PHP/MySQL is losing adoption
states the AMP stack is losing adoption. Any numbers to find?
PHP/MySQL is losing adoption
states the AMP stack is losing adoption. Any numbers to find?
https://en.wikipedia.org/wiki/Soundex
There is a close relationship between the Soundex indexing scheme and the scheme behind the Major System!!!
Online DDL是对于历史DDL的优化,默认对于支持的DDL操作生效。如果使用Copy算法,则会阻塞DML。
他的主机磁盘用的是SSD,但是innodb_io_capacity的值设置的是300。于是,InnoDB认为这个系统的能力就这么差,所以刷脏页刷得特别慢,甚至比脏页生成的速度还慢,这样就造成了脏页累积,影响了查询和更新性能
错误的io能力设置,导致mysql错估磁盘io,影响脏页的刷新效率
比如索引是字段的前缀,如email(6)
无法从根上解决。 缓解的方法(仍然可能选错索引): - analyze table更新统计信息 - force index(索引可能变更,不灵活) - 删除错误的索引(很多时候,其他业务需要用到该索引) - 通过修改sql引导mysql优化器,让其觉得错的索引成本高(不通用)
在in中子查询不能使用limit,但是可以在from后面使用limit,因此可以在in的子查询中套一个子查询,如下:
select *from cidy where id in(select id from(select id from cidy limit 0,10) as cd);
主要是给同一页的随机写攒批 1. 只影响不存在唯一索引的插入 2. 如果插入后就需要读取,那么最好关闭change buffer
redo log 主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗。
可是实际上是对随机写攒批呀。如果没有change buffer则会在页缺失的时候加载,当然change buffer延迟了加载的时间,只在需要的时候加载,但是如何保证数据存在呢?比如更新的时候需要返回影响行数的,那是否只能用于没有唯一索引的表插入?
索引没有undolog,因此索引需要回表,通过回表得到数据的undolog,然后判定索引条目是否有效。但是如果索引本身不带事务id,那么如何知道其属于哪一个版本呢?如果每个索引条目都需要回表才能确定是否有效,那么全索引扫描不就是全表扫描了吗?如果主键变更索引又要如何处理?
https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html?open_in_browser=true
似乎是,二级索引的数据也是一样不删除,而是标记为删除,但是仍然存留在二级索引的b+树上,每个索引页会记录最近更新的事务id。而如何确定数据是否有效呢,回表,回表,回表,重要的事情说三遍,只有回表访问版本链才能知道readview是否能够看到这条记录的这个版本
If a secondary index record is marked for deletion or the secondary index page is updated by a newer transaction, the covering index technique is not used. Instead of returning values from the index structure, InnoDB looks up the record in the clustered index.
使得innodb_autoinc_lock_mode设置为1或者2,默认0,使得在插入时申请到自增值后立即释放auto-inc锁。在不同值下的行为: - 若是1,则insert ... select from这种仍然会执行完成后释放锁 - 若是2,则获取到了自增值就立即释放,但会引起主从不一致,因此需要将binlog设置为mixed或者row格式。
sql_safe_updates,其要求sql能够击中索引或者通过limit限制了更新的行数对于一个事务,应该将更容易被多个事务访问的锁放在后面加,比如说店铺,而比如用户的锁则先加,这样能够减少店铺的锁占用的时间
由于事务之间可能产生死锁,因此要么设置最大等待超时时间,要么设置死锁检测。
InnoDB 内部维护一个有向图,图中的节点表示事务(Transaction),边表示锁的等待关系。
例如:事务A持有行X的锁,事务B请求行X的锁并被阻塞,则图中有一条边从B指向A(B→A,表示B在等待A释放锁)。
当某个事务请求锁时,如果锁已被其他事务持有,InnoDB 会更新等待图,添加一条新的边。
每次有事务请求锁失败(进入等待状态)时,InnoDB 会触发死锁检测。
深度优先搜索(DFS):InnoDB 通过DFS遍历等待图,检查是否存在环。如果发现环,则判定为死锁。
优化:为了减少性能开销,InnoDB 不会每次都全图遍历,而是从新加入的边出发,仅检查可能形成环的路径。
如果检测到死锁,InnoDB 会选择一个事务作为牺牲者(通常选择回滚成本更低的事务,例如修改数据量较小的事务),强制回滚该事务,并释放其持有的锁。
回滚后,等待图中对应的边被移除,其他被阻塞的事务可以继续执行。
因此由于事务的不断加入,图会变得越来越大,进行环检测是O(n)的操作,若n很大则cpu大量消耗。
可以通过中间件对操作相同key的事务限流,这样事务虽然也在等待,但是没有增加死锁检测的负担。
这个跟索引c的数据是一模一样的。
当索引值相同时,按照主键排序,因此索引最后的字段是主键的话,可以去掉该索引
元数据锁
全库只读,最好使用flush table with read lock,其比设置readonly的好处是: 1. 能够自动释放 2. 可能其他系统会使用readonly做主备逻辑
如果有不合适的,为什么,更好的方法是什么?
