Progress in the life sciences is constrained not only by the difficulty of the underlying science, but by the complexity of the research workflows themselves.
这一观点挑战了传统认知,指出科学进步的主要瓶颈可能不是科学本身的难度,而是研究流程的复杂性。这暗示了优化工作流程可能比增加科学知识更能推动进步。
Progress in the life sciences is constrained not only by the difficulty of the underlying science, but by the complexity of the research workflows themselves.
这一观点挑战了传统认知,指出科学进步的主要瓶颈可能不是科学本身的难度,而是研究流程的复杂性。这暗示了优化工作流程可能比增加科学知识更能推动进步。
(1:20.00-1:40.00) What he describes is the following: Most of his notes originate from the digital using hypothes.is, where he reads material online and can annotate, highlight, and tag to help future him find the material by tag or bulk digital search. He calls his hypothes.is a commonplace book that is somewhat pre-organized.
Aldrich continues by explaining that in his commonplace hypothes.is his notes are not interlinked in a Luhmannian Zettelkasten sense, but he "sucks the data" right into Obsidian where he plays around with the content and does some of that interlinking and massage it.
Then, the best of the best material, or that which he is most interested in working with, writing about, etc., converted into a more Luhmannesque type Zettelkasten where it is much more densely interlinked. He emphasizes that his Luhmann zettelkasten is mostly consisting of his own thoughts and is very well-developed, to the point where he can "take a string of 20 cards and ostensibly it's its own essay and then publish it as a blog post or article."
(1:21:20-1:39:40) Chris Aldrich describes his hypothes.is to Zettelkasten workflow. Prevents Collector's Fallacy, still allows to collect a lot. Open Bucket vs. Closed Bucket. Aldrich mentions he uses a common place book using hypothes.is which is where all his interesting highlights and annotations go to, unfiltered, but adequately tagged. This allows him to easily find his material whenever necessary in the future. These are digital. Then the best of the best material that he's interested in and works with (in a project or writing sense?) will go into his Zettelkasten and become fully fledged. This allows to maintain a high gold to mud (signal to noise) ratio for the Zettelkasten. In addition, Aldrich mentions that his ZK is more of his own thoughts and reflections whilst the commonplace book is more of other people's thoughts.
https://nataliekraneiss.com/your-academic-reading-list-in-obsidian/
This is excellent! I was going to spend some time this week to write some custom code with Dataview to do this, but apparently there's a reasonably flexible plugin that will get me 95% of what I'm sure to want without any work!
https://threadreaderapp.com/thread/1601640985858957312.html
Example of a literature review/research workflow using online repositories (like Google Scholar, Scopus, Clarivate, etc.), Zotero, Research Rabbit, and Obsidian.
And there’s beginning to be more and more of an understanding on the scientific side and more and more interest on the side of people who are interested in developing tools for thought for understanding. How does the workflow of thinking happen when you have these tools that magnify your capabilities? There really hasn’t been a fraction of the amount of research on that as there has been on the development of the tangible tools themselves.
Bias towards researching tangible things needs time to be overcome, it's also a gear shift to higher level of complexity in viewpoint. Compare to my searches in my fav topics list, where does this apply / potential hardening of focus?
The paper describes four ontologies for representing workflows in Research Objects, and includes examples and motivation scenarios.
