[[Erwin Blom p]] on how AI tools lower the Coasean floor for books.
67 Matching Annotations
- May 2026
-
fmthandpickedai.substack.com fmthandpickedai.substack.com
- Feb 2026
-
felipezamana.com felipezamana.com
-
You know, the e-books basically were a way for somebody who wanted to read my content in a book format, with a flow to it and things like that.
his ebooks as blogposts put together in a flow.
-
The e-books that I published, for example, are years’ worth of blog posts, where I take the best ones, synthesize them, and put them together into a better product. The first book that I published was after 10 years of blogging. I took all these 10 years’ worth of content and launched the Perpetual Beta series. Then, I’ve added several to that. The last e-book was launched in 2024, and that was more of a questioning of what the heck is going on, because that was where AI was starting to rear its ugly head and everything.
Harold used his blog as source for creating ebooks on diff topics. #idea Vgl jaarboeken v blogarchief
Tags
Annotators
URL
-
- Dec 2025
-
en.wikipedia.org en.wikipedia.org
-
LCP is DRM standard (.lcpl files), a JSON/XML extension and ISO standard. https://readium.org/lcp-specs/
Came across it in Norwegian e-book store. This page suggests it is in use elsewhere too. Seems to be a format used for lending books too.
Elsewhere I find that Readium 1.0 can be de-drmd easily but 2.5 is more secure from that.
Tags
Annotators
URL
-
-
www.epubor.com www.epubor.com
-
you can download the .lcpl within the Calibre directly.
Calibre works directly with .lcpl LCP drm
-
All you need to open (or decrypt) LCP eBooks is the account passphrase given to you by the eBook provider - the very same passphrase you'd have to enter into your eBook reader device (once) to read LCP-encrypted books. Sometime, the passphrase can be the passwords.
.lcpl LCP drmd books have a passphrase. Typically this will be the one for your account from the platform where you bought the book
Tags
Annotators
URL
-
-
calibre-ebook.com calibre-ebook.com
-
Support for jumping to and displaying paper edition page numbers [7.17] If an e-book contains embedded information about the pages from the paper edition of the book, the calibre E-book viewer can now jump to a page number via the Go to button in the viewer controls.
Calibre, if it can detect it, can use paper edition page numbers. It's #openvraag how I want to deal with location numbers in ebooks as ref.
Tags
Annotators
URL
-
- Sep 2025
-
Local file Local file
-
With an eBook, however, you are not a first-class commercialcitizen. Instead, you have only purchased tenuous rights withinsomeone else’s company store
ebooks versus physical books
-
- Jan 2025
-
pluralistic.net pluralistic.net
-
[[Cory Doctorow]] explaining the issue with Amazon in terms of racketeering and market dominance. Am in process of writing a post on moving my reading out of Amazon [[Amazon aankopen vermijden]]
-
- Aug 2024
-
www.msnbc.com www.msnbc.com
-
Chris Hayes speaks with Internet Archive founder Brewster Kahle and Library Futures co-founder Kyle Courtney about why megapublishers are suing to redefine e-books. as legally different from paper books.
Could the future of libraries as we’ve known them be completely different? Our guests this week say so. Megapublishers are suing the Internet Archive, perhaps best known for its Wayback Machine, to redefine e-books as legally different from paper books. A difference in how they are classified would mean sweeping changes for the way libraries operate. Brewster Kahle is a digital librarian at the Internet Archive. Kyle Courtney is a lawyer, librarian, director of copyright and information policy for Harvard Library. He’s the co-founder of Library Futures, which aims to empower the digital future for America’s libraries. They join to discuss what’s animating the lawsuit, information as a public good and the consequences should the publishers ultimately prevail.
July 9, 2024
-
- Feb 2024
-
www.ebooksforus.com www.ebooksforus.com
- Jan 2024
-
www.youtube.com www.youtube.com
-
2023-12-21 BookBridge Talk, 2023. https://www.youtube.com/watch?v=3M-nfWI93nY. Andy Matuschak and Derrek Chow
-
-
en.wikipedia.org en.wikipedia.org
-
Amazon's .kfx ebook format and predecessors are extensions of html5, css and backwards compatible with mobipocket (the 2000 French proprietary format that Kindle bought and used).