删除主键相当于重建整个表,mysql内部会使用一个隐式的自增字段存储记录。而创建主键则再次进行更改,将其从隐式转成显示的字段。因此如果需要重建主键索引则可以直接使用alter table T engine=InnoDB。
如果要删除自增主键,那么主键列必须将自增删除掉,因为隐式的主键也是自增的,一个表只能有一个自增字段
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
尽量使用自增主键,能够避免页分裂,同时减少普通索引叶子节点的占用空间
不论是删除主键还是创建主键,都会将整个表重建
删除或创建主键会重建表
覆盖索引、前缀索引、索引下推
索引主要优化手段。尽量避免回表从而提高查询性能
在一天一备的模式里,最坏情况下需要应用一天的binlog。比如,你每天0点做一次全量备份,而要恢复出一个到昨天晚上23点的备份。一周一备最坏情况就要应用一周的binlog了。
Percona XtraBackup 8.0.30-23引入了--register-redo-log-consumer参数。--register-redo-log-consumer参数默认为禁用状态。当启用时,此参数允许Percona XtraBackup在备份开始时注册为一个重做日志消费者。服务器不会移除Percona XtraBackup(消费者)尚未复制的重做日志。消费者读取重做日志并手动提升日志序列号(LSN)。在此过程中,服务器阻止写入操作。基于重做日志的消耗,服务器决定何时可以清理日志。
因为备库会很快同步主库的数据,如果发生误删数据,备库无法保证数据的恢复。而全量备份则可以留存定期的快照,当出现问题时能够回滚
我给你留一个问题吧。你现在知道了系统里面应该避免长事务,如果你是业务开发负责人同时也是数据库负责人,你会有什么方案来避免出现或者处理这种情况呢?
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
查找长事务
就是当系统里没有比这个回滚日志更早的read-view的时候。
由于当前系统中没有比undolog更早的readview才能删除undolog。因此应当避免长事务来防止undolog大量占用磁盘和buffer pool。
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
undolog使得记录能够往回回滚,使得mvcc读取到历史版本的数据
目前有团队在做基于redolog来做归档,从而去除binlog的依赖
redolog是innodb引入保证crash-safe的。而binlog则是mysql的归档日志,可以提供备份、从节点复制等功能。为了保证redolog与binlog的一致性,通常需要两阶段提交,从而防止mysql的数据与binlog数据不一致。主要在于需要保证事务的redolog状态至少为prepare状态,且binlog完整(如果当前redolog处于提交状态,则事务直接是有效的)
redolog是循环写的,只需要读取需要修改的数据(页)然后根据页的状态生成物理修改日志。使用redolog则无需直接去随机写修改磁盘页,而转变为了“顺序写redolog”
正常情况下的WAL或者说日志基本都是逻辑日志,而在mysql中redolog是物理日志,mysql如何知道要将数据写到物理磁盘上的那一个位置呢? Buffer Pool中为物理页的映射,由此知道如何在物理上进行数据的修改。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。你会在数据库的慢查询日志中看到一个rows_examined的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的
row_examined表示在执行器扫描的数据行数,不代表执行引擎扫描的数据行数
有些时候MySQL占用内存涨得特别快,这是因为MySQL在执行过程中临时使用的内存是管理在连接对象里面的
连接使用的一些内存资源只有在连接断开时释放。因此对于大查询或者长期使用的连接可以定期释放或者在5.7+执行mysql_reset_connection
Most applications do not need to process massive amounts of data. This has led to a resurgence in data management systems with traditional architectures; SQLite, Postgres, MySQL are all growing strongly, while “NoSQL” and even “NewSQL” systems are stagnating.
SQL still shines over NoSQL
MySQL是什么?它有什么优势?
