- Jun 2021
-
github.com github.com
-
I'm not sure if there's any cost in terms of contributing either, especially when by design git can have any branch as default, and will not hinder your experience when you use something other than master.
git is neutral/unbiased/agnostic about default branch name by design
And that is a good thing
-
The primary branch in git can have any name by design.
-
In the context of git, the word "master" is not used in the same way as "master/slave". I've never known about branches referred to as "slaves" or anything similar.
-
- May 2021
-
stackoverflow.com stackoverflow.com
-
Normally, git diff looks for non-printable characters in the files and if it looks like the file is likely to be a binary file, it refuses to show the difference. The rationale for that is binary file diffs are not likely to be human readable and will probably mess up your terminal if displayed. However, you can instruct git diff to always treat files as text using the --text option. You can specify this for one diff command: git diff --text HEAD HEAD^ file.txt You can make Git always use this option by setting up a .gitattributes file that contains: file.txt diff
-
-
gregoryszorc.com gregoryszorc.com
-
If you insist on using Git and insist on tracking many large files in version control, you should definitely consider LFS. (Although, if you are a heavy user of large files in version control, I would consider Plastic SCM instead, as they seem to have the most mature solution for large files handling.)
When the usage of Git LFS makes sense
-
In Mercurial, use of LFS is a dynamic feature that server/repo operators can choose to enable or disable whenever they want. When the Mercurial server sends file content to a client, presence of external/LFS storage is a flag set on that file revision. Essentially, the flag says the data you are receiving is an LFS record, not the file content itself and the client knows how to resolve that record into content.
Generally, Merculiar handles LFS slightly better than Git
-
If you adopt LFS today, you are committing to a) running an LFS server forever b) incurring a history rewrite in the future in order to remove LFS from your repo, or c) ceasing to provide an LFS server and locking out people from using older Git commits.
Disadvantages of using Git LFS
-
-
git-scm.com git-scm.com
-
:/<text>, e.g. :/fix nasty bug A colon, followed by a slash, followed by a text, names a commit whose commit message matches the specified regular expression.
:/<text>- searching git commits using their text instead of hash, e.g.:/fix nasty bug
-
-
git-scm.com git-scm.com
-
git worktree add <path> automatically creates a new branch whose name is the final component of <path>, which is convenient if you plan to work on a new topic. For instance, git worktree add ../hotfix creates new branch hotfix and checks it out at path ../hotfix.
The simple idea of git-worktree to manage multiple working trees without stashing
-
-
stackoverflow.com stackoverflow.com
-
git diff --relative will print paths from the dir you are in.
first sighting: git diff --relative
-
-
git-scm.com git-scm.com
Tags
Annotators
URL
-
-
paul-samuels.com paul-samuels.com
-
stackoverflow.com stackoverflow.com
-
kdiff3 can be used solely with keyboard, so 5 conflict file takes when reading the code just few minutes.
-
Thanks. Worked for me. I needed to move the merged directory into a sub-folder so after following the above steps I simply used git mv source-dir/ dest/new-source-dir
-
In case you want to put project-a into a subdirectory, you can use git-filter-repo (filter-branch is discouraged)
-
Note: This rewrites history;
-
-
-
github.com github.com
-
--ignore-unmatch
-
-
syslog.ravelin.com syslog.ravelin.com
-
Preserving history; we often find ourselves using the git blame tool to discover why a certain change was made.
-
Preserving commit hashes; we use commit hashes in binary names and our issue tracker; ideally, these references remain intact.
-
-
-
github.com github.com
-
New changes to the old repositories can be imported into the monorepo and merged in. For example, in the above example, say repository one had a branch my_branch which continued to be developed after the migration. To pull those changes in:
-
-
-
stephan-bester.medium.com stephan-bester.medium.com
-
mattmazzola.medium.com mattmazzola.medium.com
-
github.com github.com
-
[Old commit references] Provide a way for users to use old commit IDs with the new repository (in particular via mapping from old to new hashes with refs/replace/ references).
-
Let's say that we want to extract a piece of a repository, with the intent on merging just that piece into some other bigger repo.
-
-
-
stackoverflow.com stackoverflow.com
-
If you want the project's history to look as though all files have always been in the directory foo/bar, then you need to do a little surgery. Use git filter-branch with the "tree filter" to rewrite the commits so that anywhere foo/bar doesn't exist, it is created and all files are moved to it:
-
-
til.hashrocket.com til.hashrocket.com
-
Tip about left/right of commit-history between 2 branches.
-
- Apr 2021
-
-
🐛 (home, components): Resolve issue with modal collapses 🚚 (home): Move icons folder ✨ (newsletter): Add Newsletter component
With gitmojis, we can replace the
<type>part of a git commit -
feat(home, components): Add login modal fix(home, components): Resolve issue with modal collapses chore(home): Move icons folder
Examples of readable commits in the format:
<type> [scope]: "Message"
-
-
github.com github.com
Tags
Annotators
URL
-
-
techmunching.com techmunching.com
-
Very good post and with nice animated gif`s
Tags
Annotators
URL
-
- Mar 2021
-
gist.github.com gist.github.com
- Feb 2021
-
nixos.wiki nixos.wiki
-
git clone --depth=1 https://github.com/nixos/nixpkgs
i should remember this to only get last commit, which basically means to only care about the data, and discard commit history.
