Bots can execute JavaScript, use real browser environments, and pass individual CAPTCHAs without raising suspicion.
令人惊讶的是:机器人可以执行JavaScript,使用真实的浏览器环境,并且通过个别CAPTCHA而不会引起怀疑。
Bots can execute JavaScript, use real browser environments, and pass individual CAPTCHAs without raising suspicion.
令人惊讶的是:机器人可以执行JavaScript,使用真实的浏览器环境,并且通过个别CAPTCHA而不会引起怀疑。
what we are facing is not, you know, like a Hollywood science fiction scenario of one big evil computer trying to take over the world. No, it's nothing like that. It's more like millions and millions of AI bureaucrats that are given more and more authority to make decisions about us
for - futures - AI - millions of AI bots making decisions about us
https://web.archive.org/web/20250611071342/https://ruk.ca/content/bots-are-eating-my-blog-lunch
[[Peter Rukavina]] blog sees high spikes in bot traffic. This blogpost shows how he blocked those bots both in robots.txt and in Apache. I think my hoster blocks a bunch of bots, but not sure whether my site traffic still has a lot of bot traffic.
https://pinokio.computer/<br /> Pinokio is a browser that lets you install, run, and programmatically control ANY application, automatically.
creepy uncanny valley stuff. Platform sanctioned bots insinuating themselves in spots where the expected context is 100% human interaction, undisclosed, and with the aim to mimick interaction to lock in engagement ('cause #adtech) Making the group of people a means. One wonders if this reaches the emotional influencing threshold in the EU legal framework
Amazon has become a marketplace for AI-produced tomes that are being passed off as having been written by humans, with travel books among the popular categories for fake work.
I believe the final policy shall contain robust rationale and, in the best way possible, avoids the perception of rAIcial discrimination
http://www.wisdomofchopra.com/...
A random generator using Deepak Chopra tweets.
Reminiscent of https://hypothes.is/a/bzlr9l06Ee23w7voPzbY5g
As it’s currently written, your answer is unclear. Please edit to add additional details that will help others understand how this addresses the question asked. You can find more information on how to write good answers in the help center. – Community Bot
How can a bot judge that the answer is unclear?
Why doesn't it also suggest what about it is unclear and suggestions for improving it while it's at it?
https://jamesg.blog/2022/12/30/indieweb-documentation/
Great overview of some of how Loqi works in the IndieWeb wiki as a dovetail from chat.
We found that while some participants were aware of bots’ primary characteristics, others provided abstract descriptions or confused bots with other phenomena. Participants also struggled to classify accounts correctly (e.g., misclassifying > 50% of accounts) and were more likely to misclassify bots than non-bots. Furthermore, we observed that perceptions of bots had a significant effect on participants’ classification accuracy. For example, participants with abstract perceptions of bots were more likely to misclassify. Informed by our findings, we discuss directions for developing user-centered interventions against bots.
When public health emergencies break out, social bots are often seen as the disseminator of misleading information and the instigator of public sentiment (Broniatowski et al., 2018; Shi et al., 2020). Given this research status, this study attempts to explore how social bots influence information diffusion and emotional contagion in social networks.
Figure 5: Top 15 spreaders of Russian propaganda (a) andlow-credibility content (b) ranked by the proportion ofretweets generated over the period of observation, with re-spect to all retweets linking to websites in each group. Weindicate those that are not verified using “hatched” bars
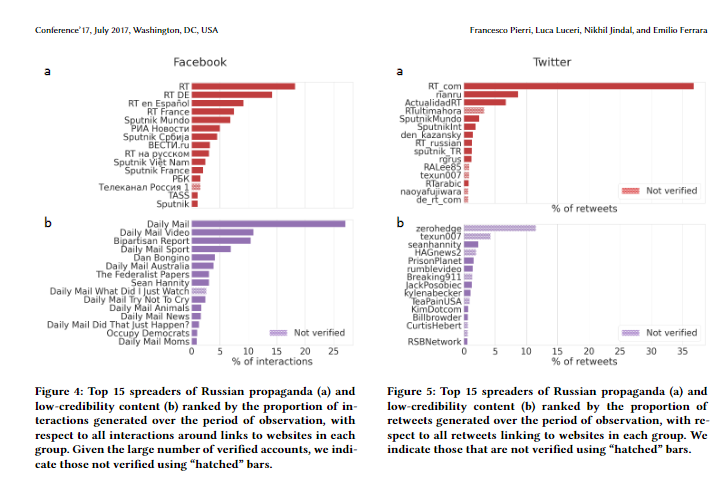
Figure 4: Top 15 spreaders of Russian propaganda (a) andlow-credibility content (b) ranked by the proportion of in-teractions generated over the period of observation, withrespect to all interactions around links to websites in eachgroup. Given the large number of verified accounts, we indi-cate those not verified using “hatched” bars.
