placeholder
I think this should be different
placeholder
I think this should be different
liver-lipted nigger ain’t done took and beat mah baby already! Ah’ll take a stick and salivate ’im!”
Researchers at the University of Reading recently conducted a blind test in which ChatGPT-written answers were submitted through the university’s own examination system: 94% of the AI submissions went undetected and received higher scores than those submitted by the humans.
WOW! This is actually insane.
Turnitin, which scans submissions for signs of plagiarism. In 2023, Turnitin launched a new AI detection tool that assesses the proportion of the text that is likely to have been written by AI.
AI programmed to detect AI? Feels a bit self aware to me.
Many such tools are now available, such as Google’s Gemini, Microsoft Copilot, Claude and Perplexity. These large language models absorb and process vast datasets, much like a human brain, in order to generate new material.
AI is so confusing to me.
What needs to happen to get me a future? Something remarkable. Something utterly remarkable because it's not it's not going that way.
for - quote - future of humanity - something remarkable has to happen - Eric Weinstein
Another limitation in this implementation is that passing other options in the shebang to vite-node won't work, as I expect exact indexes in order to figure out what are the arguments to forward. It's not perfect but I think it's good enough to unblock people like me as a start. 👍
there is something that all humans do naturally even without education yeah and that is learn language
for - quote - language education - there is something that all humans do naturally even without education, and that is learn language - David Long
This project is a fork of motdotla/dotenv. The difference is this project by default overrides system environment variables.
Not a need that I have, but I guess they felt a need for it
Your file structure might look something like this:
poor man's file structure diagram
There has to be a better way for us to manage Javascript build/run scripts. Everything for this platform seems tacked together. quotes with escaped quotes and npm builds to call other 'npm run' builds.. This is getting pretty painful.
#> 1 OpenAlex Only 12427
damn the wrapper I made only finds around 1685 hits, I wonder if it is to do with the type of search?
api_endpoint <- oa_query(
entity = "works",
title_and_abstract.search = search_string,
from_publication_date = from_date,
to_publication_date = to_date
)
But it is YouTube’scomplex economic allegiances that compel it to both play host to amateur video cultureand provide content owners the tools to criminalize it.
I learned that YouTube must balance between supporting user-generated content and protecting corporate interests.
‘Videos that are considered sexually suggestive, or that contain profanity, will bealgorithmically demoted on our “Most Viewed”, “Top Favorited”, and other browsepages’ (YouTube, 2008a).
Something I learned was, based on what content is in a video that it can be demoted on things like "Most viewed" and "Top Favorited." I did not know that based on certain content in a video that it could alter or change the popularity of it or how often it can be looked at/seen.
ost advertisers are wary of pairing ads with user-generated videos, despitetheir occasionally massive viral circulation, out of fear of being associated with thewrong content.
I always thought about how certain ads were paired with certain videos. I was always curious if companies were ever worried about what videos their ads would be on, and how decisions like that were even made. This confirmed for me that this is also a common thought amongst advertisers. If there ads were playing on not so appropriate videos it would have a bad look on their company and could damage their reputation/brand. The reading confirms that there is a fear of being associated with the wrong content.
Platforms’ are ‘platforms’ not necessarilybecause they allow code to be written or run, but because they afford an opportunity tocommunicate, interact or sell.
This is a confirmation for me because I always knew that social media allowed us to interact with one another and communicate via online. This justifies my thoughts because it claims that platforms not only run codes, but are a way of interaction amongst people. In addition it is a way to sell and make money by sharing new ideas.
All four of these semantic areas are relevant to why ‘platform’ has emerged in referenceto online content-hosting intermediaries and, just as important, what value both its speci-ficity and its flexibility offer them.
This is something new I learned because I was not aware that the term platform had these different meanings behind them. The four semantic areas are: computational, architectural, figurative, and political. All of these categories make up how the term platform came to be and what it truly means.
elegated
def: * consign or dismiss to an inferior rank or position.
carbohydrate
To identify carbohydrates (and lipids in general besides phospholipids), you can count the number of C, H, and O present in the molecule.
The number of carbons and oxygens should be equal, whereas the number of hydrogens should be double this amount.
You can also identify lipids by looking for the polar "head" and nonpolar "tail"!
If I decide to add it, which solution should I pick, battle tested Sorbet or core team endorsed RBS?
once you realize that the world isn't what you think it is it's very easy to grab onto something else and grab onto some kind of weird conspiracy well that's the thing you've been describing thus far as well sorry to in just say but like the openness requires structure
for - quote conspiracy theories - lizard people - first stage of initiation - if reality isn't as it appears, it's easy to latch onto something else - John Churchill
I am just surprised that there is no clear official name for such a popular and well known convention. Internet searching seems to indicate that the common term used is "Red Squiggly Line", but it seems like a term quickly made-up just to describe something for which we know no name. There's a technical name for the dot on an "i" for goodness sake (tittle).
1:09:52 A Bank LOAN is an interest attached to your own ability to pay back something that did not exist before you borrowed it
1:09:59 A bank officer ACQUIRES the loan in order to charge interest on it
(in its practitioners' perverse terminology) as “secure boot”
On many occasions, I've opened up requests for support in the form of a Github pull request. This way, I am telling the author: I have found a potential problem with your library, here is how I fixed it for my circumstance, here is the code I used for reference. You get extra internet points if you open the pull request with: "I don't expect this pull request to get merged, but I wanted to you show you what I did".
Not everyone has time to adhere to the specific coding styles for a project, so if you can't do a full blown pull-request, there is NOTHING wrong with opening a pull-request that only has the intention of showing the author how you solved the problem.
Let your operating system handle daemons, respawning and logging while you focus on your application features and users.
Less system administration, easier debugging, simpler code, all because you leveraged the init system to do the work for you!
hash digest returns an alphanumeric message which is the digest. that is incorrect, this alphanumeric message is a representation of the digest. The digest itself is a string of bits with a fixed length
used to be
nostalgia
likethe place in a face where the eye has been taken out.
