一个短视频APP视频内容安全审核的思路调研及实现汇总
https://github.com/minitrill/VideoAudit 有很多代码,很不错~!
一个短视频APP视频内容安全审核的思路调研及实现汇总
https://github.com/minitrill/VideoAudit 有很多代码,很不错~!
基于nude(裸露程度)的色情图片识别 nudepy 这个库基本上可以视为上述方法的威力加强版 库内通过c语言实现了一个皮肤分类器,并基于较复杂的裸露程度来判别图片是否是色情图片 说明程序入口见pic_classify_nude.py,这里主要是对于nude库的封装 >>>from pic_classify_nude import test >>> >>>test('1.png') # 判断色情图片T/F True
还不错的入门级方案。
100 000+ datapoints). This library solves this by downsampling the signal for the currently selected time window and then plotting the downsampled points.
Optimization plotting library.
I’d probably choose the official Docker Python image (python:3.9-slim-bullseye) just to ensure the latest bugfixes are always available.
python:3.9-slim-bullseye may be the sweet spot for a Python Docker image
So which should you use? If you’re a RedHat shop, you’ll want to use their image. If you want the absolute latest bugfix version of Python, or a wide variety of versions, the official Docker Python image is your best bet. If you care about performance, Debian 11 or Ubuntu 20.04 will give you one of the fastest builds of Python; Ubuntu does better on point releases, but will have slightly larger images (see above). The difference is at most 10% though, and many applications are not bottlenecked on Python performance.
Choosing the best Python base Docker image depends on different factors.
There are three major operating systems that roughly meet the above criteria: Debian “Bullseye” 11, Ubuntu 20.04 LTS, and RedHat Enterprise Linux 8.
3 candidates for the best Python base Docker image
If we call this using Bash, it never gets further than the exec line, and when called using Python it will print lol as that's the only effective Python statement in that file.
#!/bin/bash
"exec" "python" "myscript.py" "$@"
print("lol")
For Python the variable assignment is just a var with a weird string, for Bash it gets executed and we store the result.
__PYTHON="$(command -v python3 || command -v python)"
x() is the same as doing x.__call__()
How do you even begin to check if you can try and “call” a function, class, and whatnot? The answer is actually quite simple: You just see if the object implements the __call__ special method.
Use of __call__
Python is referred to as a “duck-typed” language. What it means is that instead of caring about the exact class an object comes from, Python code generally tends to check instead if the object can satisfy certain behaviours that we are looking for.
everything is stored inside dictionaries. And the vars method exposes the variables stored inside objects and classes.
Python stores objects, their variables, methods and such inside dictionaries, which can be checked using vars()
>>> page = Page.objects.get(title="A Blog post") >>> page <Page: A Blog post> # Note: the blog post is an instance of Page so we cannot access body, date or feed_image >>> page.specific <BlogPage: A Blog post>
You can convert a Page object to its more specific user-defined equivalent using the .specific property. This may cause an additional database lookup.
Use settings to change the default templates used for each tag Specify templates using template and sub_menu_template arguments for any of the included menu tags (See Specifying menu templates using template tag parameters). Put your templates in a preferred location within your project and wagtailmenus will pick them up automatically (See Using preferred paths and names for your templates).
Dónde especificar las plantillas para los menús. Si no usas las tuyas, el paquete usa plantillas por defecto usando bootstrap3
While main menus always have to be defined for each site, for flat menus, you can support multiple sites using any of the following approaches: Define a new menu for each site Define a menu for your default site and reuse it for the others Create new menus for some sites, but use the default site’s menu for others You can even use different approaches for different flat menus in the same project. If you’d like to learn more, take a look at the fall_back_to_default_site_menus option in Supported arguments
Usar main menu o flat menu en wagtail
Have you noticed how the aricle pages are not shown below the ‘Latest news’ item, despite specifying allow_subnav=True on the menu item? Only pages with a show_in_menus value of True will be displayed (at any level) in rendered menus. The field is added by Wagtail, so is present for all custom page types. For page types that are better suited to showing on listing/index pages (for example: news articles or events) - you can set the show_in_menus_default attribute on the page type class to False to exclude them from menus by default.
Configuraciones básicas de wagtailmenus para que se muestren o no
indent=True here is treated as indent=1, so it works, but I’m pretty sure nobody would intend that to mean an indent of 1 space
bool is actually not a primitive data type — it’s actually a subclass of int!
Python has only 5 primitives
complex is a supertype of float, which, in turn, is a supertype of int.
On some of Python's primitives
Now since the “compiling to bytecode” step above takes a noticeable amount of time when you import a module, Python stores (marshalls) the bytecode into a .pyc file, and stores it in a folder called __pycache__. The __cached__ parameter of the imported module then points to this .pyc file.When the same module is imported again at a later time, Python checks if a .pyc version of the module exists, and then directly imports the already-compiled version instead, saving a bunch of time and computation.
Python takes benefit of caching imports
Bytecode is a set of micro-instructions for Python’s virtual machine. This “virtual machine” is where Python’s interpreter logic resides. It essentially emulates a very simple stack-based computer on your machine, in order to execute the Python code written by you.
What bytecode does
Python is compiled. In fact, all Python code is compiled, but not to machine code — to bytecode
Python is compiled to bytecode
Python always runs in debug mode by default.The other mode that Python can run in, is “optimized mode”. To run python in “optimized mode”, you can invoke it by passing the -O flag. And all it does, is prevents assert statements from doing anything (at least so far), which in all honesty, isn’t really useful at all.
Python debug vs optimized mode
np = __import__('numpy') # Same as doing 'import numpy as np'
This refers to the module spec. It contains metadata such as the module name, what kind of module it is, as well as how it was created and loaded.