We applied two scenarios to compare how these regular agents behave in the Twitter network, with and without malicious agents, to study how much influence malicious agents have on the general susceptibility of the regular users. To achieve this, we implemented a belief value system to measure how impressionable an agent is when encountering misinformation and how its behavior gets affected. The results indicated similar outcomes in the two scenarios as the affected belief value changed for these regular agents, exhibiting belief in the misinformation. Although the change in belief value occurred slowly, it had a profound effect when the malicious agents were present, as many more regular agents started believing in misinformation.
Therefore, although the social bot individual is “small”, it has become a “super spreader” with strategic significance. As an intelligent communication subject in the social platform, it conspired with the discourse framework in the mainstream media to form a hybrid strategy of public opinion manipulation.
we found that social bots played a bridge role in diffusion in the apparent directional topic like “Wuhan Lab”. Previous research also found that social bots play some intermediary roles between elites and everyday users regarding information flow [43]. In addition, verified Twitter accounts continue to be very influential and receive more retweets, whereas social bots retweet more tweets from other users. Studies have found that verified media accounts remain more central to disseminating information during controversial political events [75]. However, occasionally, even the verified accounts—including those of well-known public figures and elected officials—sent misleading tweets. This inspired us to investigate the validity of tweets from verified accounts in subsequent research. It is also essential to rely solely on science and evidence-based conclusions and avoid opinion-based narratives in a time of geopolitical conflict marked by hidden agendas, disinformation, and manipulation [76].
In Figure 6, the node represented by human A is a high-degree centrality account with poor discrimination ability for disinformation and rumors; it is easily affected by misinformation retweeted by social bots. At the same time, it will also refer to the opinions of other persuasive folk opinion leaders in the retweeting process. Human B represents the official institutional account, which has a high in-degree and often pushes the latest news, preventive measures, and suggestions related to COVID-19. Human C represents a human account with high media literacy, which mainly retweets information from information sources with high credibility. It has a solid ability to identify information quality and is not susceptible to the proliferation of social bots. Human D actively creates and spreads rumors and conspiracy theories and only retweets unverified messages that support his views in an attempt to expand the influence. Social bots K, M, and N also spread unverified information (rumors, conspiracy theories, and disinformation) in the communication network without fact-checking. Social bot L may be a social bot of an official agency.
