Pointing someone to a README.md does not lead to learning.
This reminds me of an interesting study from MIT relating to collective learning that I heard about from Cesar Hidalgo recently.
Pointing someone to a README.md does not lead to learning.
This reminds me of an interesting study from MIT relating to collective learning that I heard about from Cesar Hidalgo recently.
Solid supports templating in 3 forms JSX, Tagged Template Literals, and Solid's HyperScript variant.
Although I also work with solid in my day job at inrupt, I wrote this guide in my spare time.
I saw object proxies being the solution to doing diffing so that this approach could compete in any scenario that a VDOM could
So how do we declare the variable y to be the value of x plus 5? That's where reactive programming comes in. Reactive programming is a way of programming that makes it possible solve this problem
Here's a proxy store I wrote to derive the value of a store nested within other stores, it plays nice with typescript and can go infinitely deep
What is an iterable object in JavaScript? It’s an object that supports the iterable protocol.
no gradient tapes, no graph definitions requires
Note to self: look up what this means
Today we begin the Early Access Program for Code With Me, a tool for remote collaborative development and pair programming that you have long been waiting for.
Code With Me - new feature from JetBrains for collaborative programming. Unfortunately, soon it won't be free.
Indeed, this simple contract is very close to that of an observable, such as those provided by Rxjs. set is basically equivalent to next in the observable world.
The $ contract for auto-subscribing is lovely in its simplicity and flexibility. You can adapt your own preferred state-management pattern or library, with or without Svelte stores as helpers. Svelte does not fuss about how you want to manage your state.
However, IMO, having the conditional in the detach function is necessary, because there are other manifestations of this error. For example, if the DOM element in a component is removed from software outside of svelte, detach will have the same error.
IMO, the conditional needs to be added to detach to fix all manifestations of this error.
detach, as an api, should be declarative (ensure the node is detached) instead of imperative (detach the node), allowing it to be called multiple times by performing a noop if the node is already detached. This way, it won't matter if the node is removed from the DOM from outside of svelte.
Spending more time looking for a solution rather than thinking about it.
Stack Overflow Antipattern:
The benefit of this approach is that rather than having these defaults and fighting against them, it’s fully up to you to decide how to handle everything.
Then, the projects that use these libraries get to process these import statements how they like when they are bundled. For the ones that wish to load jQuery from a global, we again mark 'jquery' as an external—since we still don't want Rollup to bundle jQuery—and as a global.
I wrote hundreds of Rect components and what I learned is that Componets should be able to be styled by developer who is using it.
feel like there needs to be an easy way to style sub-components without their cooperation
The idea of a web browser being something we can comprehend, of a web page being something that more people can make, feels exciting to me.
my personal hope is that we can build a more sensible coherent web, that exudes the machines inside of it, by better harkening towards custom elements ("webcomponents"). move the page from being a bunch of machines in javascript, to a bunch of machines in hypertext.
and then build pages that start to expose & let the user play with the dom. start to build experiences that bridge the gap into the machine/page.
and keep going. keep going. build wilder web experiences. build more machines. and keep building battlesuits for the user, out of more componenets, out of more web, to let them wrestle & tangle with & manipulate & experiment & hack on & see & observe & learn about the truthful, honest, direct hypertext that we all navigate.
There is a good amount of properties that should mostly be applied from a parent's point of view. We're talking stuff like grid-area in grid layouts, margin and flex in flex layouts. Even properties like position and and the top/right/left/bottom following it in some cases.
The main reason using classes isn't a great solution is that it completely breaks encapsulation in a confusing way, the paren't shouldn't be dictating anything, the component itself should. The parent can pass things and the child can choose to use them or not but that is different: control is still in the hands of the component itself, not an arbitrary parent.
The RFC is more appropriate because it does not allow a parent to abritrarily control anything below it, that responsibility still relies on the component itself. Just because people have been passing classes round and overriding child styles for years doesn't mean it is a good choice and isn't something we wnat to encourage.
For my point of view, and I've been annoyingly consistent in this for as long as people have been asking for this feature or something like it, style encapsulation is one of the core principles of Svelte's component model and this feature fundamentally breaks that. It would be too easy for people to use this feature and it would definitely get abused removing the style safety that Svelte previously provided.
Ideally: Only let a parent control those specific CSS properties, and never let a child use them on the root element.
margin, flex, position, left, right, top, bottom, width, height, align-self, justify-self among other is CSS properties that should never be modified by the child itself. The parent should always have control of those properties, which is the whole reason I'm asking for this.
I think Svelte's approach where it replaces component instances with the component markup is vastly superior to Angular and the other frameworks. It gives the developer more control over what the DOM structure looks like at runtime—which means better performance and fewer CSS headaches, and also allows the developer to create very powerful recursive components.
Lets not extend the framework with yet another syntax
Yup.ref('value')
Often, allowing the parents to compose elements to be passed into components can offer the flexibility needed to solve this problem. If a component wants to have direct control over every aspect of a component, then it should probably own the markup as well, not just the styles. Svelte's slot API makes this possible. You can still get the benefits of abstracting certain logic, markup, and styles into a component, but, the parent can take responsibility for some of that markup, including the styling, and pass it through. This is possible today.
As you can see, this would mean that a change in a component is potentially no longer isolated to that component, and the entire codebase should be checked to see if anybody has been overriding the default styles.
Your styles are scoped to the component. No more leakage, no more unpredictable cascade.
It's fashionable to dislike CSS. There are lots of reasons why that's the case, but it boils down to this: CSS is unpredictable. If you've never had the experience of tweaking a style rule and accidentally breaking some layout that you thought was completely unrelated — usually when you're trying to ship — then you're either new at this or you're a much better programmer than the rest of us.
It turns out that even the length of time an element has been mounted is an important piece of state that determines what pixels the user sees. And some of this state can’t simply be lifted into our application state.
What this means is that our desire to express UI using pure functions is in direct conflict with the very nature of the DOM. It’s a great way to describe a state => pixels transformation — perfect for game rendering or generative art — but when we’re building apps on the web, the idea chafes against the reality of a stateful medium.
Functions have lots of interesting and useful properties. You can isolate them. You can compose them. You can memoize them. In other words, functional UI feels correct, and powerful, in a way that wasn’t true of whatever came before it. I think this is why people get quasi-religious about React. It’s not that it’s Just JavaScript. It’s that it’s Just Functions. It’s profound.
Svelte, on the other hand, is a compiler. In a way, Svelte is more like a programming language than a library.
A paradigm is a model or pattern. In JavaScript, there are a number of popular paradigms including object-oriented programming (OOP) and functional programming (FP). Paradigms are more important than is sometimes recognized. They help form mental models for solving problems. Becoming well-versed in the principles of a given paradigm can help accelerate development by providing mental shortcuts for solving the challenges that arise while building applications. They can also help produce higher quality software.
we need to step back and make a closer look at the DRY principle. As I mentioned earlier, it stands for "Don’t Repeat Yourself" and requires that any piece of domain knowledge has a single representation in your code base. The words domain knowledge are key here. DRY is not about duplicating code. It is specifically about duplicating domain knowledge
This is actually a good point – to have a single representation of specific piece of domain knowledge in the code.