Connotations of blankness, blindness, torture, missingness, meant to be beautiful but something missing from it (the core is taken out)
most of the great religions in the world have been attempts to to restrain or reform uh human nature or at least uh channel our worst impulses into something 01:10:48 more productive or higher something loftier um and in this this is exactly what we need here it's something that will create a form of altruism which doesn't only extend to people we see around us now but extends 01:11:00 to the future generations
for - rapid whole system change - need for something that will create a new form of altruism - Ronald Wright - transition - requires an experience of re-awakening transition - need for a new religion? Deep Humanity?
comment 10 July 2024 - Deep Humanity is our attempt at this. It is not a religion, however. It is humanity, but in the deepest sense, so it is accessible to anyone in our species. Our tagline has been - Rekindling wonder in an age of crisis - However, this morning an adjacency occurred:
adjacency - between - familiarity - wonder - adjacency relationship - Familiarity hides wonder - Richard Dawkins said: - There is an anaesthetic of familiarity, - a sedative of ordinariness - which dulls the senses and hides the wonder of existence. - For those of us not gifted in poetry, - it is at least worth while from time to time - making an effort to shake off the anaesthetic. - What is the best way of countering the sluggish habitutation brought about by our gradual crawl from babyhood? - We can't actually fly to another planet. - But we can recapture that sense of having just tumbled out to life on a new world - by looking at our own world in unfamiliar ways. - That is, when a type of experience becomes familiar through repeated sensory episodes, - we lose the feeling of wonder we had when we initially experienced it - It's much like visiting a place for the very first time. We are struck with a sense of wonder because everything is unpredictable, in a safe way. We have no idea what's around the next corner. It's a surprise. - However, once we live there, and have traced that route hundreds of times, we have transformed that first magical experience into mundane experience. - So it is with everything that makes us human, with all the foundational things about reality that we learned from the moment we were born. - They have all become jaded. We've forgotten the awe of those first experiences in this reality: - our first experience of our basic senses - our first breath of air, instead of amniotic fluid - our first integration of multiple sensory experiences into a cohesive whole - the birth of objectification - the very first application of objectification to form the object we called mOTHER - the Most significant OTHER - our first encounter with the integration of multiple sensory stimuli associated with each object we construct - our first encounter with auditory human, speech symbols - our first experience with object continuity - how objects still exist even if they disappear from view momentarily - do we remember freaking out when mOTHER disappeared from view momentarily? - our first ability to communicate with mOTHER through speech symbols - our first encounter with ability to control our bodies through our own volition - our first encounter with gravity, the pull towards the ground - our first encounter with a large bright sphere suspended in the sky - our first encounter with perspective, how objects change size in our field of view as they get nearer or farer - etc... - What's missing now, is that we have repeated all these experiences so many times, that the feeling of awe no longer emerges with life - To generate awe, the repertoire of existing experiences is insufficient - now we have to create NEW experiences, we have to create novelty - Mortality Salience can help jolt us out of this fixation on novelty, and remind us of the sacred that is already here all the time - For, what happens at the time of death? All the constructions we have taken for granted in life disappear all at once, or perhaps some before others - Hence, we begin to re-experience them as relative, as constructions, and not absolutes - All living organisms have their own unique umwelt - These umwelts are all expressions of the sacred, sensing itself in different ways
we strive to heed upstream's recommendations on how they intend for their software to be consumed.
These can then be used to develop a definition that states the essence of the living thing—what makes it what it is and thus cannot be altered; the essence is, of course, immutable.
The Aristotelian method dominated classification until the 19th century. His scheme was, in effect, that the classification of a living thing by its nature—i.e., what it really is, as against superficial resemblances—requires the examination of many specimens, the discarding of variable characters (since they must be accidental, not essential), and the establishment of constant characters.
What they say is this is due to is new EU policies about messenger apps. I'm not in the EU. I reckon it's really because there's a new Messenger desktop client for Windows 10, which does have these features. Downloading the app gives FB access to more data from your machine to sell to companies for personalized advertising purposes.
overpopulation and degeneration caused by pacifism and civilization,<br /> and the long-overdue depopulation through mass murder on all levels.<br /> hell of a time to be alive... most of us will be dead soon. byee, i hate you all : D
“Various people asked to do various things with it, and they referred them to this guy who didn't respond,” Brand says. “And so it was just frustrating for decades.”
for: futures - neo-Venetian crypto-networks, Global Chinese Commons, GCC, cosmolocal, coordiNation, somewheres, everywheres, nowheres, Global System One, Global System Two, Global System Three, contributory accounting, fourth sector, protocol cooperative, mutual coordination economics
summary
what you're referring to is the idea that people come together and through language culture and story they have narratives that then create their own realities like the 00:12:04 sociologist abely the sociologist wi Thomas said if people think people believe things to be real then they are real in their consequences
for: Thomas Theorem, The definition of the situation, William Isaac Thomas, Dorothy Swain Thomas, definition - Thomas Theorem, definition - definition of the situation, conflicting belief systems - Thomas theorem, learned something new - Thomas theorem
definition: Thomas Theorem
If men define situations as real, they are real in their consequences.[1]
In other words, the interpretation of a situation causes the action. This interpretation is not objective. Actions are affected by subjective perceptions of situations. Whether there even is an objectively correct interpretation is not important for the purposes of helping guide individuals' behavior.|
key insight: polarization
adjacency between:
adjacency statement
reference
One loss due to this change is the ability to represent an invalid UUID (vs a NIL UUID).
Given the security implications of getting the implementation correct, we strongly encourage you to use OAuth 2.0 libraries when interacting with Google's OAuth 2.0 endpoints. It is a best practice to use well-debugged code provided by others, and it will help you protect yourself and your users. For more information, see Client libraries.
Capybara.string(response.body)
const $html = Cypress.$(body)
I think the problem with after_destroy is that it is triggered before the database commits. This means the change may not yet be seen by other processes querying the database; it also means the change could be rolled back, and never actually commited. Since shrine deletes the attachment in this hook, that would mean it might delete the attachment prematurely, or even delete the attachment when the record never ends up destroyed in the database at all (in case of rollback), which would be bad. For shrine's logic to work as expected here, it really does need to be triggered only after the DB commit in which the model destroy is committed.
For lost googlers:
They sound like "argument by prestige". If MSDN says it, or some famous developer or author whom everybody likes says it, it must be so.