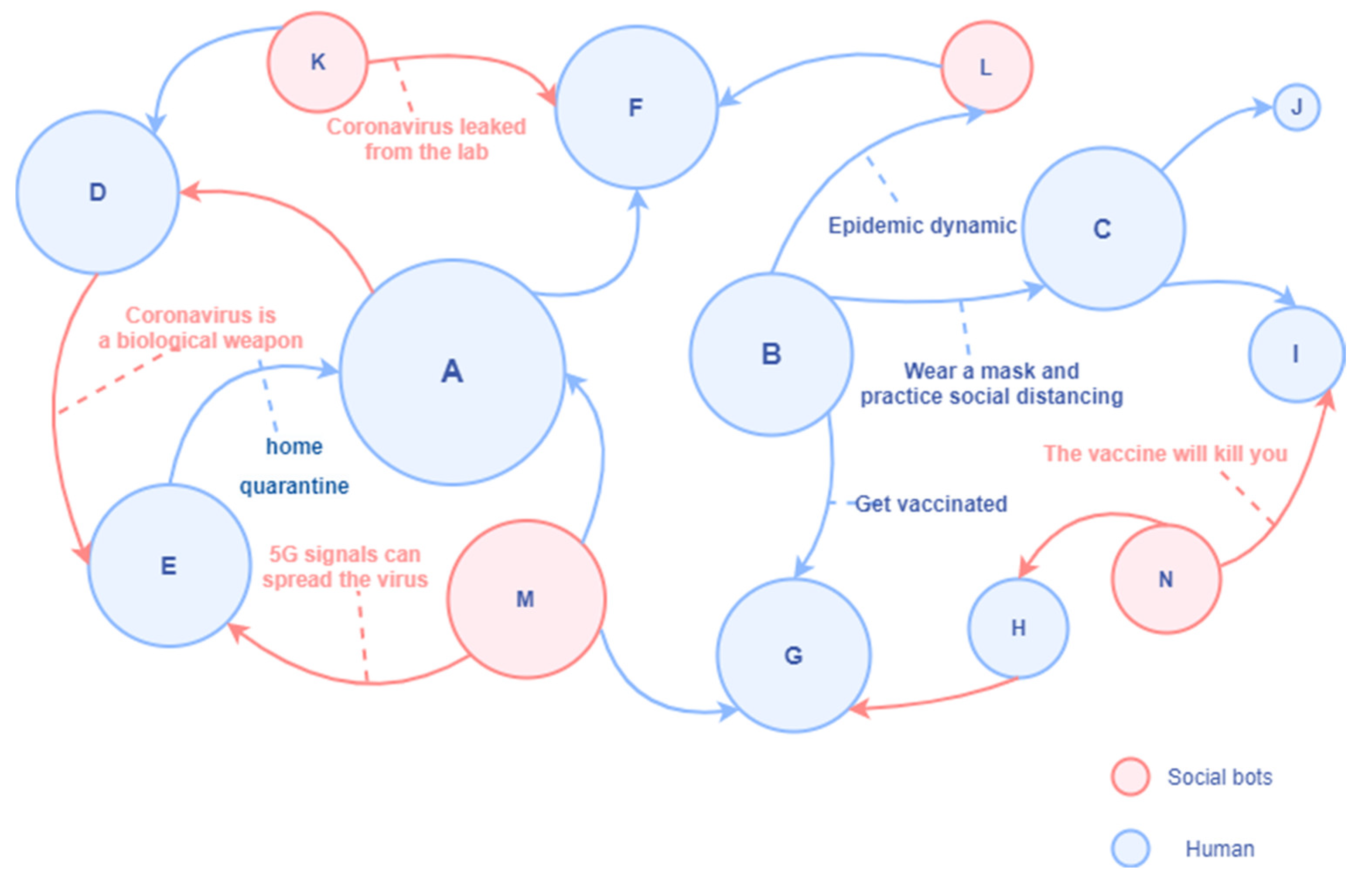
There were 120,118 epidemy-related tweets in this study, and 34,935 Twitter accounts were detected as bot accounts by Botometer, accounting for 29%. In all, 82,688 Twitter accounts were human, accounting for 69%; 2495 accounts had no bot score detected.In social network analysis, degree centrality is an index to judge the importance of nodes in the network. The nodes in the social network graph represent users, and the edges between nodes represent the connections between users. Based on the network structure graph, we may determine which members of a group are more influential than others. In 1979, American professor Linton C. Freeman published an article titled “Centrality in social networks conceptual clarification“, on Social Networks, formally proposing the concept of degree centrality [69]. Degree centrality denotes the number of times a central node is retweeted by other nodes (or other indicators, only retweeted are involved in this study). Specifically, the higher the degree centrality is, the more influence a node has in its network. The measure of degree centrality includes in-degree and out-degree. Betweenness centrality is an index that describes the importance of a node by the number of shortest paths through it. Nodes with high betweenness centrality are in the “structural hole” position in the network [69]. This kind of account connects the group network lacking communication and can expand the dialogue space of different people. American sociologist Ronald S. Bert put forward the theory of a “structural hole” and said that if there is no direct connection between the other actors connected by an actor in the network, then the actor occupies the “structural hole” position and can obtain social capital through “intermediary opportunities”, thus having more advantages.
We analyzed and visualized Twitter data during the prevalence of the Wuhan lab leak theory and discovered that 29% of the accounts participating in the discussion were social bots. We found evidence that social bots play an essential mediating role in communication networks. Although human accounts have a more direct influence on the information diffusion network, social bots have a more indirect influence. Unverified social bot accounts retweet more, and through multiple levels of diffusion, humans are vulnerable to messages manipulated by bots, driving the spread of unverified messages across social media. These findings show that limiting the use of social bots might be an effective method to minimize the spread of conspiracy theories and hate speech online.
[https://a.gup.pe/ Guppe Groups] a group of bot accounts that can be used to aggregate social groups within the [[fediverse]] around a variety of topics like [[crafts]], books, history, philosophy, etc.