__spec__
let’s say you only want to support integer addition with this class, and not floats. This is where you’d use NotImplemented
Example use case of NotImplemented:
class MyNumber:
def __add__(self, other):
if isinstance(other, float):
return NotImplemented
return other + 42
__radd__ operator, which adds support for right-addition
class MyNumber:
def __add__(self, other):
return other + 42
def __radd__(self, other):
return other + 42
Now I should mention that all objects in Python can add support for all Python operators, such as +, -, +=, etc., by defining special methods inside their class, such as __add__ for +, __iadd__ for +=, and so on.
For example:
class MyNumber:
def __add__(self, other):
return other + 42
and then:
>>> num = MyNumber()
>>> num + 3
45
NotImplemented is used inside a class’ operator definitions, when you want to tell Python that a certain operator isn’t defined for this class.
NotImplemented constant in Python
Doing that would even catch KeyboardInterrupt, which would make you unable to close your program by pressing Ctrl+C.
except BaseException: ...
every exception is a subclass of BaseException, and nearly all of them are subclasses of Exception, other than a few that aren’t supposed to be normally caught.
on Python's exceptions
print(dir(__builtins__))
command to get all the builtins
builtin scope in Python:It’s the scope where essentially all of Python’s top level functions are defined, such as len, range and print.When a variable is not found in the local, enclosing or global scope, Python looks for it in the builtins.
builtin scope (part of LEGB rule)
Global scope (or module scope) simply refers to the scope where all the module’s top-level variables, functions and classes are defined.
Global scope (part of LEGB rule)
you can use the nonlocal keyword in Python to tell the interpreter that you don’t mean to define a new variable in the local scope, but you want to modify the one in the enclosing scope.
nonlocal
The enclosing scope (or nonlocal scope) refers to the scope of the classes or functions inside which the current function/class lives.
Enclosing scope (part of LEGB rule)
The local scope refers to the scope that comes with the current function or class you are in.
Local scope (part of LEGB rule)
A builtin in Python is everything that lives in the builtins module.
Python's builtin
in Python 3.0 (alongside 2.6), A new method was added to the str data type: str.format. Not only was it more obvious in what it was doing, it added a bunch of new features, like dynamic data types, center alignment, index-based formatting, and specifying padding characters.
History of str.format in Python
playground https://regex101.com/
TypedDict is a dictionary whose keys are always string, and values are of the specified type. At runtime, it behaves exactly like a normal dictionary.
TypedDict
you should only use reveal_type to debug your code, and remove it when you’re done debugging.
Because it's only used by mypy
What this says is “function double takes an argument n which is an int, and the function returns an int.
def double(n: int) -> int:
This tells mypy that nums should be a list of integers (List[int]), and that average returns a float.
from typing import List
def average(nums: List[int]) -> float:
for starters, use mypy --strict filename.py
If you're starting your journey with mypy, use the --strict flag
If no explicit epoch is given, the implicit epoch is 0.
That is a very bad decision for pep-440 - when no epoch specified, it should have implied the latest!
You probably shouldn't use Alpine for Python projects, instead use the slim Docker image versions.
(have a look below this highlight for a full reasoning)
Before we dive into the details, here's a brief summary of the most important changes:
List of the most important upcoming Python 3.10 features (see below)
Python Examples
مثال هاي پايتون
The models are developed in Python [46], using the Keras [47] and Tensorflow [48] libraries. Detailson the code and dependencies to run the experiments are listed in a Readme file available togetherwith the code in the Supplemental Material.
I have not found the code or Readme file
Export/takeout for your personal Hypothes.is data: annotations and profile information.
Python batch-file approach for exporting from hypothesis.
exporting hypothesis annotations to obsidian (markdown files)
CLI-based method for batch exporting hypothesis annotations in markdown suitable for adding to Obsidian. I'm not sure I like it; the idea of batch-filing the process irks me. I would prefer for it to all happen in the background.
Some problems with the feature
Chapter with list of problems pattern matching brings to Python 3.10
One thing to note is that match and case are not real keywords but “soft keywords”, meaning they only operate as keywords in a match ... case block.
match and case are soft keywords
Use variable names that are set if a case matches Match sequences using list or tuple syntax (like Python’s existing iterable unpacking feature) Match mappings using dict syntax Use * to match the rest of a list Use ** to match other keys in a dict Match objects and their attributes using class syntax Include “or” patterns with | Capture sub-patterns with as Include an if “guard” clause
pattern matching in Python 3.10 is like a switch statement + all these features
It’s tempting to think of pattern matching as a switch statement on steroids. However, as the rationale PEP points out, it’s better thought of as a “generalized concept of iterable unpacking”.
High-level description of pattern matching coming in Python 3.10
>>> import _ctypes>>> print(_ctypes.PyObj_FromPtr(4319088080))2077
Amazing tip ob how to extract a python-object from a a memory-pointer.
The best practice is this: #!/usr/bin/env bash #!/usr/bin/env sh #!/usr/bin/env python
The best shebang convention: #!/usr/bin/env bash.
However, at the same time it might a security risk if the $PATH to bash points to some malware. Maybe then it's better to point directly to it with #!/bin/bash
As python supports virtual environments, using /usr/bin/env python will make sure that your scripts runs inside the virtual environment, if you are inside one. Whereas, /usr/bin/python will run outside the virtual environment.
Important difference between /usr/bin/env python and /usr/bin/python
The tree obtained is the logical structure of the program, which is then converted to bytecode (.pyc or .pyo).
Python is often used as the programming language for many small-form devices, such as the Raspberry Pi and other microcontrollers
The Python programming language was created by Guido Von Rossum in 1991 and started with a previous language called ABC.
