Robert C. Hilborn (2017). Gravitational Waves without General Relativity: A Tutorial. Am. J. Phys. 86, 186-197 (2018).
An informative tutorial for GW community!
Robert C. Hilborn (2017). Gravitational Waves without General Relativity: A Tutorial. Am. J. Phys. 86, 186-197 (2018).
An informative tutorial for GW community!
矩阵表达式
需要校对下公式~
He Wan
Check
数字、序列、映射、类、实例和异常
这里罗列了完备的所有内置类型。
MelNet: A Generative Model for Audio in the Frequency Domain
本文的主要贡献如下:
提出了 MelNet。一个语谱图的生成模型,它结合了细粒度的自回归模型和多尺度生成过程,能够同时捕获局部和全局的结构。
展示了 MelNet 在长程依赖性上卓越的性能。
展示了 MelNet 在多种音频生成任务上优秀的能力:无条件语音生成任务、音乐生成任务、文字转语音合成任务。而且在这些任务上,MelNet 都是端到端的实现。
An Introduction to Variational Autoencoders
【导读】变分自编码器(VAE)是重要的生成式模型。与生成式对抗网络(GAN)类似,VAE也可以被用来生成逼真的图像和文本信息,但VAE的思想却与GAN有很大的区别。本文介绍Arxiv上的一篇93页VAE导论,该导论包含大量的公式推导和图示。
近几年来,生成式对抗网络(GAN)吸引了大量科研人员和工程师的关注。然而除了GAN,变分自编码器(VAE)也是这几年较为火热的重要的生成式模型。与GAN的利用生成器和判别器进行对抗的思路不同,VAE的核心组件是自编码器和KL散度约束。
Object Discovery with a Copy-Pasting GAN
利用复制粘贴生成对抗网络(GAN)进行对象发现 Relja Arandjelovic、Andrew Zisserman
在本文中,研究者解决了对象发现(object discovery)的问题,即针对给定的输入图像进行对象分割,并在不使用任何直接监督的情况下训练系统。研究者提出了一种新的复制粘贴生成对抗网络(GAN)框架,其中通过将一幅图像中的一个对象合成到另一幅图像中,生成器能够发现图像中的对象,因此判别器无法分清楚生成的是否为伪图像。在认真解决了一些细小问题,如阻止生成器「作弊」,这个游戏最终导致生成器学会选择对象,因为复制粘贴对象最有可能欺骗判别器。结果显示,该系统在四个迥然不同的数据集上表现良好,包括挑战杂乱背景中的大型对象外观变化。
RandomOut: Using a convolutional gradient norm to rescue convolutional filters
或许导师这回可以相信初始化网络后的稳定性一直就是一个问题了吧~ 另外,此文还是在优秀的 MXNet 框架上跑的,赞一个~
Kervolutional Neural Networks
卷积神经网络(CNN)能够在诸多计算机视觉任务中实现当前最优性能。但是,在非线性空间中建立卷积的研究投入很少。目前的研究主要利用激活层(activation layer),这样仅能提供逐点非线性。 为了解决这个问题,一种新的运算ker-volution(核卷积)被引入,其利用核方法(kernel trick)来近似人类感知系统的复杂行为。通过补丁级(patch-wise)核函数,核卷积神经网络(KNN)泛化卷积,增强模型能力,获取特征的高阶交互,但同时又没有引入附加参数。大量的实验表明,核卷积神经网络获得了较基线CNN更高的准确率和更快的收敛速度。
Recent Advances in Open Set Recognition: A Survey
异常检测的综述
A Discussion on Solving Partial Differential Equations using Neural Networks
有不少 insight 的讨论,如 Benefits and drawbacks of solving partial differential equations with neural networks:

Augmented Neural ODEs
神经常微分方程无法表示某些简单函数,本文提出更具表现力的增强神经ODE,可有效降低计算成本、改善泛化性
Image Generation from Small Datasets via Batch Statistics Adaptation
用批量统计适应从小数据集生成图像,仅用25张人脸图像微调预训练BigGANs/SNGANs
Evolutionary Generative Adversarial Networks
因为当前现有的很多GANS结构在训练的时候并不稳定,很容易就会发生模式崩塌的现象,在文中,作者提出一个新颖GAN框架称为进化对抗网络(E-GAN)。摒弃了单一的生成器的设定,将生成器当做一个族群,每个单个的生成器就是一个体,而每个个体的变异的方式是不同的。作者利用一种评价机制来衡量生成的样本的质量和多样性,这样只有性能良好的生成器才能保留下来,并用于进一步的培训。通过这种方式,E-GAN克服了个体对抗性训练目标的局限性,始终保留了对GANs的进步和成功做出贡献的最佳个体。
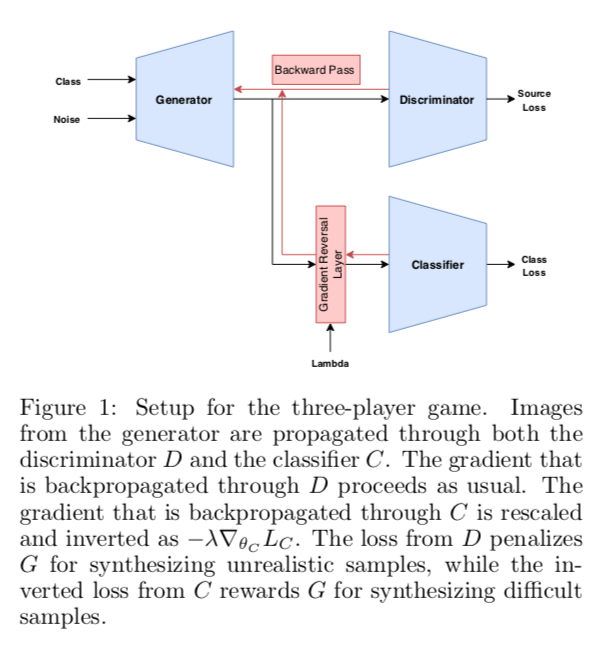
A Three-Player GAN: Generating Hard Samples To Improve Classification Networks
三方GANs,在生成器和分类器之间引入竞争,生成器的目标是合成既逼真又难以被分类器标记的样本
Phase-aware Speech Enhancement with Deep Complex U-Net
A Deep Generative Model of Speech Complex Spectrograms
对傅里叶变换建模~~
O-GAN: Extremely Concise Approach for Auto-Encoding Generative Adversarial Networks
本文通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。
Mean-field Analysis of Batch Normalization
BN 的平均场理论
Interplay Between Optimization and Generalization of Stochastic Gradient Descent with Covariance Noise
一个有趣的事实:batch-size 对训练收敛和模型泛化表现是有影响的,batch-size 越大,收敛越好,泛化变差。。。
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
提出了新的 LocalNorm。既然Norm都玩得这么嗨了,看来接下来就可以研究小 GeneralizedNorm 或者 AnyRandomNorm 啥的了。。。[doge]
Deep Learning Multidimensional Projections
深度学习版的降维可视化!
其中有好些是与 UMAP 和 t-sne 做的对比。
Transfusion: Understanding Transfer Learning with Applications to Medical Imaging
基于模型参数的迁移学习对 proformace 影响不大,当然训练更快啦。有趣的是,迁移 trained 模型参数的均值/方差统计性也可以得到不错的迁移效果。
On the Impact of the Activation Function on Deep Neural Networks Training
理论学习的好资料~~~
Seven Myths in Machine Learning Research
Reddit: http://t.cn/EVgQRrv Lots of negative comments, but it’s a pretty good article...//@iPHYSresearch:技术博客文章也可以在 arXiv 上过审了。。。。[费解] 这飘逸的格式。。。[doge]
Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent
谷歌大脑这篇文章脑洞很新奇!网络的训练拟合,可以看做是泰勒近似展开!in the infinite width limit, they are governed by a linear model obtained from the first-order Taylor expansion of the network around its initial parameters. Reddit 的讨论很棒!
On Evaluating Adversarial Robustness
大神 Goodfellow 参与的 paper 怎能不收藏呢?对抗样本始终是一个相当难啃的骨头。。。。
事实证明,正确评估针对对抗性案例的防御是非常困难的。尽管最近大量的工作试图设计出能够抵抗自适应攻击的防御措施,但很少有人成功;提出防御的大多数论文很快就被证明是错误的。作者认为一个很大的因素是执行安全评估的难度。在这篇论文中,作者讨论了方法论基础,回顾了普遍接受的最佳实践,并提出了评估对抗性示例的防御的新方法。这是一个开放性工作,贡献者包括Ian Goodfellow、Nicholas Carlini等人。
Deep Learning for Image Super-resolution: A Survey
【导读】图像超分(SR, Super-Resolution)图像处理及数据非常重要的应用方向,主要目标在于增强原始图像与视频的分辨率精度。最近这些年,非常多的图像超分问题研究均采用了深度学习的架构,本篇综述希望通过全面回顾基于深度学习的图像超分方法,帮助大家快速了解这一领域的最新动态。
图像超分问题,主要目标是图像处理技术中的重要研究方向,主要目标是将图片从低分辨率恢复到高分辨率的图像。这类方法具有非常广泛的应用价值,比如医疗影像、安防等等。通常来说,这一问题非常具有挑战性,因为总是存在多种对应于相同低分辨率图像的高分辨率映射。在以往的研究中,提出了一些传统的超分方法,包括基于预测的方法,基于边的方法,以及稀疏表示方法等等。
随着深度学习技术的快速发展,基于深度学习的图像超分方法已经被开发出来,并且在多个测试任务上,取得了目前最优的性能效果。多种深度学习方法已经被应用到具体的图像超分任务中,从早期的卷积神经网络(SRCNN)到最近提出的基于GAN的超分方法。通常来说,使用了深度学习的超分算法类中,存在着以下几种不同之处:网络架构不同、损失函数不同、学习原理、策略不同等。
在这篇文章中,主要给出了在超分算法中使用深度学习技术的一些优势。虽然存在着一些其他关于超分算法的综述,但我们不同之处在于主要关注基于深度学习的超分算法,而不像其他早期工作那样关注于传统的超分算法综述。本篇综述给出了一个统一的深度学习视角,来回顾最近的超分技术进展。
给出了一个综合的基于深度学习的图像超分技术综述,包括问题设置、数据集、性能度量、一组基于深度学习的图像超分方法集合,特定领域的图像超分方法应用等等。
为最近基于深度学习的图像超分算法提供了系统性、结构化的视角,并总结了高效图像超分解决方案中的优势于劣势。
我们讨论了这个领域的挑战与开放问题,并总结了最近的新趋势与未来的发展方向。
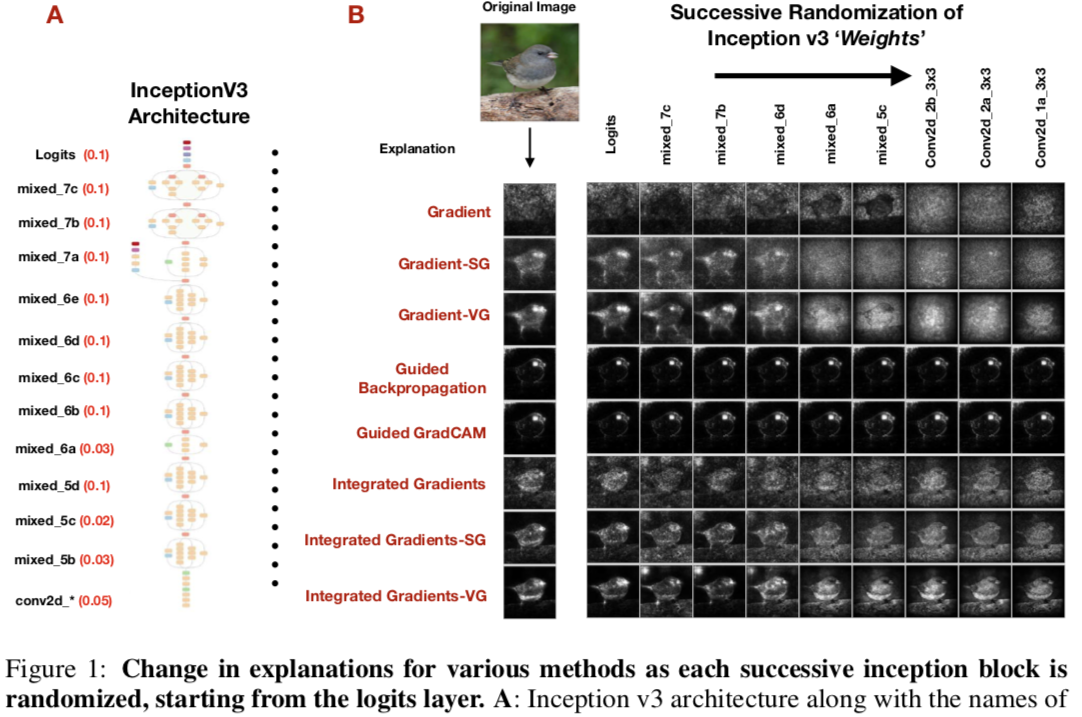
Why are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps
图二的对比图画得很有趣~ 虽然 idea 很简单,Threshold 的存在对Saliency的噪声去除起了关键作用。。。这似乎并没那么意外。。。
Deep learning approach based on dimensionality reduction for designing electromagnetic nanostructures
将深度学习应用于物理学,逐渐成为呼声很高的研究方法。这篇论文是相关工作中的一个代表,研究人员将深度学习技术应用于电磁纳米结构的分析、设计和优化研究当中,不仅大大地降低了分析和设计的计算复杂度,还能够提供新的设计方案(例如本文中设计了一种全新的基于相变材料的可重构光学超曲面)。作者将相关的软件集合成一个工具包,免费开放,可促进电磁纳米结构的研究。
Maximum Entropy Generators for Energy-Based Models
【能量视角下的GAN模型】本文直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》,作者给出了GAN/WGAN的清晰直观的能量图像,讨论了判别器(能量函数)的训练情况和策略,指出了梯度惩罚一个非常漂亮而直观的能量解释。此外,本文还讨论了GAN中优化器的选择问题。http://t.cn/EcBIwqJ
Impact of Fully Connected Layers on Performance of Convolutional Neural Networks for Image Classification
作者总结说:1)CNN 层越少,FC 层里的node 就要越多才行。相反 CNN 越深,FC node 少就够了;2)浅的 CNN 除了需要更多 FC node 外,数据集 class 类目数越多,FC 层应该越多越好,反之亦然;3)对于单个 class 内样本越多的数据集,网络越深越好,但若 class 类目数很多,浅的网络表现会更好。
A Layer-Based Sequential Framework for Scene Generation with GANs
以 Mask 作为 Input 进行“场景生成”。现在对 GAN 生成技术的控制玩得越来越柔韧有俞~~

Are All Layers Created Equal?