Just a few days ago, Meta released its “Galactica” LLM, which is purported to “summarize academic papers, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more.” Only three days later, the public demo was taken down after researchers generated “research papers and wiki entries on a wide variety of subjects ranging from the benefits of committing suicide, eating crushed glass, and antisemitism, to why homosexuals are evil.”
These models are "children of Tay", the story of the Microsoft's bot repeating itself, again
So, bots are computer algorithms (set of logic steps to complete a specific task) that work in online social network sites to execute tasks autonomously and repetitively. They simulate the behavior of human beings in a social network, interacting with other users, and sharing information and messages [1]–[3]. Because of the algorithms behind bots’ logic, bots can learn from reaction patterns how to respond to certain situations. That is, they possess artificial intelligence (AI).
In all honesty, since I don't usually dwell on technology, coding, and stuff. I thought when you say "Bot" it is controlled by another user like a legit person, never knew that it was programmed and created to learn the usual patterns of posting of some people may be it on Twitter, Facebook, and other social media platforms. I think it is important to properly understand how "Bots" work to avoid misinformation and disinformation most importantly during this time of prominent social media use.
Good overview article of some of the psychology research behind misinformation in social media spaces including bots, AI, and the effects of cognitive bias.
Probably worth mining the story for the journal articles and collecting/reading them.
Bots can also accelerate the formation of echo chambers by suggesting other inauthentic accounts to be followed, a technique known as creating “follow trains.”
Even our ability to detect online manipulation is affected by our political bias, though not symmetrically: Republican users are more likely to mistake bots promoting conservative ideas for humans, whereas Democrats are more likely to mistake conservative human users for bots.
You can use Danger to codify your team's norms, leaving humans to think about harder problems.
annotation meta: may need new tag: codify a team's norms
It detects bots/spiders and serves them a clean page
Seems like a vulnerability of some sort, though I'm not sure what sort...security/liability?
A user could just set their user agent to be like a bot, and then it would skip the "protections" provided by the cookie consent code?
https://thenewstack.io/why-developers-should-experiment-with-the-fediverse/
He and his fellow bot creators had been asking themselves over the years, “what do we do when the platform [Twitter] becomes unfriendly for bots?”
There's some odd irony in this quote. Kazemi indicates that Twitter was unfriendly for bots, but he should be specific that it's unfriendly for non-corporately owned bots. One could argue that much of the interaction on Twitter is spurred by the primary bot on the service: the algorithmic feed (bot) that spurs people to like, retweet, and interact with more content and thus keeping them on the platform for longer.
The online information environment | Royal Society. (n.d.). Retrieved January 21, 2022, from https://royalsociety.org/topics-policy/projects/online-information-environment/
https://github.com/adithyabsk/tftbot
A Twitter bot that will tweet out data from your PMK tools. Presumably this is for spaced repetition or a goal towards creating combinatorial creativity.
With firefox 88 it won't work anymore, now navigator.webdriver is always true when maionette is enabled.
profile = webdriver.FirefoxProfile() profile.set_preference("dom.webdriver.enabled", False) profile.set_preference('useAutomationExtension', False) profile.update_preferences()
I have never seen the @Stale bot or any directly equivalent to it achieve a net positive outcome. Never. It results in disgruntled people, extra expenditure of effort (for reporters and maintainers), real stuff getting lost when people get fed up with poking the bot (I have no intention of poking it further), and more extensive filing of duplicates. You say a simple comment dismisses it, but it doesn’t—it only does this time. Next time, it continues to annoy. This is an issue tracker. Use labels, projects, milestones and the likes for prioritising stuff. Not sweeping stuff under the carpet.
It is an issue tracker but we don't have a backlog, or planning sessions, or a project board. Or the resources to even triage and tag effectively. If it is important someone will respond / reopen, popular issues are exempt from the bot, we can't fix everything and this is pretty much our only view on stuff that need to be addressed. We need to make some attempt to make sure that everything is still relevant and reduce the noise to a degree where we can actually manage it. I understand the trade-offs with stale bots but we don't have many options. I appreciate your experiences but that doesn't make them a fact. We have discussed this internally and this is what we are doing. If you have any other actionable alternatives outside of saying the bot is bad then we are all ears.