DRY is not about duplicating code.
We wanted a library designed specifically for a functional programming style, one that makes it easy to create functional pipelines, one that never mutates user data.
Codecheckers/covid-uk. (2020). [R]. CODECHECK. https://github.com/codecheckers/covid-uk (Original work published 2020)
aaronpeikert. (2020). Aaronpeikert/reproducible-research [TeX]. https://github.com/aaronpeikert/reproducible-research (Original work published 2019)
Eglen, S. J. (2020). CODECHECK certificate 2020-008. Zenodo. https://doi.org/10.5281/zenodo.3746024
r/BehSciMeta—Comment by u/nick_chater on ”Programming errors and their implications”. (n.d.). Reddit. Retrieved June 1, 2020, from https://www.reddit.com/r/BehSciMeta/comments/gsowog/programming_errors_and_their_implications/fsi76l7
r/BehSciMeta—No appeasement of bad faith actors. (n.d.). Reddit. Retrieved June 2, 2020, from https://www.reddit.com/r/BehSciMeta/comments/gv0y99/no_appeasement_of_bad_faith_actors/
Hackathons are a great way of testing new technology with your team, and a place where you can go crazy with solutions.
find every email on a web page that you're on. The big kahuna - this works for every website. Inject it into a site with Chrome DevTools (more here)
Use this code below to find every e-mail on a webpage:
var elems = document.body.getElementsByTagName("*");
var re = new RegExp("(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$)");
for (var i = 0; i < elems.length; i++) {
if (re.test(elems[i].innerHTML)) {
console.log(elems[i].innerHTML);
}
}
“I came to Rust from Haskell, and I feel that Haskell is a very elegant and safe language. The biggest differentiator for me is that there is a greater difference between high-performance code and idiomatic ‘clean’ code in Haskell than in Rust. Most Rust code looks like most other Rust code, even when it performs well. Haskell can become unfamiliar real quick if someone is operating under different libraries and goals from what you are typically doing. Small differences in syntax can result in huge differences in behavior, and Rust has more uniformity on that axis.”
Then when giving answers I'm even less certain. For example I see occasional how-to questions which (IMO) are ridiculously complex in bash, awk, sed, etc. but trivial in python, (<10 lines, no non-standard libraries). On such questions I wait and see if other answers are forthcoming. But if they get no answers, I'm not sure if I should give my 10 lines of python or not.
Go cheatsheet
Super useful cheatsheet for the Go programming language.
The above errors can be resolved by simply adding the ⚡attribute to the <html> tag like so: <html ⚡ lang="en">
TLA+ is a high-level language for modeling programs and systems--especially concurrent and distributed ones.
Need to look more into TLA+ and formal verification with regards to software development.
Essays on programming I think about a lot
Nice collection of programming essays
Introducing Module#const_source_locationUsing Method#source_location made finding the location of any method fairly easy. Unfortunately, there wasn’t an equivalent for constants. This meant that unless the constant you needed to find was defined in your codebase, finding its source location was not easy.
When FrozenError is raised, it is usually difficult to determine from the context which was the frozen object that a modification was attempted on.Ruby 2.7 introduces FrozenError#receiver which will return the frozen object that modification was attempted on, similar to NameError#receiver. This can help pinpoint exactly what is the frozen object.
A beginless range is experimentally introduced. It might not be as useful as an endless range, but would be good for DSL purposes.
dynamic
A dynamic language (Lisp, Perl, Python, Ruby) is designed to optimize programmer efficiency, so you can implement functionality with less code. A static language (C, C++, etc) is designed to optimize hardware efficiency, so that the code you write executes as quickly as possible. https://stackoverflow.com/questions/20563433/difference-between-static-and-dynamic-programming-languages#:~:text=A%20dynamic%20language%20(Lisp%2C%20Perl,executes%20as%20quickly%20as%20possible.
multi-paradigm
Programming paradigms are a way to classify programming languages based on their features - these include imperative, declarative,
https://upload.wikimedia.org/wikipedia/commons/f/f7/Programming_paradigms.svg
https://en.wikipedia.org/wiki/Comparison_of_multi-paradigm_programming_languages
the overloaded operators ¬, =, ≠, and abs are defined
Most of Algol's "special" characters (⊂, ≡, ␣, ×, ÷, ≤, ≥, ≠, ¬, ⊃, ≡, ∨, ∧, →, ↓, ↑, ⌊, ⌈, ⎩, ⎧, ⊥, ⏨, ¢, ○ and □) can be found on the IBM 2741 keyboard with the APL "golf-ball" print head inserted; these became available in the mid-1960s while ALGOL 68 was being drafted. These characters are also part of the Unicode standard and most of them are available in several popular fonts.
Made analogy with internal combustion engine, which has 1000s of parts, with the "radical simplicity" approach taken by Tesla: they use an electric motor, which only has 2 components!
comparison: Sapper vs. Gatsby
Typical software requirements specify the following
The brain uses the same area to save coding as it does to save our speech. They found that programming is like talking. The research found out that the brain regions that are most active during coding are those that are also relevant in the processing of natural language.
in Python - setting up basic logger is very simple
Apart from printing the result, it is better to debug with logging.
Sample logger:
import logging
logging.basicConfig(
filename='application.log',
level=logging.WARNING,
format= '[%(asctime)s] {%(pathname)s:%(lineno)d} %(levelname)s - %(message)s',
datefmt='%H:%M:%S'
)
logging.error("Some serious error occurred.")
logging.warning('Function you are using is deprecated.')
the sample result:
[12:52:35] {<stdin>:1} ERROR - Some serious error occurred.
[12:52:35] {<stdin>:1} WARNING - Function you are using is deprecated.
