(f([x1,x2,x3,x4]) \approx 2 * f([x1,x4])\)
\(w_{new} = 0.5 * w_{old}\) ,这样:
\(f([x1,x2,x3,x4]) \approx f([x1,x4])\)
为了防止 overfitting,防止参数量太多而引起的数据集和模型的优化方向 mis-match 的情况。我们经常人为设定:
\(\Sigma_1 = \Sigma_2\)
需要说明的是:如果做了公用 \(Sigma\) 这种假设的话,最后得到的就是一个直线边界,不做这一假设的话得到的是一个曲线边界。
likelihood 公式就变成:
\(N1 = num(samples of C1)\)
\(N2 = num(samples of C2)\)
\(L(\mu_1, \mu_2, \Sigma) = f_{\mu_1,\Sigma}(x^1)f_{\mu_1,\Sigma}(x^2)f_{\mu_1,\Sigma}(x^3)......f_{\mu_1,\Sigma}(x^{N1}) * f_{\mu_2,\Sigma}(x^1)f_{\mu_2,\Sigma}(x^2)f_{\mu_2,\Sigma}(x^3)......f_{\mu_2,\Sigma}(x^{N2})\)
对上面的式子可以通过微分,或者直接记住下面的公式解(其中 \(\mu_1\) \(\mu_2\) 跟原来一样,都是 样本的均值,\(\Sigma\) 是某类别的样本比例作为权重的 \(\Sigma\) 之和):
\(\mu_1 = avg(sample of C1)\)
\(\mu_1 = avg(sample of C1)\)
\(\Sigma = \frac{N_1}{N_1+N_2}\Sigma^1 + \frac{N_2}{N_1+N_2}\Sigma^2\)
线性回归的标签值 \(y\) 都是实数(亦即可能任意大or任意小),同时线性回归的代价函数是平方误差 \((y-\hat{y})^2\) --- square error. 而代价函数又会通过 GD 直接影响 w 和 b --- 分界线。
在分类问题中,无论错误程度多高,错点的代价永远算作‘1’;而在线性回归中,做错点的代价与他的错误程度平方正比(远大于1)。两者的代价函数不一样,两者得到的函数(分界线)就肯定不一样。
logistic regression 有非常严格的使用限制,线性可分。
logistic regression 虽然可以理解为对分布的近似,但其本质仍然是一个直线分界线,因为他也是要求出 w 和 b,使用的函数集仍然是 wx+b = y , 也就是要求数据集必须是线性可分的。
如果遇到线性不可分的数据集,可以考虑采用特征转换。但如何做特征转换呢?
一个很好的方法是cascading logistic regression models --- 把很多个 logistic regression 接起来,就可以做到这件事情。这个东西有点像是在解释 NN,以及为什么他可以做到自动化 feature transform, 然后做分类。
李老师由此引入 "Neuron" 概念:
每一个逻辑斯模型的输入可以是其他逻辑斯模型的输出。
他们可以串在一起形成一个网络,这个网络就叫做神经网络。
主要就是利用 softmax:
第一步:计算 score
z1 = w1 * x + b1
z2 = w2 * x + b2
z3 = w3 * x + b3
第二步:对 score 做 exponential normalization
\(y_{1} = \frac{e^{z_{1}}}{\sum^3_{j=1}e^{z_{j}}}\)
\(y_{2} = \frac{e^{z_{2}}}{\sum^3_{j=1}e^{z_{j}}}\)
\(y_{3} = \frac{e^{z_{3}}}{\sum^3_{j=1}e^{z_{j}}}\)
第三步:以 yi 表示 P(Ci | x) --- x 属于第i个分类的预测概率
\(y_i = P(C_i | x)\)
为什么叫做 softmax 呢? exponential 函数会让大小值之间的差距变的更大,换言之他会强化最大值。
总体来看,如果样本足够多,判别模型的正确率高于生成模型的正确率。
生成模型和判别模型最大的区别在于,生成模型预先假设了很多东西,比如预先假设数据来自高斯,伯努利,符合朴素贝叶斯等等,相当于预先假设了 Hypothesis 函数集,只有在此基础上才有可能求出这个概率分布的参数。
生成模型,进行了大量脑补。脑补听起来并不是一件好事,但是当你的数据量太小的时候,则必须要求你的模型具备一定的脑补能力。
判别模型非常依赖样本,他就是很传统,死板,而生成模型比较有想象力,可以“想象”出不存在于当前样本集中的样本,所以他不那么依赖样本。
关于 想象出不能存在于当前样本集的样本 ,见本课程 40:00 老师举例。
生成模型在如下情形比判别模型好:
释疑第三条优点:老师举例,在语音辨识问题中,语音辨识部分虽然是 DNN --- 一个判别模型,但其整体确实一个生成模型,DNN 只是其中一块而已。为什么会这样呢?因为你还是要去算一个先验概率 --- 某一句话被说出来的概率,而获得这个概率并不需要样本一定是声音,只要去网络上爬很多文字对话,就可以估算出这个概率。只有 类别相关的概率 才需要声音和文字pair,才需要判别模型 --- DNN 出马。
from vis.modifiers import Jitter
Here the code is obsoleted, should change to:
from vis.input_modifiers import Jitter
from vis.utils.vggnet import VGG16
Here the vis.utils.vggnet is deleted, should change with keras original package:
from keras.applications.vgg16 import VGG16
@mingrutar - Correction: config = tf.ConfigProto() config.gpu_options.allow_growth = True session = tf.Session(config=config)
当运行 keras 进行模型训练时,如果遇到以下错误:
failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
可以添加这样的语句,如此之后可以正常运行了。
Mixin’ traits ‘statically’
静态的 mixin a trait 是说:这个 trait 的成员(method, field) 可以有一个 default implementation. 这样你 mixin 这个 trait 的时候,可以只提供那些没有 Implementation 的抽象函数。 当然也可以都自己实现一遍。
val singingPerson = new Person with Singerperson.sing
val singingPerson = new Person with Singer 倒是很像 组合
A Scala function that’s created with val is very different than a method created with def.
这里才是我最想看到的
By all accounts, creating a Scala def method creates a standard method in a Java class
当你用 def 创建了一个函数,你其实就是创建了一个 java class 中的方法(method)
if i != 0
这个部分:
if i != 0
会被 compiler 自动解析为 PF 的 isDefinedAt() 函数,这个函数返回 boolean,用来确定 PF 的定义域。
a val function, all you’re really doing with code like this is assigning a variable name to an anonymous function
val function like
val f = (a:Int, b:Int) => a+b
就是定义了一个 literal function, 然后给他一个名字 : f
A block of code with one or more case expressions is a legal way to define an anonymous function
用 case 构建 literal function
Ordered特质更像是rich版的Comparable接口
Ordered 青出于 Comparable 而胜于 Comparable