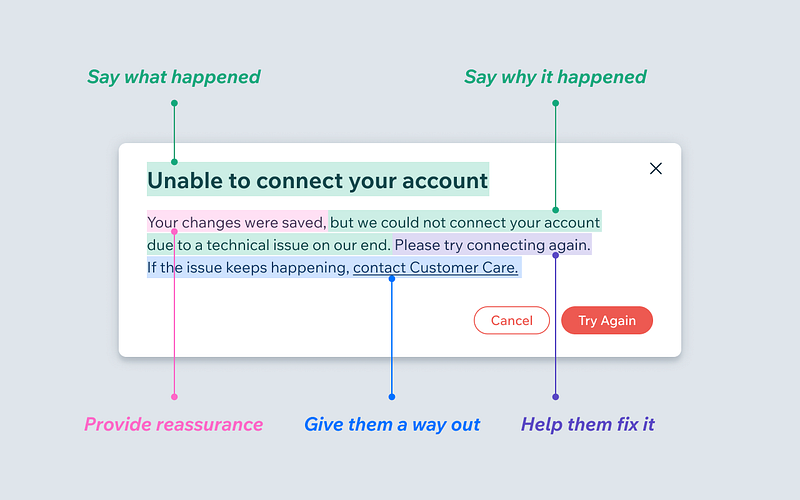
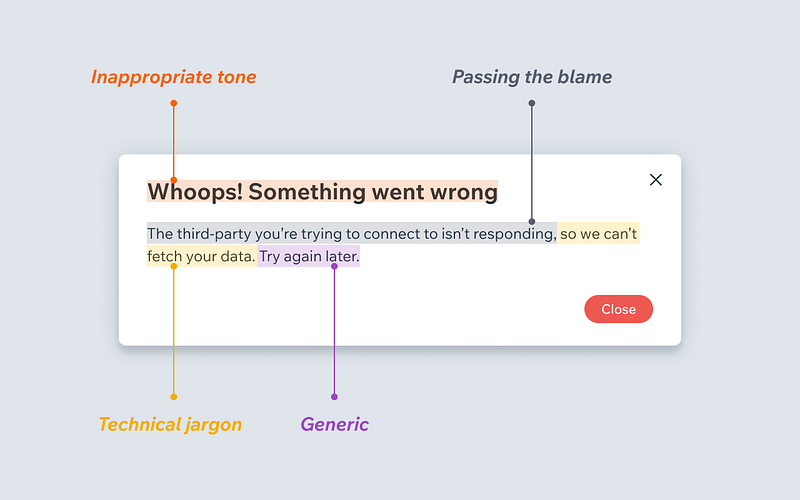
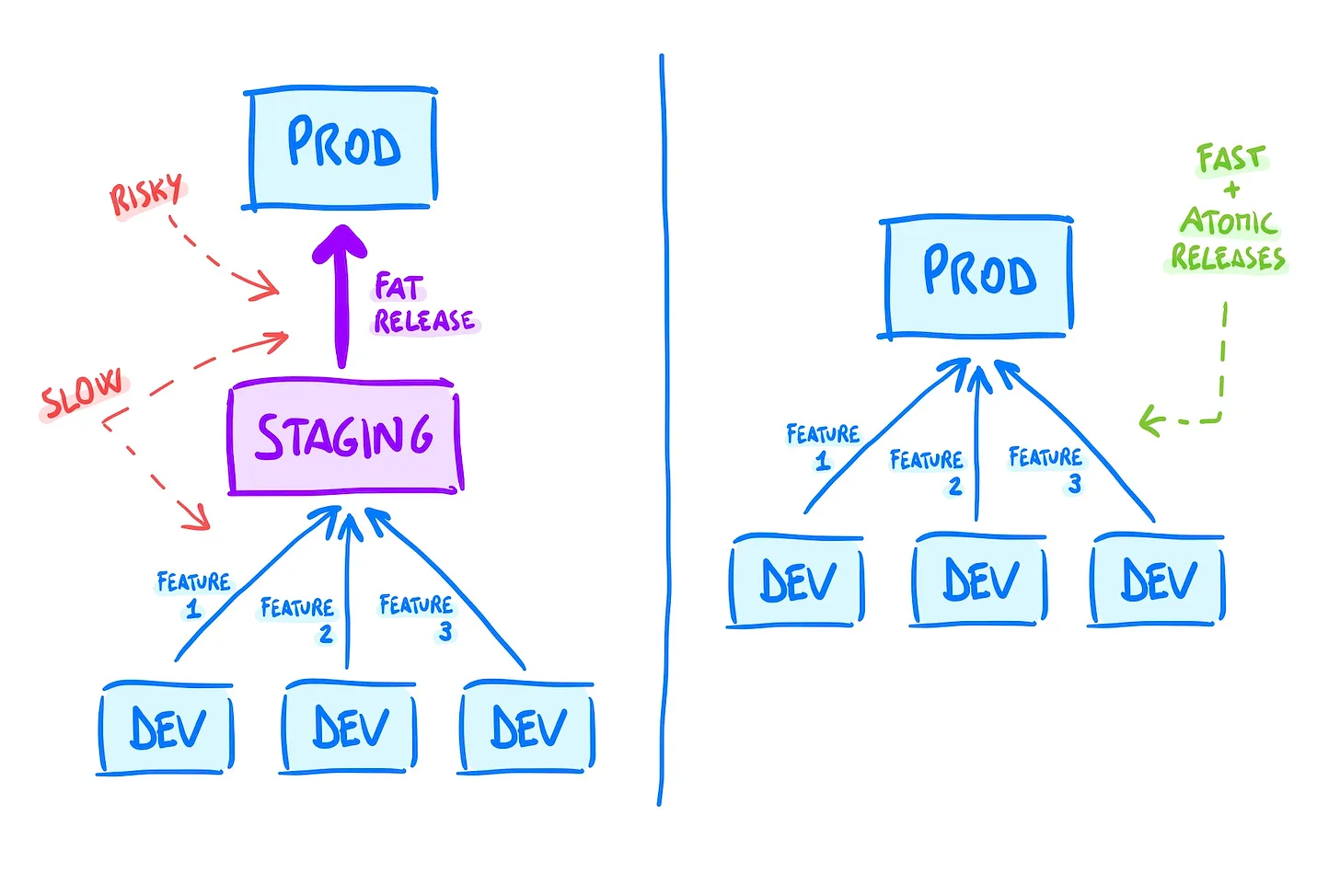
At the end of the day, Copilot is supposed to be a tool to help developers write code faster, while ChatGPT is a general purpose chatbot, yet it still can streamline the development process, but GitHub Copilot wins hands down when the task is coding focused!
GitHub Copilot is better at generating code than ChatGPT