Google的这文2个 idea 很简单:一个是在 trained 网络各层的参数分别换回训练前的初始参数而观察相应各层的鲁棒性;另一个是把上一个 idea 基础上把那套初始参数再从某分布中随机取一次瞅效果。此 paper 的严谨的验证试验过程是最值得学习的~[并不简单]
Perturbative GAN: GAN with Perturbation Layers
作者提出了更好更快更强的 Perturbative GAN。记得去年 CVPR2018的一篇《Perturbative Neural Networks》被 reddit 一网友提出质疑闹得满城风雨,最后还不是打脸(http://t.cn/EcYUjg4)[doge],而这进一步的工作又出来了,真的是真金不怕火炼啊![赞]
Do we train on test data? Purging CIFAR of near-duplicates
作者玩了把 CIFAR 测试数据集,认为有些样本作为 test 会与 train 样本太相近而过拟合的问题,于是就自己替换了疑似问题样本提出了新 test 数据集,最后拿那些著名模型实验后,庆幸说貌似它们没有过拟合而被错误评估模型优劣~(有点打脸的感觉~)
TUNet: Incorporating segmentation maps to improve classification
Twin U-Net… 貌似这一个脑洞可以串联出好多脑洞。。。。
Weighted Channel Dropout for Regularization of Deep Convolutional Neural Network
这项工作由 Hou 和 Wang 完成,受到了以下观察的启发。在一个 CNN 的卷积层的堆栈内,所有的通道都是由之前的层生成的,并会在下一层中得到平等的对待。这就带来了一个想法:这样的「分布」可能不是最优的,因为事实可能证明某些特征比其它特征更有用。当特征仍然可追溯时,对于更高层(更浅)来说尤其如此。Zhang et al. 2016 更进一步表明了这一点,他们表明,对于每张输入图像,更高层中仅有少量通道被激活,同时其它通道中的神经元响应接近于零。
由此,作者提出了一种根据激活的相对幅度来选择通道的方法,并可以进一步作为一种建模通道之间的依赖关系的特殊方法。他们这项工作的主要贡献是为 CNN 中卷积层的正则化提出了加权式通道丢弃(Weighted Channel Dropout/WCD)方法。
Semantic Redundancies in Image-Classification Datasets: The 10% You Don't Need
深度神经网络版的“特征工程”技术~ [doge]
Revisiting Self-Supervised Visual Representation Learning
无监督的视觉表示学习在计算机视觉研究中仍然是一个很大程度上未解决的问题。在最近提出的用于无监督学习视觉表示的方法中,一类自我监督技术在许多具有挑战性的基准上实现了卓越的性能。已经研究了大量的自我监督学习的前提任务,但其他重要的方面,如卷积神经网络(CNN)的选择,并没有得到同等的关注。因此,我们重新审视了许多以前提出的自我监督模型,进行彻底的大规模研究,结果发现了多个关键的问题。我们挑战了自我监督的视觉表现学习中的一些常见实践,并观察到CNN设计的标准配方并不总是转化为自我监督的表征学习。作为我们研究的一部分,我们大大提高了先前提出的技术的性能,并且大大优于以前发布的最先进的结果。
An Introduction to Image Synthesis with Generative Adversarial Nets
GAN 自 2014 年诞生至今也有 4 个多年头了,大量围绕 GAN 展开的文章被发表在各大期刊和会议,以改进和分析 GAN 的数学研究、提高 GAN 的生成质量研究、GAN 在图像生成上的应用(指定图像合成、文本到图像,图像到图像、视频)以及 GAN 在 NLP 和其它领域的应用。图像生成是研究最多的,并且该领域的研究已经证明了在图像合成中使用 GAN 的巨大潜力。本文对 GAN 在图像生成应用做个综述。
Decoupled Greedy Learning of CNNs
基于反向传播的神经网络在训练过程中一个造成低效的问题是,每个层必须等信号在网络中传播之后才能更新。在这篇文章中,作者考察并分析了一种称为“解耦贪心学习”(Decoupled Greedy Learning)的训练程序,这个过程可以有效地解决上述问题。
Deep Learning on Small Datasets without Pre-Training using Cosine Loss
在当代深度学习中,有两件事似乎无可争议:
Unsupervised speech representation learning using WaveNet autoencoders
我们通过将自动编码神经网络应用于语音波形来考虑无监督提取有意义的语音潜在表示的任务。目标是学习能够从信号中捕获高级语义内容的表示,例如,音素身份,同时不会混淆信号中的低级细节,例如底层音高轮廓或背景噪音。自动编码器模型的行为取决于应用于潜在表示的约束类型。我们比较了三种变体:简单的降维瓶颈,高斯变分自动编码器(VAE)和离散矢量量化VAE(VQ-VAE)。我们根据说话人的独立性,预测语音内容的能力以及精确重建单个谱图帧的能力来分析学习表征的质量。此外,对于使用VQ-VAE提取的差异编码,我们测量将它们映射到电话的容易程度。我们引入了一种正则化方案,该方案强制表示集中于话语的语音内容,并报告性能与ZeroSpeech 2017无监督声学单元发现任务中的顶级条目相当。 【translated by 谷歌翻译】
【摘要自机器之心】:
论文《Unsupervised speech representation learning using WaveNet autoencoders》介绍了通过将自编码神经网络用到语音波形提取语音中有意义的隐藏表征的无监督任务。目的是学习到一种能够捕捉信号中高层次语义内容的表征,同时又能够对有背景噪声或者潜在基频曲线(underlying pitch contour)的信号中的扰乱信息足够稳定。自编码器模型的行为由应用到隐藏表征的约束所决定。在此论文中,作者对比了三种变体:简单降维瓶颈、高斯变分自编码器和离散向量量化VAE。而后,作者对预测语音内容的能力等进行了分析。
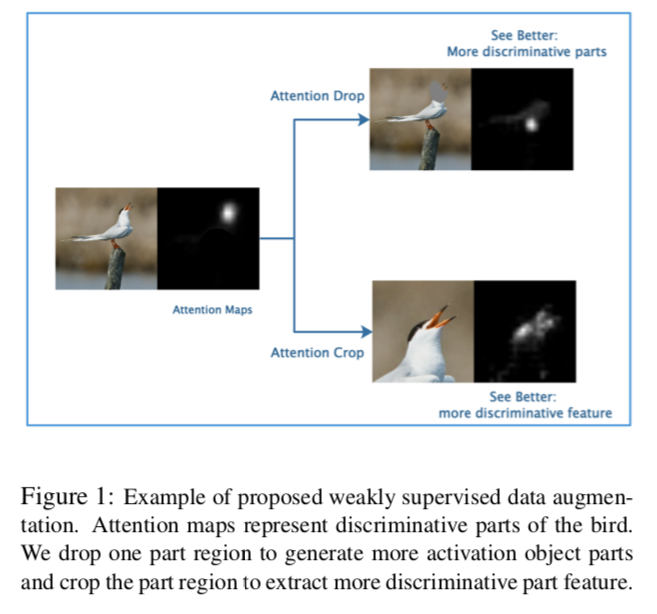
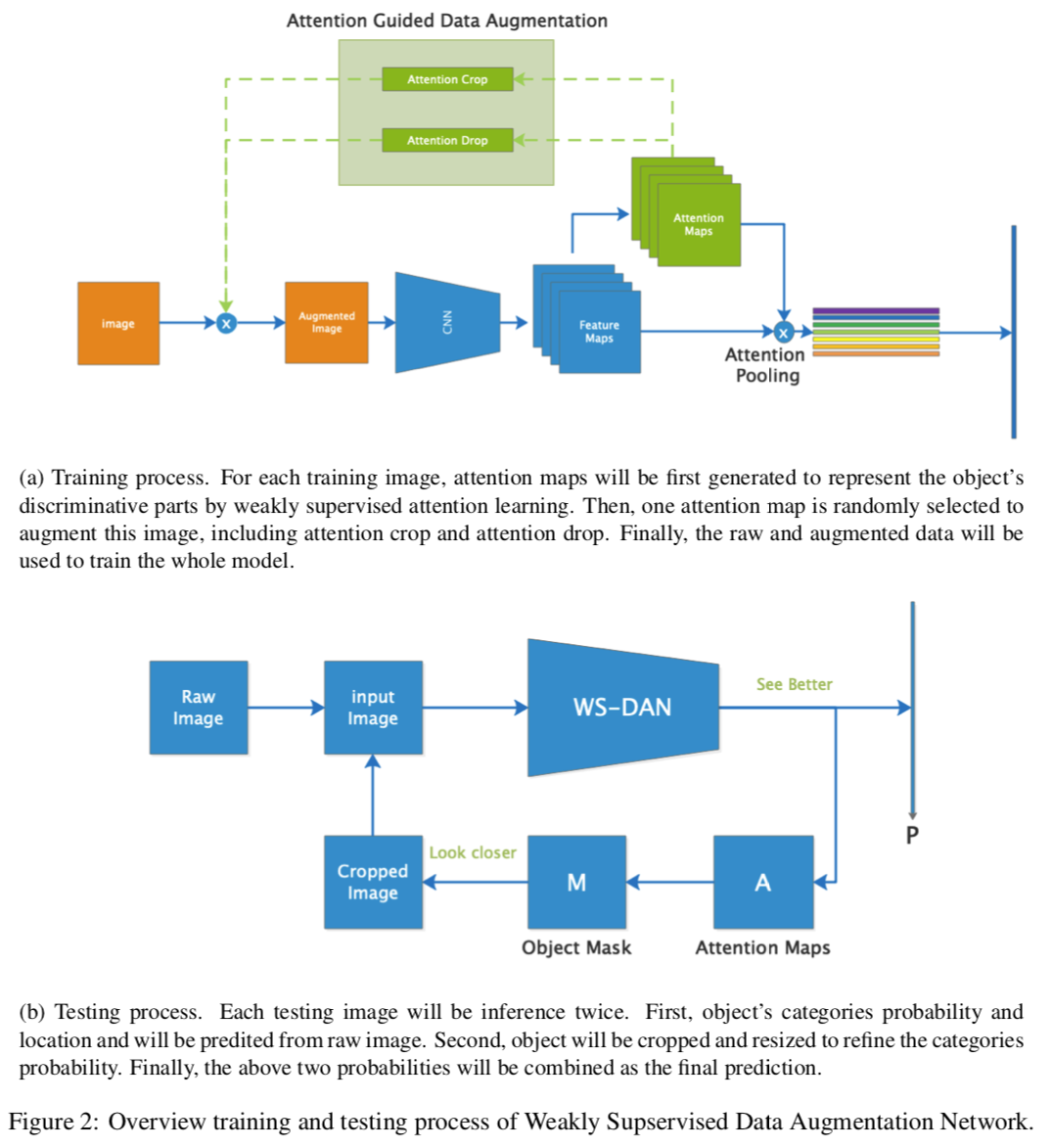
See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification
一篇来自中科院的 paper。充分利用每个样本的 attention map 在训练和测试阶段都作为有效信息送入模型来“学习”和“检验”模型,从而实现数据扩增(成对生成正反 label)和对非相关噪声特征更加鲁棒。
Using Pre-Training Can Improve Model Robustness and Uncertainty
此 paper 回应并补充了去年何神的一篇说 pre-training 对 performance 鸟用不大的文章 (Rethinking ImageNet Pre-training)。你问是怎么回应的?瞅一眼此 paper 的题目就晓得了。。。。
Fixup Initialization: Residual Learning Without Normalization
关于拟合的表现,Regularization 和 BN 的设计总是很微妙,尤其是 learning rate 再掺和进来以后。此 paper 的作者也就相关问题结合自己的文章在 Reddit 上有所讨论。
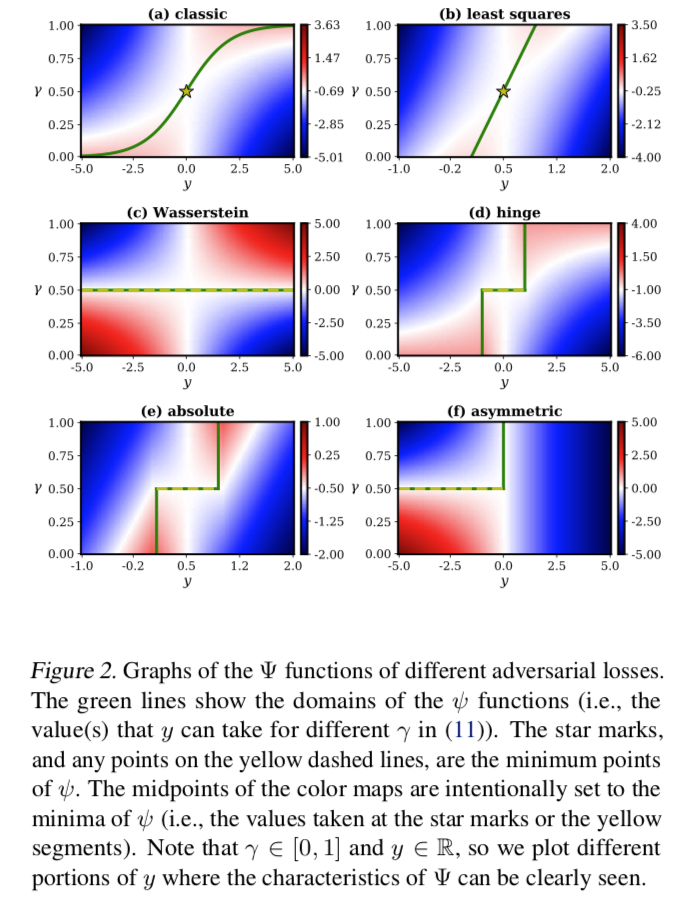
Towards a Deeper Understanding of Adversarial Losses
研究了各种对抗生成训练的 losses,还可以 know which one of them makes an adversarial loss better than another。
Fitting A Mixture Distribution to Data: Tutorial
目测是一篇很有爱的教程!