Proprietary format.
Tags
Annotators
URL
-
-
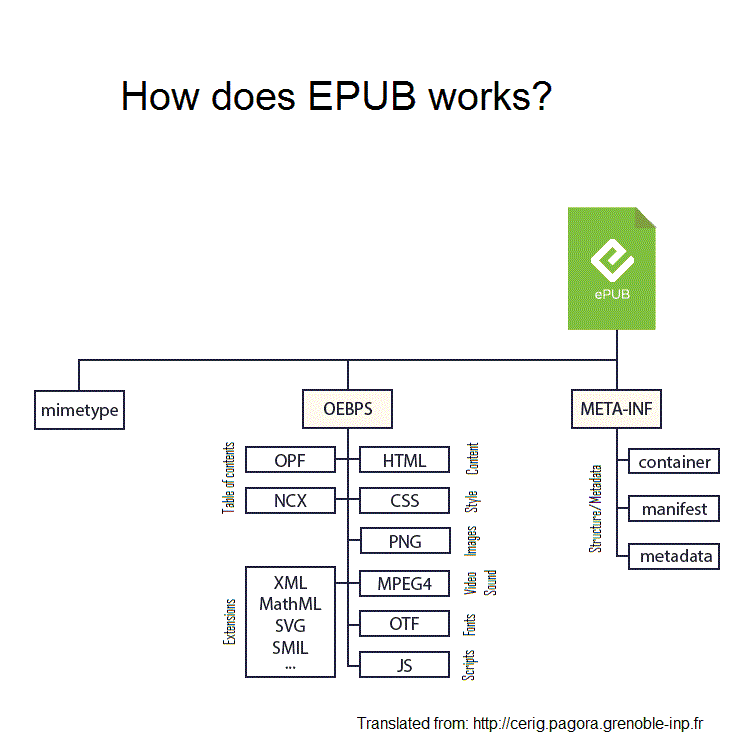
www.w3.org www.w3.orgEPUB 3.31
-
The W3C standard for Epub ebooks. Nav [[How Standard Ebooks serves millions of requests per month with a 2GB VPS; or, a paean to the classic web - Alex Cabal]]
-
-
alexcabal.com alexcabal.com
-
first published #2022/02/11
Apart from the framing of this post more as an apology than as a show of strength of keeping things simple and sturdy, interesting nuggets: Epub ebooks are xhtml and static so rapidly served without the need for a fancy framework or even a database. Flat texts are small, and their current collection fits in RAM entirely. PHP is used without frills. All in all a strong call to keep things simple, and to embrace my current use of php for local tools too: it's very fast.
Also makes me wonder: #openvraag what can one do with Epub books outside an ebook reader, in terms of excerpting e.g. and ripping things out for re-use elsewhere. I've got loads of them on my laptop
-
- Mar 2023
-
standardebooks.org standardebooks.org
- Dec 2022
-
standardebooks.org standardebooks.org
-
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>awarm.space</span> in Making a modern ebook with Standard Ebooks (<time class='dt-published'>08/02/2021 12:08:19</time>)</cite></small>
-
- Nov 2022
-
www.gutenberg.org www.gutenberg.org
-
Project Gutenberg is a library of over 60,000 free eBooks
目前有6万多本书籍可供下载,大多为版权过期而进入公有领域的书籍。
-
- Oct 2022
-
libreture.com libreture.com
Tags
Annotators
URL
-
-
libreture.com libreture.com
Tags
Annotators
URL
-
-
link.springer.com link.springer.com
-
Sisto, M.C. Publishing and Library E-Lending: An Analysis of the Decade Before Covid-19. Pub Res Q 38, 405–422 (2022). https://doi.org/10.1007/s12109-022-09880-7
-
- May 2022
-
sl.wordpress.org sl.wordpress.org
-
The Library Bookshelves plugin allows you to curate virtual bookshelves just like you would a shelf around a theme in your library. Bookshelves are displayed as customizable Slick carousels, using cover art from, and links to, your library catalog. The plugin creates a Bookshelves post type, shortcode, widget, and custom taxonomy.