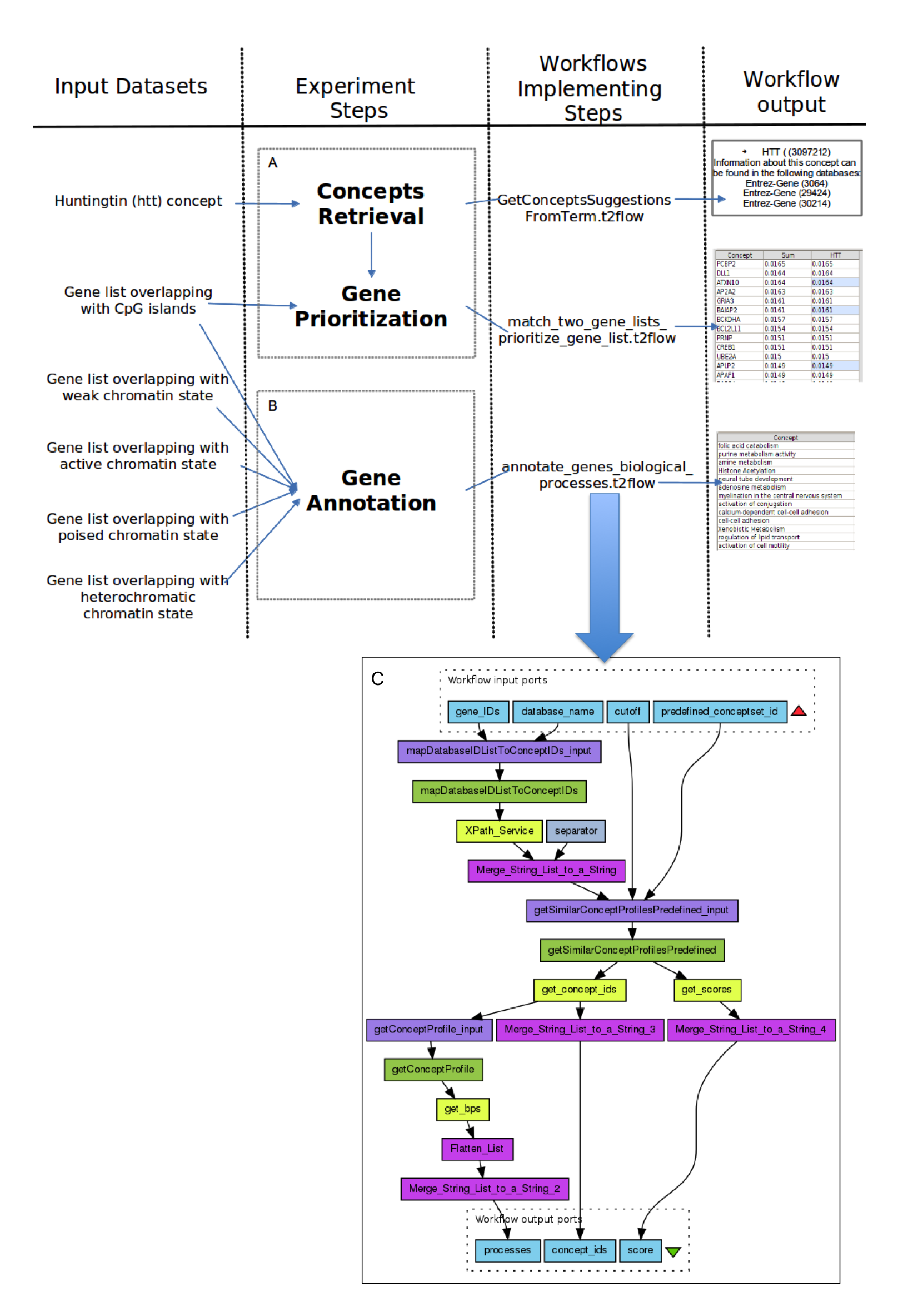
The ontologies developed make use of and extend existing well known ontologies, namely the Object Reuse and Exchange (ORE) vocabulary, the Annotation Ontology (AO) and the W3C PROV ontology (PROVO). We illustrate how the ontologies can be utilized using a real-world scenario, in which scientists created a Workflow Research Object for an investigation on the Huntington's disease. We also present the tools we developed for managing Workflow Research Objects.
Since most of our feeds rely on either machine algorithms or human curation, there is very little control over what we actually want to see.
While algorithmic feeds and "artificial intelligences" might control large swaths of what we see in our passive acquisition modes, we can and certainly should spend more of our time in active search modes which don't employ these tools or methods.
How might we better blend our passive and active modes of search and discovery while still having and maintaining the value of serendipity in our workflows?
Consider the loss of library stacks in our research workflows? We've lost some of the serendipity of seeing the book titles on the shelf that are adjacent to the one we're looking for. What about the books just above and below it? How do we replicate that sort of serendipity into our digital world?
How do we help prevent the shiny object syndrome? How can stay on task rather than move onto the next pretty thing or topic presented to us by an algorithmic feed so that we can accomplish the task we set out to do? Certainly bookmarking a thing or a topic for later follow up can be useful so we don't go too far afield, but what other methods might we use? How can we optimize our random walks through life and a sea of information to tie disparate parts of everything together? Do we need to only rely on doing it as a broader species? Can smaller subgroups accomplish this if carefully planned or is exploring the problem space only possible at mass scale? And even then we may be under shooting the goal by an order of magnitude (or ten)?
Stringing beads: from tool combinations to workflows
on research workflows and tools