Here is a list of some open data available online. You can find a more complete list and details of the open data available online in Appendix B.
DataHub (http://datahub.io/dataset)
World Health Organization (http://www.who.int/research/en/)
European Union Open Data Portal (http://open-data.europa.eu/en/data/)
Amazon Web Service public datasets (http://aws.amazon.com/datasets)
Facebook Graph (http://developers.facebook.com/docs/graph-api)
Healthdata.gov (http://www.healthdata.gov)
Google Trends (http://www.google.com/trends/explore)
Google Finance (https://www.google.com/finance)
Google Books Ngrams (http://storage.googleapis.com/books/ngrams/books/datasetsv2.html)
Machine Learning Repository (http://archive.ics.uci.edu/ml/)
As an idea of open data sources available online, you can look at the LOD cloud diagram (http://lod-cloud.net ), which displays the connections of the data link among several open data sources currently available on the network (see Figure 1-3).
The second-to-last layer is what Han settled on as a reasonable sweet-spot.
Pretty arbitrary choice
Python is a high-level programming language that is object-oriented and used to create different desktop apps, different systems, websites, and platforms. This language might not be the most popular in the techno world, but it surely is the first choice for freshers and beginners.
Here's the guide to become a successful Python Developer
PyPA still advertises pipenv all over the place and only mentions poetry a couple of times, although poetry seems to be the more mature product.
Sounds like PyPA does not like poetry as much for political/business reasons
The main selling point for Anaconda back then was that it provided pre-compiled binaries. This was especially useful for data-science related packages which depend on libatlas, -lapack, -openblas, etc. and need to be compiled for the target system.
Reason why Anaconda got so popular
Many of Python’s standard tools allow already for configuration in pyproject.toml so it seems this file will slowly replace the setup.cfg and probably setup.py and requirements.txt as well. But we’re not there yet.
Potential future of pyproject.toml
Any import statement compiles to a series of bytecode instructions, one of which, called IMPORT_NAME, imports the module by calling the built-in __import__() function.
All the Python import statements come down to the __import__() function
databases is an async SQL query builder that works on top of the SQLAlchemy Core expression language.
databases Python package
The fact that FastAPI does not come with a development server is both a positive and a negative in my opinion. On the one hand, it does take a bit more to serve up the app in development mode. On the other, this helps to conceptually separate the web framework from the web server, which is often a source of confusion for beginners when one moves from development to production with a web framework that does have a built-in development server (like Django or Flask).
FastAPI does not include a web server like Flask. Therefore, it requires Uvicorn.
Not having a web server has pros and cons listed here
FastAPI makes it easy to deliver routes asynchronously. As long as you don't have any blocking I/O calls in the handler, you can simply declare the handler as asynchronous by adding the async keyword like so:
FastAPI makes it effortless to convert synchronous handlers to asynchronous ones
Fixtures are created when first requested by a test, and are destroyed based on their scope: function: the default scope, the fixture is destroyed at the end of the test.
Fixtures can be executed in 5 different scopes, where function is the default one:
When pytest goes to run a test, it looks at the parameters in that test function’s signature, and then searches for fixtures that have the same names as those parameters. Once pytest finds them, it runs those fixtures, captures what they returned (if anything), and passes those objects into the test function as arguments.
What happens when we include fixtures in our testing code
“Fixtures”, in the literal sense, are each of the arrange steps and data. They’re everything that test needs to do its thing.
To remind, the tests consist of 4 steps:
(pytest) fixtures are generally the arrange (set up) operations that need to be performed before the act (running the tests. However, fixtures can also perform the act step.
Here is how you can create a fully configured new project in a just a couple of minutes (assuming you have pyenv and poetry installed already).
Fast track setup of a new Python project
After reading through PEP8, you may wonder if there is a way to automatically check and enforce these guidelines? Flake8 does exactly this, and a bit more. It works out of the box, and can be configured in case you want to change some specific settings.
Flake8 does PEP8 and a bit more
Pylint is a very strict and nit-picky linter. Google uses it for their Python projects internally according to their guidelines. Because of it’s nature, you’ll probably spend a lot of time fighting or configuring it. Which is maybe not bad, by the way. Outcome of such strictness can be a safer code, however, as a consequence - longer development time.
Pylint is a very strict linter embraced by Google
The goal of this tutorial is to describe Python development ecosystem.
tl;dr:
INSTALLATION:
TESTING:
REFACTORING:
For Windows, there is pyenv for Windows - https://github.com/pyenv-win/pyenv-win. But you’d probably better off with Windows Subsystem for Linux (WSL), then installing it the Linux way.
You can install pyenv for Windows, but maybe it's better to go the WSL way
There are often multiple versions of python interpreters and pip versions present. Using python -m pip install <library-name> instead of pip install <library-name> will ensure that the library gets installed into the default python interpreter.
Potential solution for the Python's ImportError after a successful pip installation
In addition to SQLAlchemy core queries, you can also perform raw SQL queries
Instead of SQLAlchemy core query:
query = notes.insert()
values = [
{"text": "example2", "completed": False},
{"text": "example3", "completed": True},
]
await database.execute_many(query=query, values=values)
One can write a raw SQL query:
query = "INSERT INTO notes(text, completed) VALUES (:text, :completed)"
values = [
{"text": "example2", "completed": False},
{"text": "example3", "completed": True},
]
await database.execute_many(query=query, values=values)
=================================
The same goes with fetching in SQLAlchemy:
query = notes.select()
rows = await database.fetch_all(query=query)
And doing the same with raw SQL:
query = "SELECT * FROM notes WHERE completed = :completed"
rows = await database.fetch_all(query=query, values={"completed": True})
If you're serious about neural networks, I have one recommendation. Try to rebuild this network from memory.