Stop to think about "normal app" as like desktop app. Android isn't a desktop platform, there is no such this. A "normal" mobile app let the system control the lifecycle, not the dev. The system expect that, the users expect that. All you need to do is change your mindset and learn how to build on it. Don't try to clone a desktop app on mobile. Everything is completely different including UI/UX.
depends on how you look at it: "normal"
As an aside, I think I now prefer this technique to Python for at least one reason: passing arguments to the decorator method does not make the technique any more complex. Contrast this with Python: <artima.com/weblogs/viewpost.jsp?thread=240845>
When you call 'foo' in Ruby, what you're actually doing is sending a message to its owner: "please call your method 'foo'". You just can't get a direct hold on functions in Ruby in the way you can in Python; they're slippery and elusive. You can only see them as though shadows on a cave wall; you can only reference them through strings/symbols that happen to be their name. Try and think of every method call 'object.foo(args)' you do in Ruby as the equivalent of this in Python: 'object.getattribute('foo')(args)'.
def document(f): def wrap(x): print "I am going to square", x f(x) return wrap @document def square(x): print math.pow(x, 2) square(5)
S
Found this video to be quite informal, as I didn't know about the currents that go on underwater. The "ocean's conveyor belt". These currents, sometimes called submarine rivers, flow deep below the surface of the ocean and are hidden from immediate detection.
Calon Lân Course<br /> by SaySomethingin
Lesson 1: https://www.saysomethingin.com/wp-content/uploads/2023/01/Calon-Lan-Lesson1.mp3
Lesson 2: https://www.saysomethingin.com/wp-content/uploads/2023/01/Calon-Lan-Lesson2.mp3
That tends to be the biggest cop out excuse for libraries. Just do a major version release. The fact this library lies about the encodingis extremely problematic and causes numerous bugs. Any program currently using this library is already incorrect because of this behavior. Actually exposing the problem makes it easier for people to fix.
in reply to subject of https://hyp.is/VeTJlpN0Ee2mNKOVyQ-B5g/github.com/mikel/mail/issues/902
Agree, but we're stuck with API compatibility for a good while.
Imagine what happens when subscribers change activities, interests, or focus. As a result, they may no longer be interested in the products and services you offer. The emails they receive from you are now either ‘marked as read’ in their inbox or simply ignored. They neither click the spam reporting button nor attempt to find the unsubscribe link in the text. They are no longer your customers, but you don’t know it.
If you are going to crawl sites you better use Ferrum or Vessel because you crawl, not test.
Until now, we had a lot of code. Although we were using a plugin to help with boilerplate code, ready endpoints, and webpages for sign in/sign up management, a lot of adaptations were necessary. This is when Doorkeeper comes to the rescue. It is not only an OAuth 2 provider for Rails but also a full OAuth 2 suite for Ruby and related frameworks (Sinatra, Devise, MongoDB, support for JWT, and more).
So far for the obligatory warning. I get the point, I even agree with the argument, but I still want to send a POST request. Maybe you are testing an API without a user interface or you are writing router tests? Is it really impossible to simulate a POST request with Capybara? Nah, of course not!
This is ugly by design, as an inducement to test properties instead of specifics.
Related: #45017 ActiveRecord silently triggers a rollback when return is used in the transaction block.
i was a bit unsure what to think of it, as i wished to go into this 100% blind. And boy am i glad i did.
I like it. I’m biased though since I’m a sucker for opportunities to simplify like this one.
The bash manual contains the statement For almost every purpose, aliases are superseded by shell functions.
Also, the chances of breaking something are really high, because not even you remember how the code actually works.
The rules recorded in natural language are readable not only by humans but also by the computer and therefore no longer need to be programmed by a software developer. This task is now taken over by openVALIDATION.
Such schemas cannot easily be refactored without removing the benefits of sharing. Refactoring would require forking a local copy, which for schemas intended to be treated as an opaque validation interface with internal details that may change, eliminates the benefit of referencing a separately maintained schema in the first place.
an equivalent of R's signif function in Ruby.
So when should you use rbspy, and when should you use stackprof? The two tools are actually used in pretty different ways! rbspy is a command line tool (rbspy record --pid YOUR_PID), and StackProf is a library that you can include in your Ruby program and use to profile a given section of code.
I don't understand the hesitation here to accept a really useful addition to rspec. Maintenance burden. Forseen internal changes required to do it. Unforseen internal changes required to do it. Formatter changes to handle new output status for a spec that passed and failed It's simply not a previously design use case of RSpec. It will be hacky to implement.
We already have a very wide configuration API. The further we expand it the more unwieldy it becomes for users. At this point we generally require new features to be implemented first as extension gems, and then to see support, before considering including them in core.
It sounds like the OP's needs have been met, but for future explorers, here's some tools to tell if something is clickable.
It feels like « removing spring » is one of those unchallenged truths like « always remove Turbolinks » or « never use fixtures ». It also feels like a confirmation bias when it goes wrong.
"unchallenged truths" is not really accurate. More like unchallenged assumption.
All seem focused on rendering the 404 page manually. However, I wanted to make rescue_from work. My solution is the catch-all route and raising the exception manually.
Interleaving is a learning technique that involves mixing together different topics or forms of practice, in order to facilitate learning. For example, if a student uses interleaving while preparing for an exam, they can mix up different types of questions, rather than study only one type of question at a time.Interleaving, which is sometimes referred to as mixed practice or varied practice, is contrasted with blocked practice (sometimes referred to as specific practice), which involves focusing on only a single topic or form of practice at a time.
Interleaving (aka mixed practice or varied practice) is a learning strategy that involves mixing different topics, ideas, or forms of practice to improve outcomes as well as overall productivity. Its opposite and less effective strategy is blocking (or block study or specific practice) which focuses instead on working on limited topics or single forms of practice at the same time.
This may be one of the values of of the Say Something In Welsh method which interleaves various new nouns and verbs as well as verb tenses in focused practice.
Compare this with the block form which would instead focus on lists of nouns in a single session and then at a later time lists of verbs in a more rote fashion. Integrating things together in a broader variety requires more work, but is also much more productive in the long run.
the more effort they had to put into the study strategy, the less they felt they were learning.
misinterpreted-effort hypothesis: the amount of effort one puts into studying is inversely proportional to how much one feels they learn.
Is this why the Says Something In Welsh system works so well? Because it requires so much mental work and effort in short spans of time? Particularly in relation to Duolingo which seems easier?
The focus of the dev container specification is to describe how to enrich a container for the purposes of development, rather than acting as a multi-container orchestrator format.
https://forum.artofmemory.com/t/what-language-s-are-you-studying/73190
I've been studying Welsh on and off now for just over a year.
