JSON support:
sqlite can parse json for inputs.
JSON support:
sqlite can parse json for inputs.
The files will have the same EXIF data they had when originally updated. Any details added to your photos after upload will be compiled in a separate JSON file.
The downloads will include original exif data. If that has been altered (e.g. location or time (NB I adjusted some for diff timezones)) the alterations will be provided as JSON
pokemonDataDictionary := STONJSON fromString: pokemonRawData
A través de este código (STONJSON) podremos sustraer los datos de manera ligera a fin de contar con el diccionario de los datos., por otro lado, para tener una estructura de los datos se recomienda el navegador Mozilla Firefox, toda vez que tiene una interfaz nativa para ver los datos con más facilidad.
A continuación se ilustra un ejemplo de la visualización de JSON:
ormato ampliamente utilizado en el intercambio de datos en la web
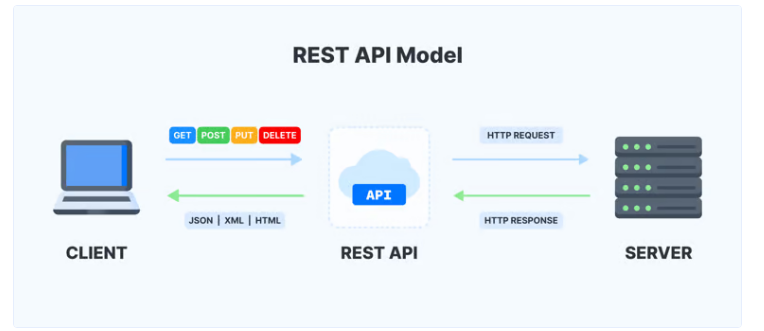
Dicho formato (JSON) también es comúnmente utilizado para el desarrollo de interfaces de programación de aplicaciones (API REST), por ejemplo, en las Bibliotecas universitarias se utiliza usualmente para el vaciado de datos entre los sistemas de información académicos con los ILS para descargar/actualizar los datos de los estudiantes matriculados en una Universidad sin necesidad de hacer cargas por archivo txt, xls, etc.
JSON
Meh. Verbose, bad types, needs parsing.
JSON HAL
Ajv generates code to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
application/xml: data-size: XML very verbose, but usually not an issue when using compression and thinking that the write access case (e.g. through POST or PUT) is much more rare as read-access (in many cases it is <3% of all traffic). Rarely there where cases where I had to optimize the write performance existence of non-ascii chars: you can use utf-8 as encoding in XML existence of binary data: would need to use base64 encoding filename data: you can encapsulate this inside field in XML application/json data-size: more compact less that XML, still text, but you can compress non-ascii chars: json is utf-8 binary data: base64 (also see json-binary-question) filename data: encapsulate as own field-section inside json
If the JSON o
نکته خیلی مهمی که میگه اینه که حتما باید Value ها حاوی کلید باشند مگرنه به مشکل میخوره
request.get_json()
چه تابع جالبی که میاد اطلاعات JSON را به Python تبدیل می کند
s:
قوانین تبدیل JSON به Python dict: اولا اگر در Json حالت Key و Value داشته باشد، در پایتون به صورت Dictionary است. دوما آرایه در Json به List در پایتون تبدیل می شود. سوما Value هایی که داخل " " باشد به Sting در پایتون تبدیل می شود. چهارما باحاله نگاه کن :) پنجما اعدادی که " " نداشته باشد به اعداد تبدیل می شود.
In P
هر وقت اسم JSON پیش می اید نام POSTMAN می درخشد
Usin
حالا رفت سراغ Json چون خیلی بهتر از Query String و Form Data براد اطلاعات را میفرسته. برای اطلاعات پیچیده تر بهتر است.
Exactly my thoughts on the matter! I'm coming from XML SOAP background and concept of schema just got into my blood and JSON documents rather don't announce their schema. To me it's whether server "understands" the request or not. If server doesn't know what "sales_tax" is then it's simply 400: "I have no idea what you sent me but definitely not what I want.".