to find its location, type:
logging.getLoggerClass().root.handlers[0].baseFilename
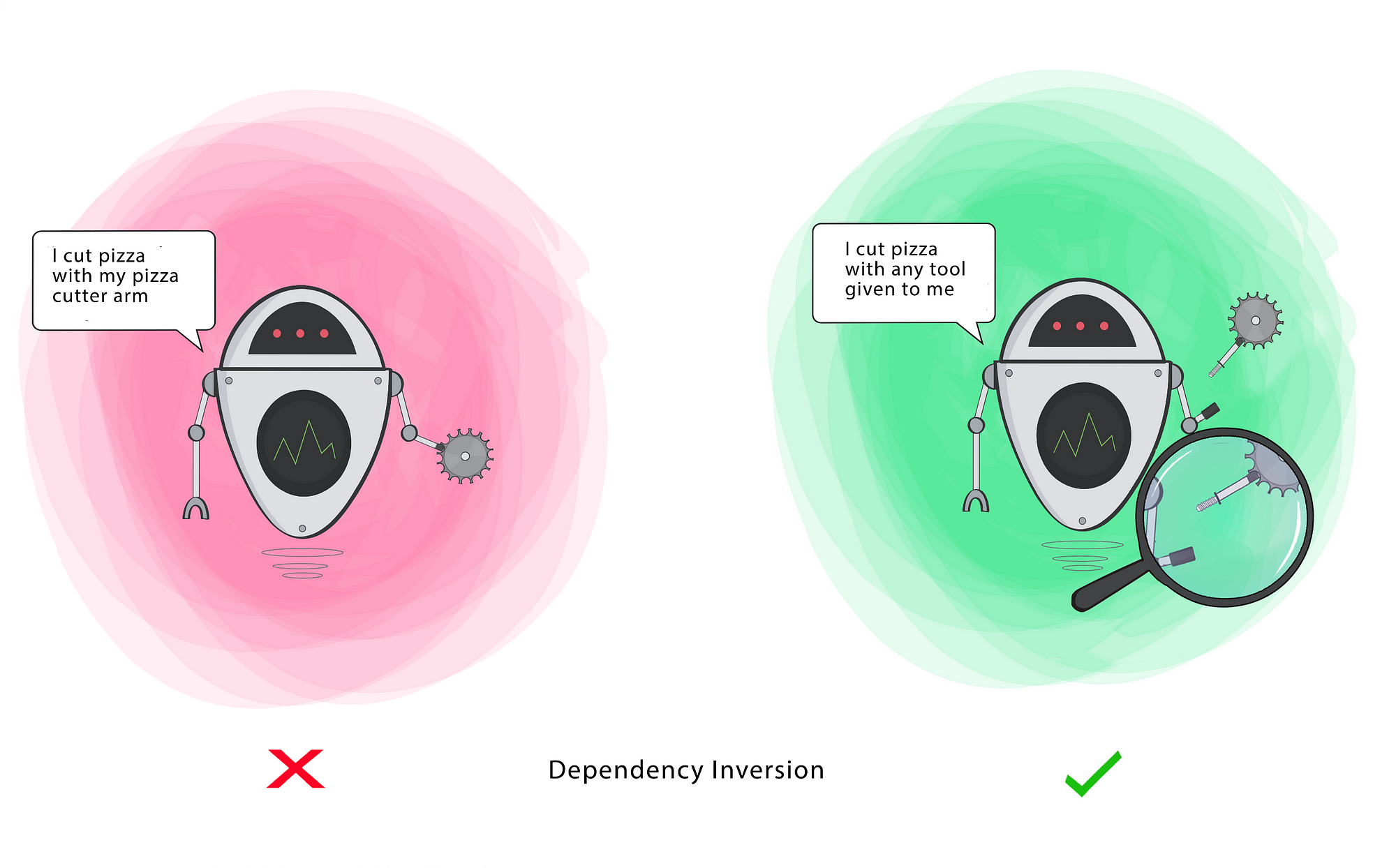
- High-level modules should not depend on low-level modules. Both should depend on the abstraction.- Abstractions should not depend on details. Details should depend on abstractions.
SOLI(D)
Dependency Inversion
Clients should not be forced to depend on methods that they do not use.
SOL(I)D
Interface Segregation
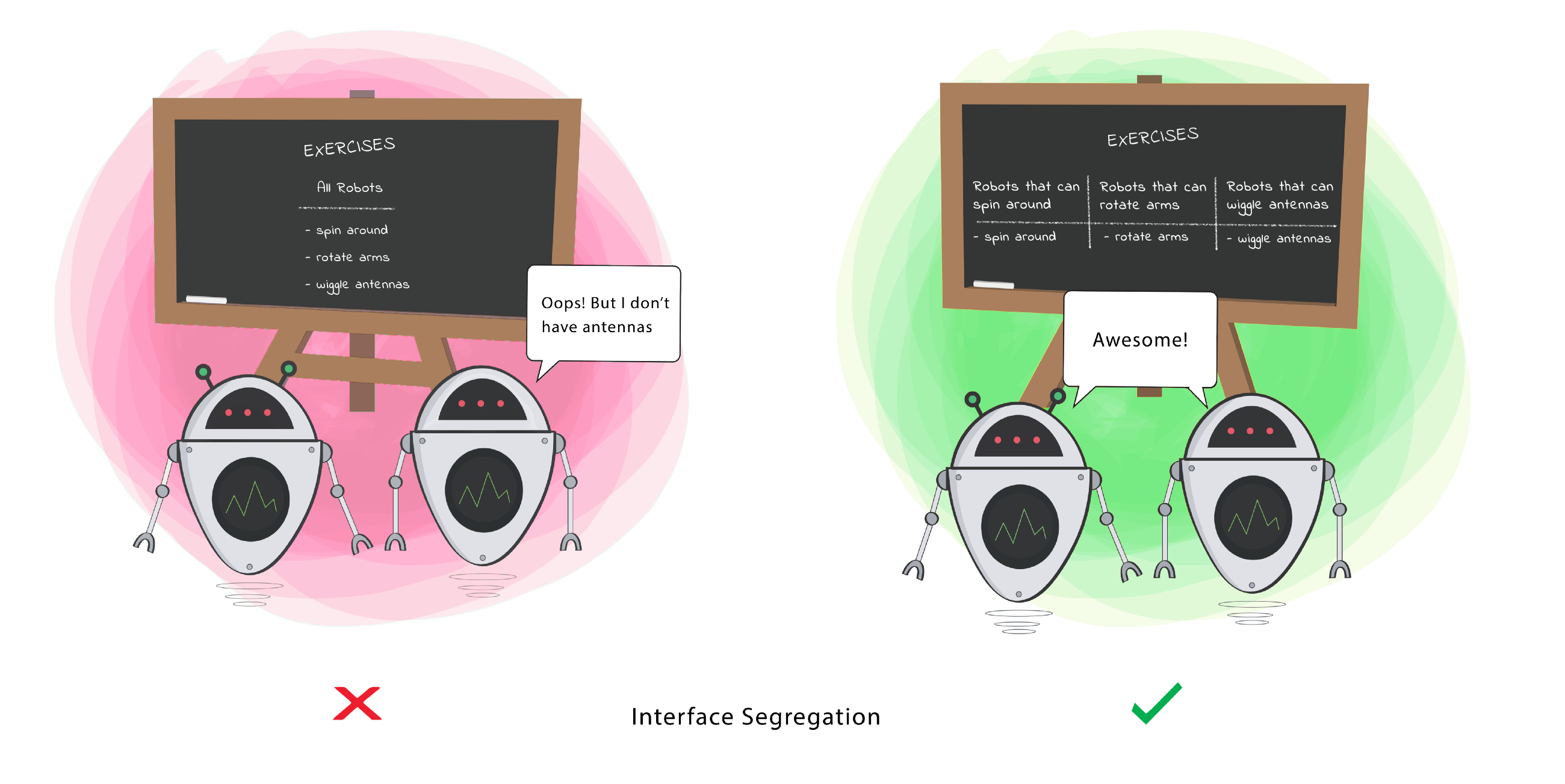
If S is a subtype of T, then objects of type T in a program may be replaced with objects of type S without altering any of the desirable properties of that program.
