This is a page I found while trying to learn the syntax of Dataview (an Obsidian plugin that allows database queries on one's own vault).
326 Matching Annotations
- Jun 2023
-
blacksmithgu.github.io blacksmithgu.github.io
-
math.stackexchange.com math.stackexchange.com
-
As opposed to MathOverflow.net, Math SE is
Q&A site for people studying math at any level & professionals in related fields source
I learned this from this answer on the Math.Meta.SE site
Tags
Annotators
URL
-
-
forums.ankiweb.net forums.ankiweb.net
-
Error opening file for writing: mpv.exe Anki Desktop
Ran into the same issue when reinstalling Anki. The solution was (as dae suggested) to use Task Manager to close
mpvunder "Background processes".Afterwards, the Anki Setup program ran without issue.
-
-
www.brainfacts.org www.brainfacts.org
-
Found this webpage for a 3D brain model when someone (maybe frymatic?) mentioned a region of the brain I was having trouble imagining.
-
-
www.alignmentforum.org www.alignmentforum.org
-
An article recommended to me by Dalton V. that he thought I'd enjoy and appreciate. Looks like AlignmentForum is one of those "online Rationalist communities" (like LessWrong, SlateStarCodex, etc.).
The blog post "The Waluigi Effect" by Cleo Nardo touches on a variety of interesting topics:
- the Waluigi effect
- Simulator Theory
- Derrida's "there is no outside text"
- RLHF (Reinforcement Learning from Human Feedback) and potential limits
-
- May 2023
-
oeis.org oeis.org
-
Related to this note:
Haris Neophytou wants to apply a "primality sieve" (namely the sieve of Eratosthenes) to this list. I think it's so he can construct the primes that divide the order of the monster group \(M\)
-
-
oeis.org oeis.org
-
Trying to follow an argument given here: https://youtu.be/mFZs7uGwNBo?t=3413
The sequence A002267 is claimed by Haris Neophytou to be the 1st 15 "super singular prime numbers" (ie, the primes that divides the order of the Monster Group). The order is the number of elements in the group.
Note that the last 3 elements [47, 59, 71] multiply to give the number of dimensions in which the Monster group exists: 196,883.
Neophytou believes A002267 gives a different way of looking at the monster group \(M\).
Around 1:02:45, Neophytou says he'll start from A002822...
(a list of numbers, \(m\text{,}\) such that \(6m - 1\) and \(6m + 1\) are twin primes)
... and construct "the minimal order of the monster" (what?)
Tags
Annotators
URL
-
- Jan 2023
-
pipeittodevnull.github.io pipeittodevnull.github.io
-
This was recommended in the Obsidian Members Group Discord for teaching someone how to setup an Obsidian vault with a GitHub repo for version control. Kamil claimed it was more clear than an intro article by [[Bryan Jenks]] on how to setup GitHub with Obsidian. Jenks eventually made a video about the process.
-
-
www.health.harvard.edu www.health.harvard.edu
-
I came here looking for the glycemic index for bananas to see if this might explain a friends delayed reaction to consuming high amounts of salicylate. That is, the pain they experienced as a burn in the mouth/tongue only occurred after consuming a banana. A prior search tentatively suggested that spikes in insulin (which occur with foods high in glycemic index and glycemic load) can cause inflammation to the affected region which sends white blood cells as a response and can cause swelling and increased sensitivity to pain.
-
-
www.ncbi.nlm.nih.gov www.ncbi.nlm.nih.gov
-
Therefore, we propose that flow and hyperfocus are the same phenomenon. Although we are mindful that just because two phenomena are descriptively similar, they are not necessarily mechanistically identical, there is no evidence to suggest that either flow or hyperfocus are distinct.
Ashinoff and Abu-Akel propose an equivalence between "flow" and "hyperfocus". They mention later in this paper that "flow" is more often used in positive psychology literature whereas "hyperfocus" is more often used in psychiatric literature. Even so, they also qualify that they may just appear to be the same (ie, descriptively similar) while having a different cause (ie, mechanism of action).