The DDGLC data are not accessible online as of yet. A migration of the database and the data into aMySQL target system is underway and will allow us to offer an online user interface by the end of 2017 Whatwe can already offer now is a by-product of our work, the Gertrud Bauer Zettelkasten Online.6'
61 Available online at http://research.uni-leipzig.de/ddglc/bauerindex.html. The Work on this parergon to the lexicographical labors of the DDGLC project was funded by the Gertrud-und Alexander Böhlig-Stiftung. The digitization of the original card index was conducted by temporary collaborators and volunteers in the DDGLC project: Jenny Böttinger, Claudia Gamma, Tami Gottschalk, Josephine Hensel, Katrin John, Mariana Jung, Christina Katsikadeli, and Elen Saif. The IT concept and programming were carried out by Katrin John and Maximilian Moller.
Digitization of Gertrud Bauer's zettelkasten was underway in 2017 to put the data into a MySQL database with the intention of offering it as an online user interface sometime in 2017.
MySQL - Operand should contain 1 column(s) Ask Question
ResultMap collection多层嵌套使用
MySQL数据库,数据表超过百万了查询速度有点慢。之后怎么存储呢?
既然MySQL中InnoDB使用MVCC,为什么REPEATABLE-READ不能消除幻读?
数据库MVCC和隔离级别的关系是什么?
如何根据sql语句逆向生成回滚语句?
到底什么情况下mysql innodb会发生回表操作?
为什么会有人写出几百行的SQL语句啊?这些人的心态是怎样的?为了凸显自己的强大吗?
关于幻读,可重复读的真实用例是什么?
Cache 和 Buffer 都是缓存,主要区别是什么?
我们为什么要使用Mysql处理读写分离?读写分离有什么优点?
乐观锁与悲观锁各自适用场景是什么?
UNLOCK TABLES;
select sleep(N)可以让此语句运行N秒钟
PAREPARE STATEMENT
使用@DynamicUpdate性能会好一些。因为不使用@DynamicUpdate时,即使没有改变的字段也会被更新
那么查询索引本身已经“覆盖”了需要的数据,不再需要回表查询。因此,这种情况也叫作索引覆盖
extra中显示:use index,不是user index condition,也不是null
普通索引和change buffer的配合使用,对于数据量大的表的更新优化还是很明显的
然后提交
version被其他事务抢先更新
version拿到最新的当前值
事务B是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务C’释放这个锁,才能继续它的当前读。
update t set a = a + 1;
当前事务变更后,可重复读拿到的就是更新的数据
最可能造成锁冲突、最可能影响并发度的锁的申请时机尽量往后放
事务中的MDL锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
mdl只有在事务之后才会释放
比较理想的机制是,在alter table语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃
等待
使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。
SET collation_connection = 'utf8_general_ci';
编码
第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的
恢复目标时间
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
就是当系统里没有比这个回滚日志更早的read-view的时候
疑惑点
MySQL的隔离级别设置为“读提交
mysql默认是可重复读
创建一个视图
一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的
非所有数据,而是所读取行
幻读是读取了其他事务新增的数据,针对insert和delete操作
可重复读
感觉oracle的DG就诞生了,物理的速度也将远超逻辑的,毕竟只记录了改动向量
redo log和binlog都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致
如果中间出现事故,mysql会做相应处理两阶段提交
数据表和数据列是否存在, 别名是否有歧义等。如果通过则生成新的解析树,再提交给优化器
参数wait_timeout
连接超时时间
Binlog日志保留时长
mysqld
开启binlog
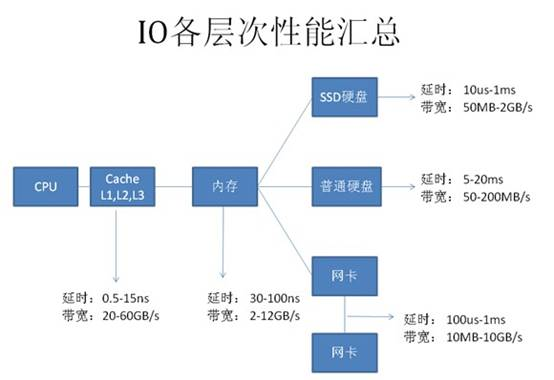
由图中可看到,每种设备都有两个指标: - 延时(响应时间):表示硬件的突发处理能力; - 带宽(吞吐量):代表硬件持续处理的能力。
大多数情况,性能最慢的设备会是瓶颈点。
如,下载时网络速度可能会是瓶颈点,本地复制文件时硬盘可能是瓶颈点。
为什么这些一般的工作能快速确认瓶颈点呢?