-
-
sl.wordpress.org sl.wordpress.org
-
www.wordpresspluginfinder.com www.wordpresspluginfinder.com
-
The plugin convert content of your blog posts and pages to most popular e-book formats for readers – pdf, ePub, mobi and fb2, using php-librasries: mPDF; PHPePub; MOBIClass; bgFB2. Plugin displays a icons form for download converted files before and/or after content on your blog pages. You can create OPDS catalogue on your site with this plugin, if you enable the option. OPDS catalog support the file-types: 'epub', 'fb2', 'pdf', 'mobi', 'zip', 'rtf', 'doc', 'docx', 'htm', 'html', 'txt', 'djvu', 'mp3', 'm4a', 'm4b'.
Q.: How can users access the OPDS catalogue?
A.: OPDS catalogue URL
http://yoursite.com/feed/opds.
-
-
specs.opds.io specs.opds.io
-
www.thoughtco.com www.thoughtco.com
-
thecodebarbarian.com thecodebarbarian.com
-
With some extra work, you can download the entire text version of Moby-Dick from Project Gutenberg using Axios.
```js const axios = require('axios'); const epub = require('epub-gen');
axios.get('http://www.gutenberg.org/files/2701/2701-0.txt'). then(res => res.data). then(text => { text = text.slice(text.indexOf('EXTRACTS.')); text = text.slice(text.indexOf('CHAPTER 1.'));
const lines = text.split('\r\n'); const content = []; for (let i = 0; i < lines.length; ++i) { const line = lines[i]; if (line.startsWith('CHAPTER ')) { if (content.length) { content[content.length - 1].data = content[content.length - 1].data.join('\n'); } content.push({ title: line, data: ['<h2>' + line + '</h2>'] }); } else if (line.trim() === '') { if (content[content.length - 1].data.length > 1) { content[content.length - 1].data.push('</p>'); } content[content.length - 1].data.push('<p>'); } else { content[content.length - 1].data.push(line); } } const options = { title: 'Moby-Dick', author: 'Herman Melville', output: './moby-dick.epub', content }; return new epub(options).promise;}). then(() => console.log('Done')); ```
-
-
www.edrlab.org www.edrlab.org
Tags
Annotators
URL
-
-
www.w3.org www.w3.orgEPUB 3.21
Tags
Annotators
URL
-
-
idpf.org idpf.org
-
This specification, Open Annotation in EPUB, defines a profile of the W3C Open Annotation specification [OpenAnnotation] for the creation, distribution and rendering of annotations for EPUB® Publications.
This appendix is informative
All examples use the same hypothetical publication of Alice in Wonderland, and are given in the collection structure with a single annotation.
-
Commentary Annotation on Publication with URI
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@id": "http://www.example.org/ebooks/A1B0D67E-2E81-4DF5/v2.epub", "@type": "dctypes:Text" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Commentary Annotation on Publication without Identifying URI
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Collection Metadata
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "dc:title": "Alice in Wonderland Annotations", "dc:publisher": "Example Organization", "dc:creator": "Anne O'Tater", "dcterms:modified": "2014-03-17T12:30:00Z", "dc:description": "Anne's collection of annotations on Alice in Wonderland", "dc:rights": [ { "@value": "Quelques droits en Français", "@language": "fr" }, { "@value": "Some Rights in English", "@language": "en" } ], "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Annotation with Ancillary Resources in the Zip
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland! <img src='/imgs/heart.jpg'/></div>" }, "motivatedBy": "oa:commenting" } ] } -
Styling of Selection
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "styledBy": { "@type": "oa:CssStyle", "format": "text/css", "chars": ".red { border: 1px solid red; }" }, "hasTarget": { "@type": "oa:SpecificResource", "hasSelector": { "@type": "oa:FragmentSelector", "value": "epubcfi(/6/4[chap01ref]!/4[body01]/10[para05]/3:10)" }, "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" }, "styleClass": "red" }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love this part of the text</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] }- Replying to an Annotation
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:B81AF8C4-B04A-4D3D-B1D3-23F7C02E56BB", "@type": "oa:Annotation", "motivatedBy": "oa:replying", "hasTarget": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<span xmlns='http://www.w3.org/1999/xhtml'>I agree!</span>" } } ] }
-
-
-
vaemendis.net vaemendis.net
-
The OPDS Page Streaming Extension (OPDS-PSE) is an unofficial extension of the Open Distribution Publication System. Its goal is to enrich the OPDS feed with information allowing the client to request a specific page of a document without having to download it completely. This extension was designed primarily for comic books, to allow reading them on connected devices without having to wait for the book to be completely downloaded.