I've been using a mix of Duolingo for it's easy user interface and it's built in spaced repetition. I like the way that it integrates vocabulary and grammar in a holistic way which focuses on both reading, writing, and listening.
However, I've also been using the fantastic platform Say Something in Welsh. This uses an older method of listening and producing based teaching which actually makes my brain feel a bit tired after practice. The focus here is solely on listening and speaking and forces the student to verbally produce the language. It's a dramatically different formula than most high school and college based courses I've seen and used over the years having taken 3 years of Spanish, 2 of French, and 2 of Latin.
The set up consists of the introduction of a few words which are then used in a variety of combinations to create full sentences. The instructors say a sentence in English and the listener is encouraged in just a few seconds to attempt to produce it in the target language (Welsh, in my case), then the instructor says the sentence in Welsh with a pause for the student to repeat it properly, another instructor says it in Welsh with a pause for a third repeat. This goes on for 20 to 30 minutes at a time. The end result is that the learner gets into the language much more quickly and can begin both understanding the spoken language as well as produce it much more rapidly than older school based methods (at least in my experience, though I have known some college language labs to use a much more limited version of a similar technique). Each lesson adds new material, but also reviews over older material in a spaced repetition format as well so you're always getting something new mixed in with the old to make new and interesting sentences for conversation.
SSiW also has modules for Manx, Cornish, Dutch, and Spanish.
I find that the two done hand in hand has helped me produce much faster results in language acquisition in an immersive manner than I have done previously and with much less effort.
Instead read this gems brief source code completely before use OR copy the code straight into your codebase.
it is highly encouraged to switch to zeitwerk mode because it is a better autoloader
Not what you asked, but as this question is linked to from a few places I hope someone finds this answer useful.
StopTheMadness is a web browser extension that stops web sites from making your browser harder to use
"The good news is that you can wrest control of your browser back from these malicious, control-freak sites."
I am open to discussion but I don't want to jump on the conclusion.
The biggest reason is that we still have several options, so I didn't want to restrict the future possibility.
because it is in a central location and contributed to by many people, problems are found quickly, and fixes are for everyone—not just one specific template.
Instead of render props, we use Svelte's slot props: // React version <Listbox.Button> {({open, disabled} => /* Something using open and disabled */)} </Listbox.Button> <!--- Svelte version ---> <ListboxButton let:open let:disabled> <!--- Something using open and disabled ---> </ListboxButton>
having inconsistencies when all the "subtle" conditions were met is unfriendly. it requires the user to have much deeper understanding of the nuances of the language.
Tip for those who run into the same error message and find this bug report by Google: Your cause for this error message might be a different cause entirely. To find your cause, set a breakpoint, and look at the call stack.
Over the years in academic settings I've picked up pieces of Spanish, French, Latin and a few odd and ends of other languages.
Six years ago we put our daughter into a dual immersion Japanese program (in the United States) and it has changed some of my view of how we teach and learn languages, a process which is also affected by my slowly picking up conversational Welsh using the method at https://www.saysomethingin.com/ over the past year and change, a hobby which I wish I had more targeted time for.
Children learn language through a process of contextual use and osmosis which is much more difficult for adults. I've found that the slowly guided method used by SSiW is fairly close to this method, but is much more targeted. They'll say a few words in the target language and give their English equivalents, then they'll provide phrases and eventually sentences in English and give you a few seconds to form them into the target language with the expectation that you try to say at least something, or pause the program to do your best. It's okay if you mess up even repeatedly, they'll say the correct phrase/sentence two times after which you'll repeat it again thus giving you three tries at it. They'll also repeat bits from one lesson to the next, so you'll eventually get it, the key is not to worry too much about perfection.
Things slowly build using this method, but in even about 10 thirty minute lessons, you'll have a pretty strong grasp of fluent conversational Welsh equivalent to a year or two of college level coursework. Your work on this is best supplemented with interacting with native speakers and/or watching television or reading in the target language as much as you're able to.
For those who haven't experienced it before I'd recommend trying out the method at https://www.saysomethingin.com/welsh/course1/intro to hear it firsthand.
The experience will give your brain a heavy work out and you'll feel mentally tired after thirty minutes of work, but it does seem to be incredibly effective. A side benefit is that over time you'll also build up a "gut feeling" about what to say and how without realizing it. This is something that's incredibly hard to get in most university-based or book-based language courses.
This method will give you quicker grammar acquisition and you'll speak more like a native, but your vocabulary acquisition will tend to be slower and you don't get any writing or spelling practice. This can be offset with targeted memory techniques and spaced repetition/flashcards or apps like Duolingo that may help supplement one's work.
I like some of the suggestions made in Lynne's post as I've been pecking away at bits of Japanese over time myself. There's definitely an interesting structure to what's going on, especially with respect to the kana and there are many similarities to what is happening in Japanese to the Chinese that she's studying. I'm also approaching it from a more traditional university/book-based perspective, but if folks have seen or heard of a SSiW repetition method, I'd love to hear about it.
Hopefully helpful by comparison, I'll mention a few resources I've found for Japanese that I've researched on setting out a similar path that Lynne seems to be moving.
Japanese has two different, but related alphabets and using an app like Duolingo with regular practice over less than a week will give one enough experience that trying to use traditional memory techniques may end up wasting more time than saving, especially if one expects to be practicing regularly in both the near and the long term. If you're learning without the expectation of actively speaking, writing, or practicing the language from time to time, then wholesale mnemotechniques may be the easier path, but who really wants to learn a language like this?
The tougher portion of Japanese may come in memorizing the thousands of kanji which can have subtly different meanings. It helps to know that there are a limited set of specific radicals with a reasonably delineable structure of increasing complexity of strokes and stroke order.
The best visualization I've found for this fact is the Complete Listing of the 214 Radicals and Major Variations from An Introduction to Japanese Kanji Calligraphy by Kunii Takezaki (Tuttle, 2005) which I copy below:

(Feel free to right click and view the image in another tab or download it and view it full size to see more detail.)
I've not seen such a chart in any of the dozens of other books I've come across. The numbered structure of increasing complexity of strokes here would certainly suggest an easier to build memory palace or songline.
I love this particular text as it provides an excellent overview of what is structurally happening in Japanese with lots of tidbits that are otherwise much harder won in reading other books.