-
-
mythcosmologysacred.com mythcosmologysacred.com
-
A paper recommended in the presentation "William Rowlandson - Image, Imagination And The Imaginal" filmed at Breaking Convention 2017.
Seems to be a different take on the "imaginal" than John Vervaeke's suggestion that the "imaginal" is using imagination for the sake of training and enhancing sensory awareness.
-
-
en.wikipedia.org en.wikipedia.org
-
A term recommended by Eve regarding an interdisciplinary approach that accounts for multiple feedback loops within complex systems. Need to confer complex systems science to see if ADHD is already addressed in that domain.
-
-
www.toastmasters.org www.toastmasters.org
-
An organization recommended to me for helping improve compressing complicated arguments into a more digestible for oration & verbal discussion. Mentioned by 2 separate people (Travis & Mavis).
-
-
www.reddit.com www.reddit.com
-
There is an add on called "Spaced Repetition" that you may find useful. It can do both flashcards and full notes.
Look into plugin "Spaced Repetition" for Obsidian
-
-
s4be.cochrane.org s4be.cochrane.org
-
High-level view of the 3 different types of heterogeneity (clinical, methodological, statistical). I used these definitions as the basis for some Anki cards
-
-
www.inc.com www.inc.com
-
Article recommended by robot for songs to reduce anxiety
-
- Dec 2022
-
www.embopress.org www.embopress.org
-
I came here after recalling a critique by Bessel van der Kolk's "The Body Keeps the Score: Brain, Mind, and Body in the Healing of Trauma" regarding the disease model and it's negative impact on adequately helping people with trauma. van der Kolk's critique was similar to Marc Lewis' critique of the disease model as it applies to addiction from "The Biology of Desire: Why Addiction Is Not a Disease". This made me wonder what the term "disease" actually means and whether or not some general consensus existed within the medical community. This article suggests there is no such consensus.
This article is by Jackie Leach Scully who holds a "PhD in cellular pathology, University of Cambridge; BA (Hons) in biochemistry, University of Oxford; MA in psychoanalytic studies, Sheffield University".
Scully does several insightful things in this paper the following are the ones that were most salient to me upon the first read: - distinguishes "disease" from "disability" - contrasts the "social model" and "medical model" perspectives on "disability" - The "medical model" referred to here is probably what Lewis & van der Kolk are critiquing as the "disease model".<br /> - Are the "medical" and "disease" model different? - the social model seems to have arisen as a response to the inadequacy of the medical model
- "The social model's fundamental criticism of the medical model is that it wrongly locates 'the problem' of disability in biological constraints, considering it only from the point of view of the individual and neglecting the social and systemic frameworks that contribute to it. The social model distinguishes between impairment (the biological substrate, such as impaired hearing) and the disabled experience. In this view the presence of impaired hearing is one thing, while the absence of subtitling on TV is quite another, and it is the refusal of society to make the necessary accommodations that is the real site of disability. A social model does not ignore biology, but contends that societal, economic and environmental factors are at least as important in producing disability."- brings up a subtle point that there are two jumps "from gene to phenotype, and from phenotype to experience" and that some of the arguments mentioned "suggest that the 'harm' of the impairment is not straightforwardly related to phenotype. What ought to concern us about disease and disability is the disadvantage, pain or suffering involved, and in a sense the impairment is always a kind of surrogate marker for this experience."
-
-
plato.stanford.edu plato.stanford.edu
-
I came to this page after reading the "About the Author (The Second Right Answer)" page of Roger von Oech's "A Whack on the Side of the Head: How You Can Be More Creative" which was mentioned by Kevin Bowers in his discussion with John Vervaeke titled "Principles & Methods for Achieving a Flow State | Voices w/ Vervaeke | John Vervaeke & Kevin Bowers".
von Oech stated that
I wrote my doctoral dissertation on the twentieth century German philosopher Ernst Cassirer, the last man to know everything. From him, I learned that it's good to be a generalist, and that looking at the Big Picture helps to keep you flexible.