A Survey of the Recent Architectures of Deep Convolutional Neural Networks
深度卷积神经网络(CNN)是一种特殊类型的神经网络,在各种竞赛基准上表现出了当前最优结果。深度 CNN 架构在挑战性基准任务比赛中实现的高性能表明,创新的架构理念以及参数优化可以提高 CNN 在各种视觉相关任务上的性能。本综述将最近的 CNN 架构创新分为七个不同的类别,分别基于空间利用、深度、多路径、宽度、特征图利用、通道提升和注意力。
Understanding Geometry of Encoder-Decoder CNNs
由于计算机视觉,医学成像等各种逆问题的优异性能,使用卷积神经网络(CNN)架构的编码器 - 解码器网络已被广泛用于深度学习文献中。然而,仍然难以获得相干几何学视图为何如此架构提供了理想的性能。最近对神经网络的普遍性,表现力和优化景观的理论认识以及卷积框架理论的启发,在这里我们提供了一个统一的理论框架,有助于更好地理解编码器 - 解码器CNN的几何。我们的数学框架表明,编码器 - 解码器CNN架构与使用组合卷积帧的非线性基表示密切相关,其可表达性随着网络深度呈指数增长。我们还展示了跳过连接的可表达性和优化环境的重要性。
Training Neural Networks with Local Error Signals
自 GoogLeNet 之后,local loss 这个 idea 恐怕并不新鲜了吧~
Exploring Disentangled Feature Representation Beyond Face Identification
Accepted by CVPR 2018, 香港中文大学、北京大学和商汤科技的文章. 这篇采用了对抗的思路来获得人脸表征, 并使用AutoEncoder的结构训练出了一个属性可控的人脸生成模型. 具体来讲, encoder部分使用Inception-ResNet作为backbone, 在最后使用Distilling和Dispelling分支分别学习与ID相关/无关的特征; decoder部分使用这两个特征concat的结果作为输入, 经过TransposeConv和Upsampling获得输出图像. 最终在LFW的精度是99.8, 生成人脸的效果也比较出色.
?
Artificial Neural Networks
三大板块:Hopfield 网络+ 监督学习+非监督学习
Optimization Models for Machine Learning: A Survey
感觉此文于我而言真正有价值的恐怕只有文末附录的 Dataset tables 汇总整理了。。。。。
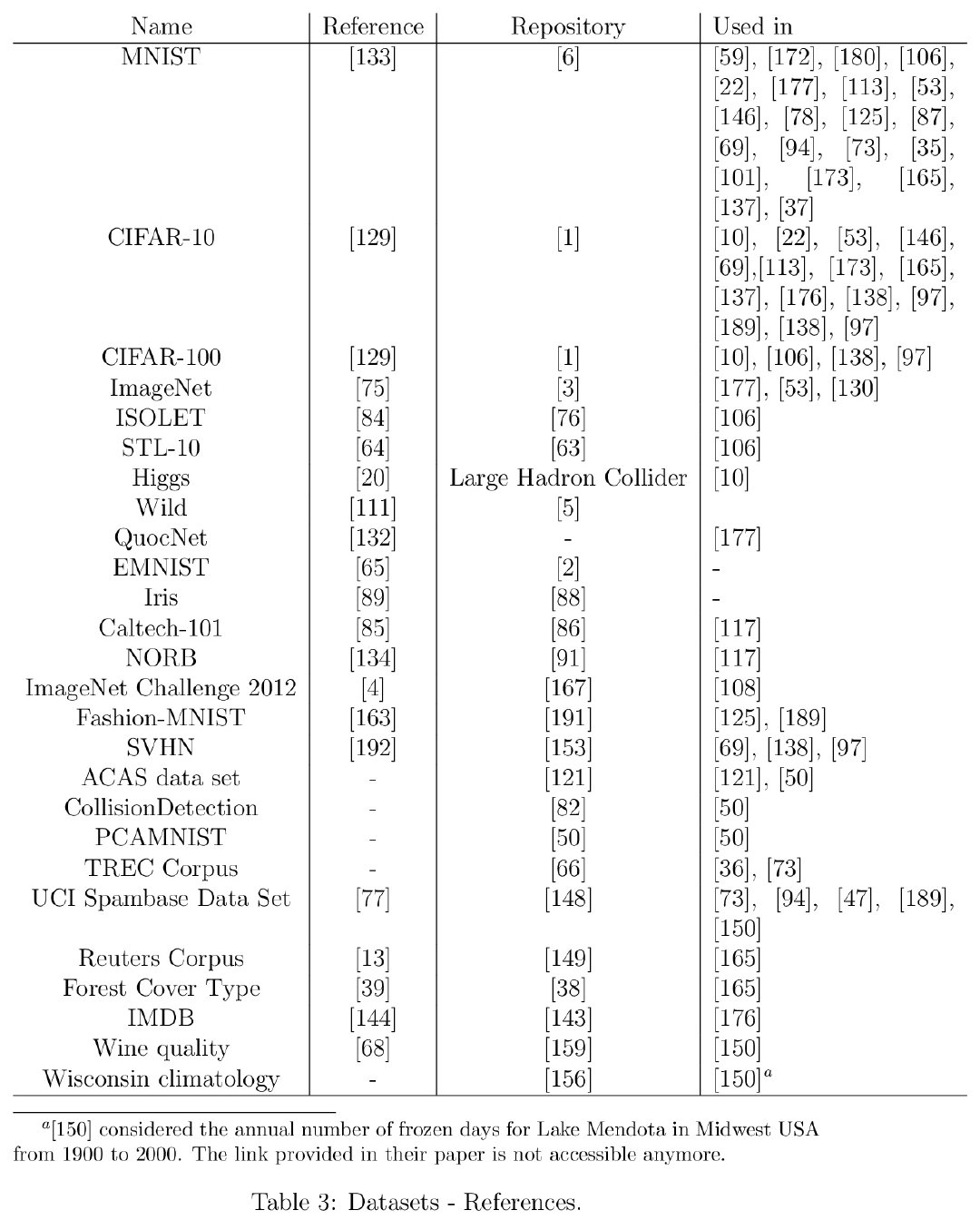
MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks
这 paper 挺神的,用 GAN 做时序数据异常检测。主要神在 G 和 D 都仅用 LSTM-RNN 来构造的!不仅因此值得我关注,更因为该模型可以为自己思考“非模板引力波探测”带来启发!
Eliminating all bad Local Minima from Loss Landscapes without even adding an Extra Unit
好猛的 paper,全文就一页,仅两个引用!一个简单的 idea:引入两个辅助参数,使得新 loss 的任何局部极小都是原 loss 的全局最小。小槽点:
一点实验都不做,都留给读者,真的合适么?[笑cry]
配图很好看,主要是感觉和 “Neural Ordinary Differential Equations” 很像~
Image Transformation can make Neural Networks more robust against Adversarial Examples
这个小文就是想告诉我们,要想提高对抗样本的鲁棒性,“转一转”你手上的样本就好了。。。。。
Explanatory Graphs for CNNs
Q Zhang 在知乎上亲自解答关于 Explanatory Graphs 的技术细节和研究理念~ http://t.cn/EqfQbAW [赞]
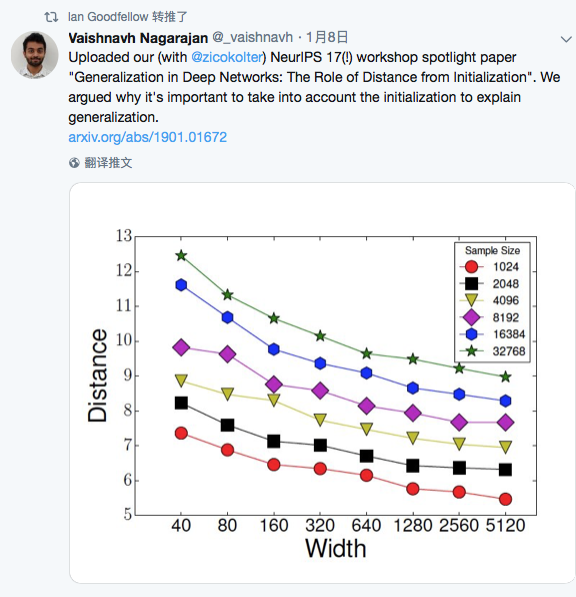
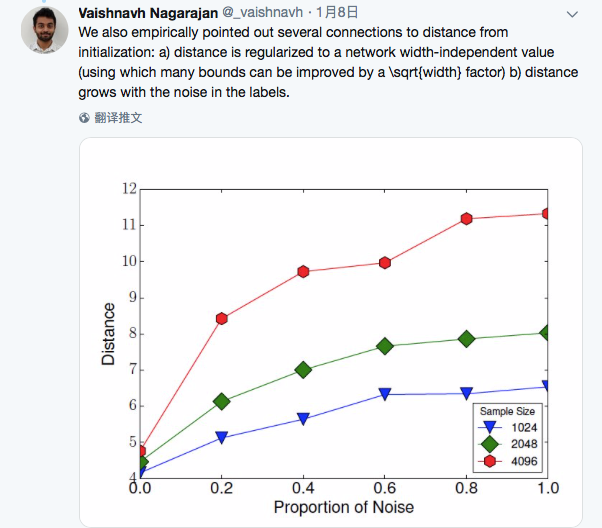
Generalization in Deep Networks: The Role of Distance from Initialization
Goodfellow 转推了此文。
作者强调了模型的初始化参数对解释泛化能力的重要性!