Example :
- Namespace declaration in the feed element (in our example, we use the prefix
« pse »):
xml <feed xmlns="http://www.w3.org/2005/Atom" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:pse="http://vaemendis.net/opds-pse/ns" xmlns:opds="http://opds-spec.org/2010/catalog" xml:lang="en" xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/" >- Additional link in an entry to allow page by page access to the document :
xml <link rel="http://vaemendis.net/opds-pse/stream" type="image/jpeg" href="/opds-comics/stream/1217?page={pageNumber}&width={maxWidth}" pse:count="35" /> - Namespace declaration in the feed element (in our example, we use the prefix
Tags
Annotators
URL
-
-
sudonull.com sudonull.com
-
www.slideshare.net www.slideshare.net
-
gallica.bnf.fr gallica.bnf.fr
-
www.quietthyme.com www.quietthyme.com
-
-
www.goodreads.com www.goodreads.comAPI1
Tags
Annotators
URL
-
-
www.goodreads.com www.goodreads.com
-
-
www.liseuses.net www.liseuses.net
-
- Feedbooks : http://fr.feedbooks.com/catalog
- Atramenta : https://www.atramenta.net/opds/
- Gallica : https://gallica.bnf.fr/opds
- Ebooks Gratuits : https://www.ebooksgratuits.com/opds/
- Archive.org : http://bookserver.archive.org/catalog
- Projet Gutenberg : http://m.gutenberg.org/ebooks/?format=opds
- Framabookin : https://framabookin.org/
Tags
Annotators
URL
-
-
wiki.mobileread.com wiki.mobileread.com
Tags
Annotators
URL
-
-
www.digitalocean.com www.digitalocean.com
-
readium.org readium.org
Tags
Annotators
URL
-
-
drafts.opds.io drafts.opds.io
-
blog.ubiquitypress.com blog.ubiquitypress.com
-
example.com example.com
Tags
Annotators
URL
-
-
blog.feedbooks.com blog.feedbooks.com
- Mar 2021
-
www.inputmag.com www.inputmag.com
- Oct 2020
-
buttondown.email buttondown.email
-
But wait, there’s more. Much more. We generally encounter four different acquisition models (my thanks to Janet Morrow of our library for this outline): 1) outright purchase, just like a print book, easy peasy, generally costs a lot even though it’s just bits (we pay an average of over $40 per book this way), which gives us perpetual access with the least digital rights management (DRM) on the ebooks, which has an impact on sustainable access over time; 2) subscription access: you need to keep paying each year to get access, and the provider can pull titles on you at any time, plus you also get lots of DRM, but there’s a low cost per title (~$1 a book per year); 3) demand-driven/patron-driven acquisition: you don’t get the actual ebook, just a bibliographic record for your library’s online system, until someone chooses to download a book, or reads some chunk of it online, which then costs you, say ~$5; 4) evidence-based acquisitions, in which we pay a set cost for unlimited access to a set of titles for a year and then at the end of the year we can use our deposit to buy some of the titles (<$1/book/year for the set, and then ~$60/book for those we purchase).
Nice to see this laid out. I've never seen a general overview of how this system works for libraries.
I've always wondered what it cost my local public library to loan me an e-book whether I read it or not.
-
- Aug 2020
-
www.reddit.com www.reddit.com
-
Guide how to download ebooks via IRC
-
- Apr 2020
-
librivox.org librivox.org
-
About LibriVox LibriVox Objective To make all books in the public domain available, for free, in audio format on the internet. Our Fundamental Principles Librivox is a non-commercial, non-profit and ad-free project Librivox donates its recordings to the public domain Librivox is powered by volunteers Librivox maintains a loose and open structure Librivox welcomes all volunteers from across the globe, in all languages
Tags
Annotators
URL
-
-
www.gutenberg.org www.gutenberg.org
-
Project Gutenberg is a library of over 60,000 free eBooks. Choose among free epub and Kindle eBooks, download them or read them online. You will find the world's great literature here, with focus on older works for which U.S. copyright has expired. Thousands of volunteers digitized and diligently proofread the eBooks, for enjoyment and education.