This was a surprising reference since Bowers stated that the book was written for helping entrepreneurs become more creative; the book seems more widely applicable based on the examples and exercises given in the first 20 pages.
Cassirer appears to bridge between the continental and analytic traditions in philosophy. Cassirer's touching on mathematics, aesthetics, and ethics reminds me of - John Vervaeke's work - ie, the process of relevance realization and his neo platonic, transformational reading of ancient texts - Forrest Landry work - ie, his magnum opus "An Immanent Metaphysics" which he purports to be pointing to a foundation between ontology, epistemology, and ethics. Recently, IDM (Immanent Domain Metaphysics) made more sense to me when I attempted to translat the 3 axioms and 3 modalities into language from category theory
The following seem important and related somehow: 1. the symbolic process 2. the process of abstraction 3. the process of representation
Maybe these are related to the means by which one can can transcend their current self? ie, is it through particular symbolic practices that one can more easily shed one identity and acquire another?
Also, are 1., 2., and 3. different aspects of the same thing/event?
-
-
-
simonhong commented Dec 11, 2020 @pitsi That homepage option is related with below homepage option. If homepage is configured, new tab will show that url. Loading local html file in new tab is not supported.
I came here looking for a way to change the default New Tab Page in Brave to open up to my Hypothes.is bookmarks.
This was passage was only part of the solution. The full solution is as follows: 1. Go to Settings > Appearances - brave://settings/appearance 2. Under "Show home button", select website you want to open as New Tab Page 3. Go to Settings > New Tab Page - brave://settings/newTab 4. Change from "Dashboard" to "Homepage"
-
-
www.amazon.com www.amazon.com
-
I'm a software engineer and ignored wrist and forearm pain for almost a decade. Finally it got really bad so I had to take some steps to improve my condition. I purchased 5 vertical mouses, 1 of the more expensive ones and 4 cheaper ones, to see how they compare.My conclusion is that you just can't judge how a mouse will fit you from reviews. Even reviewers with small hands like mine, had opinions I wholly disagreed with. And I think it's because people use the mouse in a variety of ways. For example, some people rest their hand entirely on their mouse while others use a "floating" hand. Some anchor their wrist and move their hand, while others anchor their elbow and move their forearm. Some have small hands; but, wrist pads and wrist braces raise the wrist, cancelling the problem of (or even overcompensating for) small hands.Especially if you're like me and rest the entire weight of your hand and also anchor your wrist, you're not going to be happy with *any* vertical mouse *at first*, because your hand will feel like it's sagging down the mouse, and when you try to unsag your hand the mouse will feel insecure because you're unanchored your wrist. (This is where the cushion of a wrist brace helped immensely. After 2 weeks I was able to use the mouse even without the wrist brace. But man, did I hate all 5 mouses at first.)Anyway, moral of the story: Bite the bullet and purchase a few mouses. $150 gets you 1 quality mouse and 1 or 2 cheaper ones.Here's a wrist brace I love because it's not plastic-stiff (no affiliation whatsoever): https://www.amazon.com/gp/product/B072392YGD.Here are the products I compared:- https://www.amazon.com/gp/product/B073B12MS6 (Jelly Comb)- https://www.amazon.com/gp/product/B07RK96WF8 (VicTsing)- https://www.amazon.com/gp/product/B00BIFNTMC (Anker)- https://www.amazon.com/gp/product/B07BFCVJZC (Lekvey)- https://www.amazon.com/gp/product/B07FNJB8TT (Logitech MX)Miscellaenous:- There's a reason I didn't try the famous Evoluent VM4R. The updated model is getting flack for not living up to its predecessor, and its predecessor apparently hasn't shipped a driver for Mac OSX Catalina, which is what I'm on.- The Anker and Lekvey have exactly the same chassis (and therefore size). The Anker is battery powered while the Levkey is charged. The VicTsing is slightly larger than those. The Jelly Comb is significantly smaller than any of them.