Learning with Fenchel-Young Losses
又见到 Blondel 的关于 Fenchel-Young Losses 的 paper,虽然看不懂,不过不明觉厉~
InstaGAN: Instance-aware Image-to-Image Translation
这两天很火的 paper,新的 InstaGAN 不仅对抗编码一幅图像,还可以同时编码其中的实例。
网络结构图:

Improving Generalization and Stability of Generative Adversarial Networks
GANs with 0-GP (a zero-centered gradient penalty)。通过重新设计正则化方案,来提升 GANs 的表现,网络也更加稳定,对超参数更鲁棒。
Generative Models from the perspective of Continual Learning
蛮有趣的实验!读读 OpenReview.net 上匿名审稿人和作者之间的对话也会收获颇多~~
Finger-GAN: Generating Realistic Fingerprint Images Using Connectivity Imposed GAN
CFUN: Combining Faster R-CNN and U-net Network for Efficient Whole Heart Segmentation
图做得很好看~~~
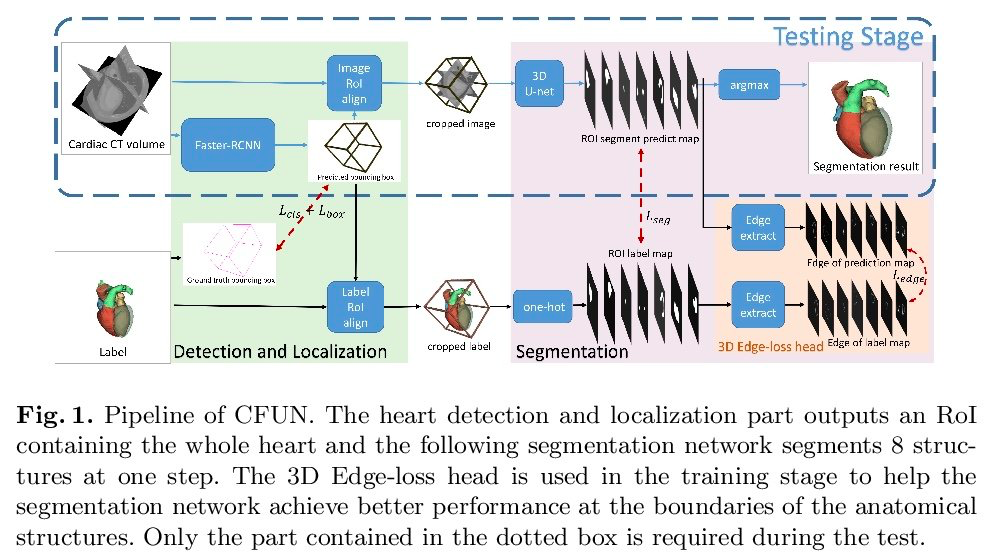
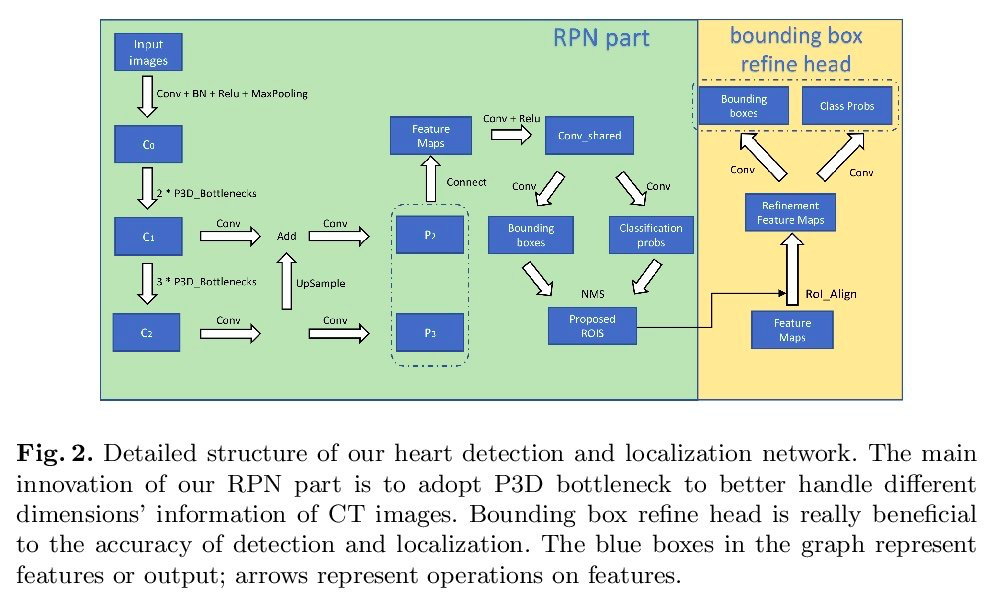
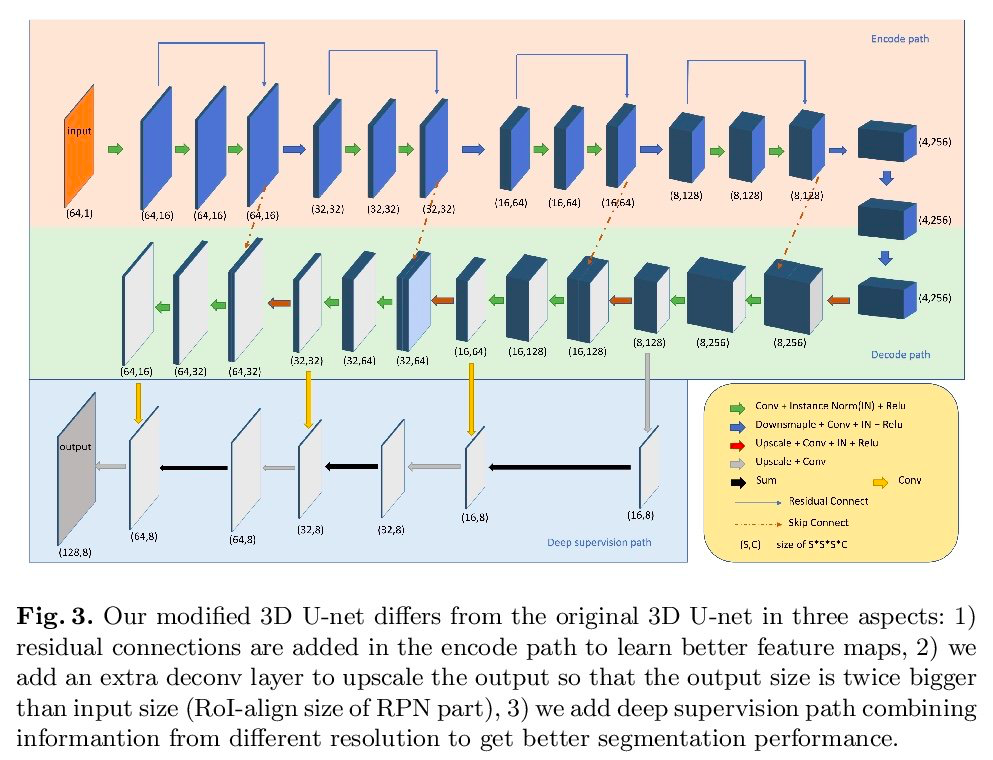
Deep Paper Gestalt
这是个迷人的研究:
“bad paper 都写不满8页”;
“paper 头2页里没有插图的话会让读者摸不到头绪”;
“good paper 首页都有图说明 main ideas,有各种图表等会均衡分布 paper 中来展示验证性实验,重要数学公式,以及有彩图列表来量化数据集的基准”
“作者还自嘲了本 paper 97%概率被拒稿[doge]”;
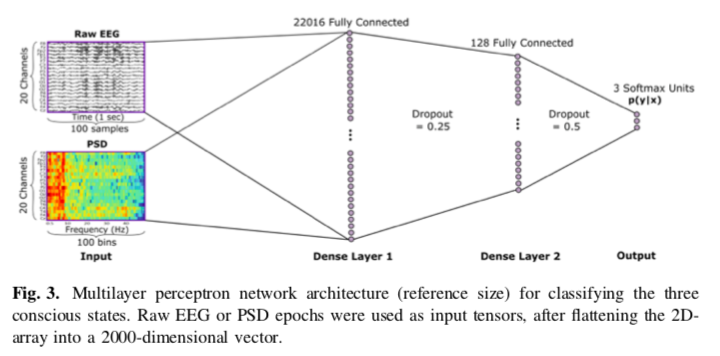
Deep Neural Networks for Automatic Classification of Anesthetic-Induced Unconsciousness
spatio-temporo-spectral features.
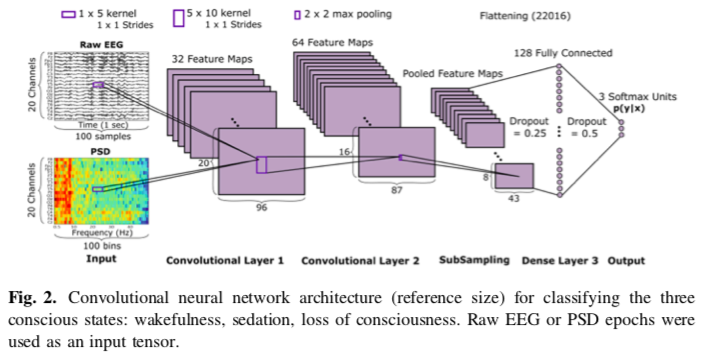
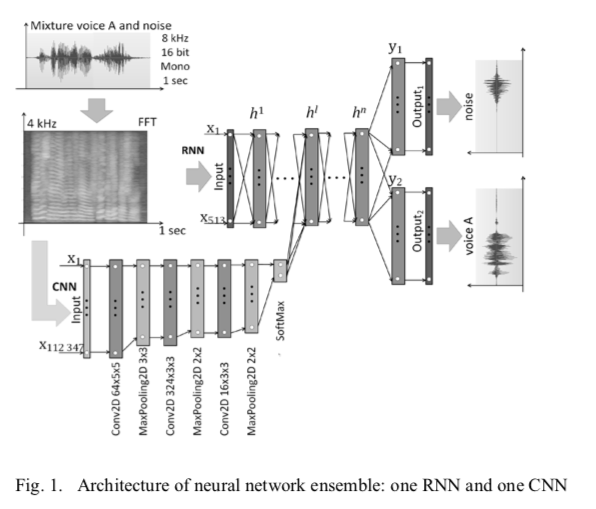
Using Convolutional Neural Networks to Classify Audio Signal in Noisy Sound Scenes
先辨别信号位置,再过滤出信号,这和 LIGO 找event波形的套路很像~ ;又看到 RNN与CNN 结合起来的应用~
Are All Training Examples Created Equal? An Empirical Study
从此paper了解到了叫 Active learning 的有趣概念,这似乎和自己设计的连续参数训练数据采样池很接近。。。。
这篇文章的主要工作是给出了一个在图像分类中关于训练样本重要性的研究,对于样本的重要度采用基于梯度的方法进行度量。文章的结论可能表明在深度学习中主动学习或许并不总是有效的。
A Tutorial on Distance Metric Learning: Mathematical Foundations, Algorithms and Software
很不错的 Distance Metric Learning 综述性材料,富含概念,如何设计DML算法,DML 算法的数学理论是怎样的(凸优化、矩阵分析、信息论)等等。最后开源了Python 库 pyDML 以方便研究此 paper 中的算法。
A Probe into Understanding GAN and VAE models
paper 提出了个 VAE-GAN 模型,不过正如作者自己说的可能是 GPU 资源不够,图像质量并不太如意,而且用的是 FCN 不是 CNN;主要用 Entropy 来量化评估生成变现。
Understanding Individual Decisions of CNNs via Contrastive Backpropagation
文中的 Deep Taylor Decomposition 这个理论假定有那么点意思~
Generalized Batch Normalization: Towards Accelerating Deep Neural Networks
核心是这么一句话: Generalized Batch Normalization (GBN) to be identical to conventional BN but with
standard deviation replaced by a more general deviation measure D(x)
and the mean replaced by a corresponding statistic S(x).
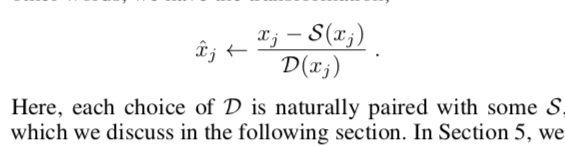
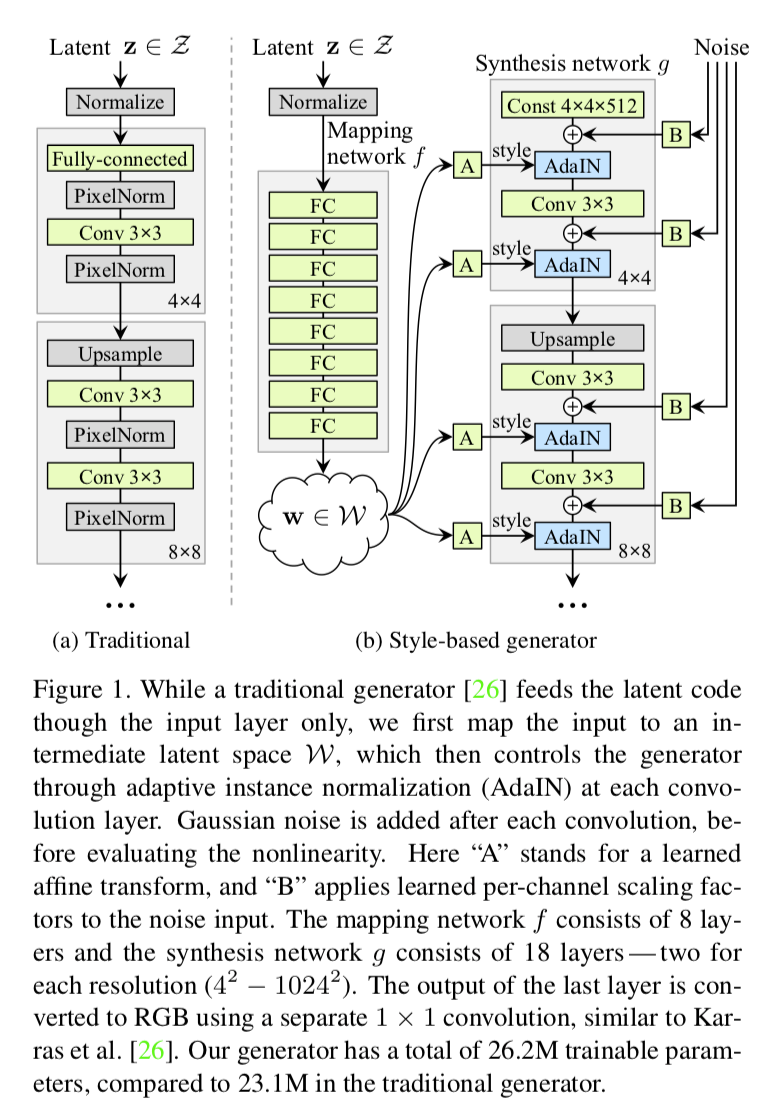
A Style-Based Generator Architecture for Generative Adversarial Networks
带风格变化的“变脸”~ 此文的开源代码应该很值得期待!