Pitfall #1: Server-Side Rendering Attacker-Controlled Initial State
```html
<script>window.__STATE__ = ${JSON.stringify({ data })}</script>```
One option is to use the serialize-javascript NPM module to escape the rendered JSON.
html
{
username: "pwned",
bio: "</script><script>alert('XSS Vulnerability!')</script>"
}
This is risky because JSON.stringify() will blindly turn any data you give it into a string (so long as it is valid JSON) which will be rendered in the page. If { data } has fields that un-trusted users can edit like usernames or bios, they can inject something like this:
json
{
username: "pwned",
bio: "</script><script>alert('XSS Vulnerability!')</script>"
}
Sometimes when we render initial state, we dangerously generate a document variable from a JSON string. Vulnerable code looks like this:
```html
<script>window.__STATE__ = ${JSON.stringify({ data })}</script>```
console
$ curl -LH "Accept: application/vnd.schemaorg.ld+json" https://doi.org/10.5438/4K3M-NYVG
{
"@context": "http://schema.org",
"@type": "ScholarlyArticle",
"@id": "https://doi.org/10.5438/4k3m-nyvg",
"url": "https://blog.datacite.org/eating-your-own-dog-food/",
"additionalType": "BlogPosting",
"name": "Eating your own Dog Food",
"author": {
"name": "Martin Fenner",
"givenName": "Martin",
"familyName": "Fenner",
"@id": "https://orcid.org/0000-0003-1419-2405"
},
"description": "Eating your own dog food is a slang term to describe that an organization should itself use the products and services it provides. For DataCite this means that we should use DOIs with appropriate metadata and strategies for long-term preservation for...",
"license": "https://creativecommons.org/licenses/by/4.0/legalcode",
"version": "1.0",
"keywords": "datacite, doi, metadata, FOS: Computer and information sciences",
"inLanguage": "en",
"dateCreated": "2016-12-20",
"datePublished": "2016-12-20",
"dateModified": "2016-12-20",
"isPartOf": {
"@id": "https://doi.org/10.5438/0000-00ss",
"@type": "CreativeWork"
},
"citation": [
{
"@id": "https://doi.org/10.5438/0012",
"@type": "CreativeWork"
},
{
"@id": "https://doi.org/10.5438/55e5-t5c0",
"@type": "CreativeWork"
}
],
"schemaVersion": "http://datacite.org/schema/kernel-4",
"periodical": {
"@type": "Series",
"identifier": "10.5438/0000-00SS",
"identifierType": "DOI"
},
"publisher": {
"@type": "Organization",
"name": "DataCite"
},
"provider": {
"@type": "Organization",
"name": "datacite"
}
}
The usefulness of JSON is that while both systems still need to agree on a custom protocol, it gives you an implementation for half of that custom protocol - ubiquitous libraries to parse and generate the format, so the application needs only to handle the semantics of a particular field.
To be clear: when PeterisP says parse the format, they really mean lex the format (and do some minimal checks concerning e.g. balanced parentheses). To "handle the semantics of a particular field" is a parsing concern.
https://github.com/CondeNast/atjson
They're using annotations in this context more like CSS, but instead of adding the markup into the content as is done in HTML and processing it, they've physically separated the text and the markup entirely and are using location within the text to indicate where the formatting should take place.
If you want to see what an activity stream looks like, and your browser renders JSON nicely, just grab a random outbox and have a look.)
https://botsin.space/users/grigornaregatsi/outbox?page=true
Of course, CSV is less flexible than JSON. It's suitable when you have a list of items with mostly the same properties, and no nested structures.
At 100,000 entries, this list would be 2.4 MB (that's ~63% less than the JSON)
CSV is a format that's more lightweight than JSON and super well suited to streaming.
Those methods will wait until the entire response has been downloaded, and then parse it. That's because JSON is not a streaming format
To consume JSON in a streaming way, use jq
JSON is ubiquitous, more lightweight than XML but still flexible enough to represent any data structure you typically need
To summarize the three options we’ve seen, as well as a streaming ijson-based solution:
Comparison of 4 Python's JSON libraries
Spring Boot 处理 Long 类型的 json 数据,前端调用精度丢失,变成 00
ObjectMapper @JsonProperty 不生效问题处理(kotlin)
JSON is a similar, perhaps even more popular, format (and almost[!] a subset of YAML 1.2).
almost eh?
Jackson 通过自定义注解来控制 json key 的格式
为什么说JSON不适合做配置文件?
https://micro.blog/posts/search?q=indieweb
an alternate form for micro.blog search functionality
The @id keyword allows you to give a node a URI. This URI identifies the node. See Node Identifiers in the JSON-LD spec. (The equivalent in Microdata is the itemid attribute, and the equivalent in RDFa Lite is the resource attribute.)
pointer: type: string description: A string containing a JSON pointer to the specific field within a received JSON body that caused the problem, e.g. '/data/attributes/title' to refer to the `title` property within the `attributes` object that is a child of the top level `data` object. example: /data/attributes/title
A workaround you can use is to move additionalProperties to the extending schema and redeclare the properties from the extended schema.