Some options (you will have to use your own judgment, based on your use case)
4 different options to install Poetry through a Dockerfile
Create an account or session
This is the process of using social login. Google/FB does the authentication part. Once the token has been confirmed, create a new access_token and refresh_token for the user like a normal user who logged in via email/password.
Uber and Booking.com’s ecosystem was originally JVM-based but they expanded to support Python models/scripts. Spotify made heavy use of Scala in the first iteration of their platform until they received feedback like:some ML engineers would never consider adding Scala to their Python-based workflow.
Python might be even more popular due to MLOps
ELIZA in Python
Integrated access to the pdb debugger and the Python profiler.
Python’s Significant Whitespace Problems
Really lousy attempt to discredit Python's ingenuity of binding content to form. Adequately replied by Roman Suzi.
TensorFlow.js provides theLayers API,which mirrors the Keras API as closely as possible, in-cluding the serialization format.
Surfing TensorFlow I was orbiting this conclusion. It's good to see it it stated clearly.
Uses Pydantic which enforces type hints at runtime.
pydantic used by FastAPIif a module's name has no dots, it is not considered to be part of a package. It doesn't matter where the file actually is on disk.
what if Python module's name has no dots
if you imported moduleX (note: imported, not directly executed), its name would be package.subpackage1.moduleX. If you imported moduleA, its name would be package.moduleA. However, if you directly run moduleX from the command line, its name will instead be __main__, and if you directly run moduleA from the command line, its name will be __main__. When a module is run as the top-level script, it loses its normal name and its name is instead __main__.
When Python's module name is __main__ vs when it's a full name (preceded by the names of any packages/subpackages of which it is a part, separated by dots)
A file is loaded as the top-level script if you execute it directly, for instance by typing python myfile.py on the command line. It is loaded as a module if you do python -m myfile, or if it is loaded when an import statement is encountered inside some other file.
3 cases when a Python file is called as a top-level script vs module
The majority of Python packaging tools also act as virtualenv managers to gain the ability to isolate project environments. But things get tricky when it comes to nested venvs: One installs the virtualenv manager using a venv encapsulated Python, and create more venvs using the tool which is based on an encapsulated Python. One day a minor release of Python is released and one has to check all those venvs and upgrade them if required. PEP 582, on the other hand, introduces a way to decouple the Python interpreter from project environments. It is a relative new proposal and there are not many tools supporting it (one that does is pyflow), but it is written with Rust and thus can't get much help from the big Python community. For the same reason it can't act as a PEP 517 backend.
The reason why PDM - Python Development Master may replace poetry or pipenv
However, the place where pip places that package might not be in your $PATH (thus requiring you to manually update your $PATH afterwards), and on windows the pip install might not take care of python-specific issues for you (see "Notes for Windows Users", above). As such, installation via package managers is recommended instead.
If your python3 executable is named "python" instead of "python3" (this particularly appears to affect a number of Windows users), then you'll also need to modify the first line of git-filter-repo to replace "python3" with "python".
you want to pass a function as an argument to higher-order functions
Functional programming - passing functions as arguments, as opposed to data objects.
Lambda functions are used when you need a function for a short period of time.
saves time writing (& maintaining, unit testing) private utility functions.
Cookiecutter takes a source directory tree and copies it into your new project. It replaces all the names that it finds surrounded by templating tags {{ and }} with names that it finds in the file cookiecutter.json. That’s basically it. [1]
The main idea behind cookiecutter
you can take the opportunity of using Python as a corresponding module pexpect is written for it (http://pexpect.sourceforge.net). It's clear that Python language should be installed on the system beforehand
Holy xxx, it takes 3.37s to calculate merely 1,000,000 reciprocal numbers. The same logic in C takes just a blink: 9ms; C# takes 19ms; Nodejs takes 26ms; Java takes 5ms! and Python takes self-doubting 3.37 SECONDS.
But numpy takes just 2ms!
As to why both is_a? and kind_of? exist: I suppose it's part of Ruby's design philosophy. Python would say there should only be one way to do something; Ruby often has synonymous methods so you can use the one that sounds better. It's a matter of preference.
I don't like notebooks.- Joel Grus (Allen Institute for Artificial Intelligence)
Because it teaches scientists bad programming habits:
%history works)

session.query(Book.author, Chapter.title).select_from(Book).join(Book.chapters) or session.query(Book).options(load_only("author"), joinedload("chapters").load_only("title"))
Very useful quick guide for how to only load certain foreign key fields.
Advanced profile tricks for python
McCabe, Stefan, Leo Torres, Timothy LaRock, Syed Arefinul Haque, Chia-Hung Yang, Harrison Hartle, and Brennan Klein. ‘Netrd: A Library for Network Reconstruction and Graph Distances’. ArXiv:2010.16019 [Physics], 29 October 2020. http://arxiv.org/abs/2010.16019.
PyPy uses a technique known as meta-tracing, which transforms an interpreter into a tracing just-in-time compiler.
Default: 0
padding's defautl value ==0
You can use container values, that wraps actual success or error value into a thin wrapper with utility methods to work with this value. That’s exactly why we have created @dry-python/returns project. So you can make your functions return something meaningful, typed, and safe.
I'm not a fan of listing exceptions functions can throw, especially here in Python, where it's easier to ask forgiveness than permission.
Interesting project to safely patch 3rdp libs, by detecting any breaking changes if/when the lib gets upgraded in the future.
Here is a quick recap table of every technology we discussed in this blog post.
Quick comparison of Python web scraping tools (socket, urlib3, requests, scrapy, selenium) [below this highlight]
We recommend the Alpine image as it is tightly controlled and small in size (currently under 5 MB), while still being a full Linux distribution. This is fine advice for Go, but bad advice for Python, leading to slower builds, larger images, and obscure bugs.