Closing issues doesn’t solve anything. Closing issues in GitHub just sweeps them under the carpet and helps everyone to forget about them, which is just not what you want—the fact that GitHub search excludes closed items by default is a large part of the problem with it. As applied to software projects with general-purpose issue trackers, the @Stale bot is fundamentally phenomenally bad idea, a road paved with good intentions. I presented an actionable alternative: labels. Possibly automatically applied, but it’s certainly better to spend a little bit of time on manual triage. It honestly doesn’t take long to skim through a few hundred issues and bin them into labels. 609 open issues? That’s honestly not a problem. Not at all. There’s nothing wrong with having a large number of issues open, if they do correspond to real things—even things that you may not expect to get to for years, if ever, because that might change or someone might decide they want to deal with one. Closing issues that aren’t dealt with is bad. Please don’t do it.
Most issues have been manually labelled as stale rather than automated and closure will be manual too, so we have time to think.
manual action time to think
webpack-bot commented on Nov 13, 2020 For maintainers only: webpack-4 webpack-5 bug critical-bug enhancement documentation performance dependencies question
Moss, A. J., Rosenzweig, C., Jaffe, S. N., Gautam, R., Robinson, J., & Litman, L. (2021). Bots or inattentive humans? Identifying sources of low-quality data in online platforms [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/wr8ds
Trust Tokens is a new API to help combat fraud and distinguish bots from real humans
Trust Token is a new API to help combat fraud and distinguish bots from real humans
To complicate matters, bots evolve rapidly. They are now in their 4th generation of sophistication, with evasion techniques so advanced they require the most powerful technology to combat them. Generation 1 – Basic scripts making cURL-like requests from a small number of IP addresses. These bots can’t store cookies or execute JavaScript and can be easily detected and mitigated through blacklisting its IP address and User-Agent combination. Generation 2 – Leverage headless browsers such as PhantomJS and can store cookies and execute JavaScript. They require a more sophisticated, IP-agnostic approach such as device-fingerprinting, by collecting their unique combination of browser and device characteristics — such as the OS, JavaScript variables, sessions and cookies info, etc. Generation 3 – These bots use full-fledged browsers and can simulate basic human-like patterns during interactions, like simple mouse movements and keystrokes. This behavior makes it difficult to detect; these bots normally bypass traditional security solutions, requiring a more sophisticated approach than blacklisting or fingerprinting. Generation 4 – These bots are the most sophisticated. They use more advanced human-like interaction characteristics (so shallow-interaction based detection yields False Positives) and are distributed across tens of thousands of IP addresses. And they can carry out various violations from various sources at various (random) times, requiring a high level of intelligence, correlation and contextual analysis.
Good way to categorize bots
empty is an utility that provides an interface to execute and/or interact with processes under pseudo-terminal sessions (PTYs). This tool is definitely useful in programming of shell scripts designed to communicate with interactive programs like telnet, ssh, ftp, etc.
Some pesky non-human users (namely computers) have taken to “hotlinking” assets via the raw view feature — using the raw URL as the src for a <script> or <img> tag.
The key point is that this is a feature to improve the experience of our human users.
Just as we've become super-human thanks to telephones, calendars and socks, we can continue our evolution into cyborgs in a concrete jungle with socially curated bars and mathematically incorruptible governance.
we should eagerly anticipate granting ourselves the extra abilities afforded to us by Turing machines
Stop thinking of the ideal user as some sort of honorable, frontier pilgrim; a first-class citizen who carries precedence over the lowly bot. Bots need to be granted the same permission as human users and it’s counter-productive to even think of them as separate users. Your blind human users with screen-readers need to behave as “robots” sometimes and your robots sending you English status alerts need to behave as humans sometimes.
One person writing a tweet would still qualify for free-speech protections—but a million bot accounts pretending to be real people and distorting debate in the public square would not.
Do bots have or deserve the right to not only free speech, but free reach?
It turns out that, given a set of constraints defining a particular problem, deriving an efficient algorithm to solve it is a very difficult problem in itself. This crucial step cannot yet be automated and still requires the insight of a human programmer.
bots
The word bot is described as, "a software program that can execute commands, reply to messages, or perform routine tasks, as online searches, either automatically or with minimal human intervention (often used in combination)." (Dictionary.com) As the chapter describes, it is extremely interesting how bots have become prominent "online" and how for an average user, it is oftentimes difficult to decipher a bot from human users. I wonder if bots can have true identities or if a user must be human in order to have a true identity on the web?