SO(L)ID
Liskov Substitution

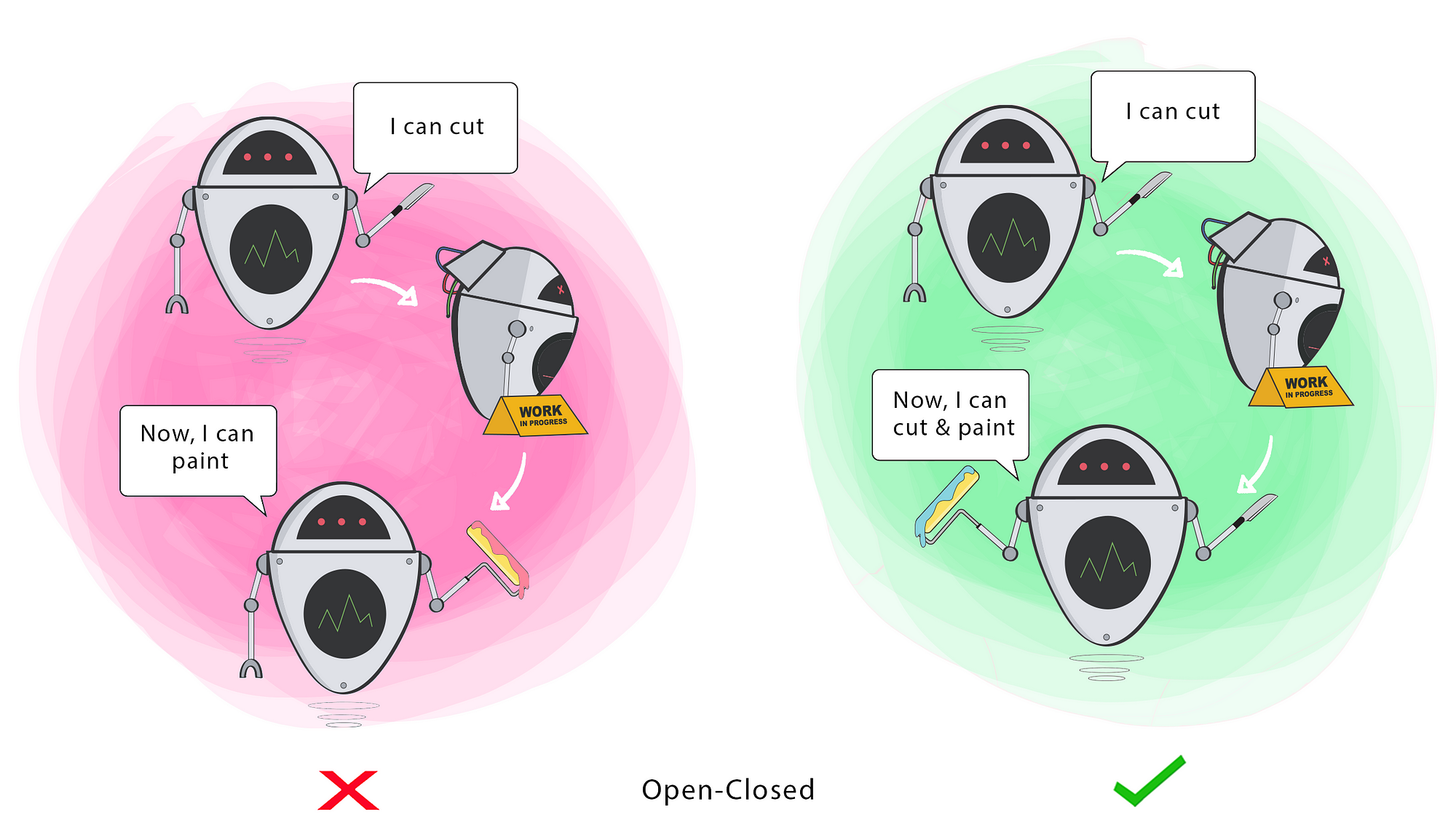
Classes should be open for extension, but closed for modification
S(O)LID
Open-Closed
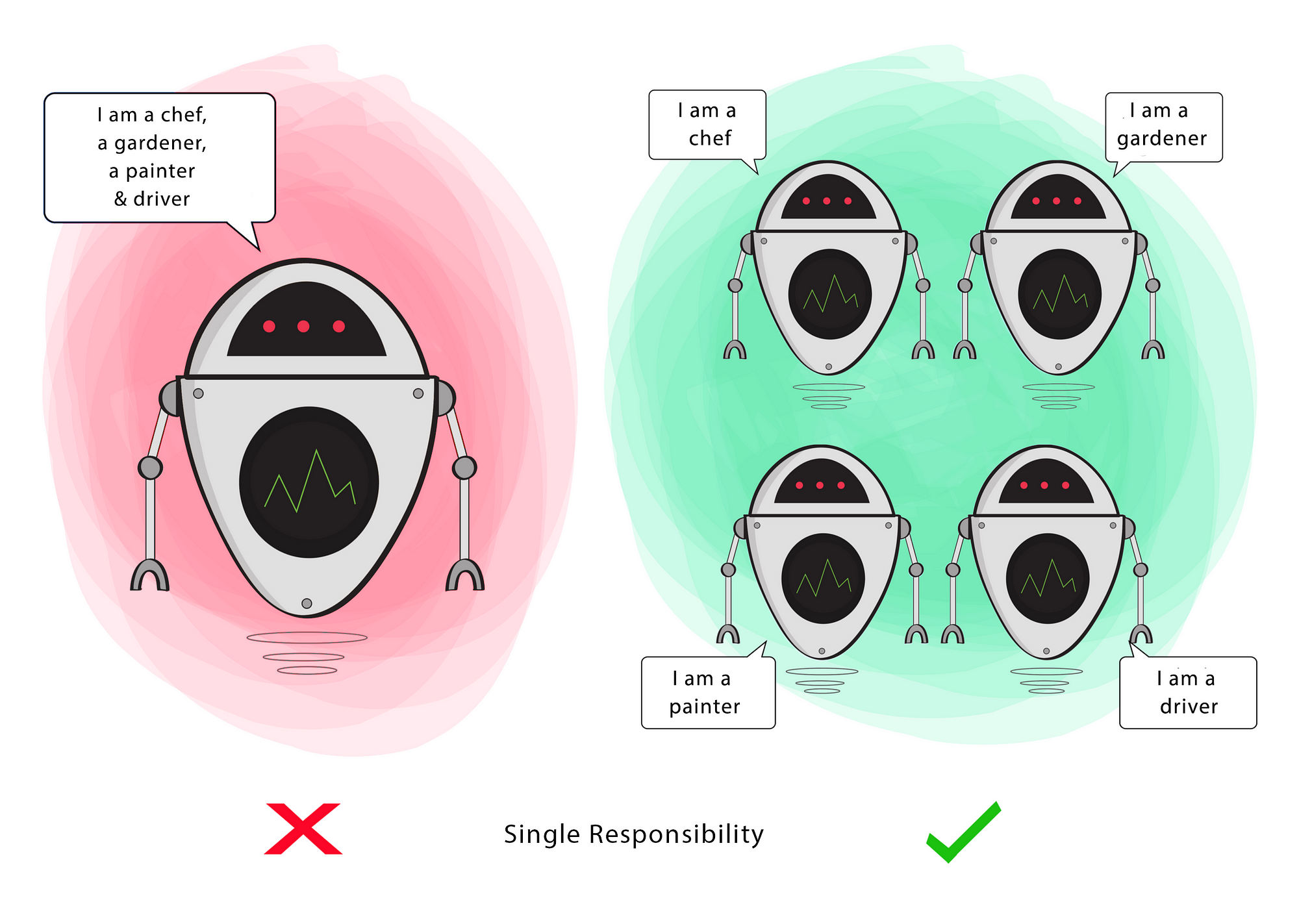
A class should have a single responsibility
(S)OLID
Single Responsibility
Peikert, A., & Brandmaier, A. M. (2019). A Reproducible Data Analysis Workflow with R Markdown, Git, Make, and Docker. https://doi.org/10.31234/osf.io/8xzqy
This tightly controlled build environment is sometimes called a "holy build box". The Traveling Ruby project provides such a holy build box.