-
-
maggieappleton.com maggieappleton.com
-
The transclusion doesn't automatically change along with it. If transclusions were direct embeds of the original content, we'd end up with link rot on a whole new scale. Every document would be a sad compilation of 404's.
Thinking about Git repositories, this is how submodules work. you 'freeze' the 'transclusion' to one exact commit and can update if and when needed. Moreover, the contents are stored within the local repository, so they are future-proof.
-
- Jan 2021
-
devcenter.heroku.com devcenter.heroku.com
-
master
Tive problemas ao executar o deploy porque este repo por ser novo já usa o padrao de "main" para o nome da branch principal.
$ git push heroku main
-
- Dec 2020
-
git-scm.com git-scm.com
-
Download for macOS
Install git on a macOS
Tags
Annotators
URL
-
-
hacks.mozilla.org hacks.mozilla.org
-
Less developer maintenance burden: The existing (Kuma) platform is complex and hard to maintain. Adding new features is very difficult. The update will vastly simplify the platform code — we estimate that we can remove a significant chunk of the existing codebase, meaning easier maintenance and contributions.
-
-
github.com github.com
-
Does anyone know how to make npm use a specific fork containing a bug fix while waiting for maintainer to merge a pull request? I was just going to point my package.json to this fork, like this: "svelte-material-ui": "https://github.com/vtpatrickeddy/svelte-material-ui.git#patch-1", but that doesn't work because the repo is a monorepo. And there doesn't appear to be a way to specify a subdirectory inside it, like: "@smui/textfield": "https://github.com/vtpatrickeddy/svelte-material-ui.git/packages/textarea#patch-1",
-
-
-
-
$ git log --grep "commit message search"
git blame: searching commit messages themselves with grep
-
$ git log -S "deleted code" -p
git blame: way to find deleted piece of code
-
$ git log -S "some code" -p app/models/user.rb
git blame: limiting search to a specific folder
-
$ git log -G "REGEX HERE"
git blame: searching with a regular expression
-
Find the entire history of a snippet of code with git log -S Include -p to see the diff as well as the commit messages Include --reverse to see the commit that introduced the code listed first Scope search to specific folders or files by including a path Search with a regular expression using git log -G Search commit messages using git log --grep
Summary of
git blamesearching tips -
If you include the -p option (short for --patch) you get the full diff alongside the commit messages
git log -S "method_name" -p<--- get the full dif with commit messages to have more context -
Say you want to find the first commit that introduced a particular class, method or snippet of code. You can use the pickaxe combined with the --reverse option to get the commits in reverse-chronological order so the commit where the code first appears is listed at the top
git log -S "method_name" -p --reverse<--- get commits in reverse-chronological order -
git log -S (also known as “the pickaxe”) is how you take things to the next level. It lets you search for all commits that contain a given string:
git log -S<--- search for commits with a given string -
git blame is too coarse: it reports against the whole line. If the most recent change isn’t related to the part of the line you’re interested, you’re out of luck. git blame is too shallow: it only reports a single change; the most recent one. The story of the particular piece of code you’re interested in may have evolved over several commits. git blame is too narrow: it only considers the file you are running blame against. The code you are interested in may also appear in other files, but to get the relevant commits on those you’ll need to run blame several times.
Disadvantages of
git blamecommand (it's like limiting ourselves to 2D view instead of 3D
-
- Nov 2020
-
changelog.com changelog.com
-
I feel that with all that power that it’s gaining, instead of being a more approachable tool, that it’s actually being a tool that is continuously making people feel frustrated, to the point where I feel that whatever the next version control system is… (And it does not have to be something separate than Git. It should maybe be just a really powerful abstraction built on top of Git.) But I think whatever the next iteration of the people’s version control is… it should be something that is more reflective of how we think about what version control is for us.
Tags
Annotators
URL
-
-
scolaire.loupbrun.ca scolaire.loupbrun.ca
-
master
une mobilisation parallèle dans le milieu des technologies a eu lieu pour retirer les références à caractère opprimant, mobilisation qui a refait surface avec la poussée du mouvement Black Lives Matter.
par exemple, une recommandation consiste à nommer «
main» ou «primary» la branche principale (au lieu de «master»).
-
-
-
master
une mobilisation parallèle dans le milieu des technologies a eu lieu pour retirer les références à caractère opprimant, mobilisation qui a refait surface avec la poussée du mouvement Black Lives Matter.
par exemple, une recommandation consiste à nommer «
main» ou «primary» la branche principale (au lieu de «master»).
-
-
www.remotemobprogramming.org www.remotemobprogramming.org
Tags
Annotators
URL
-
-
opensource.com opensource.com
-
For example, suppose you want to search for the string "font-size: 52 px;" in your repository: $ git rev-list –all | xargs git grep -F ‘font-size: 52 px;’
Searching Git repo with grep
-
$ git show main:README.md Once you execute this command, you can view the content of the file in your terminal.
You can view the README.md file while being in any branch
-
Every repository has a .git folder. It is a special hidden folder. $ ls -a . … .git
Inside the hidden .git folder, you may find:
- The current state of HEAD:
$ cat .git/HEAD ref: refs/heads/master- Potentially a description of your repo:
$ cat .git/description -
To optimize your repository further, you can use Git garbage collection. $ git gc --prune=now --aggressive This command helps when you or your team heavily uses pull or push commands.