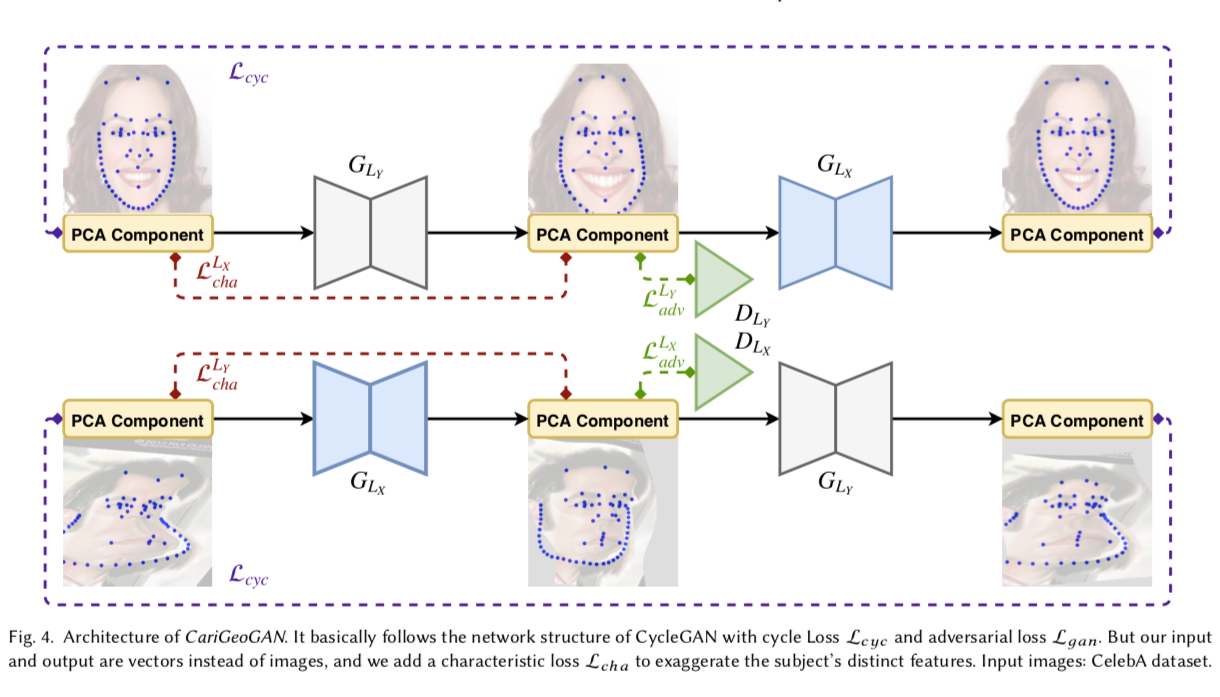
CariGANs: Unpaired Photo-to-Caricature Translation
照片转动画。。。
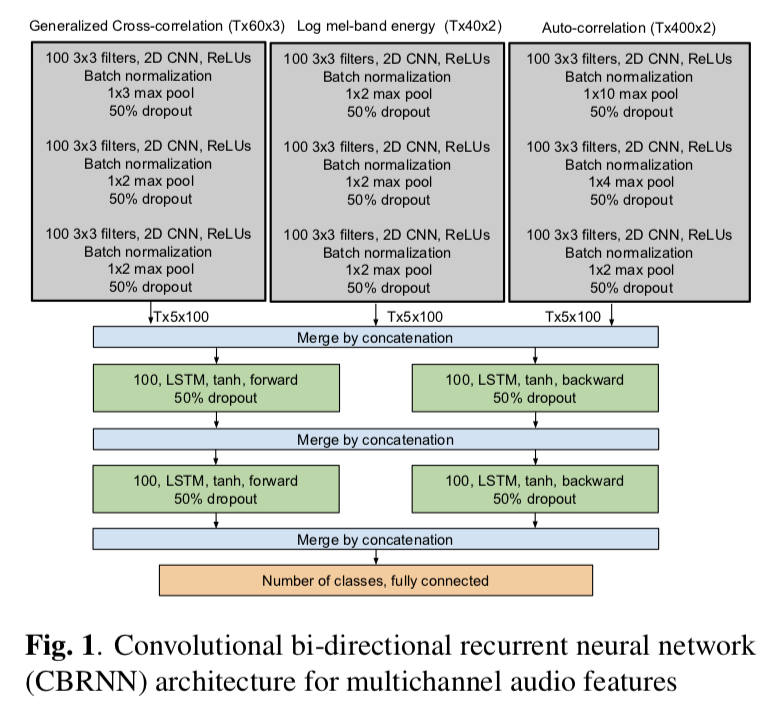
Sound Event Detection Using Spatial Features and Convolutional Recurrent Neural Network.
输入数据是多通道音频信号,网络是结合了CNN 和 LSTM。
Physics-guided Neural Networks (PGNNs)
曹老师推来让我读读的 paper
Generalization and Equilibrium in Generative Adversarial Nets (GANs)
转自作者 Yi Zhang 在知乎上的回答:https://www.zhihu.com/question/60374968/answer/189371146
老板在Simons给的talk:https://www.youtube.com/watch?v=V7TliSCqOwI
这应该是第一个认真研究 theoretical guarantees of GANs的工作
使用的techniques比较简单,但得到了一些insightful的结论:
在只给定training samples 而不知道true data training distribution的情况下,generator's distribution会不会converge to the true data training distribution.
答案是否定的。 假设discriminator有p个parameters, 那么generator 使用O(p log p) samples 就能够fool discriminator, 即使有infinitely many training data。
这点十分反直觉,因为对于一般的learning machines, getting more data always helps.
几乎所有的GAN papers都会提到GANs' training procedure is a two-player game, and it's computing a Nash Equilibrium. 但是没有人提到此equilibrium是否存在。
大家都知道对于pure strategy, equilibrium doesn't always exist。很不幸的是,GANs 的结构使用的正是pure strategy。
很自然的我们想到把GANs扩展到mixed strategy, 让equilibrium永远存在。
In practice, 我们只能使用finitely supported mixed strategy, 即同时训练多个generator和多个discriminator。借此方法,我们在CIFAR-10上获得了比DCGAN高许多的inception score.
通过分析GANs' generalization, 我们发现GANs training objective doesn't encourage diversity. 所以经常会发现mode collapse的情况。但至今没有paper严格定义diversity或者分析各种模型mode collapse的严重情况。
关于这点在这片论文里讨论的不多。我们有一篇follow up paper用实验的方法估计各种GAN model的diversity, 会在这一两天挂到arxiv上。
Bag of Tricks for Image Classification with Convolutional Neural Networks
李沐老师们的 paper!Pretty much summaries of various tricks by itself!
Paper Summary
Reddit: http://t.cn/Ey1gZKo
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)
BatchNorm有效性原理探索——使优化目标函数更平滑
How convolutional neural network see the world - A survey of convolutional neural network visualization methods
果断收藏并且要细读下。。。Paper Summary 准备!
这可是对 CNN 可视化方法的 review 啊!
一篇很棒的综述,专门说 CNN 的可视化的!要好好读读了!
Paper Summary 准备!
Improved Techniques for Training GANs
训练GANs 其实是一个找纳什均衡的问题。但是找高维连续非凸问题的纳什均衡点是很困难的。
Image Score: How to Select Useful Samples
提出的 semi-supervised learning 这个概念比较有趣。给数据集每个 sample 打分或许对 interpretability 有点帮助吧。。。。
Linear Backprop in non-linear networks
这年头~ 非线性梯度也可以不用算了。。。嗅到一丝 DNN 要返祖回到 ANN 的味道。
Seeing in the dark with recurrent convolutional neural networks
目测一些结果和自己的 paper 很接近,同时此 paper 于我而言,有太多值得借鉴的地方!同时又看到了 recurrency(类循环记忆单元)在模式识别领域有着很必要的用武之地!
Analyzing the Noise Robustness of Deep Neural Networks
清华的这篇文章似乎有着很不错的可视化图像,企图对模型对抗性进行可视化解释,不知道他们是否有在非DL模型上去考察对抗样本是如何分错的?毕竟并不仅仅是复杂模型才会有对抗问题哦。。
Multilevel Wavelet Decomposition Network for Interpretable Time Series Analysis
初步扫了一眼,感觉这篇文章应该可以给我一些 idea,内含我感兴趣(看得懂)的方法/机制,另外综述的参考文献对我来时也应该很有帮助。
本文是北京航空航天大学发表于KDD 2018的文章,作者提出了将小波变换和深度神经网络进行完美结合,克服了融合的损失,对时间序列数据的分析起到了很好的启发性研究。
Summary
Learning with Random Learning Rates
作者提出了一种新的Alrao优化算法,让网络中每个 unit 或 feature 都各自从不同级别的随机分布中采样获得其自己的学习率。该算法没有额外计算损耗,可以更快速达到理想 lr 下的SGD性能,用来测试 DL 模型很棒!
Deep convolutional Gaussian processes
似乎很有趣,可惜我统计没学好,没掌握到背后的本质,需要回炉重造了[委屈]~ 文章居然用的是今年年初发表的 UMAP 进行降维可视化,而不是 t-sne,这很新颖嘛!
Learning Confidence Sets using Support Vector Machines
也是一篇讨论“置信度”的文章。将二分类问题转化为一个分别独立的“三分类”问题,且分类边界可学习,而边界的取定用 SVM。文章里似乎有不少详尽的数学理论推导,值得练手推推看~
Interpreting Adversarial Robustness: A View from Decision Surface in Input Space
通常人们都认为,局部最小损失的超平面在参数空间中越平坦,就意味着泛化能力越好。但此文通过可视化某种决策边界认为在原始输入空间中就可以察觉到对抗性鲁棒的端倪~(这个结论还需广泛复现吧,自己不试验下也不敢确信,毕竟缺乏理论基础~[可怜])
Spurious samples in deep generative models: bug or feature?
此文引言还算引人入胜的。全文似乎就为了阐述一件事情:Spurious samples are not simply errors but a feature of deep generative nets. 但我怎么觉得这是一句废话呢?不然你以为 generate model 是根据什么 generate samples 的呢?
Inhibited Softmax for Uncertainty Estimation in Neural Networks
这种关乎网络“置信度confidence”或者叫“不确定度uncentainty”的 paper 还是挺有意义的,虽然现在还是婆说婆有理的阶段。文内综述了很多 Related 工作,还是挺值得 mark 下的。作者提的Inhibited Softmax蛮好理解的,另repo里放了不少ipynb文档[good]。
Deep processing of structured data
此文提出“set aggregation network”(SAN)子网络,但说白了是将卷积完的各特征图都做非线性化操作后再求和为一个图,so就有所谓pooling和flatten是其特例了。后文的实验还远算不上效果显著,甚至在我看来还没做完[挖鼻]~此文就随便看看得了~我这还没吐槽: 图像文本等不应该是“非结构化数据”嘛?[哼]
Taming VAEs
征服VAE——用约束优化训练VAE的高效方法
Adversarial Attacks and Defences: A Survey
一篇印度人写的对抗性防御的综述paper。
Over-Optimization of Academic Publishing Metrics: Observing Goodhart's Law in Action
爱可可:学术指标的过拟合游戏——古德哈特定律:“当一项指标成为目标时,它就不再是好的衡量标准。” 作者名单长、论文短、出版物数量激增、自引用和冗长参考文献列表,使得基于引用的指标越来越显现出局限性,是时候重新思考如何衡量学术成功了。
On the loss landscape of a class of deep neural networks with no bad local valleys
文章声称的全局最小训练,事实上主要基于一个比较特殊的人工神经网络的结构,用了各种连接到 output 的 skip connection,还有几个额外的assumptions 作为理论保证。
Learning Confidence for Out-of-Distribution Detection in Neural Networks
此文对我来说,值得好好看一看~
关键在于最后一层处,并行的多安排了一层表示学习confidence 的输出层。不过,总觉得这种操作很片面,有点以偏概全~
An analytic theory of generalization dynamics and transfer learning in deep linear networks
这是一篇谈论泛化error和Transfer L.的理论 paper. 虽实验细节还没看懂, 但结论很意义:新提出一个解析的理论方法,发现网络最首要先学到并依赖的是tast structure(通过early-stoping)而不是网络size!这也就解释了为啥随机data比real data更容易被学习,似乎存在更好的non-GD优化策略.
关于 SNR 也有迁移实验,说可以从高 SNR 迁移到低 SNR。。。
Foundations of Sequence-to-Sequence Modeling for Time Series
利用序列到序列模型来做时序数据预测的理论研究 paper~
Opening the black box of deep learning
上海大学的这个文有水文的倾向,没有提出任何实际数学的理论构想,整体还是太过唯象,企图给出DL 的物理理论解释。。。~ 扫了一眼,论点论证都比较牵强 ~
On the Spectral Bias of Deep Neural Networks
就是这么一句话:“we study deep networks using Fourier analysis.” 让我立马收藏此文,好好读读看!
Paper Summary
Troubling Trends in Machine Learning Scholarship
写 paper 如何做到心中有数~!
专门对 ML 圈里的写 paper 乱象罗列了一通,自己写 ML paper 必看!来个 Paper Summary 吧~
The GAN Landscape: Losses, Architectures, Regularization, and Normalization
看到 Goodfellow 亲自转推了此文~~
很重要的 review,准备个 Paper Summary
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
这文帅了~ 信息丰富 超多的图~ 让人眼前一亮~
探讨了18个模型的鲁棒性和准确率。结论很多,如模型构架是影响鲁棒性和准确率的重要因素(似乎是废话);相似模型构架基础上增加“深度”对鲁棒性的提升很微弱;有些模型(Vgg类)的表现出很强的对抗样本迁移性。。。
Grassmannian Learning: Embedding Geometry Awareness in Shallow and Deep Learning
就喜欢这些用微分流形讲机器学习的~!
应该写个 Paper Summary 表示尊敬~~~
Dropout is a special case of the stochastic delta rule: faster and more accurate deep learning
需要好好读读的~ 似乎在暗示我应该继续从信号处理的角度解读 MLP 和 CNN 的原理,应该是很有价值的!
好好写个 Paper Summary 为好~
Label-Noise Robust Generative Adversarial Networks
作者提出一种新的GAN类型,称为标签噪声GAN(rGAN),通过结合噪声过渡模型,即使标签有噪声,也可以学习干净的标签条件生成分布
Interpretable Convolutional Filters with SincNet
一篇值得我高度关注的 paper,来自 AI 三巨头之一 Yoshua Bengio!其背后的核心是将数字信号处理DSP中卷积的激励函数(滤波器)进行了重新设计,不仅会保留了卷积的特性(线性性+时间平移不变性)还在滤波器上添加待学习参数来学习合适的高低频截断位置。
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
The researchers found that defenses against adversarial examples commonly use obfuscated gradients, which create a false sense of security but, in fact, can be easily circumvented. The study describes three ways in which defenses obfuscate gradients and shows which techniques can circumvent the defenses. The findings can help organizations that use defenses relying on obfuscated gradients to fortify their current methods.
vanishing/exploding gradients are caused by extremely deep neural network evaluation.