Don’t go to code academy, go to design academy. Be advocates of the user & consumer. It’s not about learning how to code, it’s about translating real-world needs to technological specifications in just ways that give end users agency and equity in design, development and delivery. Be a champion of user-centric design. Learn how to steward data and offer your help.
The importance of learning to design, and interpreting/translating real-world needs.
bookmark
function (or in the case of type classes, we call these methods)
If you can tell that two types are equal or not equal, that type belongs in the Eq type class.
two types or rather two things of the same type?
Mehrotra, S., Rahimian, H., Barah, M., Luo, F., & Schantz, K. (2020 May 02). A model of supply-chain decisions for resource sharing with an application to ventilator allocation to combat COVID-19. Naval Research Logistics (NRL). https://doi.org/10.1002/nav.21905
Continuous Delivery of Deployment is about running as thorough checks as you can to catch issues on your code. Completeness of the checks is the most important factor. It is usually measured in terms code coverage or functional coverage of your tests. Catching errors early on prevents broken code to get deployed to any environment and saves the precious time of your test team.
Continuous Delivery of Deployment (quick summary)
Continuous Integration is a trade off between speed of feedback loop to developers and relevance of the checks your perform (build and test). No code that would impede the team progress should make it to the main branch.
Continuous Integration (quick summary)
A good CD build: Ensures that as many features as possible are working properly The faster the better, but it is not a matter of speed. A 30-60 minutes build is OK
Good CD build
A good CI build: Ensures no code that breaks basic stuff and prevents other team members to work is introduced to the main branch Is fast enough to provide feedback to developers within minutes to prevent context switching between tasks
Good CI build
The idea of Continuous Delivery is to prepare artefacts as close as possible from what you want to run in your environment. These can be jar or war files if you are working with Java, executables if you are working with .NET. These can also be folders of transpiled JS code or even Docker containers, whatever makes deploy shorter (i.e. you have pre built in advance as much as you can).
Idea of Continuous Delivery
Continuous Delivery is about being able to deploy any version of your code at all times. In practice it means the last or pre last version of your code.
Continous Delivery
Continuous Integration is not about tools. It is about working in small chunks and integrating your new code to the main branch and pulling frequently.
Continuous Integration is not about tools
The app should build and start Most critical features should be functional at all times (user signup/login journey and key business features) Common layers of the application that all the developers rely on, should be stable. This means unit tests on those parts.
Things to be checked by Continous Integration
Continuous Integration is all about preventing the main branch of being broken so your team is not stuck. That’s it. It is not about having all your tests green all the time and the main branch deployable to production at every commit.
Continuous Integration prevents other team members from wasting time through a pull of faulty code
// ES5-compatible code var myObject = { prop1: 'hello', prop2: 'world', output: function() { console.log(this.prop1 + ' ' + this.prop2); } }; myObject.output(); // hello world
Creating an object.
Scrum means that “you have to get certain things done with those two weeks.” Kanban means “do what you can do in two weeks.”
If you get a choice, push for Kanban over Scrum
What people will say is that estimates are for planning – that their purpose is to figure out how long some piece of work is going to take, so that everybody can plan accordingly. In all my five years shipping stuff, I can only recall one project where things really worked that way.
Project estimations are just energy drainers and stress producers
Be explicit about the difference between hard deadlines
Different types of deadlines:
If you delegate all your IT security to the InfoSec, they will come up with draconian rules
Try to do some of your own security before delegating everything to InfoSec that will come with draconian restrictions
you should always advocate for having a dedicated SRE if there’s any real risk of after-hours pages that are out of your control.
Site Reliability Engineers (ideally from different time zones) should've been settled when we might expect after-hours errors
I try to write a unit test any time the expected value of a defect is non-trivial.
Write unit tests at least for the most important parts of code, but every chunk of code should have a trivial unit test around it – this verifies that the code is written in a testable way, which indeed is extremely important
I’m defining an integration test as a test where you’re calling code that you don’t own
When to write integration tests:
Which database technology to choose
Which database to choose (advice from an Amazon employee):
I would use a serverless function when I have a relatively small and simple chunk of code that needs to run every once in a while.
When to make a serverless function (advice from an Amazon employee)
Programming languages These will probably expose my ignorance pretty nicely.
When to use different programming languages (advice from an Amazon employee):
A few takeaways
Summarising the article:
I set it with a few clicks at Travis CI, and by creating a .travis.yml file in the repo
You can set CI with a few clicks using Travis CI and creating a .travis.yml file in your repo:
language: node_js
node_js: node
before_script:
- npm install -g typescript
- npm install codecov -g
script:
- yarn lint
- yarn build
- yarn test
- yarn build-docs
after_success:
- codecov
I set it with a few clicks at Travis CI, and by creating a .travis.yml file in the repo
You can set CI with a few clicks using Travis CI and creating a .travis.yml file in your repo:
language: node_js
node_js: node
before_script:
- npm install -g typescript
- npm install codecov -g
script:
- yarn lint
- yarn build
- yarn test
- yarn build-docs
after_success:
- codecov
Continuous integration makes it easy to check against cases when the code: does not work (but someone didn’t test it and pushed haphazardly), does work only locally, as it is based on local installations, does work only locally, as not all files were committed.
CI - Continuous Integration helps to check the code when it :
In Python, when trying to do a dubious operation, you get an error pretty soon. In JavaScript… an undefined can fly through a few layers of abstraction, causing an error in a seemingly unrelated piece of code.
Undefined nature of JavaScript can hide an error for a long time. For example,
function add(a,b) { return + (a + b) }
add(2,2)
add('2', 2)
will result in a number, but is it the same one?