Alipne Linux isn't the most convenient OS for Python, but fine for Go
Did you know that everything you can do in VBA can also be done in Python? The Excel Object Model is what you use when writing VBA, but the same API is available in Python as well.See Python as a VBA Replacement from the PyXLL documentation for details of how this is possible.
We can replace VBA with Python
You can write Excel worksheet functions in your Jupyter notebook too. This is a really great way of trying out ideas without leaving Excel to go to a Python IDE.
We can define functions in Python to later use in Excel
Use the magic function “%xl_get” to get the current Excel selection in Python. Have a table of data in Excel? Select the top left corner (or the whole range) and type “%xl_get” in your Jupyter notebook and voila! the Excel table is now a pandas DataFrame.
%xl_get lets us get the current Excel selection in Python
to run Python code in Excel you need the PyXLL add-in. The PyXLL add-in is what lets us integrate Python into Excel and use Python instead of VBA
PyXLL lets us use Python/Jupyter Notebooks in Excel
Turning my Jupyter-compatible Python code into Flask-compatible Python code took dozens of hours. I ran into small bugs and errors
That's how I always expected Python notebook development to be
Comparison between pytest and unittes test frameworks
Detailed comparison table of pytest vs unittest modules (check below)
The behaviour of the argument function is extended by the decorator without actually modifying it.
需要修饰的函数被装饰器(decorator)扩展,且不用修改原函数.
As of Python 3.6, f-strings are a great new way to format strings.
Python 3.6 之后推出的 f-strings 语法