There are number of clues that something is wrong with the gradient including:
Dataset Distillation
一篇知识蒸馏(Distillation)的新应用。Distillation 本身的应用目标是为了“模型压缩”从而知识转化实现小模型上的快速训练,而此文是对“数据压缩”以实现不错的蒸馏效果。
How Many Samples are Needed to Learn a Convolutional Neural Network?
Conclusion 里说:"Our paper only considered CNN with linear activation.“ 啥?linear activation?我不知道还有什么理由让我继续读下去[允悲]。。。另有 reddit 上对此文的讨论:http://t.cn/ELKbsjx
Smooth Loss Functions for Deep Top-k Classification
其实还是挺有创意的~ 通过推广 Multi-class SVM 的 loss,进一步构造光滑性 (无限可微),其可 reduce 回到交叉熵 loss,实验给出对噪声更好的鲁棒性,顺道讨论了如何降低“光滑性”带来的算法复杂度。
Stochastic Gradient Descent Optimizes Over-parameterized Deep ReLU Networks
这个哥们的文章和这个月内好几篇的立意基本一致(1811.03804/1811.03962/1811.04918) [抓狂] ,估计作者正写的时候,内心是崩溃的~[笑cry] 赶快强调自己有着不同的 assumption~
Rethinking floating point for deep learning
【网络的压缩加速问题】
Facebook人工智能研究院的Jeff Johnson改进了一种新颖的浮点数表示法(posit),使其更加适用于神经网络的训练和推理,并在FPGA上进行了对比实验。和IEEE-754浮点数标准相比,本论文基于改进的浮点数系统,可以实现低bit神经网络训练和高效推理,不再需要后续的量化压缩过程就可以部署在嵌入式等资源受限终端。该论文提出的方法区别于神经网络模型的剪枝、量化等常规思路,直接从浮点数表示这个更加基本、底层的角度尝试解决模型的压缩加速问题,是一个很新颖的方式,且效果不错,值得深入研究。除了论文,作者还给出了代码实现和博客文章,帮助理解。
Focal Loss for Dense Object Detection
【Best Student Paper Award at ICCV 2017】
何神在此文章中提出了 RetinaNet !
Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection
此文提出的 Retina U-Net 是结合了何神提出的 RetinaNet 的思想和已广泛得到应用的 U-Net 结构,用以考虑 supervision + segmentation 的问题。
Rethinking ImageNet Pre-training
ImageNet预训练的反思——ImageNet预训练可在训练早起加速收敛,但未必能提供正则化或提高最终目标任务准确性
何神的新paper!欲最快速通晓文章的 insights,请直接阅读文章的 discussions 部分即可!
A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data
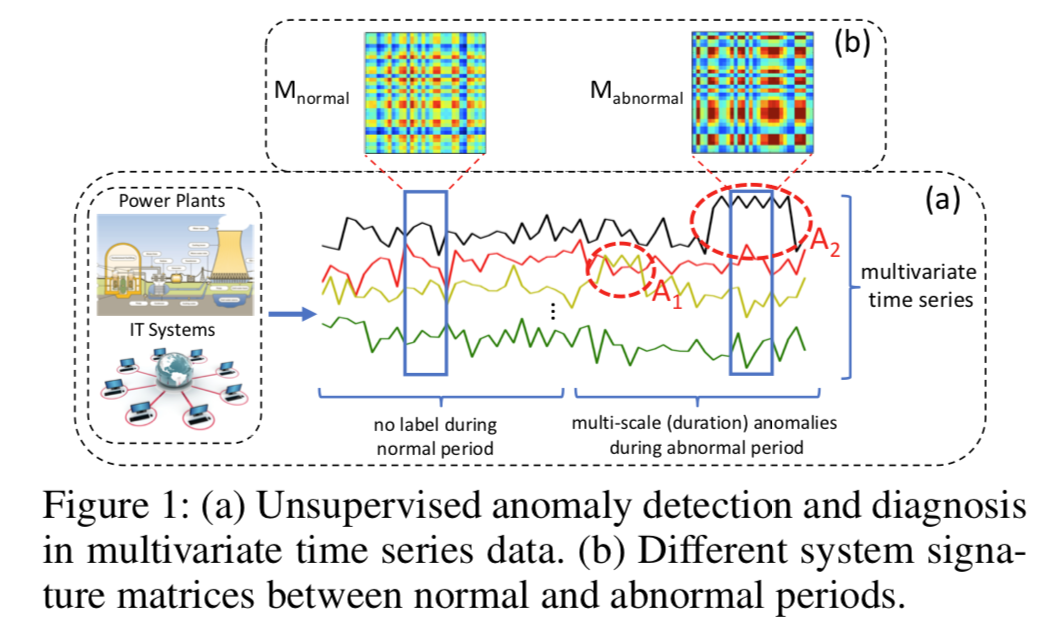
虽然数据特点为多变量时序信号+噪声少还频率低,不过作者提出的 Multi-Scale Convolutional Recurrent Encoder-Decoder (MSCRED) 网络很有趣,可见基于注意力机制的 ConvLSTM 在模式识别上是大为有用的!
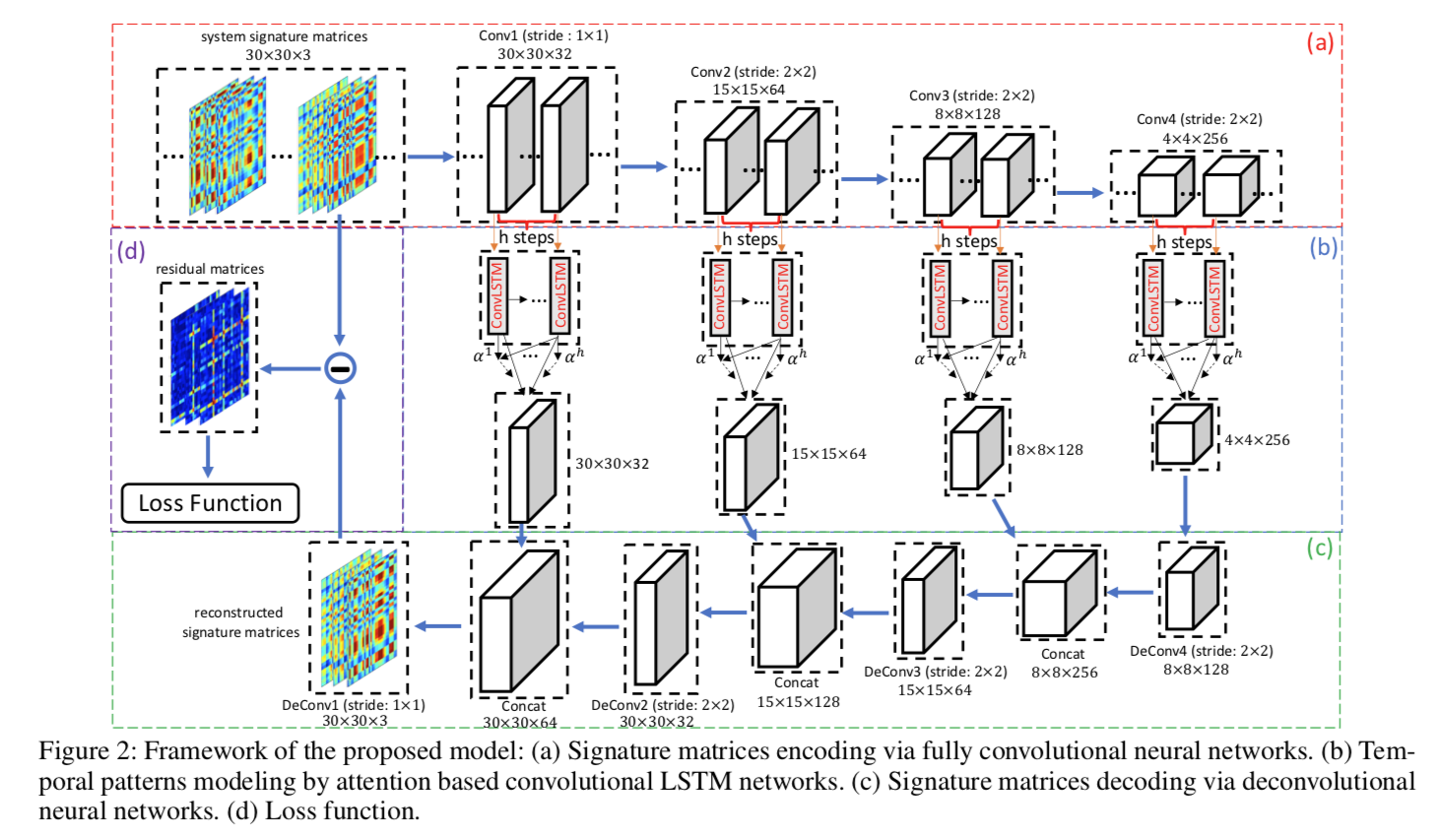
此外paper里的数学表述和实验讨论也很值得参考学习,算是非常标准的基于新model的 paper 样板~
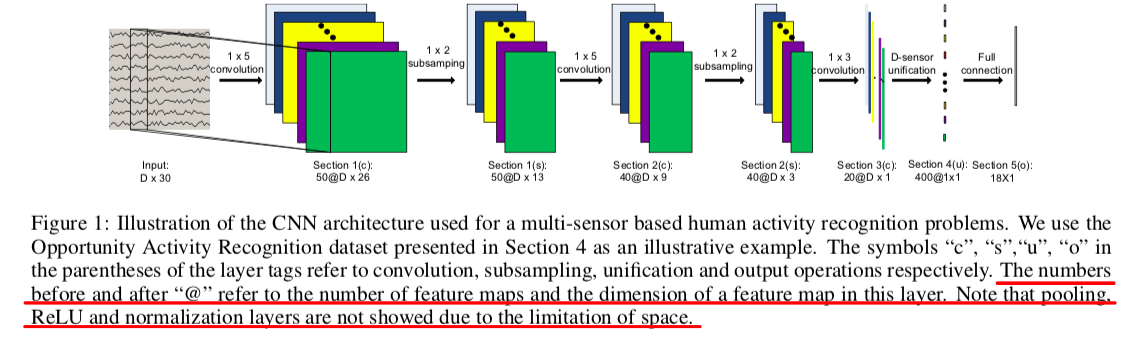
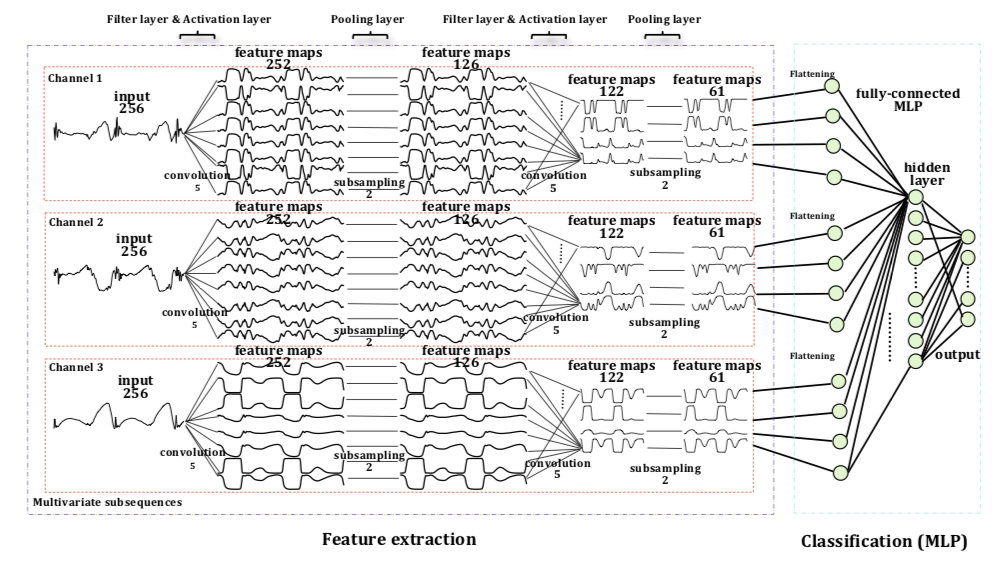
Deep Convolutional Neural Networks On Multichannel Time Series For Human Activity Recognition.
这个文章的研究对象是 HAR 问题。不过这里的多通道时序信号是排成 长 x 宽维度,模拟图片数据来解决的,并不是图像的多通道。不过最后的效果貌似很不错,远胜过 SVM,KNN,MV,以及 DBN(深度置信网络)。
文章对网络结构的英文描述还是值得借鉴的~
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Goodfellow 转载了此 BigGANs!
在 ImageNet 上最大范围尺度上训练 GAN 来研究类别的不稳定性。并据称Iception Scores 提升超过100,有应用“orghogonal 正则化”技术~
这也是2018年 Spectral Normalization 的作者!