You can optimise your repo not only with
.gitignorefile, but with Git garbage collection.This command is an internal utility that cleans up unreachable or "orphaned" Git objects in your repository
-
Git, along with some Bash command piping, makes it easy to create a zip archive for your untracked files. $ git ls-files --others --exclude-standard -z |\ xargs -0 tar rvf ~/backup-untracked.zip
Taking backup of untracked files.
This command makes an archive (and excludes files listed in .gitignore) with the name backup-untracked.zip
-
$ git rev-list –count master 32
Example of counting the number of commits with
git rev-list --count -
Many developers count the number of commits to judge when to increment the build number, for instance, or just to get a feel for how the project is progressing.
Why to count the number of commits
-
To avoid similar scenarios, enable Git autocorrection in your Git configuration: $ git config --global help.autocorrect 1
Applying autocorrection in Git.
When you type:
git stats, instead of suggesting a command, it will rungit statusautomatically
Tags
Annotators
URL
-
- Oct 2020
-
unix.stackexchange.com unix.stackexchange.com
-
git rev-parse --show-toplevel
-
-
opencontent.org opencontent.org
-
When you can assume that all the materials you’re using in and with your class are open educational resources, here’s one way to remix the effective practices listed above with OER in order to provide you and your students with opportunities to spend your time and effort on work that makes the world a better place instead of wasting it on disposable assignments.
As I think of remix, reuse, redistribute and things like git and version control, I also can't help but think that being able to send and receive webmentions in the process of reusing and redistribution with referential links back to the originals will allow the original creator to at least be aware of the changes and their existence to potentially manually add them to the original project. (Manually because they may not (yet) know how to keep their content under source control or allow others to do so and send pull requests.)
-
Free to accessFree to reuseFree to reviseFree to remixFree to redistributeThe question becomes, then, what is the relationship between these additional capabilities and what we know about effective teaching and learning? How can we extend, revise, and remix our pedagogy based on these additional capabilities?
I look at this and think immediatly about the Git model of allowing people to not only fork and reuse/redistribute pieces, but what about the ability to do pull requests to take improvements and push them back up the the source so that everyone potentially benefits?
-
-
stackoverflow.com stackoverflow.com
-
git push origin master explicitly says "push the local branch 'master' to the remote named 'origin'". This does not define a persistent relationship, it just executes a push this one time. Note that the remote branch is assumed to be named "master". git push -u origin master is the same thing, except it first adds a persistent tracking relationship between your local branch "master" and the remote named "origin". As before, it is assumed the remote branch is named "master". If you have done a push with -u already, then the relationship is already defined. In the future, you can simply say git push or git pull, and git will automatically use the defined remote tracking branch without being told explicitly. You can view your tracking relationships with git branch -vv, which will list your local branches along with their current HEAD commit and, if one is set, the remote tracking branch. Here is an example.
-
- Sep 2020
-
scolaire.loupbrun.ca scolaire.loupbrun.ca
-
Examining the changes to programs over time is a useful strategy for under-standing the life of the code
ce que permet notamment le numérique aisément, voire fluidement ou même nativement (avec des logiciels et protocoles comme Git): le versionnement, l'archivage des versions, le marquage volontaire v1, v2 v3.57 comme Kittler…
-
-
github.com github.com
Tags
Annotators
URL
-
-
github.com github.com
-
-
For a non-monorepo package you can simply point directly to the Github repo. This case is similar, but you want to scope it just to a single package within the repo. For those that make monorepos they don't necessarily need this feature. It's for those that use projects that use monorepos. Telling them to not organize their projects into monorepos doesn't help people who make use of these projects.
-
If npm installs a git repo, it assumes that the git repo is the package. I don't really know how we could specify a sub-path easily, since all parts of the git url are already used for other things.
-
-
-
This is more a rhetoric question as this seems to be quite hard ;-) There is a long discussion about installing a subfolder of a repository and monorepos in general at the NPM Github issues (yarn misses this feature, too). The thing is that this makes it quite hard to report issues of your project as one can't test the current master easily. Do you recommend a way how to use the latest Github version?
-
- Aug 2020
-
-
Would you really forget to push your code if that triggers a rocket launch?
Git-rocket (VS Code extension).
Lol :D
Tags
Annotators
URL
-
-
medium.com medium.com
-
Don’t forget to tell Git who you are, add this cell so you don’t have to answer every time you commit during a new session!
Authenticate yourself with GitHub:
!git config --global user.email <YOUR EMAIL> !git config --global user.name <YOUR NAME>
-
- Jul 2020
-
lwn.net lwn.net
-
"that text has been removed from the official version on the Apache site." This itself is also not good. If you post "official" records but then quietly edit them over time, I have no choice but to assume bad faith in all the records I'm shown by you. Why should I believe anything Apache board members claim was "minuted" but which in fact it turns out they might have just edited into their records days, weeks or years later? One of the things I particularly watch for in modern news media (where no physical artefact captures whatever "mistakes" are published as once happened with newspapers) is whether when they inevitably correct a mistake they _acknowledge_ that or they instead just silently change things.
-
If the reality is you pushed out a release that doesn't even compile, and then you spotted the typo six minutes later, that's fine, that's what the git repo should show. Don't come to me asking if there's a way to change history so that it seems as if it didn't happen that way. How does that help anybody?
To answer your question:
How does that help anybody?
It keeps the history clean.
Assuming they push up an amended commit minutes after the bad commit, this shouldn't cause too much of a problem. (Depends how many people are working on it and how often they git pull.)