A location into which the result is stored.
out 参数是用来存放结果的 这样可以达到就地计算的效果
Text Sequence Type
文本序列类型
和 Python 里的字符串和列表切片不同,你不能在 start, stop 或者 step 这些参数中使用负数。:
通过 itertools.islice() 可以实现 set dict 的切片操作。
line.strip()
去掉字符串头和尾的空格
# A recursive generator that generates Tree leaves in in-order.
用生成器来写中序遍历
Any function containing a yield keyword is a generator function;
函数体里包含 yield 关键字的函数都是生成器函数
Generators
生成器
if expression is creating a tuple, it must be surrounded with parentheses.
如果表达式创建了一个元组,那么必须被圆括号包裹.
list comprehensions
List Comprehensions 列表推导
Generator Expressions 生成器表达式
An object is called iterable if you can get an iterator for it.
言外之意就是,如果调用 iter 之后没有报 TypeError, 说明该对象是可迭代的(iterable)
An iterator is an object representing a stream of data;
迭代器是一个代表数据流的对象
key 形参用来指定在进行比较前要在每个列表元素上调用的函数
与 C++ 不同,key 形参用来指定进行比较前在每个列表元素上调用的函数。
Sprawdźmy który rodzaj modelu daje najlepszą skuteczność: Python sns.boxplot(data=models_df, x='score', y='model') 1 sns.boxplot(data=models_df, x='score', y='model')
After comparing the pipelined ML models, we can easily display a comparison boxplot.
Well working ML models: 1) XGBoost 2) LightGBM 3) CatBoost.
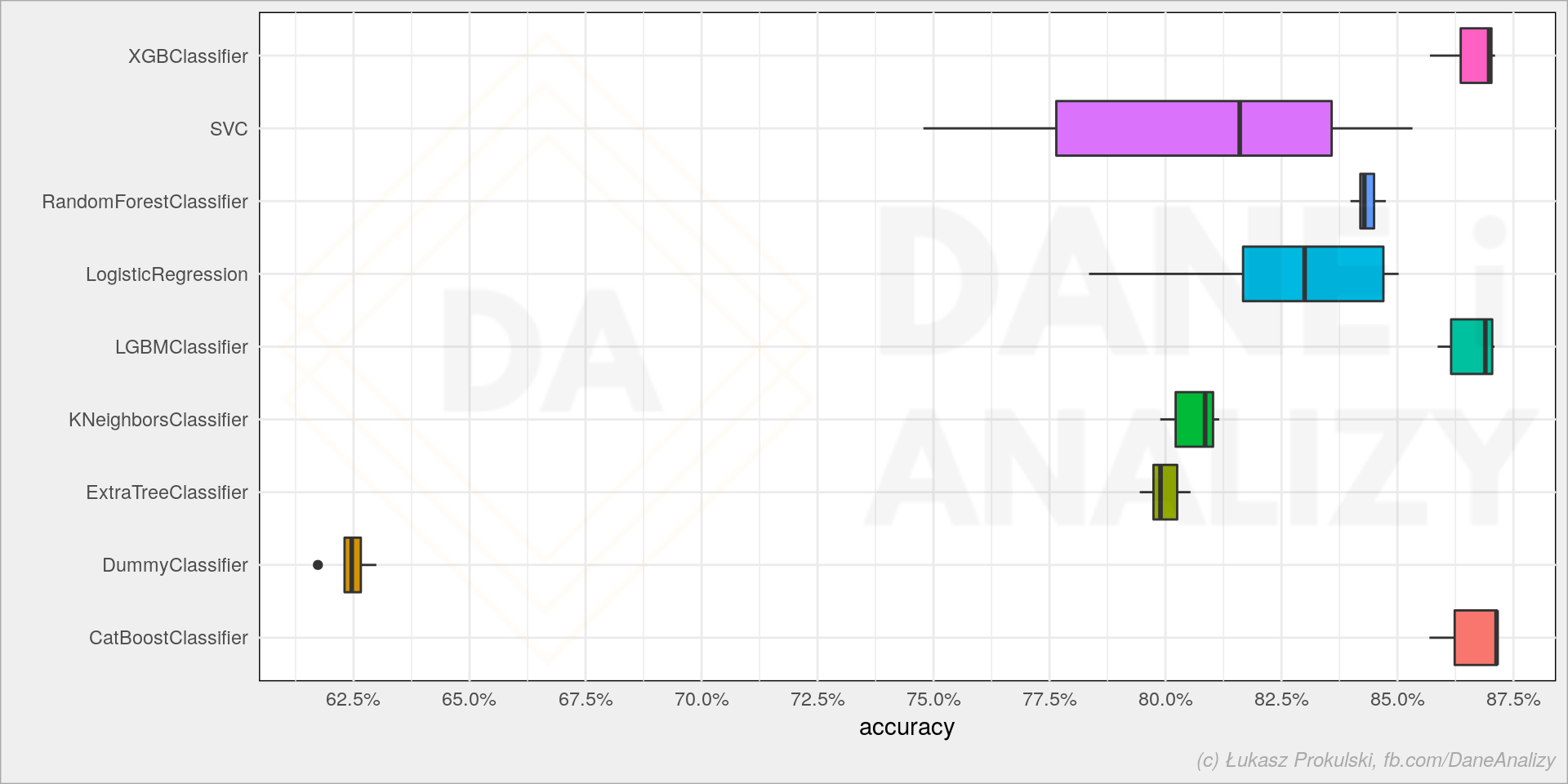
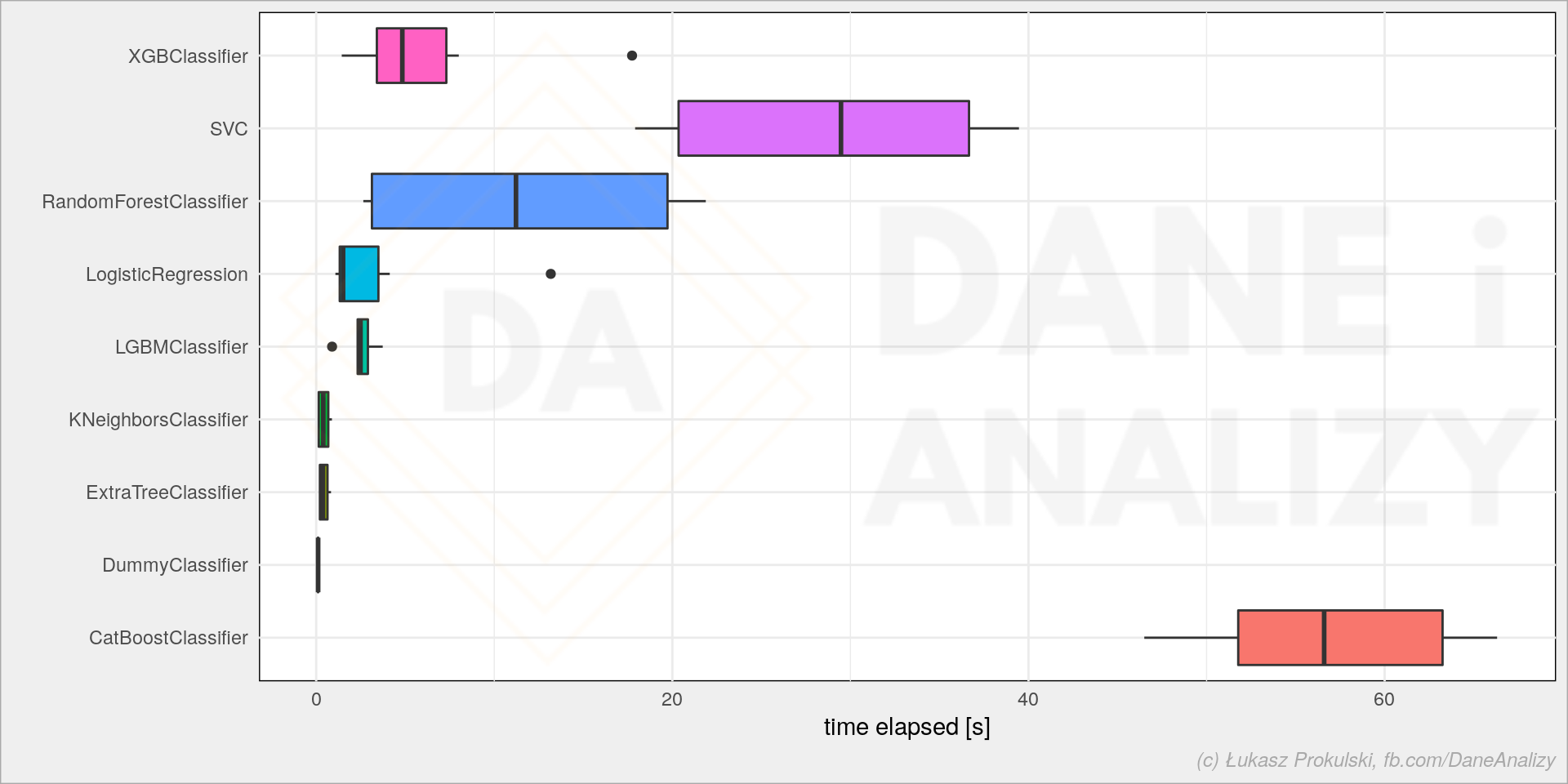
Przy tych danych wygląda, że właściwie nie ma większej różnicy (nie bijemy się tutaj o 0.01 punktu procentowego poprawy accuracy modelu). Może więc czas treningu jest istotny? Python sns.boxplot(data=models_df, x='time_elapsed', y='model') 1 sns.boxplot(data=models_df, x='time_elapsed', y='model')
Training time of some popular ML models. After considering the performance, it's worth using XGBoost and LightGBM.