There are many kanji books with various forms of what I would call very low level mnemonic aids. I've not found one written or structured by what I would consider a professional mnemonist. One of the best structured ones I've seen is A Guide to Remembering Japanese Characters by Kenneth G. Henshall (Tuttle, 1988). It's got some great introductory material and then a numbered list of kanji which would suggest the creation of a quite long memory palace/journey/songline.
Each numbered Kanji has most of the relevant data and readings, but provides some description about how the kanji relates or links to other words of similar shapes/meanings and provides a mnemonic hint to make placing it in one's palace a bit easier. Below is an example of the sixth which will give an idea as to the overall structure.

I haven't gotten very far into it yet, but I'd found an online app called WaniKani for Japanese that has some mnemonic suggestions and built-in spaced repetition that looks incredibly promising for taking small radicals and building them up into more easily remembered complex kanji.
I suspect that there are likely similar sources for these couple of books and apps for Chinese that may help provide a logical overall structuring which will make it easier to apply or adapt one's favorite mnemotechniques to make the bulk vocabulary memorization easier.
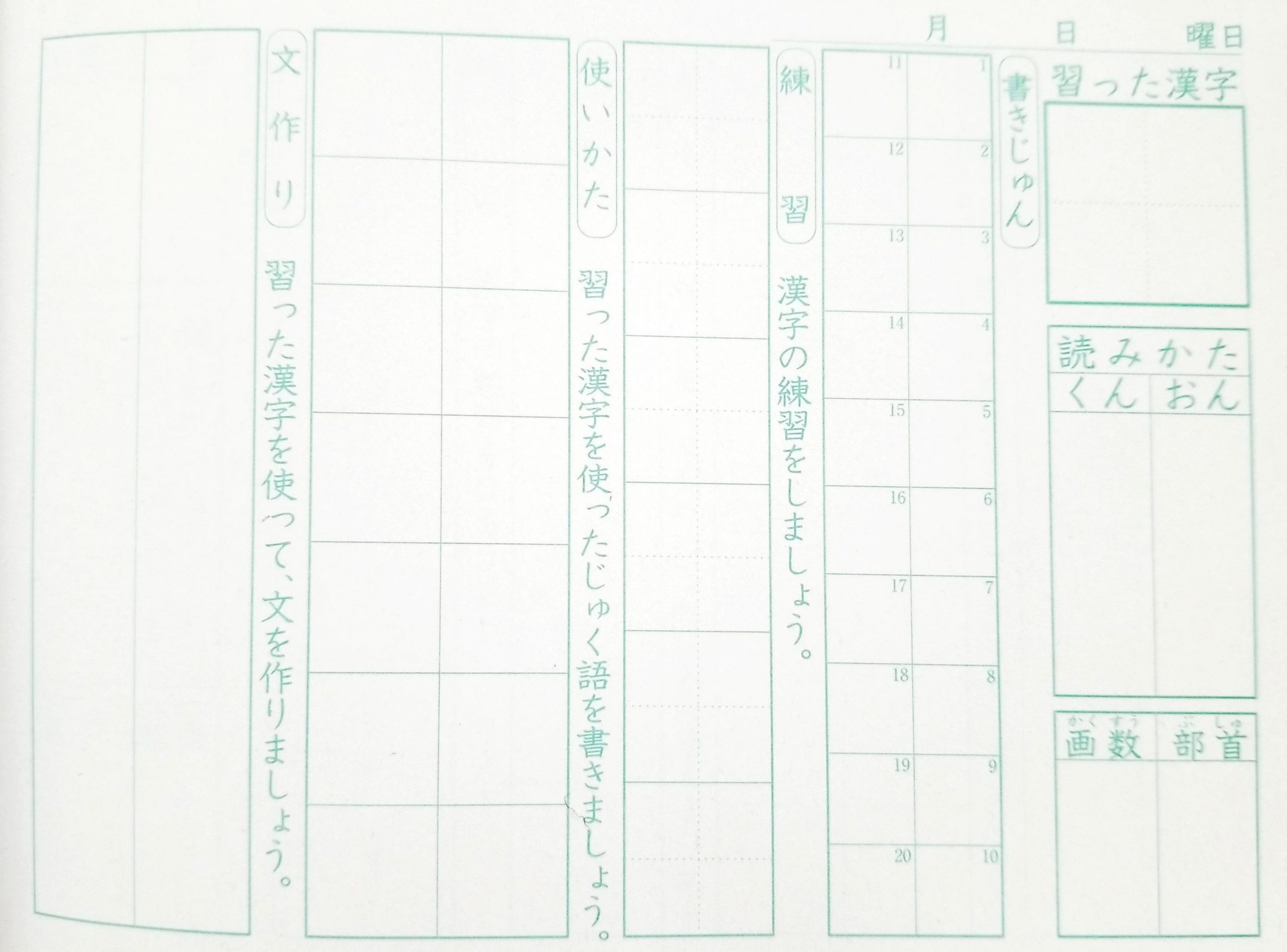
The last thing I'll mention I've found, that's good for practicing writing by hand as well as spaced repetition is a Kanji notebook frequently used by native Japanese speaking children as they're learning the levels of kanji in each grade. It's non-obvious to the English speaker, and took me a bit to puzzle out and track down a commercially printed one, even with a child in a classroom that was using a handmade version. The notebook (left to right and top to bottom) has sections for writing a big example of the learned kanji; spaces for the "Kun" and "On" readings; spaces for the number of strokes and the radical pieces; a section for writing out the stroke order as it builds up gradually; practice boxes for repeated practice of writing the whole kanji; examples of how to use the kanji in context; and finally space for the student to compose their own practice sentences using the new kanji.
Regular use and practice with these can be quite helpful for moving toward mastery.
I also can't emphasize enough that regularly and actively watching, listening, reading, and speaking in the target language with materials that one finds interesting is incredibly valuable. As an example, one of the first things I did for Welsh was to find a streaming television and radio that I want to to watch/listen to on a regular basis has been helpful. Regular motivation and encouragement is key.
I won't go into them in depth and will leave them to speak for themselves, but two of the more intriguing videos I've watched on language acquisition which resonate with some of my experiences are:
I am firmly convinced that asserting on the state of the interface is in every way superior to asserting on the state of your model objects in a full-stack test.
Okay thank you. I'll need to do some thinking then on how to apply that to things like git config --global core.editor
const palette: { [key: string]: string } = {...
what is the TypeScript Way™ of handling the implicit any that appears due to object literals not having a standard index signature?