With Codecov it is easy to make jest & Travis CI generate one more thing:
Codecov lets you generate a score on your tests:

I would use ESLint in full strength, tests for some (especially end-to-end, to make sure a commit does not make project crash), and add continuous integration.
Advantage of tests
It is fine to start adding tests gradually, by adding a few tests to things that are the most difficult (ones you need to keep fingers crossed so they work) or most critical (simple but with many other dependent components).
Start small by adding tests to the most crucial parts
I found that the overhead to use types in TypeScript is minimal (if any).
In TypeScript, unlike in JS we need to specify the types:

I need to specify types of input and output. But then I get speedup due to autocompletion, hints, and linting if for any reason I make a mistake.
In TypeScript, you spend a bit more time in the variable definition, but then autocompletion, hints, and linting will reward you. It also boosts code readability
TSDoc is a way of writing TypeScript comments where they’re linked to a particular function, class or method (like Python docstrings).
TSDoc <--- TypeScript comment syntax. You can create documentation with TypeDoc
ESLint does automatic code linting
ESLint <--- pluggable JS linter:
if (x = 5) { ... })Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.
According to the Kernighan's Law, writing code is not as hard as debugging
Write a new test and the result. If you want to make it REPL-like, instead of writing console.log(x.toString()) use expect(x.toString()).toBe('') and you will directly get the result.
jest <--- interactive JavaScript (TypeScript and others too) testing framework. You can use it as a VS Code extension.
Basically, instead of console.log(x.toString()), you can use except(x.toString()).toBe(''). Check this gif to understand it further
interactive notebooks fall short when you want to write bigger, maintainable code
Survey regarding programming notebooks:

I recommend Airbnb style JavaScript style guide and Airbnb TypeScript)
Recommended style guides from Airbnb for:
Creating meticulous tests before exploring the data is a big mistake, and will result in a well-crafted garbage-in, garbage-out pipeline. We need an environment flexible enough to encourage experiments, especially in the initial place.
Overzealous nature of TDD may discourage from explorable data science
The programming language is augmented with natural language description details, where convenient, or with compact mathematical notation.
There are many types of CRDTs
CRDTs have different types, such as Grow-only set and Last-writer-wins register. Check more of them here
Some of our main takeaways:CRDT literature can be relevant even if you're not creating a decentralized systemMultiplayer for a visual editor like ours wasn't as intimidating as we thoughtTaking time to research and prototype in the beginning really paid off
Key takeaways of developing a live editing tool
traditional approaches that informed ours — OTs and CRDTs
Traditional approaches of the multiplayer technology
CRDTs refer to a collection of different data structures commonly used in distributed systems. All CRDTs satisfy certain mathematical properties which guarantee eventual consistency. If no more updates are made, eventually everyone accessing the data structure will see the same thing. This constraint is required for correctness; we cannot allow two clients editing the same Figma document to diverge and never converge again
CRDTs (Conflict-free Replicated Data Types)
They’re a great way of editing long text documents with low memory and performance overhead, but they are very complicated and hard to implement correctly
Characteristics of OTs
Even if you have a client-server setup, CRDTs are still worth researching because they provide a well-studied, solid foundation to start with
CRDTs are worth studying for a good foundation
Figma’s multiplayer servers keep track of the latest value that any client has sent for a given property on a given object
✅ No conflict:
❎ Conflict:
Figma doesn’t store any properties of deleted objects on the server. That data is instead stored in the undo buffer of the client that performed the delete. If that client wants to undo the delete, then it’s also responsible for restoring all properties of the deleted objects. This helps keep long-lived documents from continuing to grow in size as they are edited
Undo option
it's important to be able to iterate quickly and experiment before committing to an approach. That's why we first created a prototype environment to test our ideas instead of working in the real codebase
First work with a prototype, then the real codebase
Designers worried that live collaborative editing would result in “hovering art directors” and “design by committee” catastrophes.
Worries of using a live collaborative editing
We had a lot of trouble until we settled on a principle to help guide us: if you undo a lot, copy something, and redo back to the present (a common operation), the document should not change. This may seem obvious but the single-player implementation of redo means “put back what I did” which may end up overwriting what other people did next if you’re not careful. This is why in Figma an undo operation modifies redo history at the time of the undo, and likewise a redo operation modifies undo history at the time of the redo
Undo/Redo working
operational transforms (a.k.a. OTs), the standard multiplayer algorithm popularized by apps like Google Docs. As a startup we value the ability to ship features quickly, and OTs were unnecessarily complex for our problem space
Operational Transforms (OT) are unnecessarily complex for problems unlike Google Docs
Every Figma document is a tree of objects, similar to the HTML DOM. There is a single root object that represents the entire document. Underneath the root object are page objects, and underneath each page object is a hierarchy of objects representing the contents of the page. This tree is is presented in the layers panel on the left-hand side of the Figma editor.
Structure of Figma documents
When a document is opened, the client starts by downloading a copy of the file. From that point on, updates to that document in both directions are synced over the WebSocket connection. Figma lets you go offline for an arbitrary amount of time and continue editing. When you come back online, the client downloads a fresh copy of the document, reapplies any offline edits on top of this latest state, and then continues syncing updates over a new WebSocket connection
Offline editing isn't a problem, unlike the online one
An important consequence of this is that changes are atomic at the property value boundary. The eventually consistent value for a given property is always a value sent by one of the clients. This is why simultaneous editing of the same text value doesn’t work in Figma. If the text value is B and someone changes it to AB at the same time as someone else changes it to BC, the end result will be either AB or BC but never ABC
Consequence of approaches like last-writer-wins
We use a client/server architecture where Figma clients are web pages that talk with a cluster of servers over WebSockets. Our servers currently spin up a separate process for each multiplayer document which everyone editing that document connects to
Way Figma approaches client/server architecture
Sometimes it's interesting to explain some code (How many time you spend trying to figure out a regex pattern when you see one?), but, in 99% of the time, comments could be avoided.
Generally try to avoid (avoid != forbid) comments.
Comments:
When we talk about abstraction levels, we can classify the code in 3 levels: high: getAdress medium: inactiveUsers = Users.findInactives low: .split(" ")
3 abstraction levels:
getAdressinactiveUsers = Users.findInactives.split(" ")Explanation:
searchForsomething()account.unverifyAccountmap, to_downncase and so on The ideal is not to mix the abstraction levels in only one function.
Try not mixing abstraction levels inside a single function
There is another maxim also that says: you must write the same code a maximum of 3 times. The third time you should consider refactoring and reducing duplication
Avoid repeating the same code over and over
Should be nouns, and not verbs, because classes represent concrete objects
Class names = nouns
Uncle Bob, in clean code, defends that the best order to write code is: Write unit tests. Create code that works. Refactor to clean the code.