- See photo attached for comparisons of things like click and scrollwheel feel. 3.0 out of 5 stars You can't judge comfort from reviews By Andrew Cheong on September 13, 2020 I'm a software engineer and ignored wrist and forearm pain for almost a decade. Finally it got really bad so I had to take some steps to improve my condition. I purchased 5 vertical mouses, 1 of the more expensive ones and 4 cheaper ones, to see how they compare.My conclusion is that you just can't judge how a mouse will fit you from reviews. Even reviewers with small hands like mine, had opinions I wholly disagreed with. And I think it's because people use the mouse in a variety of ways. For example, some people rest their hand entirely on their mouse while others use a "floating" hand. Some anchor their wrist and move their hand, while others anchor their elbow and move their forearm. Some have small hands; but, wrist pads and wrist braces raise the wrist, cancelling the problem of (or even overcompensating for) small hands.Especially if you're like me and rest the entire weight of your hand and also anchor your wrist, you're not going to be happy with *any* vertical mouse *at first*, because your hand will feel like it's sagging down the mouse, and when you try to unsag your hand the mouse will feel insecure because you're unanchored your wrist. (This is where the cushion of a wrist brace helped immensely. After 2 weeks I was able to use the mouse even without the wrist brace. But man, did I hate all 5 mouses at first.)Anyway, moral of the story: Bite the bullet and purchase a few mouses. $150 gets you 1 quality mouse and 1 or 2 cheaper ones.Here's a wrist brace I love because it's not plastic-stiff (no affiliation whatsoever): https://www.amazon.com/gp/product/B072392YGD.Here are the products I compared:- https://www.amazon.com/gp/product/B073B12MS6 (Jelly Comb)- https://www.amazon.com/gp/product/B07RK96WF8 (VicTsing)- https://www.amazon.com/gp/product/B00BIFNTMC (Anker)- https://www.amazon.com/gp/product/B07BFCVJZC (Lekvey)- https://www.amazon.com/gp/product/B07FNJB8TT (Logitech MX)Miscellaenous:- There's a reason I didn't try the famous Evoluent VM4R. The updated model is getting flack for not living up to its predecessor, and its predecessor apparently hasn't shipped a driver for Mac OSX Catalina, which is what I'm on.- The Anker and Lekvey have exactly the same chassis (and therefore size). The Anker is battery powered while the Levkey is charged. The VicTsing is slightly larger than those. The Jelly Comb is significantly smaller than any of them.- See photo attached for comparisons of things like click and scrollwheel feel. Images in this review 495 people found this helpful
Another helpful verified purchase Amazon review on some mice. I found this while looking for a mouse that was (1) ergonomic, (2) rechargeable, and (3) wireless.
Reviewer gives some thoughts on the different ways ppl use mice and how that effects they need (or lack thereof) for a wrist brace.
-
-
smile.amazon.com smile.amazon.com
-
I'm building a work from home setup for my wife with 34" Ultrawide LG monitor running macbook pro in closed display mode. We were using Apple Magic Mouse but we noticed alot of stress to the arm and decided to buy an ergonomic mouse. I bought four mice all together : Anker B2C, 2 of the Jellycomb (MV045 & MV09D) and iClever TM209G to compare. Out of the 4 mice, this iClever mice was the last one to come out of the box for the test and honestly I was kind of bummed out only to find out the same exact Jelly Comb MV045 mouse inside the box just with different branding. The iClever didn't have bluetooth where as the Jellycomb did. I honestly didn't even try setting this one up as the form factor was rather uncomfortable for us. Here's the deal, you get what you pay for. All mice performed a good job. Fairly easy to connect with included usb dongle. However, the cheaper jellycomb kept disconnecting when connecting using the dongle. Fortunately it also has bluetooth mode and the connection was much better. I prefer bluetooth over the usb dongle because the dongle takes one more usb port that could be available for other devices on my Caldigit Soho USB C Docking station! Anker mouse lacks bluetooth but I didn't have any issue with its wireless connection using the dongle.