How does it help anyone to keep 2 separate commits that, semantically, could and should have been just 1? How does it help anyone to have a permanent record of someone's mistake?
If it can be easily and quickly fixed, I say go for it!
-
-
git.vger.kernel.narkive.com git.vger.kernel.narkive.com
-
unix.stackexchange.com unix.stackexchange.com
-
If we do not care about untracked files in the working directory, we can use the --untracked-files=no option to disregard those:
-
-
github.com github.com
Tags
Annotators
URL
-
-
-
This commit does not belong to any branch on this repository.
How would I download this commit/changeset with a git client then?? Or is it simply the case that if someone ever deletes the source branch for a merge request and "orphans" those commits, that there is now no longer a way to download it via the usual git fetch methods and the only way now to view these commits is via the web interface?
Idea: Create a permanent tag for every version of every pull request that gets pushed up. (Which maybe the already do internally to prevent it from being GC'd?)
https://github.com/ruby/ruby/pull/1758
Ana06 deleted the Ana06:array-diff branch on Apr 30, 2019
-
-
git-annex.branchable.com git-annex.branchable.com
Tags
Annotators
URL
-
- Jun 2020
-
ljvmiranda921.github.io ljvmiranda921.github.io
-
Automate Python workflow using pre-commits: black and flake8
Super helpful how-to-guide for git pre-commit hooks.
-
-
docs.gitlab.com docs.gitlab.com
-
uses a pre-clone step to seed the project with a recent archive of the repository. This is done for several reasons: It speeds up builds because a 800 MB download only takes seconds, as opposed to a full Git clone.
-
- May 2020
-
psyarxiv.com psyarxiv.com
-
Peikert, A., & Brandmaier, A. M. (2019). A Reproducible Data Analysis Workflow with R Markdown, Git, Make, and Docker. https://doi.org/10.31234/osf.io/8xzqy
-
-
stackoverflow.com stackoverflow.com
-
echo "${BASH_REMATCH[1]/:\/\//://gitlab-ci-token:${GL_TOKEN:-$GITLAB_TOKEN}@}" > $HOME/.config/git/credentials
-
git config --global credential.helper store
What does this do?
-
-
www.hostgator.com www.hostgator.com
-
After the initial backup, future backups are differential, both in the files that are transferred and the files that are stored on your behalf.
I guess git can help with the differential part of the backup, but how exactly does it? In order for it to help with transfer from the subject server, wouldn't it have to keep the git repo on that server? Otherwise wouldn't it have to transfer everything to the remote cloud git repo so that git can do the diff there?
Makes me wonder if simple rsync wouldn't be more efficient than all this.
-
the files are then transferred over the to git repository onto the cloud server.
-
-
codeguard.zendesk.com codeguard.zendesk.com
-
File pick up begins with an analysis of the file structure and creation of a git repository within Amazon’s Elastic Compute Cloud (EC2).
-
-
github.com github.com
-
github.com github.com
-
# Two commits are considered the same if they have the same tree and # the same commit and author metadata. This is how we re-identify # commits after their hash IDs have been rewritten.
-
-
stackoverflow.com stackoverflow.com
-
git describe [--tags] describes the current branch in terms of the commits since the most recent [possibly lightweight] tag in this branch's history. Thus, the tag referenced by git describe may NOT reflect the most recently created tag overall.
-
-
gitlab.com gitlab.com
-
What I think we're lacking is proper tooling, or at least the knowledge of it. I don't know what most people use to write Git commits, but concepts like interactive staging, rebasing, squashing, and fixup commits are very daunting with Git on the CLI, unless you know really well what you're doing. We should do a better job at learning people how to use tools like Git Tower (to give just one example) to rewrite Git history, and to produce nice Git commits.
-
-
github.com github.com
- Apr 2020
-
towardsdatascience.com towardsdatascience.com
-
Notebook files, however, are essentially giant JSON documents that contain the base-64 encoding of images and binary data. For a complex notebook, it would be extremely hard for anyone to read through a plaintext diff and draw meaningful conclusions—a lot of it would just be rearranged JSON and unintelligible blocks of base-64.
Git traces plaintext differences and with notebooks it's a problem
-
There is no hidden state or arbitrary execution order in a YAML file, and any changes you make to it can easily be tracked by Git
In comparison to notebooks, YAML is more compatible for Git and in the end might be a better solution for ML
-
-
stackoverflow.com stackoverflow.com
-
You are correct: by default, git log -p shows you the merge commit, but does not even attempt to show a diff for it.
-
-
-
in order to track the always-improving upstream project, we continuously rebase our patches on top of the upstream master
-
-
www.git-tower.com www.git-tower.com
-
git commit --amend --author="John Doe <john@doe.org>"
Update the author for a git commit
Tags
Annotators
URL
-
-
johnpapa.net johnpapa.net
-
gh repo create hello-world -d "A react app for the web" --public
GitHub released a new CLI: gh with which you can do much more operations.
For example, you can create repo without going into your browser:
gh repo create hello-world -d "A react app for the web" --publicGenerally, it will be great for CI/CD pipelines
Tags
Annotators
URL
-
-
-
git reflog is a very useful command in order to show a log of all the actions that have been taken! This includes merges, resets, reverts: basically any alteration to your branch.
Reflog - shows the history of actions in the repo.