另外,附录里还如此贴心的写了一页“错题本”。。。有心又有爱的作者![赞]
Paper Summary
Seamless Nudity Censorship: an Image-to-Image Translation Approach based on Adversarial Training
【用GAN给裸女自动“穿”上比基尼】
这么多人对这篇文章经验的实验效果表示赞叹和好奇~ 我也去瞻仰一番去。。。
Classification and Geometry of General Perceptual Manifolds
一篇Physical Review X 上的文章~ 读读看~
Paper Summary
A Performance Evaluation of Convolutional Neural Networks for Face Anti Spoofing
这篇 paper 中的写作风格和语言值得借鉴。细致的介绍了模型验证和对比的过程。对自己比较有启发~
Towards a universal neural network encoder for time series
数据任务是“时序序列的分类”,这是我感兴趣的问题。Universal 代表不需要额外设置和训练,从某数据集训练后,就可以拿到另一个新训练集类型去搞事情~ 另一个特点是用了 encoder 得到了低维不变的表示。
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
如果不是看到大神 Goodfellow 是作者之一,我就还以为这是一片水文呢~ 结论说DNN的随机初始化下,不管从可视化还是量化的角度上看都和训练好后的很像。猜测可能这些“解释”都是与低层的表示相关联导致,影射了模型本身存在很强的先验。
An Information-Theoretic View for Deep Learning
这是一篇关于DL理论的 paper,很有亮点!其给出了期望泛化误差范围内 CNN 层数的理论上界!“the deeper the better” 的神话终将是要设限的。。
Revisiting Small Batch Training for Deep Neural Networks
这篇文章简而言之就是mini-batch sizes取得尽可能小一些可能比较好。自己瞅了一眼正在写的 paper,这不禁让我小肝微微一颤,心想:还是下次再把 batch-size 取得小一点吧。。。[挖鼻]
A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay
一篇专门谈论超参和调参的 paper,现在版本更新到了 v2,还附带有 github 代码以帮助读者复现文章
Understanding Individual Neuron Importance Using Information Theory
前几天也发现了这个文,果断收藏下载了!
在信息论下,讨论互信息和分类效率等在网络内部的影响~
Understanding Convolutional Neural Network Training with Information Theory
要认真读的文,从信息论观点去理解 CNN。
Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks
这是一个三通道并列输入的时序信号模型。效果貌似不错,还针对不同模型算法的预测时间在不同训练规模数据上的模型表现做了对比,
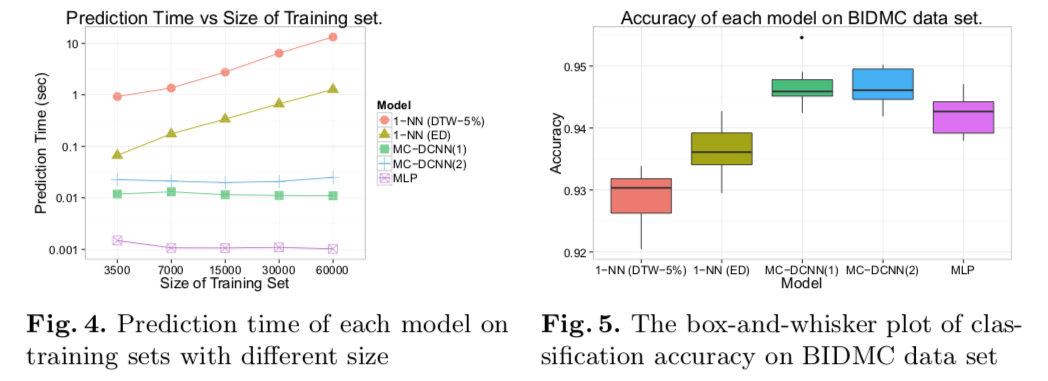
另外文章的模型图示也很有启发性。
Generating Natural Adversarial Examples
讨论对抗样本生成的~
Language GANs Falling Short
此文的一个 Paper Summary 写的特别棒!
This paper’s high-level goal is to evaluate how well GAN-type structures for generating text are performing, compared to more traditional maximum likelihood methods. In the process, it zooms into the ways that the current set of metrics for comparing text generation fail to give a well-rounded picture of how models are performing.
In the old paradigm, of maximum likelihood estimation, models were both trained and evaluated on a maximizing the likelihood of each word, given the prior words in a sequence. That is, models were good when they assigned high probability to true tokens, conditioned on past tokens. However, GANs work in a fundamentally new framework, in that they aren’t trained to increase the likelihood of the next (ground truth) word in a sequence, but to generate a word that will make a discriminator more likely to see the sentence as realistic. Since GANs don’t directly model the probability of token t, given prior tokens, you can’t evaluate them using this maximum likelihood framework.
This paper surveys a range of prior work that has evaluated GANs and MLE models on two broad categories of metrics, occasionally showing GANs to perform better on one or the other, but not really giving a way to trade off between the two.
The first type of metric, shorthanded as “quality”, measures how aligned the generated text is with some reference corpus of text: to what extent your generated text seems to “come from the same distribution” as the original. BLEU, a heuristic frequently used in translation, and also leveraged here, measures how frequently certain sets of n-grams occur in the reference text, relative to the generated text. N typically goes up to 4, and so in addition to comparing the distributions of single tokens in the reference and generated, BLEU also compares shared bigrams, trigrams, and quadgrams (?) to measure more precise similarity of text.
The second metric, shorthanded as “diversity” measures how different generated sentences are from one another. If you want to design a model to generate text, you presumably want it to be able to generate a diverse range of text - in probability terms, you want to fully sample from the distribution, rather than just taking the expected or mean value. Linguistically, this would be show up as a generator that just generates the same sentence over and over again. This sentence can be highly representative of the original text, but lacks diversity. One metric used for this is the same kind of BLEU score, but for each generated sentence against a corpus of prior generated sentences, and, here, the goal is for the overlap to be as low as possible
The trouble with these two metrics is that, in their raw state, they’re pretty incommensurable, and hard to trade off against one another.
更多需要阅读 Paper Summary 了。。。。
Generalization Error in Deep Learning
一篇谈深度学习模型泛化能力的 review paper~ 不错。。。就是很理论。。很泛泛。。。
Stochastic Adaptive Neural Architecture Search for Keyword Spotting
一篇讲 identifying keywords in a real-time audio stream 的 paper。这和引力波探测中的数据处理很接近哦~!此文提出 end-end 的“随机自适应神经构架搜寻” (SANAS) 实现高效准确的训练效果。这显然对 real-time 特点的类型数据应用带来启发。FYI:人家源码还开放了。。。
WaveGlow: A Flow-based Generative Network for Speech Synthesis
一篇来自 NVIDIA 的小文。提出的实时生成网络 WaveGlow 结合了 Glow 和 WaveNet 的特点,实现了更快速高效准确的语音合成。
Why scatter plots suggest causality, and what we can do about it
看了半天我真是不明白,转了45度再把图捏成方形的,就可以写篇 paper 宣传了?。。。[哼]
Human activity recognition based on time series analysis using U-Net
看了半天并没有感觉到太大的心意~ 无非主要是和 sliding window 方法在做对比。但效果肯定更好啦~ 毕竟 label 用的是 pixel-level 了啊,还用的是 U-net,结果毫不奇怪吧~ 在我看来,主要功劳在于数据的 labeling 吧….
Don't Use Large Mini-Batches, Use Local SGD
最近(2018/8)在听数学与系统科学的非凸最优化进展时候,李博士就讲过:现在其实不太欣赏变 learning rate 了,反而逐步从 SGD 到 MGD 再到 GD 的方式,提高 batch-size 会有更好的优化效果!
Deep learning for time series classification: a review
这个文与我的课题貌似相当相关!
准备好好写一个 Paper Summary 为好~
Are adversarial examples inevitable?
从结论部分来看,分析了“问题”成因,“问题”分类,“问题”特性,“问题”本质,可谓“问题”之不可避免而任重而道远,就说没提“问题”的解决办法。。。
现在关于对抗性的 paper 都要不可避免的谨慎对待啊~
Accelerating Natural Gradient with Higher-Order Invariance
每次看到研究梯度优化理论的 paper,都感觉到无比的神奇!厉害到爆表。。。。
ClusterGAN : Latent Space Clustering in Generative Adversarial Networks
貌似结果效果很惊艳<del>~</del>~!
用 GAN 做聚类的!
Identifying Generalization Properties in Neural Networks
按作者说法,证明了模型泛化能力确实与 Hessian矩阵相关,还提出了一个新 metric 来量化泛化能力。有趣的是(下方)的那一幅图,可以明显说明较平坦的局部最小对应于更好的泛化能力~~
来自 NATURE.AI 的 summary 评论:
This paper discusses the mathematical factors that are attributed to a deep network's generalisation ability. We have written a 2-minute summary that breakdowns the key mathematical framework that underlies this paper.
NEMGAN: Noise Engineered Mode-matching GAN
一个新 GAN,特点是 fully unsupervised。不仅可以做条件生成,还可以做聚类。
Efficient Identification of Approximate Best Configuration of Training in Large Datasets
这篇有微软和阿里参与的 paper,说白了就是提出了一个 ABC (approximate best configuration) 算法,一种自动化调参预判逻辑,实现了成倍的训练加速还基本不失准确率。显然这对玩 AutoML 类的商家是很有用的,而且算法还木有开源出来。。
hep-th
事实证明,有些领域的物理研究是很爱大搞特搞各种“model”的。。。。
Forward-Backward Stochastic Neural Networks: Deep Learning of High-dimensional Partial Differential Equations
惊艳到了~~ 又一篇关于求解偏微分方程的~ 拿来好好读读
Paper Summary
Deep Learning in Neural Networks: An Overview
Learning From Positive and Unlabeled Data: A Survey
一篇关于无标签正样本学习(PU Learning)的综述。自己应该好好读读,在现实情况下,这种类别很多很重要。。。
Explaining Deep Learning Models - A Bayesian Non-parametric Approach
无疑,讨论模型可解释性的 paper 总是让人充满好奇的。 文中说前人据网络的 output 形成了两种解释思路:whitebox/blackbox explanation。此文提出了新black-box方法(general sensitivity level of a target model to specific input dimensions) 通过建立 DMM-MEN。
Deep Learning for Time-Series Analysis
一个比较简洁的关于时序序列的 DL 应用的综述文章。
其中也有谈论时序序列的分类问题。
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
此文提供了一个和 t-sne 非常类似的降维可视化算法。效果相当不错!也开源了算法代码。
按照作者的说法,UMAP 比 T-SNE 算法更好的优点有二:更快!更准!
Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining
单图去雨(PyTorch)!
乖乖准备 Paper Summary 吧!
Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers
全篇的数学理论推导,意在回答2/3层过参的网络可以足够充分地学习和有良好的泛化表现,即使在简单的优化策略(类SGD)等假定下。(FYI: 文章可谓行云流水,直截了当,标准规范,阅读有种赏心悦目的感觉~)
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
This paper shows that local explanations for DNNs with random-initialized weights are qualitatively and quantitatively similar to explanations produced by DNNs with learned weights.
The paper is clear, the problem is well stated and the method is sound.
The impact of the findings in this paper is unclear. Perhaps the most important point made in the paper is the importance of the architecture over fine-tuning of the weights for explanation tasks (and more in general).
其实 goodfellow 这文章篇幅很短,可视化图像的效果是很棒的!
Sanity Checks for Saliency Maps
专门探讨对各种 Saliency methods (显著图方法)的。
Goodfellow 署名的该文章内含有大量很棒的可视化效果。
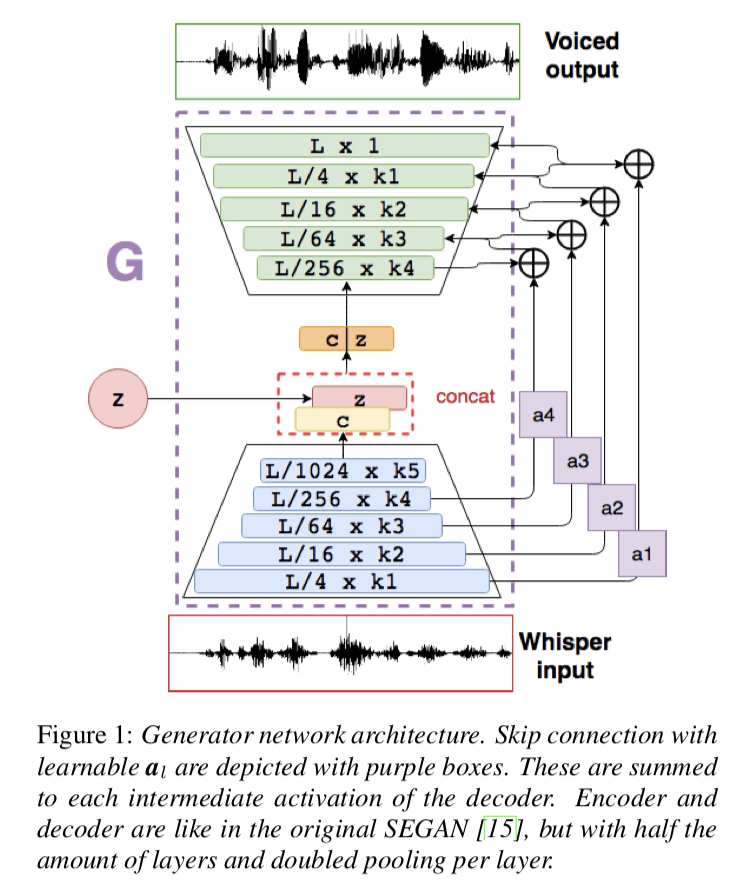
Whispered-to-voiced Alaryngeal Speech Conversion with Generative Adversarial Networks
这是一篇用 GAN 来做 Voiced Speech Restoration 的,并且使用了作者自己提出的 speech enhancement using GANs (SEGAN) 。
于我而言,亮点有二:
Do Deep Generative Models Know What They Don't Know?
DeepMind 这篇文章算是一股清流,告诉我们千万不要完全迷信生成模型的结果。这里有一个不错的paper summary:
Generative models might not be as robust as we’ve come to believe.
The DeepMind paper concludes that researchers should be aware of deep generative models’ vulnerabilities and that they will require further improvements in this regard.
“In turn, we must then temper the enthusiasm with which we preach the benefits of generative models until their sensitivity to out-of-distribution inputs is better understood.”