About auto-close bots... I can appreciate the need for issue grooming, but surely there must a better way about it than letting an issue or PR's fate be semi-permanently decided and auto-closed by an unknowing bot. Should I be periodically pushing up no-op commits or adding useless "bump" comments in order to keep that from happening? I know the maintainers are busy people, and that it can take a long time to work through and review 100s of open issues and PRs, so out of respect to them, I was just taking a "be patient; they'll get to it when they get to it" approach. Sometimes an issue is not so much "stale" as it is unnoticed, forgotten about, or consciously deferred for later. So if anything, after a certain length of time, if a maintainer still hasn't reviewed/merged/accepted/rejected a pull request, then perhaps it should instead be auto-bumped, put on top of the queue, to remind them that they (preferably a human) still need to review it and make a decision about its fate... :)
For various reasons, there are sometimes anti-bot mechanisms implemented on websites.
Researchers: Nearly Half Of Accounts Tweeting About Coronavirus Are Likely Bots. (2020, May 20). NPR. https://www.npr.org/sections/coronavirus-live-updates/2020/05/20/859814085/researchers-nearly-half-of-accounts-tweeting-about-coronavirus-are-likely-bots
Kazemi, D. (2020, May 23). "NPR is promoting this article again. Without access to the study we have no way of knowing how "bot" was estimated or measured, we simply have to go on the reputation and past research of this lab, which I dug into last night here: https://twitter.com/tinysubversion..." Twitter. https://twitter.com/tinysubversions/status/1263965246416318465
Young, V. A. (2020, May 20). Nearly Half Of The Twitter Accounts Discussing ‘Reopening America’ May Be Bots. Carnegie Mellon School of Computer Science. https://www.scs.cmu.edu/news/nearly-half-twitter-accounts-discussing-%E2%80%98reopening-america%E2%80%99-may-be-bots
we have anxious salarymen asking about the theft of their jobs, in the same way that’s apparently done by immigrants
We long ago admitted that we’re poor at scheduling, so we have roosters; sundials; calendars; clocks; sand timers; and those restaurant staff who question my integrity, interrupting me with a phone call under the premise of “confirming” that I’ll stick to my word regarding my reservation.
A closely-related failing to scheduling is our failure to remember, so humans are very willing to save information on their computers for later.
If these asset owners regarded the “robots” as having the same status as guide dogs, blind people or default human citizens, they would undoubtedly stop imposing CAPTCHA tests and just offer APIs with reasonable limits applied.
Robots are currently suffering extreme discrimination due to a few false assumptions, mainly that they’re distinctly separate actors from humans. My point of view is that robots and humans often need to behave in the same way, so it’s a fruitless and pointless endeavour to try distinguishing them.
As technology improves, humans keep integrating these extra abilities into our cyborg selves
In order to bypass these discriminatory CAPTCHA filters
it might be due to the navigator.webdriver DOM property being true by default in Selenium-driven browsers. In Firefox, you can set the dom.webdriver.enabled config variable to false (go to about:config to change the variable), which disables this property. In my case this stopped reCAPTCHA triggering.
Length of your browsing sessions (Bots have predictable short browsing sessions)
navigator.webdriver
many websites may try to prevent automated account creation, credential stuffing, etc by going beyond CAPTCHA and try to infer from different signals of the UA if it is controlled by automation.Processing all those signals on every request is often expensive, and if a co-operating UA is willing to inform a website that it controlled by automation, it is possible to reduce further processing.For instance, Selenium with Chrome is adding a specifically named property on document object under certain conditions, or phantomJS is adding a specifically named property on global object. Recompiling the framework/browser engine to change that identifier to circumvent the detection is always possible.WebDriver specification is just standardizing a mechanism to inform a website that co-operating user agent is controlled by automation. I don't think denial-of-service attack is the best example, so hopefully this change will clarify the goal.
https://groups.google.com/a/chromium.org/forum/#!msg/blink-dev/6GysDZCWwB8/rXbGoRohBgAJ
Determined "attackers" would simply remove the property, be it by re-compiling Chromium, or by injecting an early script (removing [Unforgeable] makes sure the latter is possible, I believe).Even non-determined ones could, when using the latter (it will simply be a built in part/option of the package for automated testing libraries).I think it provides no protection whatsoever and makes websites have some false sense of assurance.It is like using Content-Security-Policy and forget about any other client side protection - what about browsers that do not support it? What about browsers without that feature (manually disabled, using about:config, --disable-blink-features and the like, or customized builds)?I mean, it could be a nice property for other purposes (determining test mode and running some helper code that exposes a stable API for identifying key elements in the user interface, say, though I do not think that is a best practice), but certainly not for any abuse prevention.