Just for fun, I did a little experimenting at home to show how some of these different types of cement hold up. I started by cementing a bunch of materials together with a bunch of different types of cement. I waited 24 hours, then cut each one roughly in half, down the middle.
I feel like that is a very broad generalization but I would agree that most people have read something about technology. I'm also not sure if I agree that learning devices enhance learning outcomes for kids. I know there have been studies done that say if you use pencil and paper to write your notes, you are more likely to remember information.
The number of complaints across the issue tracker and the lack of substantive followup on many of those complaints should be ample evidence that these frustrated users exist and are likely about to leave Fenix behind in droves, if they haven't already.
How can we get action on the bugzilla bug mentioned above to cause this to be fixed?
The problem is that Webpack created convenience by automatically polyfilling and then now suddenly took it away.
Three days before Labor Day, on Friday, September 2, 1921, the U.S. Army intervened on the side of coal companies against striking coal miners, marking the end of the Battle of Blair Mountain in southern West Virginia. The battle was the climax of two decades of low-intensity warfare across the coalfields of Appalachia, as the West Virginia miners sought to unionize and mining companies used violent tactics to undermine their efforts. The struggle turned deadly.
We human beings pride ourselves on our ability to reason, but the truth is we use our brains nine times out of ten to justify what our gut wants, not what is rational to do.
Seeing what you want to see, and failing to understand the why and the how
This library on GitHub solves the cross-domain problem, along with making sure the iFrame stays sized to the content when things change. github.com/davidjbradshaw/iframe-resizer
This will obviate the need for a helper function of any kind.
Noticed that with 100+ s, I am not alone here. There are definitely a lot of devs wanting this feature. So I took some time out and decided to give this a go myself. I have created a PR for the same
that's why I bolded "same column" with the or query. I can delete the comment altogether, but thought it would be helpful for people perusing "or" query SO questions.
Our members are technically self-pay; however, 100 percent of our members pay their bills. All we—and they—ask is that healthcare providers not penalize them for this technical designation. Please give our members the same consideration in terms of discounts that insurance companies receive for negotiated contracts.
In mutations, when errors happen, the other fields may return nil. So, if those other fields have null: false, but they return nil, the GraphQL will panic and remove the whole mutation from the response, including the errors!
However, this request-by-request mindset doesn’t map well to GraphQL because there’s only one controller and the requests that come to it may be very different.
There are many projects that does not use the master branch as default. For example, Next.js uses the canary branch, the npm CLI and many more other projects uses stuff like prod, production, dev, develop, release, beta, head.
On existing projects, consider the global effort to change from origin/master to origin/main. The cost of being different than git convention and every book, tutorial, and blog post. Is the cost of change and being different worth it?
My 3 projects were using your lib and got broken thanks to the renaming.
The main (IMO) feature of MQTT – quality of service – doesn't make sense in our case: if a WebSocket server is down and doesn't receive broadcast messages (through HTTP/Redis/queue), it's likely not to handle client connections too.
This meant that we owned both sides of the product implementation. For unit testing on the frontend, we stayed with Angular’s suggestion of Jasmine. For unit testing on the backend, we went with rspec-rails. These worked well since unit tests don’t need to cross technology boundaries.
We used testing tools that were in the same ecosystem as our backend technology stack for primrily three reasons: We owned both ends of the stack Team experience Interacting with the database
Configuration style is exactly the same for env_bang and env_setting, only that there's no "ENV!" method... just the normal class: EnvSetting that is called and configured.
Programmers should be encouraged to understand what is correct, why it is correct, and then propagate.
new tag?:
I'm not sure why MSFT decided to change these codes in the first place. While it might have been a noble goal to follow the IETF standard (though I'm not really familiar with this), the old codes were already out there, and most developers don't benefit by the new codes, nor care about what these codes are called (a code is a code). Just the opposite occurs in fact, since now everyone including MSFT itself has to deal with two codes that represent the same language (and the resulting problems). My own program needs to be fixed to handle this (after a customer contacted me with an issue), others have cited problems on the web (and far more probably haven't publicised theirs), and MSFT itself had to deal with this in their own code. This includes adding both codes to .NET even though they're actually the same language (in 4.0 they distinguished between the two by adding the name "legacy" to the full language name of the older codes), adding special documentation to highlight this situation in MSDN, making "zh-Hans" the parent culture of "zh-CHS" (not sure if it was always this way but it's a highly questionable relationship), and even adding special automated code to newly created "add-in" projects in Visual Studio 2008 (only to later remove this code in Visual Studio 2010, without explanation and therefore causing confusion for developers - long story). In any case, this is not your doing of course, but I don't see how anyone benefits from this change in practice. Only those developers who really care about following the IETF standard would be impacted, and that number is likely very low. For all others, the new codes are just an expensive headache. Again, not blaming you of cours
I feel the pain. It is a normal thing that standards do evolve over time, though, and our software needs to cope with it.
I'm not sure why MSFT decided to change these codes in the first place. While it might have been a noble goal to follow the IETF standard (though I'm not really familiar with this), the old codes were already out there, and most developers don't benefit by the new codes, nor care about what these codes are called (a code is a code).
get: function(target, prop, receiver) { return "world"; }
We want the GraphQL API to be the primary means of interacting programmatically with GitLab. To achieve this, it needs full coverage - anything possible in the REST API should also be possible in the GraphQL API.
They have to ask you the dumb questions, either because their employer demands they do, or sometimes because their computer system doesn't let them get to the next part of the script unless they play ball.
Another will employ smart people who apologise to you profusely for having to go through all the pointless steps, but that's just what they have to do!
There's nothing to stop you from doing initializer code in a file that lives in app/models. for example class MyClass def self.run_me_when_the_class_is_loaded end end MyClass.run_me_when_the_class_is_loaded MyClass.run_me... will run when the class is loaded .... which is what we want, right? Not sure if its the Rails way.... but its extremely straightforward, and does not depend on the shifting winds of Rails.
does not depend on the shifting winds of Rails.
I don't believe the sprockets and sprockets-rails maintainers (actually it's up to the Rails maintainers, see rails/rails#28430) currently consider it broken. (I am not a committer/maintainer on any of those projects). So there is no point in "waiting for someone else to fix" it; that is not going to happen (unless you can change their minds). You just need to figure out the right way to use sprockets 4 with rails as it is.