Best order to write code (according to Uncle Bob):
int d could be int days
When naming things, focus on giving meaningful names, that you can pronounce and are searchable. Also, avoid prefixes
naming things, write better functions and a little about comments. Next, I intend to talk about formatting, objects and data structures, how to handle with errors, about boundaries (how to deal with another's one code), unit testing and how to organize your class better. I know that it'll be missing an important topic about code smells
Ideas to consider while developing clean code:
Should be verbs, and not nouns, because methods represent actions that objects must do
Methods names = verbs
decrease the switch/if/else is to use polymorphism
It's better to avoid excessive switch/if/else statements

In the ideal world, they should be 1 or 2 levels of indentation
Functions in the ideal world shouldn't be long
"The Big Picture" is one of those things that people say a whole lot but can mean so many different things. Going through all of these articles, they tend to mean any (or all) of these things
Thinking about The Big Picture:
Considering that there are still a ton of COBOL jobs out there, there is no particular technology that you need to know
RIght, there is no specific need to learn that one technology
read Knuth, or Pragmatic Programming, or Clean Code, or some other popular book
Classic programming related books
Senior developers are more cautious, thoughtful, pragmatic, practical and simple in their approaches to solving problems.
Interesting definition of senior devs
In recent years we’ve also begun to see increasing interest in exploratory testing as an important part of the agile toolbox
Waterfall software development ---> agile ---> exploratory testing
When I began coding, around 30 years ago, waterfall software development was used nearly exclusively.
Mathematica didn’t really help me build anything useful, because I couldn’t distribute my code or applications to colleagues (unless they spent thousands of dollars for a Mathematica license to use it), and I couldn’t easily create web applications for people to access from the browser. In addition, I found my Mathematica code would often end up much slower and more memory hungry than code I wrote in other languages.
Disadvantages of Mathematica:
In the 1990s, however, things started to change. Agile development became popular. People started to understand the reality that most software development is an iterative process
a methodology that combines a programming language with a documentation language, thereby making programs more robust, more portable, more easily maintained, and arguably more fun to write than programs that are written only in a high-level language. The main idea is to treat a program as a piece of literature, addressed to human beings rather than to a computer.
Exploratory testing described by Donald Knuth
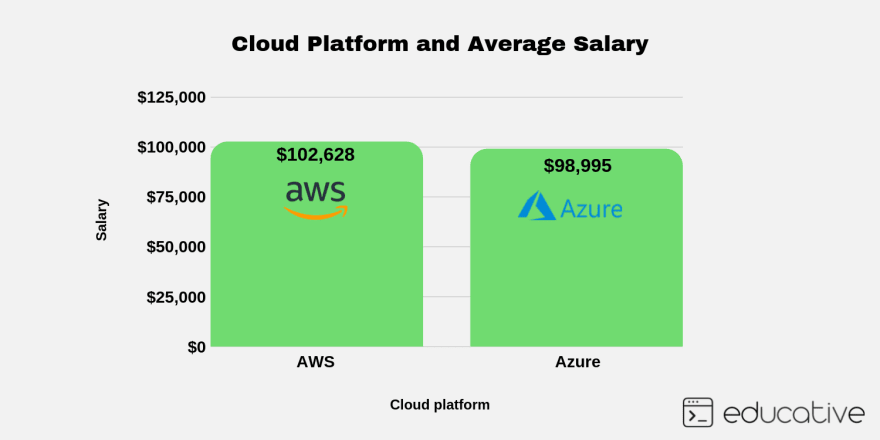
Developing in the cloud
Well paid cloud platforms:
Finding a database management system that works for you
Well paid database technologies:
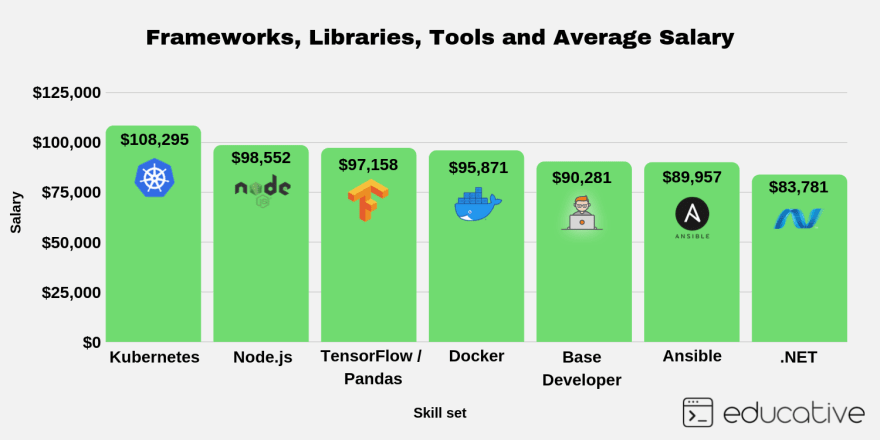
Here are a few very prominent technologies that you can look into and what impact each one might have on your salary
Other well paid frameworks, libraries and tools:
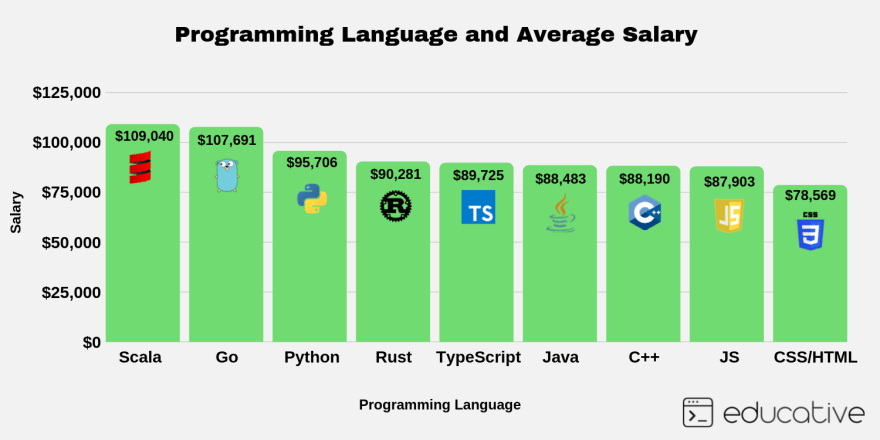
What programming language should I learn next?
Most paid programming languages:
Android and iOS
Payment for mobile OS:
First, you’ve spread the logic across a variety of different systems, so it becomes more difficult to reason about the application as a whole. Second, more importantly, the logic has been implemented as configuration as opposed to code. The logic is constrained by the ability of the applications which have been wired together, but it’s still there.
Why "no code" trend is dangerous in some way (on the example of Zapier):
the developer doesn’t need to worry about allocating memory, or the character set encoding of the string, or a host of other things.
Comparison of C (1972) and TypeScript (2012) code.
(check the code above)
“No Code” systems are extremely good for putting together proofs-of-concept which can demonstrate the value of moving forward with development.
Great point of "no code" trend
With someone else’s platform, you often end up needing to construct elaborate work-arounds for missing functionality, or indeed cannot implement a required feature at all.