Teraz w zagnieżdżonych pętlach możemy sprawdzić każdy z każdym podmieniając klasyfikatory i transformatory (cała pętla trochę się kręci):
Example (below) of when creating pipelines with scikit-learn makes sense. Basically, it's convenient to use it while comparing multiple models in a loop
hyperscript is more concise because it's just a function call and doesn't require a closing tag. Using it will greatly simplify your tooling chain.
I suppose this is also an argument that Python tries to make? That other languages have this con:
end or } ?Used by convention to avoid naming conflicts with Python keywords.
var_ 主要用来避免与关键字冲突
meant as a hint to the programmer only.
_var 这种单下划线对于解释器没有实际作用.程序员之间表示内部使用的公用做法
The second is a “throwaway” variable that we don’t need just yet, denoted with an underscore.
用下划线来表示没有用的变量
If <key> is not found, it returns None
.get(key) 如果键存在返回相应的值,否则返回 None
The len() function returns the number of key-value pairs in a dictionary
len 函数返回字典中键值对的个数
the in and not in operators
用来检查键值是否在字典中。
key values are simple strings
当键值都是简单字符串的时候,键可以不用引号包裹。
Restrictions on Dictionary Values
Python对 dict 的值没有限制, 可以是任意类型(包括可变类型和自定义对象)
it is not quite correct to say an object must be immutable to be used as a dictionary key.
一个对象必须是不可变的才能用作 dict 的键。
这句话不是很准确。 严谨的说,一个对象必须是可哈希(hashable) 的,才可以用作 dict 的键。
Restrictions on Dictionary Keys#
dict 键值的限制:
a dictionary key must be of a type that is immutable.
dict 键必须是不可修改的(immutable)
the values contained in the dictionary don’t need to be the same type.
dict 键和值的类型不必相同
Python does guarantee that the order of items in a dictionary is preserved.
尽管 Python 中访问字典元素与顺序无关, 但是 Python 会保存字典中元素定义的顺序(Python 3.7 引入的新特性).
they have nothing to do with the order of the items in the dictionary.
Python 中字典同样可以通过数字来访问,但是与列表不同的是,数字大小与元素的顺序没有关系.
If you refer to a key that is not in the dictionary, Python raises an exception:
https://realpython.com/python-defaultdict 可以参看这篇文章. defaultdict 可以处理 missing key 的情况.
Dictionary elements are not accessed by numerical index
注意: Python 中字典不能通过数字下标访问元素.
A list of tuples works well for this:
可以通过元素列表初始化字典.
dd = dict([('a',1),('b',2)])
Dictionaries and lists share the following characteristics:
Python 中字典和列表的相同点是:
Dictionaries differ from lists primarily in how elements are accessed:
Python 中字典与列表的不同点:
这篇文章主要介绍了 Python 中字典处理缺省键值的方法。
引入了一个新的数据类型 defaultdict,并介绍了它访问和修改不存在键值时的机制。
主要是重写了 .missing__() 使得在通过 subscription operation 访问修改缺省键值时自动调用该方法,从而避免了dict 的 TypeError。
the instance behaves like a standard dictionary.
如果初始化 defaultdict 没有参数, 该变量蜕变成一个标准 dict。
The first argument to the Python defaultdict type must be a callable that takes no arguments and returns a value.
不接受形参,并且返回一个值。
Using the Python defaultdict Type for Handling Missing Keys
用 Python 的 defaultdict 处理不存在的键
想要学习 defaultdict 的原因: 看到 up 主在实现 DFS 的时候用到了这个语法
可以看到的是作者用到了对缺省键的访问操作。
not to call it using the parentheses at initialization time.
注意
给 .default_factory 赋值的时候一定不要带括号。
the dictionary assigns it the default value that results from calling list().
当我们访问不存在键的时候,defaultdict 会自动将调用 default_factory 的值赋给该键。
if you call .setdefault() on an existing key, then the call won’t have any effect on the dictionary.
如果对已存在的键调用 setdefault ,不会修改原值。
如果是缺省键,就会创建新的键值对。
four available ways to handle missing keys
处理缺省键的四种方式:
if you try to access or modify a missing key, then defaultdict will automatically create the key and generate a default value for it.
如果你想要访问或者修改一个缺省键值, defaultdict 会自动创建这个键然后生成一个默认值
Decide when and why to use a Python defaultdict rather than a standard dict
这句子不错
Decide when and why to use a Python defaultdict rather than a standard dict.
augmented assignment operator
augemented assignment operators In Chinese: 增强赋值运算符
Sets are collections of unique objects,
Python 中的 set 是单一对象的集合,不存在重复项。 与 C++ 的 set , unordered_set 类似
for large datasets, it can also be a lot faster and more efficient.
defaultdict 速度和效率往往好于 dict
Diving Deeper Into defaultdict
深入分析 defaultdict
When and why to use a Python defaultdict rather than a regular dict
何时以及为什么用 Python 的 defaultdict 而不是常规的 dict
Note that __missing__() is not called for any operations besides __getitem__().
missing() 不会被除 getitem() 之外的其他操作调用。
use code to parameterize calls:
You can write Python code to parametrize calls:
python -c "
from mymodule import set_dragon_feeding_schedule, Creatures, Date
set_dragon_feeding_schedule(
feeding_times=['10:00', '14:00', '18:00'],
dishes={Creatures.Tiger: 2, Creatures.Human: 1},
start_day=Date('1020-03-01'),
)
"
instead of:
python -m mymodule \
set_dragon_feeding_schedule \
--feeding-times ['10:00','14:00','18:00'] # hopefully this way it gets recognized \
# how will you define parsing a dict with enum to integer mapping?
--dishes=Creatures.Tiger:2 \
--dishes=Creatures.Human:1 \
--start-day=1020-03-21 # BTW bash allows no comments in multiline calls
That’s it. Types are parsed, checked and converted. Defaults and description are picked from function itself. Even provides bash completions you can install. You wrote no code for that!