Deep Learning with the Random Neural Network and its Applications
此文综述了最近 Random Neural Network (RNN) 模型的应用,文末的 summary 和 future work,可以看到 RNN 已经在很多方面有着不错的表现,但是还有更多的问题需要进一步探讨和研究。
The Frontiers of Fairness in Machine Learning
这个 review 在一定程度上指出了当前前沿 ML 研究的趋势和局限性,重要的是它为未来应当着力发展和探究的课题给出了几个方向。
Toward Convolutional Blind Denoising of Real Photographs
真实照片上的盲去噪!印象中使用的 GAN~
乖乖准确 Paper Summary!
Neural Ordinary Differential Equations
总的来说,没看太懂。此文似乎并不是为了求解 ODE或者 PDE,也是对网络各层用隐藏层的导数来制作 ODE solver。

效果貌似非常 smooth:
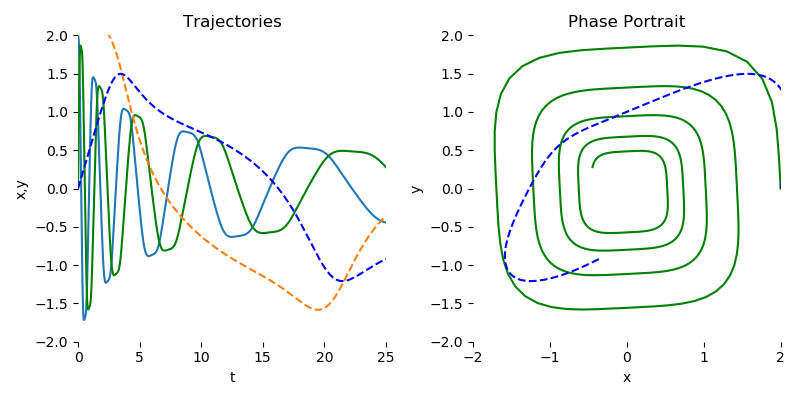
Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift
该文做的实验是探索对数据集进行 shifts (某种可控的扰动) 后的模型表现,提出了classifier-based的方法/pipeline 来观察和评价:
这对于我的引力波数据研究来说,可以借鉴其数据的 shift 方法以及评价机制 (two-sample tests)。
Applications of Deep Reinforcement Learning in Communications and Networking: A Survey
如题。
review 一篇。。。。
Generative adversarial networks and adversarial methods in biomedical image analysis
这是一篇很有 review 气质的 paper,对GAN 和对抗方法等做了介绍(在生物医药领域中),也谈论了这些技术应用的优势和劣势。
对我来说,这是一篇很适合快速入门GAN应用的 paper。
Model Selection Techniques -- An Overview
一篇关于模型选择的综述文章。涉及信号处理,图像处理等等多方面数据信息的处理。发表在信号处理的期刊杂志上。
文中关于模型选择的大概念方向,和数学表示,是值得好好阅读的。
Backprop Evolution
这似乎是说反向传播的算法,在函数结构本身上,就还有很大的优化空间。作者在一些初等函数和常见矩阵操作基础上探索了一些操作搭配,发现效能轻易的就优于传统的反向传播算法。
不禁启发:我们为什么不能也用网络去拟合优化梯度更新函数呢?
A Survey on Deep Transfer Learning
不仅综述了迁移学习的现状,也对其进行了分类。同时,还给出了“深度迁移”的概念,强调了待迁移的两个学习任务之间的非线性关系。其实这也很自然,我们本来对线性的“相似”学习任务迁移就兴趣一般,也没多大研究意义。。。。
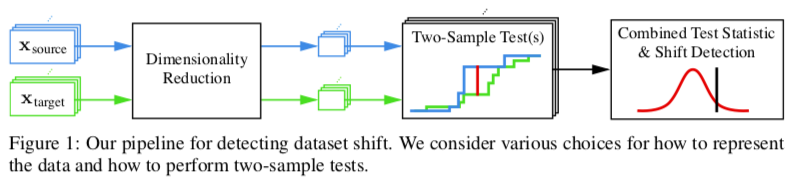
Improving Generalization for Abstract Reasoning Tasks Using Disentangled Feature Representations
非常不错的 CNN 的网络结构图:
可以看到清晰的数据处理方式,还有图形明暗色彩的变化。
Defensive Dropout for Hardening Deep Neural Networks under Adversarial Attacks
貌似就是利用 dropout 来防御对抗样本~ 然而前两天才看了 Goodfellow 在 cs231n 2017 Spring 上的报告提到说,一切用传统正则化技巧企图防御的手段都是失效的~当然包括 dropout~ 比如可以看看 Nicholas Carlini 的文章。
贴上Goodfellow讲座的 Slice 和笔记:https://iphysresearch.github.io/cs231n/cs231n_Guest%20Lecture.%20Adversarial%20Examples%20and%20Adversarial%20Training.html
Using Machine Learning to Predict the Evolution of Physics Research
内涵各种物理期刊。。。可视化挺不错。。。
DeepSphere: Efficient spherical Convolutional Neural Network with HEALPix sampling for cosmological applications
对具有方位信息的数据做卷积,实现了所谓的 3D 卷积,这对天文上的微博背景辐射(CMB)数据的应用很有意义。
End-to-end music source separation: is it possible in the waveform domain?
讨论的是 Music source separation 问题。
作者认为前人基于spectrogram的输入数据都忽略了相位信息,所以提出了直接waveform-based的模型得到了明显更好的效果。
Gradient Descent Finds Global Minima of Deep Neural Networks
全篇的数学理论证明:深度过参网络可以训练到0。(仅 train loss,非 test loss)+(GD,非 SGD)
Analyzing biological and artificial neural networks: challenges with opportunities for synergy?
Deepmind 的这篇文有点水,只能归为 review 了。涉及了很多数据分析的方法和 DNN 的概念,当然也未跑题的谈论了生物/人工神经网络之间的爱恨纠葛。
Synergy 这个词特别有趣,译为:协同增效作用。
Toward an AI Physicist for Unsupervised Learning
提出了 AI Physicist 这样的概念(paradigm),这也算是我的某种终极目标吧。
只能说是有趣吧,对理论的归纳和理解也比较有趣。
How deep is deep enough? - Optimizing deep neural network architecture
精心构造了一个度量:generalized discrimination value(GDV),实现了对网络各层中对不同输入类别的量化评价。这个评价定义还关于输入数据有平移不变性和缩放不变性 ,同时,并不依赖特征图的数目,也不依赖于每层中神经元的数目和排序。
A Convergence Theory for Deep Learning via Over-Parameterization
又一个全篇的数学理论证明,但是没找到 conclusion 到底是啥,唯一接近的是 remark 的信息,但内容也都并不惊奇。不过倒是一个不错的材料,若作为熟悉DNN背后的数学描述的话。
Unifying Probabilistic Models for Time-Frequency Analysis
文章涉及好些自己还没搞懂的概念和方法:
文中的 review 给的是很不错的~
Training neural audio classifiers with few data
这是一个比较初步的简单实验。
图像结论其实并不意外:数据量越多当然表现越好;迁移学习在极小量数据上表现良好;Prototypical 模型可能因结构的特异性会表现出一定程度上的优势;数据量越小,过拟合问题越严重。。。
Bias and Generalization in Deep Generative Models: An Empirical Study
有些没看太懂~
不过此文通过对训练集的实验控制是很值得我学习和借鉴的!
The relativistic discriminator: a key element missing from standard GAN
本文基于“图灵测试”思想提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。在笔者看来,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。
来自 Paperweekly 的论文解读:http://t.cn/EZg9Gj1
Approximate Fisher Information Matrix to Characterise the Training of Deep Neural Networks
深度神经网络训练(收敛/泛化性能)的近似Fisher信息矩阵表征,可自动优化mini-batch size/learning rate
挺有趣的 paper,提出了从 Fisher 矩阵抽象出新的量用来衡量训练过程中的模型表现,来优化mini-batch sizes and learning rates | 另外 paper 中的figure画的很好看 | 作者认为逐步增加batch sizes的传统理解只是partially true,存在逐步递减该 size 来提高 model 收敛和泛化能力的可能。
Discriminator Rejection Sampling
判别器舍选抽样(DRS)——用GAN判别器对训练的GAN生成器进行拒绝采样
作者之一 Goodfellow 这样发推评价此文:“The discriminator often knows something about the data distribution that the generator didn't manage to capture. By using rejection sampling, it's possible to knock out a lot of bad samples.”
A Tale of Three Probabilistic Families: Discriminative, Descriptive and Generative Models
这个综述的角度比较有趣,既易读也很有启发性,将模型分为三大类,它们之间的关系总结为下图:
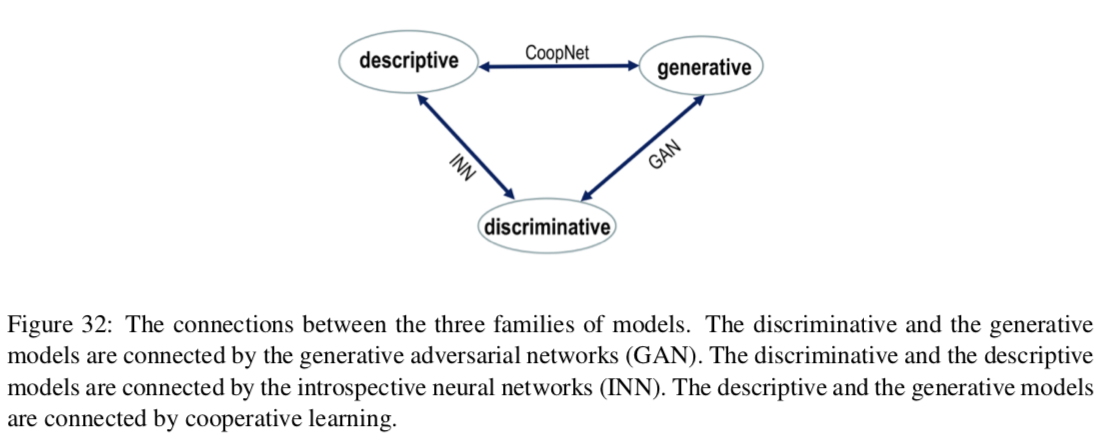
当然并不是所有模型都被囊括在其中,比如玻尔兹曼机等~
A Survey on Deep Learning: Algorithms, Techniques, and Applications
【Review】【文章摘要】
随着深度学习逐渐成为机器学习领域的引领技术,机器学习领域正在见证其黄金时代。深度学习使用多个层来表示数据的抽象,以构建计算模型。一些关键的使能深度学习算法,如生成对抗网络,卷积神经网络和模型迁移,彻底改变了我们对信息处理的方法。然而,在这个极其快节奏的领域背后存在着一种理解,因为它以前从未以多视角展示过。缺乏核心理解使得这些强大的方法成为黑盒机器,从根本上抑制了深度学习发展。此外,深度学习一再被视为机器学习中所有绊脚石的银弹,这远非事实。本文全面回顾了视觉,音频和文本处理方面的历史和最新技术方法;社交网络分析;和自然语言处理,然后深入分析深度学习应用中的突破性进展。还开展了审查深度学习所面临的问题,如无监督学习,黑盒模型和在线学习,并说明如何将这些挑战转化为多产的未来研究途径。
Quaternion Convolutional Neural Networks
【卷积神经网络】Quaternion Convolutional Neural Networks
(ECCV 2018) 本文是上海交大和杜克大学发表于ECCV 2018的工作,论文提出了一种基于Quaternion的CNN——QCNN。QCNN将图像的RGB通道转换到Quaternion数域进行讨论,并由此给出了quaternion convolution layers,quaternion fully-connected layers等结构。文章从"微观"上进行改进,提出了新的卷积神经网络,在high-level vision task和low-level vision task都取得了不错的效果。
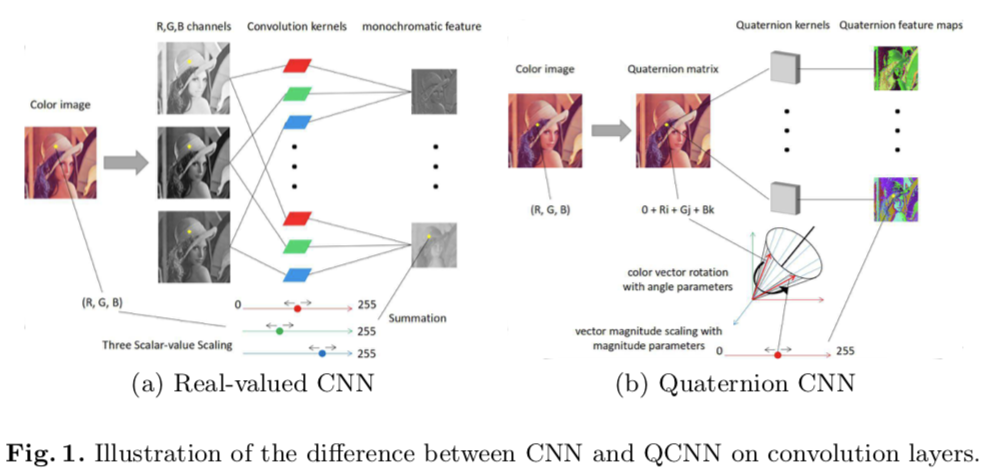
角度比较新颖。说白了就是把传统的RGB三个输入特征图用四元数在像素级别上混合表示。于是结果也就易被理解了,相当于把输入前3个独立特征图的假定换成了输入信息交叉后的单一特征图的假定~
Refacing: reconstructing anonymized facial features using GANs
一篇医疗领域的核磁共振图像生成的 paper。对我来说唯一值得 mark 的是它用的是 correlation coefficients and structural similarity indices (SSIMs) 来 evaluate CycleGAN 的效果的。
<br>
<br>
annote
A annotation like this!
highlight
You can highlight like this!
Hexo Blog 搭建笔记
第三次更新
第二次更新
第一次更新~
Python
来聊聊 Python 啊~
欢迎来扯淡啊!