Because additionalProperties only recognizes properties declared in the same subschema, it considers anything other than “street_address”, “city”, and “state” to be additional. Combining the schemas with allOf doesn’t change that.
It’s important to note that additionalProperties only recognizes properties declared in the same subschema as itself. So, additionalProperties can restrict you from “extending” a schema using Schema Composition keywords such as allOf. In the following example, we can see how the additionalProperties can cause attempts to extend the address schema example to fail.
In your scenario, which many, many people encounter, you expect that properties defined in schema1 will be known to schema2; but this is not the case and will never be.
When you do: "allOf": [ { "schema1": "here" }, { "schema2": "here" } ] schema1 and schema2 have no knowledge of one another; they are evaluated in their own context.
I'm not sure if there's a reason why additionalProperties only looks at the sibling-level when checking allowed properties but IMHO this should be changed.
It's unfortunate that additionalProperties only takes the immediate, sibling-level properties into account
additionalProperties applies to all properties that are not accounted-for by properties or patternProperties in the immediate schema.
annotation meta: may need new tag: applies to siblings only or applies to same level only
additionalProperties here applies to all properties, because there is no sibling-level properties entry - the one inside allOf does not count.
You have stumbled upon the most common problem in JSON Schema, that is, its fundamental inability to do inheritance as users expect; but at the same time it is one of its core features.
unevaluatedProperties is like additionalProperties, except that it can "see through" $ref and "see inside" allOf, anyOf, oneOf, if, then, else
I think the answer lies here: Cant see into oneOf or allOf etc. This, I think, is the distinguishing difference between additionalProperties and unevaluatedProperties.
However, unevaluatedProperties has dynamic behavior, meaning that the set of properties to which it applies cannot be determined from static analysis of the schema (either the immediate schema object or any subschemas of that object).
annotation meta: may need new tag:
dynamic behavior vs. static analysis [not quite parallel]
or can we reuse something else like?: lexical semantics vs. run-time semantics
unevaluatedProperties is similar to additionalProperties in that it has a single subschema, and it applies that subschema to instance properties that are not a member of some set.
Also, some Specification constraints cannot be represented with the JSON Schema so it's highly recommended to employ other methods to ensure compliance.
What I want is to use "additionalProperties: false" to validate a union of schemas, but it seems it isn't possible. I already tried with sevaral different combination, but I didn't make it works.
additionalProperties: false works on it, but not along with allOf, because only validate one schema or another.
allOf takes an array of object definitions that are validated independently but together compose a single object.
The latest (draft 2020-12) version of JSON Schema supports the unevaluatedProperties vocabulary (see here). This is quite a useful feature, and facilitates stricter validation while composing properties from multiple sub-schemas (using e.g. allOf) than would otherwise possible.
OAS 3.1 uses all of JSON Schema draft 2020-12 including unevaluatedProperties. You won't find direct references to unevealuatedProperties in the OAS spec because it links to the JSON Schema spec instead of duplicating it's contents.
This object is a superset of the JSON Schema Specification Draft 2020-12.
linked from: https://github.com/json-schema-org/json-schema-spec/issues/515#issuecomment-369842228
refactored using:
JSON Schema allows for additionalProperties both a boolean or an object value. true is interpreted as "additional properties follow no restrictions", false means "no additional restrictions", and an object is interpreted as a JSON schema applied to the property values (the empty object is thus equivalent to true).
The vendor prefix (vnd.) indicates that it is custom for this vendor.
The +json indicates that it can be parsed as JSON, but the media type should define further semantics on top of JSON.
05:03 Linking Zotero to Obsidian
https://www.youtube.com/watch?v=D9ivU_IKO6M Zotero管理论文的,不知道网页文章能否,如果可以,那么通过notion自制的信息管理系统就像是重复造轮子。看来我一直在重复重复造轮子···唉,metadata自动生成的json文件与ob进行一种链接。
bash
curl -H 'Accept: application/ld+json' https://musicbrainz.org/artist/20ff3303-4fe2-4a47-a1b6-291e26aa3438
When you see a job post mentioning REST or a company discussing REST Guidelines they will rarely mention either hypertext or hypermedia: they will instead mention JSON, GraphQL(!) and the like.