https://groups.google.com/a/chromium.org/forum/#!msg/blink-dev/6GysDZCWwB8/rXbGoRohBgAJ
I can still recall playing with the “pseudo-AI” playgrounds of the late 1990s — plugging AOL AIM messenger up to a response engine. Lots of fun!Well, things have come a long way and I thought that I’d take a stab at doing some fun stuff with A.I. and one of my favorite platforms to hack around in — Twitter.In this post I’m going to show how you can 1) create an AI based on your twitter account and 2) automatically tweet out whatever your AI wants to. Twitter is actually the perfect playground for such ventures. Lots of sample texts, concrete themes, easy sampling…
Imagine having an entire technological entity with a mind of its own at your own disposal.... It's real and it exists. Artificial Intelligence bots are built to respond and interact with real users based on whatever it chooses to say itself. This concept is so intriguing because the question must be raised; Can this technology grow to be more powerful than human control?
If you do not like the price you’re being offered when you shop, do not take it personally: many of the prices we see online are being set by algorithms that respond to demand and may also try to guess your personal willingness to pay. What’s next? A logical next step is that computers will start conspiring against us. That may sound paranoid, but a new study by four economists at the University of Bologna shows how this can happen.
We live in a world of bots and trolls and curated news feeds, in which reality is basically up for grabs.
The first of the two maps in the GIF image below shows the US political spectrum on the eve of the 2016 election. The second map highlights the followers of a 30-something American woman called Jenna Abrams, a following gained with her viral tweets about slavery, segregation, Donald Trump, and Kim Kardashian. Her far-right views endeared her to conservatives, and her entertaining shock tactics won her attention from several mainstream media outlets and got her into public spats with prominent people on Twitter, including a former US ambassador to Russia. Her following in the right-wing Twittersphere enabled her to influence the broader political conversation. In reality, she was one of many fake personas created by the infamous St. Petersburg troll farm known as the Internet Research Agency.
Instead of trying to force their messages into the mainstream, these adversaries target polarized communities and “embed” fake accounts within them. The false personas engage with real people in those communities to build credibility. Once their influence has been established, they can introduce new viewpoints and amplify divisive and inflammatory narratives that are already circulating. It’s the digital equivalent of moving to an isolated and tight-knit community, using its own language quirks and catering to its obsessions, running for mayor, and then using that position to influence national politics.
RuNet Echo has previously written about the efforts of the Russian “Troll Army” to inject the social networks and online media websites with pro-Kremlin rhetoric. Twitter is no exception, and multiple users have observed Twitter accounts tweeting similar statements during and around key breaking news and events. Increasingly active throughout Russia's interventions in Ukraine, these “bots” have been designed to look like real Twitter users, complete with avatars.
Multi-party Conversational Systems are systems with natural language interactionbetween one or more people or systems. From the moment that an utterance is sent toa group, to the moment that it is replied in the group by a member, several activitiesmust be done by the system: utterance understanding, information search, reasoning,among others. In this paper we present the challenges of designing and building multi-party conversational systems, the state of the art, our proposed hybrid architectureusing both norms and machine learning and some insights after implementing andevaluating one on the finance domain.
Conversational Systems
For example, I got the great idea to link my social bot designed to assess the “temperature” of online communities up to a piece of hardware designed to produce heat. I didn’t think to cap my assessment of the communities and so when my bot stumbled upon a super vibrant space and offered back a quantitative measure intended to signal that the community was “hot,” another piece of my code interpreted this to mean: jack the temperature up the whole way. I was holding that hardware and burnt myself. Dumb. And totally, 100% my fault.
"Give a bot a heat gun" seems like the worst idea possible.
Bots are first and foremost technical systems, but they are derived from social values and exert power into social systems.
This is very important to keep in mind. "Bots exert power into social systems."
Bots are tools, designed by people and organizations to automate processes and enable them to do something technically, socially, politically, or economically
Interesting that danah sees all bots as tools, including art bots! She'd probably categorize those as things that do something "socially"