With this information, you can easily undo changes that have been made to a repository with
git resetgit reflogSay that we actually didn't want to merge the origin branch. When we execute the git reflog command, we see that the state of the repo before the merge is at
HEAD@{1}. Let's perform a git reset to point HEAD back to where it was onHEAD@{1}! -
it pull is actually two commands in one: a git fetch, and a git merge. When we're pulling changes from the origin, we're first fetching all the data like we did with a git fetch, after which the latest changes are automatically merged into the local branch.
Pulling - downloads content from a remote branch/repository like
git fetchwould do, and automaticallymerges the new changesgit pull origin master -
It doesn't affect your local branch in any way: a fetch simply downloads new data.
Fetching - downloads content from a remote branch or repository without modifying the local state
git fetch origin master -
When a certain branch contains a commit that introduced changes we need on our active branch, we can cherry-pick that command! By cherry-picking a commit, we create a new commit on our active branch that contains the changes that were introduced by the cherry-picked commit.
Cherry-picking - creates a new commit with the changes that the cherry-picked commit introduced.
By default, Git will only apply the changes if the current branch does not have these changes in order to prevent an empty commit
git cherry-pick 76d12 -
Another way of undoing changes is by performing a git revert. By reverting a certain commit, we create a new commit that contains the reverted changes!
Reverting - reverts the changes that commits introduce. Creates a new commit with the reverted changes
git revert ec5be -
Sometimes, we don't want to keep the changes that were introduced by certain commits. Unlike a soft reset, we shouldn't need to have access to them any more.
Hard reset - points
HEADto the specified commit.Discards changes that have been made since the new commit that
HEADpoints to, and deletes changes in working directorygit reset --hard HEAD~2 git status -
git rebase copies the commits from the current branch, and puts these copied commits on top of the specified branch.
Rebasing - copies commits on top of another branch without creating a commit, which keeps a linear history.
Changes the history as new hashes are created for the copied commits.
git rebase masterA big difference compared to merging, is that Git won't try to find out which files to keep and not keep. The branch that we're rebasing always has the latest changes that we want to keep! You won't run into any merging conflicts this way, and keep a nice linear Git history.
Rebasing is great whenever you're working on a feature branch, and the master branch has been updated.
-
This can happen when the two branches we're trying to merge have changes on the same line in the same file, or if one branch deleted a file that another branch modified, and so on.
Merge conflict - you have to decide from which branch to keep the change.
After:
git merge devGit will notify you about the merge conflict so you can manually remove the changes you don't want to keep, save them, and then:
git add updated_file.md git commit -m "Merge..." -
If we committed changes on the current branch that the branch we want to merge doesn't have, git will perform a no-fast-forward merge.
No-fast-forward merge - default behavior when current branch contains commits that the merging branch doesn't have.
Create a new commit which merges two branches together without modifying existing branches.
git merge dev -
fast-forward merge can happen when the current branch has no extra commits compared to the branch we’re merging.
Fast-forward merge - default behavior when the branch has all of the current branch's commits.
Doesn't create a new commit, thus doesn't modify existing branches.
git merge dev -
soft reset moves HEAD to the specified commit (or the index of the commit compared to HEAD), without getting rid of the changes that were introduced on the commits afterward!
Soft reset - points
HEADto the specified commit.Keeps changes that have been made since the new commit the
HEADpoints to, and keeps the modifications in the working directorygit reset --soft HEAD~2 git status -
git reset gets rid of all the current staged files and gives us control over where HEAD should point to.
Reset - way to get rid of unwanted commits. We have soft and hard reset
-
There are 6 actions we can perform on the commits we're rebasing
Interactive rebase - makes it possible to edit commits before rebasing.
Creates new commits for the edited commits which history has been changed.
6 actions (options) of interactive rebase:
reword: Change the commit messageedit: Amend this commitsquash: Meld commit into the previous commitfixup: Meld commit into the previous commit, without keeping the commit's log messageexec: Run a command on each commit we want to rebasedrop: Remove the commit
git rebase -i HEAD~3
-
- Mar 2020
-
git-lfs.github.com git-lfs.github.com
-
-
victorzhou.com victorzhou.com
-
git config --global alias.s status
Replace
git statuswithgit s:git config --global alias.s statusIt will modify config in
.gitconfigfile.Other set of useful aliases:
[alias] s = status d = diff co = checkout br = branch last = log -1 HEAD cane = commit --amend --no-edit lo = log --oneline -n 10 pr = pull --rebaseYou can apply them (^) with:
git config --global alias.s status git config --global alias.d diff git config --global alias.co checkout git config --global alias.br branch git config --global alias.last "log -1 HEAD" git config --global alias.cane "commit --amend --no-edit" git config --global alias.pr "pull --rebase" git config --global alias.lo "log --oneline -n 10" -
alias g=git
alias g=gitThis command will let you type
g sin your shell to checkgit status
-
-
fatbusinessman.com fatbusinessman.com
-
The best commit messages I’ve seen don’t just explain what they’ve changed: they explain why
Proper commits:
- explains the reason for the change
- is searchable (contains the error message)
- tells a story (explains investigation process)
- makes everyone a little smarter
- builds compassion and trust (adds an extra bit of human context)
Tags
Annotators
URL
-
-
yvonnickfrin.dev yvonnickfrin.dev
-
If you use practices like pair or mob programming, don't forget to add your coworkers names in your commit messages
It's good to give a shout-out to developers who collaborated on the commit. For example:
$ git commit -m "Refactor usability tests. > > Co-authored-by: name <name@example.com> Co-authored-by: another-name <another-name@example.com>" -
I'm fond of gitmoji commit convention. It lies on categorizing commits using emojies. I'm a visual person so it fits well to me but I understand this convention is not made for everyone.