Tags
Annotators
URL
-
- Oct 2019
-
futurepress.github.io futurepress.github.io
-
Epictetus wrote nothing; and all that we have under his name was written by an affectionate pupil, Arrian, afterwards the historian of Alexander the Great, who, as he tells us, took down in writing the philosopher’s discourses
As it happens, this annotation works through its proper URL) but, Hypothesis butchered the link. You need to turn the page once to see the highlight though.
-
- Nov 2018
-
digital.bmj.com digital.bmj.com
-
the ePublishing service of the National Documentation Centre
EKT is part of the HIRMEOS project to bring standards and common tools (including annotation) to ebooks--starting with 5 platforms in humanities and social sciences. More here.
-
- Sep 2017
-
hechingerreport.org hechingerreport.org
-
The studying strategy with “the greatest power,” she adds, involves deeply questioning the text — asking yourself if you agree with the author, and why or why not.
Etexts have an advantage in the annotation department in that they're not limited to the marginal space. Annotations can be as lengthy as they need to be. They can also be organized through tags, and thus easily searched. They can contain hyperlinks and be hyperlinked, tying texts together. I wonder how many people are taught, in any meaningful or systematic way, to use digital texts. And if they were, how would that change this dilemma.
-
- Jan 2016
-
anthonydilaura.wordpress.com anthonydilaura.wordpress.com
-
massive advances in Open Educational Resources
Some may be surprised to hear about OERs in a post about proprietary technology, especially since this was before iBooks Author allowed the creation of ePUB3 books.
-
-
manual.calibre-ebook.com manual.calibre-ebook.com
-
Set Semantics¶ This tool is used to set semantics in EPUB files. Semantics are simply, links in the OPF file that identify certain locations in the book as having special meaning. You can use them to identify the foreword, dedication, cover, table of contents, etc. Simply choose the type of semantic information you want to specify and then select the location in the book the link should point to. This tool can be accessed via Tools->Set semantics.
Though it’s described in such a simple way, there might be hidden power in adding these tags, especially when we bring eBooks to the Semantic Web. Though books are the prime example of a “Web of Documents”, they can also contribute to the “Web of Data”, if we enable them. It might take long, but it could happen.
-
-
www.talkingnewmedia.com www.talkingnewmedia.com
-
export books as apps
On top of the whole debate between native apps and the Open Web, there’s a debate between apps and books. We might not reach the “Write Once, Publish Everywhere” dream, but there’s something to be said about having building blocks which are easy to adapt to different contexts.
-
- Dec 2015
-
-
e-readers
Leaving the door open for eBooks? IDPF is part of the coalition after all and there are important connections with work done on ePUB3.
Tags
Annotators
URL
-
- Oct 2015
-
example.com example.com
-
that format had to be HTML or PDF
No ePub?
Tags
Annotators
URL
-
- Jul 2015
-
www.digitalbookworld.com www.digitalbookworld.com
-
ALA’s 2014 Digital Inclusion Survey also documents digital differences among states and an urban/rural divide.
statistics from this ALA special report
-
American Library Association: 90% of Libraries in U.S. Now Lend Ebooks
from DigitalBookWorld July 24, 2014
-
-
lj.libraryjournal.com lj.libraryjournal.com
-
OverDrive: Ebook Checkouts Up 33 Percent
by Matt Enis Jan 14, 2014
-
-
www.infodocket.com www.infodocket.com
-
Price, Gary. "OverDrive Releases 2014 Year-End Usage Statistics Including Most Popular eBooks and Audiobooks." Library Journal 8 Jan 2015. "From an OverDrive announcement" FIled by Gary Price.
-
-
company.overdrive.com company.overdrive.com
-
Bookmarking, note-taking
-
- Jun 2015
-
www.library.illinois.edu www.library.illinois.edu
-
Proprietary Platforms
Like what? OverDrive?
-