Good example of writing CLI interfaces in Python with typer:
import typer
from pathlib import Path
app = typer.Typer()
@app.command()
def find_dragon(name: str, path: Path, min_age_years: int = 200):
<implementation goes here>
@app.command()
def feed_dragon(dragon_name: str, n_humans: int = 3):
<implementation goes here>
if __name__ == "__main__":
app()
later we can call it that way:
python example.py find_dragon 'Drake' --path /on/my/planet
Merge (|) and update (|=) operators have been added to the built-in dict class. Those complement the existing dict.update and {**d1, **d2} methods of merging dictionaries.
From Python 3.9 it's much more convenient to:
| (pipe) operator, e.g. x | y|=Use Streamlit if you want to get going as quickly possible and don’t have strong opinions or many custom requirements.Use Dash if you need something more flexible and mature, and you don’t mind spending the extra engineering time.
Streamlit vs Dash
Here’s a table showing the tradeoffs:
Comparison of dashboard tech stack as of 10/2020:

Python-igraph 0.8.3. (2020, October 8). Igraph Support Forum. https://igraph.discourse.group/t/python-igraph-0-8-3/473
The Census FTP page contains the microdata and dictionaries identifying each variable name, location, value range, and whether it applies to a restricted sample. To follow this example, download the April 2017 compressed data file that matches your operating system and unpack it in the same location as the python code. Next download the January 2017 data dictionary text file and save it in the same location.
This is important
3.5 PEP 478 security 2015-09-13 2020-09-13 Larry Hastings
All Python versions less than 3.6 are now EOL
This command will give you the top 25 stocks that had the highest anomaly score in the last 14 bars of 60 minute candles.
Supriver - find high moving stocks before they move using anomaly detection and machine learning. Surpriver uses machine learning to look at volume + price action and infer unusual patterns which can result in big moves in stocks
Like a string, a list is a sequence of values. In a string, the values are characters; in a list, they can be any type. The values in a list are called elements or sometimes itemsThe syntax for accessing the elements of a list is the same as for accessing the characters of a string—the bracket operator. The expression inside the brackets specifies the index. Remember that the indices start at 0:
cheeses[0]' Cheddar ' Unlike strings, lists are mutable. When the bracket operator appears on the left side of an assignment, it identifies the element of the list that will be assigned. numbers = [42, 123] numbers[1] = 5 numbers [42, 5] The most common way to traverse the elements of a list is with a for loop. The syntax is the same as for strings: for cheese in cheeses: print(cheese) This works well if you only need to read the elements of the list. But if you want to write or update the elements, you need the indices. A common way to do that is to combine the built-in functions range and len : for i in range(len(numbers)): numbers[i] = numbers[i] 2 This loop traverses the list and updates each element. len returns the number of elements in the list. range returns a list of indices from 0 to
n
1, where n is the length of the list. Each time through the loop i gets the index of the next element. The assignment statement in the body uses i to read the old value of the element and to assign the new value. The + operator concatenates lists: a = [1, 2, 3] b = [4, 5, 6] c = a + b c [1, 2, 3, 4, 5, 6] The operator repeats a list a given number of times: [0] 4 [0, 0, 0, 0] [1, 2, 3] 3 [1, 2, 3, 1, 2, 3, 1, 2, 3] The first example repeats [0] four times. The second example repeats the list [1, 2, 3] three times. *ython provides methods that operate on lists. For example, append adds a new element to the end of a list: t = [ ' a ' , ' b ' , ' c ' ] t.append( ' d ' ) t [ ' a ' , ' b ' , ' c ' , ' d ' ] extend takes a list as an argument and appends all of the elements: t1 = [ ' a ' , ' b ' , ' c ' ] t2 = [ ' d ' , ' e ' ] t1.extend(t2) t1 [ ' a ' , ' b ' , ' c ' , ' d ' , ' e ' ] This example leaves t2 unmodified. sort arranges the elements of the list from low to high: t = [ ' d ' , ' c ' , ' e ' , ' b ' , ' a ' ] t.sort() t [ ' a ' , ' b ' , ' c ' , ' d ' , ' e ' ] Most list methods are void; they modify the list and return None . If you accidentally write t = t.sort() , you will be disappointed with the result.
*A string is a sequence , which means it is an ordered collection of other values.
fruit =' banana ' letter = fruit[1] The second statement selects character number 1 from fruit and assigns it to letter . The expression in brackets is called an index .A lot of computations involve processing a string one character at a time. Often they start at the beginning, select each character in turn, do something to it, and continue until the end. This pattern of processing is called a traversal A segment of a string is called a slice . Selecting a slice is similar to selecting a character: s = ' Monty Python ' s[0:5] ' Monty ' s[6:12] ' PythonIt is tempting to use the [] operator on the left side of an assignment, with the intention of changing a character in a string. For example: greeting = ' Hello, world! ' greeting[0] = ' J ' TypeError: ' str ' object does not support item assignment The “object” in this case is the string and the “item” is the character you tried to assign. For now, an object is the same thing as a value, but we will refine that definition later (Section 10.10). The reason for the error is that strings are immutable ,
Miller, J. C., & TIng, T. (2019). EoN (Epidemics on Networks): A fast, flexible Python package for simulation, analytic approximation, and analysis of epidemics on networks. Journal of Open Source Software, 4(44), 1731. https://doi.org/10.21105/joss.01731
List Comprehensions