You can add gitmojis (emojis) in your commits, such as:
:recycle: Make core independent from the git client (#171) :whale: Upgrade Docker image version (#167)which will transfer on GitHub/GitLab to:
♻️ Make core independent from the git client (#171) 🐳 Upgrade Docker image version (#167) -
Separate subject from body with a blank line Limit the subject line to 50 characters Capitalize the subject line Do not end the subject line with a period Use the imperative mood in the subject line Wrap the body at 72 characters Use the body to explain what and why vs. how
7 rules of good commit messages.
Tags
Annotators
URL
-
-
blog.axosoft.com blog.axosoft.com
-
Don’t commit directly to the master or development branches. Don’t hold up work by not committing local branch changes to remote branches. Never commit application secrets in public repositories. Don’t commit large files in the repository. This will increase the size of the repository. Use Git LFS for large files. Learn more about what Git LFS is and how to utilize it in this advanced Learning Git with GitKraken tutorial. Don’t create one pull request addressing multiple issues. Don’t work on multiple issues in the same branch. If a feature is dropped, it will be difficult to revert changes. Don’t reset a branch without committing/stashing your changes. If you do so, your changes will be lost. Don’t do a force push until you’re extremely comfortable performing this action. Don’t modify or delete public history.
Git Don'ts
-
Create a Git repository for every new project. Learn more about what a Git repo is in this beginner Learning Git with GitKraken tutorial. Always create a new branch for every new feature and bug. Regularly commit and push changes to the remote branch to avoid loss of work. Include a gitignore file in your project to avoid unwanted files being committed. Always commit changes with a concise and useful commit message. Utilize git-submodule for large projects. Keep your branch up to date with development branches. Follow a workflow like Gitflow. There are many workflows available, so choose the one that best suits your needs. Always create a pull request for merging changes from one branch to another. Learn more about what a pull request is and how to create them in this intermediate Learning Git with GitKraken tutorial. Always create one pull request addressing one issue. Always review your code once by yourself before creating a pull request. Have more than one person review a pull request. It’s not necessary, but is a best practice. Enforce standards by using pull request templates and adding continuous integrations. Learn more about enhancing the pull request process with templates. Merge changes from the release branch to master after each release. Tag the master sources after every release. Delete branches if a feature or bug fix is merged to its intended branches and the branch is no longer required. Automate general workflow checks using Git hooks. Learn more about how to trigger Git hooks in this intermediate Learning Git with GitKraken tutorial. Include read/write permission access control to repositories to prevent unauthorized access. Add protection for special branches like master and development to safeguard against accidental deletion.
Git Dos
-
-
-
To add the .gitattributes to the repo first you need to create a file called .gitattributes into the root folder for the repo.
With such a content of .gitattributes:
*.js eol=lf *.jsx eol=lf *.json eol=lfthe end of line will be the same for everyone
-
On the Windows machine the default for the line ending is a Carriage Return Line Feed (CRLF), whereas on Linux/MacOS it's a Line Feed (LF).
Thar is why you might want to use .gitattributes to prevent such differences.
On Windows Machine if
endOfLineproperty is set tolf{ "endOfLine": "lf" }On the Windows machine the developer will encounter linting issues from prettier:
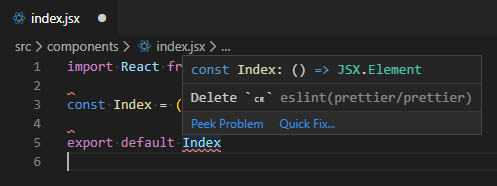
-
The above commands will now update the files for the repo using the newly defined line ending as specified in the .gitattributes.
Use these lines to update the current repo files:
git rm --cached -r . git reset --hard
-
- Feb 2020
-
lwn.net lwn.net
Tags
Annotators
URL
-
- Jan 2020
-
www.braintreepayments.com www.braintreepayments.com
Tags
Annotators
URL
-
-
codewords.recurse.com codewords.recurse.com
-
This command creates a new blob with the new content. And it updates the index entry for data/number.txt to point at the new blob.
-
They make the correction and add the file to the index again
-
-
askubuntu.com askubuntu.com
-
git -c core.sshCommand="ssh -vvv" pull
This seems like the most reliable and direct way to enable debugging of the ssh connection (authentication, etc.) used by a git command.
-
-
www.ruby-lang.org www.ruby-lang.org
-
We don’t use merge commits.
-
-
- Dec 2019
-
rubydoc.tenderapp.com rubydoc.tenderapp.com
-
Rubydoc.info can automatically fetch and rebuild your docs from your github project everytime you commit! To add a post-receive (commit) hook to Github, simply select the official Rubydoc.info service hook from the list of service hooks in your project settings.
-
-
-
As GPG and Git are widely used, it relies on thoroughly tested and secure functionality.
-
-
stackoverflow.com stackoverflow.com
-
stackoverflow.com stackoverflow.com
-
git rebase --committer-date-is-author-date
-
-
debuggable.com debuggable.com
-
The url also contains an optional refspec (#v0.0.1) that tells npm which branch, commit, or in this case tag you want to have checked out.