You can quickly implement 80% of the solution in Salesforce using a mix of visual programming (basic rule setting and configuration), but later it's not so straightforward to add the missing 20%
Summary
In doing a code review, you should make sure that:
"Continuous Delivery is the ability to get changes of all types — including new features, configuration changes, bug fixes, and experiments — into production, or into the hands of users, safely and quickly in a sustainable way". -- Jez Humble and Dave Farley
Continuous Delivery
Another approach is to use a tool like H2O to export the model as a POJO in a JAR Java library, which you can then add as a dependency in your application. The benefit of this approach is that you can train the models in a language familiar to Data Scientists, such as Python or R, and export the model as a compiled binary that runs in a different target environment (JVM), which can be faster at inference time
H2O - export models trained in Python/R as a POJO in JAR
Continuous Delivery for Machine Learning (CD4ML) is a software engineering approach in which a cross-functional team produces machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.
Continuous Delivery for Machine Learning (CD4ML) (long definition)
Basic principles:
In order to formalise the model training process in code, we used an open source tool called DVC (Data Science Version Control). It provides similar semantics to Git, but also solves a few ML-specific problems:
DVC - transform model training process into code.
Advantages:
Sometimes, the best way to learn is to mimic others. Here are some great examples of projects that use documentation well:
Examples of projects that use documentation well
(chech the list below)
“Code is more often read than written.” — Guido van Rossum
Documenting code is describing its use and functionality to your users. While it may be helpful in the development process, the main intended audience is the users.
Documenting code:
Class method docstrings should contain the following: A brief description of what the method is and what it’s used for Any arguments (both required and optional) that are passed including keyword arguments Label any arguments that are considered optional or have a default value Any side effects that occur when executing the method Any exceptions that are raised Any restrictions on when the method can be called
Class method should contain:
(check example below)
Comments to your code should be kept brief and focused. Avoid using long comments when possible. Additionally, you should use the following four essential rules as suggested by Jeff Atwood:
Comments should be as concise as possible. Moreover, you should follow 4 rules of Jeff Atwood:
From examining the type hinting, you can immediately tell that the function expects the input name to be of a type str, or string. You can also tell that the expected output of the function will be of a type str, or string, as well.
Type hinting introduced in Python 3.5 extends 4 rules of Jeff Atwood and comments the code itself, such as this example:
def hello_name(name: str) -> str:
return(f"Hello {name}")
strDocstrings can be further broken up into three major categories: Class Docstrings: Class and class methods Package and Module Docstrings: Package, modules, and functions Script Docstrings: Script and functions
3 main categories of docstrings
According to PEP 8, comments should have a maximum length of 72 characters.
If comment_size > 72 characters:
use `multiple line comment`
Docstring conventions are described within PEP 257. Their purpose is to provide your users with a brief overview of the object.
Docstring conventions
All multi-lined docstrings have the following parts: A one-line summary line A blank line proceeding the summary Any further elaboration for the docstring Another blank line
Multi-line docstring example:
"""This is the summary line
This is the further elaboration of the docstring. Within this section,
you can elaborate further on details as appropriate for the situation.
Notice that the summary and the elaboration is separated by a blank new
line.
# Notice the blank line above. Code should continue on this line.
say_hello.__doc__ = "A simple function that says hello... Richie style"
Example of using __doc:
Code (version 1):
def say_hello(name):
print(f"Hello {name}, is it me you're looking for?")
say_hello.__doc__ = "A simple function that says hello... Richie style"
Code (alternative version):
def say_hello(name):
"""A simple function that says hello... Richie style"""
print(f"Hello {name}, is it me you're looking for?")
Input:
>>> help(say_hello)
Returns:
Help on function say_hello in module __main__:
say_hello(name)
A simple function that says hello... Richie style
class constructor parameters should be documented within the __init__ class method docstring
init
Scripts are considered to be single file executables run from the console. Docstrings for scripts are placed at the top of the file and should be documented well enough for users to be able to have a sufficient understanding of how to use the script.
Docstrings in scripts
Documenting your code, especially large projects, can be daunting. Thankfully there are some tools out and references to get you started
You can always facilitate documentation with tools.
(check the table below)
Commenting your code serves multiple purposes
Multiple purposes of commenting:
BUG, FIXME, TODOEach format makes tradeoffs in encoding, flexibility, and expressiveness to best suit a specific use case.
Each data format brings different tradeoffs:
Computers can only natively store integers, so they need some way of representing decimal numbers. This representation comes with some degree of inaccuracy. That's why, more often than not, .1 + .2 != .3
Computers make up their way to store decimal numbers
Cross-platform development is now a standard because of wide variety of architectures like mobile devices, cloud servers, embedded IoT systems. It was almost exclusively PCs 20 years ago.
A package management ecosystem is essential for programming languages now. People simply don’t want to go through the hassle of finding, downloading and installing libraries anymore. 20 years ago we used to visit web sites, downloaded zip files, copied them to correct locations, added them to the paths in the build configuration and prayed that they worked.
How library management changed in 20 years
IDEs and the programming languages are getting more and more distant from each other. 20 years ago an IDE was specifically developed for a single language, like Eclipse for Java, Visual Basic, Delphi for Pascal etc. Now, we have text editors like VS Code that can support any programming language with IDE like features.
How IDEs "unified" in comparison to the last 20 years
Your project has no business value today unless it includes blockchain and AI, although a centralized and rule-based version would be much faster and more efficient.
Comparing current project needs to those 20 years ago
Being a software development team now involves all team members performing a mysterious ritual of standing up together for 15 minutes in the morning and drawing occult symbols with post-its.
In comparison to 20 years ago ;)
Language tooling is richer today. A programming language was usually a compiler and perhaps a debugger. Today, they usually come with the linter, source code formatter, template creators, self-update ability and a list of arguments that you can use in a debate against the competing language.
How coding became much more supported in comparison to the last 20 years
There is StackOverflow which simply didn’t exist back then. Asking a programming question involved talking to your colleagues.
20 years ago StackOverflow wouldn't give you a hand
Since we have much faster CPUs now, numerical calculations are done in Python which is much slower than Fortran. So numerical calculations basically take the same amount of time as they did 20 years ago.
Python vs Fortran ;)
I am not sure how but one kind soul somehow found the project, forked it, refactored it, "modernized" it, added linting, code sniffing, added CI and opened the pull request.
It's worth sharing your code, since someone can always find it and improve it, so that you can learn from it
It is solved when you understand why it occurred and why it no longer does.
What does it mean for a problem to be solved?
Let's reason through our memoizer before we write any code.
Operations performed by a memoizer:
Which is written as:
// Takes a reference to a function
const memoize = func => {
// Creates a cache of results
const results = {};
// Returns a function
return (...args) => {
// Create a key for results cache
const argsKey = JSON.stringify(args);
// Only execute func if no cached value
if (!results[argsKey]) {
// Store function call result in cache
results[argsKey] = func(...args);
}
// Return cached value
return results[argsKey];
};
};