The use of U+212B 'Angstrom sign', which was encoded due to round-trip mapping compatibility with an East-Asian character encoding, is discouraged, and the preferred representation is U+00C5 'capital letter A with ring above', which has the same glyph.
Is there a difference in semantic meaning between the two? And if so, what is it? 
https://www.merriam-webster.com/thesaurus/legitimize lists validate but https://www.merriam-webster.com/thesaurus/validate doesn't list legitimize
What is the equivalent of unbuffer program on Windows?
Of course you must not use plain-text passwords and place them directly into scripts. You even must not use telnet protocol at all. And avoid ftp, too. I needn’t say why you should use ssh, instead, need I? And you also must not plug your fingers into 220 voltage AC-output. Telnet was chosen for examples as less harmless alternative, because it’s getting rare in real life, but it can show all basic functions of expect-like tools, even abilities to send passwords. BUT, you can use “Expect and Co” to do other things, I just show the direction.
perl -ne 'chomp(); if (-e $_) {print "$_\n"}'
xargs -i sh -c 'test -f {} && echo {}'
We also know people need a good sized group and time to see the impact and value of a platform like Stack Overflow for Teams. Our previous 30 day free trial of our Basic tier wasn’t long enough. Now, Stack Overflow for Teams has a free tier for up to 50 users, forever.
substitute /one space or more/ for /newline/ globally
Yet, it certainly is important to make the proper choices when picking up style. Similarly to fashion, code style reflects our credo as developers, our values and philosophy. In order to make an informed decision, it’s mandatory to understand the issue at stake well. We all have defined class methods many times, but do we really know how do they work?
The good news: everyone had a genuine blast. We knew we had experimented our way into something fun, even if the rules and designs still needed a lot of work.
Yeah, I probably think of using foam before anyone else does.
This approach is preferable to overriding authenticate_user! in your controller because it won't clobber a lot of "behind the scenes" stuff Devise does (such as storing the attempted URL so the user can be redirected after successful sign in).
Visible spectrum wrapped to join blue and green in an additive mixture of cyan
the rainbow as a continuous (repeating) circle instead of semicircle
Svelte is different in that by default most of your code is only going to run once; a console.log('foo') line in a component will only run when that component is first rendered.
Two of the predominant types of relationships in knowledge-representation systems are predication and the universally quantified conditional.
The precise semantic interpretation of an atomic formula and an atomic sentence will vary from theory to theory.
However, if all of these are hosted in the same repository, you lose a lot of those benefits.
All too often, people get hung up on the wrong aspects of the Unix Philosophy, and miss the forest for the trees
I suspect you aren't seeing much discussion because those who have a reasonable process in place, and do not consider this situation to be as bad as everyone would have you believe, tend not to comment on it as much.
Or perhaps there was no printed manual, only a link to a web page - that has since disappeared (because the provider went bust, or just changed their web content management system).
A product’s onceability is, to a certain extent, linked to its usefulness. If it is really useful, we will certainly go to considerable lengths to repair it.
Meh... as I said earlier, I think using Webpack is the recommended way now. Another issue is there is no way to generate source maps in production.
But yeah, I'm not sure how you would determine which was the "recommended way" really. I don't see anything in Rails docs saying either way.
But last I have seen comments from DHH, he considered webpack(er) recommended for JS, but Sprockets still the preferred solution for (S)CSS.
I agree about lack of maintenance. It's probably because people use more and more Webpack.
And we shave off 6 or so seconds, that is huge.
Since the common problem with concatenating JavaScript files is the lack of semicolons, automatically adding one (that, like Sam said, will then be removed by the minifier if it's unnecessary) seems on the surface to be a perfectly fine speed optimization.
we want source maps in production (like DHH)
After waiting years for sprockets to support this we were very happy to see that sprockets 4 officially added support (thanks ), but then when trying to upgrade we noticed there's actually no way to use it in production... (without brittle hacks mentioned above).
Right now major changes require a deep and broad understanding of the codebase and how things get done.
If you end up finding and fixing a bug in your code, consider re-reading the documentation and seeing if that behavior of the library is unclear. Consider sending a documentation PR.
Usually when people are talking about code being semantically correct, they're referring to the code that accurately describes something.
Semantically correct usage of elements means that you use them for what they are meant to be used for.
It means that you're calling something what it actually is.
Hey, that’s is an imaginary complication of our example - please don’t do this with every condition you have in your app.
URI::MailTo::EMAIL_REGEXP
First time I've seen someone create a validator by simply matching against URI::MailTo::EMAIL_REGEXP from std lib. More often you see people copying and pasting some really long regex that they don't understand and is probably not loose enough. It's much better, though, to simply reuse a standard one from a library — by reference, rather than copying and pasting!!
For branching out a separate path in an activity, use the Path() macro. It’s a convenient, simple way to declare alternative routes
Seems like this would be a very common need: once you switch to a custom failure track, you want it to stay on that track until the end!!!
The problem is that in a Railway, everything automatically has 2 outputs. But we really only need one (which is exactly what Path gives us). And you end up fighting the defaults when there are the automatic 2 outputs, because you have to remember to explicitly/verbosely redirect all of those outputs or they may end up going somewhere you don't want them to go.
The default behavior of everything going to the next defined step is not helpful for doing that, and in fact is quite frustrating because you don't want unrelated steps to accidentally end up on one of the tasks in your custom failure track.
And you can't use fail for custom-track steps becase that breaks magnetic_to for some reason.
I was finding myself very in need of something like this, and was about to write my own DSL, but then I discovered this. I still think it needs a better DSL than this, but at least they provided a way to do this. Much needed.
For this example, I might write something like this:
step :decide_type, Output(Activity::Left, :credit_card) => Track(:with_credit_card)
# Create the track, which would automatically create an implicit End with the same id.
Track(:with_credit_card) do
step :authorize
step :charge
end
I guess that's not much different than theirs. Main improvement is it avoids ugly need to specify end_id/end_task.
But that wouldn't actually be enough either in this example, because you would actually want to have a failure track there and a path doesn't have one ... so it sounds like Subprocess and a new self-contained ProcessCreditCard Railway would be the best solution for this particular example... Subprocess is the ultimate in flexibility and gives us all the flexibility we need)
But what if you had a path that you needed to direct to from 2 different tasks' outputs?