-
-
github.com github.com
-
"neutrino-patch": "git+https://github.com/davidje13/neutrino-patch#semver:^1.0.1"
-
-
github.com github.com
-
npm install --save git+https://github.com/davidje13/neutrino-patch#semver:^1.0.1
-
- Nov 2019
-
-
-
medium.com medium.com
Tags
Annotators
URL
-
-
www.vogella.com www.vogella.com
Tags
Annotators
URL
-
-
about.gitlab.com about.gitlab.com
-
But in general the guideline is: code should be clean, history should be realistic.
-
many organizations end up with messy workflows, or overly complex ones.
-
-
If you push to a public branch you shouldn't rebase it since that makes it hard to follow what you're improving, what the test results were, and it breaks cherrypicking
-
- Sep 2019
-
arthurperret.fr arthurperret.fr
-
ritualistic
digital diary (when voluntary)
git commit -m 'What I did today'vs digital trail (when automated)
-
-
Tags
Annotators
URL
-
-
www.conventionalcommits.org www.conventionalcommits.org
-
-
docs.gitlab.com docs.gitlab.com
Tags
Annotators
URL
-
- Aug 2019
-
stackoverflow.com stackoverflow.com
-
I found adding a "prepare": "npm run build" to scripts fixed all my problems.
-
Update the package.json in your forked repo to add a postinstall element to scripts. In here, run whatever you need to get the compiled output (Preferred).
-
-
-
instead of prepublish, you'll need to use prepare, but this is otherwise as you'd expect.
-
-
-
docs.npmjs.com docs.npmjs.com
-
prepare: Run both BEFORE the package is packed and published, on local npm install without any arguments, and when installing git dependencies
-
-
stackoverflow.com stackoverflow.com
-
This is because it's not bundled at all, while the package expects an prebuilt version existing in dist.
-
-
-
With now more than 3000 modules, there are huge gaps in the quality of things you find in the npm registry. But more often than not, it's easy to find a module that is really close to what you need, except if it wasn't for that one bug or missing feature.
-
- Jun 2019
-
riedmann.dev riedmann.dev
-
- Mar 2019
-
www.thedevelopersconference.com.br www.thedevelopersconference.com.br
-
Implementando CI com GitLab
Ainda que os tópicos da prova LPI DevOps não cubram apenas o Git para a integração contínua (ele é usado especialmente em Source Code Management), é muito importante conhecer bem os conceitos de integração e entrega contínua cobertos nessa palestra. Eles estão nesse tópico:
701.4 Continuous Integration and Continuous Delivery
-
-
www.atlassian.com www.atlassian.com
Tags
Annotators
URL
-
- Dec 2018
-
nicolasgallagher.com nicolasgallagher.com
-
The syntax for using git checkout to update the working tree with files from a tree-ish is as follows: git checkout [-p|--patch] [<tree-ish>] [--] <pathspec>… Therefore, to update the working tree with files or directories from another branch, you can use the branch name pointer in the git checkout command. git checkout <branch_name> -- <paths> As an example, this is how you could update your gh-pages branch on GitHub (used to generate a static site for your project) to include the latest changes made to a file that is on the master branch. # On branch master git checkout gh-pages git checkout master -- myplugin.js git commit -m "Update myplugin.js from master"
-
- Nov 2018
-
medium.freecodecamp.org medium.freecodecamp.org
- Oct 2018
-
www.maxwellantonucci.com www.maxwellantonucci.com
-
Tags
Annotators
URL
-
-
lab.github.com lab.github.com
-
-
github.com github.com
-
-
Tags
Annotators
URL
-
- Jun 2018
-
swcarpentry.github.io swcarpentry.github.io
-
Windows Video Tutorial Download the Git for Windows installer. Run the installer and follow the steps bellow: Click on "Next". Click on "Next". Keep "Use Git from the Windows Command Prompt" selected and click on "Next". If you forgot to do this programs that you need for the workshop will not work properly. If this happens rerun the installer and select the appropriate option. Click on "Next". Keep "Checkout Windows-style, commit Unix-style line endings" selected and click on "Next". Keep "Use Windows' default console window" selected and click on "Next". Click on "Install". Click on "Finish". If your "HOME" environment variable is not set (or you don't know what this is): Open command prompt (Open Start Menu then type cmd and press [Enter]) Type the following line into the command prompt window exactly as shown: setx HOME "%USERPROFILE%" Press [Enter], you should see SUCCESS: Specified value was saved. Quit command prompt by typing exit then pressing [Enter] This will provide you with both Git and Bash in the Git Bash program.
Instruções de instalção do git para windows
-
- Apr 2018
-
mybinder.org mybinder.orgbinder1
-
Turn a GitHub repo into a collection of interactive notebooks
Tags
Annotators
URL
-
-
www.liaoxuefeng.com www.liaoxuefeng.com创建与合并分支3
-
如何将开发的分支代码,merge到主干上?
- 创建新分支开发
$ git checkout -b dev
- 在新分支下新增测试文件
$ echo 'Readme' > ./readme.txt
$ git add readme.text
- 将文件提交到分支
$ git commit -m "dev branch test"
- 分支开发工作完成,我们现在可以切回 master 分支
$ git checkout master
- 将 dev 分支的工作成果合并到 master 分支上
$ git merge dev
- 合并完成之后,dev 分支没有作用就可以放心删除了
$ git branch -d dev
- 删除后,查看剩余分支列表,就只剩下 master 分支了
$ git branch
-
git checkout -b dev
创建新的开发分支进行开发,与下面一组命令相同
$ git branch dev $ git checkout dev
-
$ git branch dev $ git checkout dev Switched to branch 'dev'
$$git checkout$$
命令加上 \(-b\) 参数表示创建并切换
该命令与 \(git checkout -b dev\) 相同
-
- Feb 2018
-
swcarpentry.github.io swcarpentry.github.io
-
log --patch
same as
git show -
We could also use git show which shows us what changes we made at an older commit as well as the commit message, rather than the differences between a commit and our working directory that we see by using git diff.
showas in "show me what I did"diffas in "difference between working directory and ..."