因为我们队这些慢速设备的性能数据有一些基本的认识,如网络带宽是 2 Mbps,硬盘是每分钟 7200 转等等。
(结论)因此,为了快速找到 SQL 的性能瓶颈点,需要了解计算机系统的硬件基本性能指标,如当前主流计算机性能指标数据。
数据库访问优化法则
(目的):要正确的优化 SQL;
(条件):需要快速定位性能的瓶颈点;
(进一步阐释说明):即是快速找到 SQL 主要的开销在哪里?
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password'
This fixed MySQL issues when installing Ghost on Ubuntu 20.04 on DigitalOcean.
The alternative for curl is a credential file: A .netrc file can be used to store credentials for servers you need to connect to.And for mysql, you can create option files: a .my.cnf or an obfuscated .mylogin.cnf will be read on startup and can contain your passwords.
I think you should normalize if you feel that introducing update or insert anomalies can severely impact the accuracy or performance of your database application. If not, then determine whether you can rely on the user to recognize and update the fields together. There are times when you’ll intentionally denormalize data. If you need to present summarized or complied data to a user, and that data is very time consuming or resource intensive to create, it may make sense to maintain this data separately.
When to normalize and when to denormalize. The key is to think about UX, in this case the factors are db integrity (don't create errors that annoy users) and speed (don't make users wait for what they want)
Can database normalization be taken too far? You bet! There are times when it isn’t worth the time and effort to fully normalize a database. In our example you could argue to keep the database in second normal form, that the CustomerCity to CustomerPostalCode dependency isn’t a deal breaker.
Normalization has diminishing returns
Now each column in the customer table is dependent on the primary key. Also, the columns don’t rely on one another for values. Their only dependency is on the primary key.
Columns dependency on the primary key and no dependency on other columns is how you get 2NF and 3NF
A table is in third normal form if: A table is in 2nd normal form. It contains only columns that are non-transitively dependent on the primary key
3NF Definition
if you care at all about storing timestamps in MySQL, store them as integers and use the UNIX_TIMESTAMP() and FROM_UNIXTIME() functions.
MySQL does not store offset
WordPress Database Switcheroo First, do a MySQL database export of the old database on the old server, create a new blank database on the new server, import the old data either in PHPMyAdmin or mysql directly in the command line. Make sure you have the new database selected, then run some SQL updates and replacement commands on the tables notably, wp_options, wp_posts, wp_postmeta. Use the code as below and swap in your old and new URLs, no trailing slashes. Also if necessary change the table prefix values where applicable (ie wp_ ) UPDATE wp_options SET option_value = replace(option_value, 'http://www.oldurl', 'http://www.newurl') WHERE option_name = 'home' OR option_name = 'siteurl'; UPDATE wp_posts SET guid = replace(guid, 'http://www.oldurl','http://www.newurl'); UPDATE wp_posts SET post_content = replace(post_content, 'http://www.oldurl', 'http://www.newurl'); UPDATE wp_postmeta SET meta_value = replace(meta_value,'http://www.oldurl','http://www.newurl');
This is really helpful when you're manually cloning a WP site. If you have a Domain of One's Own and you want to move a site from one user's account to another or fork a site into another user's account, this is really helpful.
DBA Por Acaso: RDS, MySQL e Tuning para Iniciantes
Outro assunto que não é explicitamente coberto por nossos tópicos, mas que é base importante para o administrador de sistemas na nuvem - e aqui coberto em um nível introdutório, para não assustar ninguém. E procura por Cloud em https://wiki.lpi.org/wiki/DevOps_Tools_Engineer_Objectives_V1 para ver como esse assunto é importante!
MySQL’s replication architecture means that if bugs do cause table corruption, the problem is unlikely to cause a catastrophic failure.
I can't follow the reasoning here. I guess it's not guaranteed to replicate the corruption like Postgres would, but it seems totally possible to trigger similar or identical corruption because the implementation of the logical statement would be similar on the replica.
My current process for debugging stored procedures is very simple. I create a table called "debug" where I insert variable values from the stored procedure as it runs. This allows me to see the value of any variable at a given point in the script, but is there a better way to debug MySQL stored procedures?
facing a similar issue