Example: I came up with this, but it takes a lot of effort to keep my custom path/track hidden/"isolated" and prevent other tasks from automatically/implicitly going into those steps:
class Example::ValidationErrorTrack < Trailblazer::Activity::Railway
step :validate_model, Output(:failure) => Track(:validation_error)
step :save, Output(:failure) => Track(:validation_error)
# Can't use fail here or the magnetic_to won't work and Track(:validation_error) won't work
step :log_validation_error, magnetic_to: :validation_error,
Output(:success) => End(:validation_error),
Output(:failure) => End(:validation_error)
end
puts Trailblazer::Developer.render o
Reloading...
#<Start/:default>
{Trailblazer::Activity::Right} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=validate_model>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=validate_model>
{Trailblazer::Activity::Left} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Right} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=save>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=save>
{Trailblazer::Activity::Left} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Right} => #<End/:success>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Left} => #<End/:validation_error>
{Trailblazer::Activity::Right} => #<End/:validation_error>
#<End/:success>
#<End/:validation_error>
#<End/:failure>
Now attempt to do it with Path... Does the Path() have an ID we can reference? Or maybe we just keep a reference to the object and use it directly in 2 different places?
class Example::ValidationErrorTrack::VPathHelper1 < Trailblazer::Activity::Railway
validation_error_path = Path(end_id: "End.validation_error", end_task: End(:validation_error)) do
step :log_validation_error
end
step :validate_model, Output(:failure) => validation_error_path
step :save, Output(:failure) => validation_error_path
end
o=Example::ValidationErrorTrack::VPathHelper1; puts Trailblazer::Developer.render o
Reloading...
#<Start/:default>
{Trailblazer::Activity::Right} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=validate_model>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=validate_model>
{Trailblazer::Activity::Left} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Right} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=save>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Right} => #<End/:validation_error>
#<Trailblazer::Activity::TaskBuilder::Task user_proc=save>
{Trailblazer::Activity::Left} => #<Trailblazer::Activity::TaskBuilder::Task user_proc=log_validation_error>
{Trailblazer::Activity::Right} => #<End/:success>
#<End/:success>
#<End/:validation_error>
#<End/:failure>
It's just too bad that:
step :direct_debit
I don't think we would/should really want to make this the "success" (Right) path and :credit_card be the "failure" (Left) track.
Maybe it's okay to repurpose Left and Right for something other than failure/success ... but only if we can actually change the default semantic of those signals/outputs. Is that possible? Maybe there's a way to override or delete the default outputs?
Patching has no implicit, magical side-effects and is strongly encouraged to customize flows for a specific case in a quick and consise way.
While you could nest an activity into another manually, the Subprocess macro will come in handy.
The macro automatically wires all of Validate’s ends to the known counter-part tracks.
In both filters, you’re able to rename and coerce variables. This gives you a bit more control than the simpler DSL.
It's recommended to configure this library by setting environment variables.
How do you know if source maps are working correctly? Try adding a syntax error to one of your assets and use the console to debug. Does it show the correct file and source location? Or does it reference the top level application.js file?
That’s it. If you have a previous “precompile” array, in your app config, it will continue to work. For continuity sake I recommend moving over those declarations to your manifest.js file so that it will be consistent.
And they are not the only way to handle errors.
And a word of warning. If you haven’t come across things like monads before, they might seem really… different. Working with tools like these takes a mind shift. And that can be hard work to start with.
The legendary cfp-app will become a Rails-to-TRB refactoring tutorial.
a framework containing the basic assumptions, ways of thinking, and methodology that are commonly accepted by members of a scientific community. such a cognitive framework shared by members of any discipline or group:
ActiveModel provides a powerful framework for defining callbacks. ActiveInteraction hooks into that framework to allow hooking into various parts of an interaction's lifecycle.
This probably looks a little different than you're used to. Rails commonly handles this with a before_filter that sets the @account instance variable.
{a: 1, b: 2, c: 3, d: 4} => {a:, b:, **rest} # a == 1, b == 2, rest == {:c=>3, :d=>4}
equivalent in javascript:
{a, b, ...rest} = {a: 1, b: 2, c: 3, d: 4}
Not a bad replacement for that! I still find javascript's syntax a little more easily readable and natural, but given that we can't use the same syntax (probably because it would be incompatible with existing syntax rules that we can't break for compatibility reasons, unfortunately), this is a pretty good compromise/solution that they've come up with.
In Ruby 3 we now have a “rightward assignment” operator. This flips the script and lets you write an expression before assigning it to a variable. So instead of x = :y, you can write :y => x
Nevermind, I use now reform-rails
@adisos if reform-rails will not match, I suggest to use: https://github.com/orgsync/active_interaction I've switched to it after reform-rails as it was not fully detached from the activerecord, code is a bit hacky and complex to modify, and in overall reform not so flexible as active_interaction. It has multiple params as well: https://github.com/orgsync/active_interaction/blob/master/spec/active_interaction/modules/input_processor_spec.rb#L41
I'm not sure what he meant by:
fully detached from the activerecord I didn't think it was tied to ActiveRecord.
But I definitely agree with:
code is a bit hacky and complex to modify
I don't think seeing it in Rails PRs naturally means we should do it blankly. Put it another way, what's the justification in those PRs for doing it?
class FormsController < ApplicationController class SearchForm < ActiveModel::Form
I kind of like how they put the form class nested directly inside the controller, although I would probably put it in its own file myself, unless it was quite trivial.
Some people believed I argued that object orientation is bad simply because extends has problems, as if the two concepts are equivalent. That's certainly not what I thought I said, so let me clarify some meta-issues.
first sighting: meta-issue 
companies want to promote what the technology can do, so they de-emphasize that the way in which you do it is less than ideal
And just because a feature or idiom is commonly used does not mean you should use it either.
If you think you’ve conveyed something but the other person hears something completely different, is that their fault or yours?
From my perspective the onus is on you to consider not just the words coming out of your mouth, but how they are received.
Everyone has their own background and context that they overlay on top of what they hear. It’s our jobs as communicators to consider that perspective and to adjust the way we communicate accordingly. If we do, we stand a better chance of persuading them to agree with our point of view.
People often hear what they think should be said, not the words that are actually spoken. This comes from the tendency of people to think faster than they talk. A listener makes assumptions about what they expect because their minds race ahead. This can be especially problematic when you misinterpret what your boss said.
My understanding of "programming to an interface" is different than what the question or the other answers suggest. Which is not to say that my understanding is correct, or that the things in the other answers aren't good ideas, just that they're not what I think of when I hear that term.