Tags
Annotators
URL
-
-
www.draconianoverlord.com www.draconianoverlord.com
-
you’ll need to know up front that you want your commit applied into multiple places, so that you can place it on its own branch
More specifically, you'll need to know up front all the places you want your patch commit applied into so that you can determine where to start the patch branch from.
-
if you can anticipate where a commit may/will be need to applied
This is an important assumption.
The way I understand it, cherry picking is intended to be used in case of unanticipated migration of code.
-
its own branch
The patch branch should start at a common ancestor of all the target branches. Since the broken code is in all the target branches, it must be in at least one of their common ancestors.
If we don't start from a common ancestor and merge the patch into all the target branches, at least one of the target branches will get some extra change along with the patch.
-
- Jan 2018
-
jeffkreeftmeijer.com jeffkreeftmeijer.com
-
it's cleaner to use rebase to bring your outdated feature branch up to speed with develop, rather than merging develop into your feature branch.
-
- Dec 2017
-
blogs.tib.eu blogs.tib.eu
-
who collected / edited / published
git log & blame
-
- Nov 2017
-
www.ruanyifeng.com www.ruanyifeng.com
-
$ git log -p [file]
显示指定文件相关的每一次diff
显示效果如下,但会显示高亮:
commit 32e0c4f6bbb91617126b1cf2ab8c403ce7691ffe Author: lishuailong <lishuailong@baidu.com> Date: Tue Jul 11 15:14:59 2017 +0800 delete by loc diff --git a/bin/server_control b/bin/server_control index 6d81daa..4cf5106 100755 --- a/bin/server_control +++ b/bin/server_control @@ -48,7 +48,7 @@ function cleanup() { function realtime_cleanup() { mkdir -p ../realtime_delete/data DATE_TO_CLEANUP=`date +"%Y%m%d" -d "-7 days"` - cat ../data/*${DATE_TO_CLEANUP}*.succ | $PYTHON_BIN delete_succ.py 2> ../log/realtime_cleanup.log + cat ../data/*${DATE_TO_CLEANUP}*.succ | $PYTHON_BIN delete.py --format json 2> ../log/realtime_cleanup.log rm -f ../data/*${DATE_TO_CLEANUP}* } commit 47a2565e033dc1ed60a0ffd4df5e760dbcaebad8 Author: lishuailong <lishuailong@baidu.com> Date: Thu Jul 6 16:18:47 2017 +0800 fix realtime cleanup diff --git a/bin/server_control b/bin/server_control index 13b756f..6d81daa 100755 --- a/bin/server_control +++ b/bin/server_control @@ -48,7 +48,7 @@ function cleanup() { function realtime_cleanup() { mkdir -p ../realtime_delete/data DATE_TO_CLEANUP=`date +"%Y%m%d" -d "-7 days"` - cat ../data/*${DATE_TO_CLEANUP}.succ | $PYTHON_BIN delete_succ.py 2> ../log/realtime_cleanup.log + cat ../data/*${DATE_TO_CLEANUP}*.succ | $PYTHON_BIN delete_succ.py 2> ../log/realtime_cleanup.log rm -f ../data/*${DATE_TO_CLEANUP}* }
Tags
Annotators
URL
-
-
nvie.com nvie.com
-
exists as long as the feature is in development
When the development of a feature takes a long time, it may be useful to continuously merge from
developinto the feature branch. This has the following advantages:- We can use the new features introduced in
developin the feature branch. - We simplify the integration merge of the feature branch into
developthat will happen at a later point.
- We can use the new features introduced in
-
- Feb 2017
-
git-merge.com git-merge.com
-
Jedi Mind Tricks for Git
@jankrag & @randomsort (slides, demo-repo)
Principles which are supported by hooks presented here
- never commit on master
- always reference an issue in commit message (via GitHub API)
- #serverless, #noOps & delivery through ready-branches
- hook manager: overcommit (via)
attributes + drivers to improve
diff- hexdump binaries
- convert .docx to .md
- line-wrap paragraphs
- metadata of images or audio
- ASCI-ize image
- xls2csv, unzip
filter drivers (process BLObs on save or checkout)
- enforce lint-/formatting
- Caesar's obfuscation
also: @_flexbox's sketch notes
-
Git Simple: Writing primary git functionalities in Ruby
-
Repo 911
repo, BFG & LFS; also @_flexbox's sketch notes
-
Git and the Terrible, Horrible, No Good, Very Bad Day
git clone https://github.com/hectorsector/git-and-the-bad-day.gitgit lol= aliasgit log --onelineplus which other options?git diffwith..vs...? one is against merge base- when pushed credentials, change them before filtering, contacting support to clear caches, or other due diligence
- ohshitgit.com
also: @_flexbox's sketch notes
-
The Battle for Sub-premacy
with @kylemacey, see @_flexbox's sketch notes
-