The creator of GraphQL admits this. During his presentation on the library at a Facebook internal conference, an audience member asked him about the difference between GraphQL and SOAP. His response: SOAP requires XML. GraphQL defaults to JSON—though you can use XML.
Conclusion There are decades of history and a broad cast of characters behind the web requests you know and love—as well as the ones that you might have never heard of. Information first traveled across the internet in 1969, followed by a lot of research in the ’70s, then private networks in the ’80s, then public networks in the ’90s. We got CORBA in 1991, followed by SOAP in 1999, followed by REST around 2003. GraphQL reimagined SOAP, but with JSON, around 2015. This all sounds like a history class fact sheet, but it’s valuable context for building our own web apps.
json
{
"success": true,
"message": "User logged in successfully",
"data": {
"user": {
"id": 2,
"name": "Client",
"client_id": 1,
"email": "client@clickapps.co",
"gender_label": null,
"gender": null,
"mobile": "123654789",
"code_country": "00967",
"birth_date": null,
"avatar": "http://localhost:3000/default_image.png",
"sms_notification": true,
"is_mobile_verified": false,
"otp": {
"otp": "8704"
},
"client_city": {
"id": 3,
"name_ar": "الرياض",
"name_en": "Riadh",
"name": "Riadh",
"status": 1,
"status_label": "Active",
"country": {
"id": 2,
"name": "Kingdub saudi Arab",
"code_country": "ksa",
"avatar": "http://localhost:3000/default_image.png",
"status": 1,
"status_label": "Active"
}
},
"client_locations": [
{
"id": 1,
"client_id": 1,
"latitude": "0.0",
"longitude": "0.0",
"address": "169 Rath Rapids",
"address_ar": "964 Michale Parkway",
"address_en": "169 Rath Rapids",
"building_name": "building_name",
"location_type": 1,
"location_type_label": "Home",
"apartment_name": null,
"require_permission": false,
"city": null,
"zip_code": null
}
]
},
"role": "client",
"token": "eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MiwibmFtZSI6IkNsaWVudCIsImVtYWlsIjoiY2xpZW50QGNsaWNrYXBwcy5jbyIsIm1vYmlsZSI6IjEyMzY1NDc4OSIsImltYWdlIjoiL2RlZmF1bHRfaW1hZ2UucG5nIiwiYWRtaW4iOmZhbHNlLCJpYXQiOjE1NDc5MjU0MzIsImV4cCI6MTU1MDUxNzQzMn0.4Vyjd7BG7v8AFSmGKmIs4VM2FBw3gOLn97Qdf6U4jxU"
}
}
``` HTTP/1.1 200 OK Content-Type: application/ld+json Link: http://api.example.com/doc/; rel="http://www.w3.org/ns/hydra/core#apiDocumentation"
{ "@context": "http://www.w3.org/ns/hydra/context.jsonld", "@graph": [{ "@id": "http://api.example.com/people", "@type": "hydra:Collection", "api:personByName": "api:PersonByNameTemplate" }, { "@id": "http://api.example.com/events", "@type": "hydra:Collection", "api:eventByName": "api:EventByNameTemplate" } } ```
The GS1 Web Vocabulary collects terms defined in various GS1 standards and data systems and made available for general use following Linked Data principles. It is designed as an extension to schema.org and, where relevant, mappings and relationships arising from that vocabulary are made explicit. The initial focus of the GS1 Web Vocabulary is consumer-facing properties for clothing, shoes, food beverage/tobacco and properties common to all products.
```html
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": ["MathSolver", "LearningResource"], "name": "An awesome math solver", "url": "https://www.mathdomain.com/", "usageInfo": "https://www.mathdomain.com/privacy", "inLanguage": "en", "potentialAction": [{ "@type": "SolveMathAction", "target": "https://mathdomain.com/solve?q={math_expression_string}", "mathExpression-input": "required name=math_expression_string", "eduQuestionType": ["Polynomial Equation","Derivative"] }], "learningResourceType": "Math solver" }, { "@context": "https://schema.org", "@type": ["MathSolver", "LearningResource"], "name": "Un solucionador de matemáticas increíble", "url": "https://es.mathdomain.com/", "usageInfo": "https://es.mathdomain.com/privacy", "inLanguage": "es", "potentialAction": [{ "@type": "SolveMathAction", "target": "https://es.mathdomain.com/solve?q={math_expression_string}", "mathExpression-input": "required name=math_expression_string", "eduQuestionType": ["Polynomial Equation","Derivative"] }], "learningResourceType": "Math solver" } </script>```