A helpful Amazon review on 4 ergonomic wireless mice. I found this while looking for a mouse that was (1) ergonomic, (2) rechargeable, and (3) wireless. The viewer covered 4 different mice: - Anker B2C - 2 of the Jellycomb - MV045 - MV09D - iClever TM209G
This page is for the iClever, but the reviewer claims that it's just like the Jelly Comb MV045.
-
-
devblogs.microsoft.com devblogs.microsoft.com
-
PS C:\> Get-CimInstance win32_POINTINGDEVICE | select hardwaretype
Command for getting hardware type of mouse via Windows PowerShell.
-
-
dvps.highrez.co.uk dvps.highrez.co.uk
-
I came here after reading a couple articles (one on Super User & one on MS's help forums) recommending X-Mouse Button Control as a general way to disable back buttons on mice.
Note: this doesn't seem to work on Windows 11 for Microsoft USB IntelliMouse Optical.
-
-
math.stackexchange.com math.stackexchange.com
-
My freely downloadable Beginning Mathematical Logic is a Study Guide, suggesting introductory readings beginning at sub-Masters level. Take a look at the main introductory suggestions on First-Order Logic, Computability, Set Theory as useful preparation. Tackling mid-level books will help develop your appreciation of mathematical approaches to logic.
This is a reference to a great book "Beginning Mathematical Logic: A Study Guide [18 Feb 2022]" by Peter Smith on "Teach Yourself Logic A Study Guide (and other Book Notes)". The document itself is called "LogicStudyGuide.pdf".
It focuses on mathematical logic and can be a gateway into understanding Gödel's incompleteness theorems.
I found this some time ago when looking for a way to grasp the difference between first-order and second-order logics. I recall enjoying his style of writing and his commentary on the books he refers to. Both recollections still remain true after rereading some of it.
It both serves as an intro to and recommended reading list for the following: - classical logics - first- & second-order - modal logics - model theory<br /> - non-classical logics - intuitionistic - relevant - free - plural - arithmetic, computability, and incompleteness - set theory (naïve and less naïve) - proof theory - algebras for logic - Boolean - Heyting/pseudo-Boolean - higher-order logics - type theory - homotopy type theory
-
-
www.logicmatters.net www.logicmatters.net
-
for settling in a finite number of steps, whether a relevant object hasproperty P.Relatedly, the answer to a question Q is effectively decidable ifand only if there is an algorithm which gives the answer, again by adeterministic computation, in a finite number of steps.
Missing highlight from preceding page:
A property \( P \) is effectively decidible if and only if there is an algorithm (a finite set of instructions for a deterministic computation) ...
Isn't this related to the idea of left & right adjoints in category theory? iirc, there was something about the "canonical construction" of something X being the best solution to a particular problem Y (which had another framing like, "Problem Y is the most difficult problem for which X is a solution")
Different thought: the Curry-Howard-Lambek correspondance connects intuitionistic logic, typed lambda calculus, and cartesian closed categories.
-
-
projects.iq.harvard.edu projects.iq.harvard.eduHandouts1
-
I came here to get the handout for Markov chains mentions in Lecture 31: Markov chains | Statistics 110. Lectures give a great intuition behind the equations, their motivation, and their limitations.
-
- Nov 2022
-
www.researchgate.net www.researchgate.net
-
Think of "data" as thevegetables grown in this garden
Since next example states local data is like an "apple", and global data is like "all apples from one tree", replace "vegetables" with "produce".
-
-
www.wikiverse.io www.wikiverse.io
-
An independent initiative made by Owen Cornec who has also made many other beautiful data visualizations. Wikiverse vividly captures the fact that Wikipedia is a an awe-inspiring universe to explore.
Tags
Annotators
URL
-
-
www.healthline.com www.healthline.com
-
I came here looking for an image of the cerebellum, but found a much more helpful interactive 3d tool to understand parts of the brain.
-
-
www.dropbox.com www.dropbox.com
-
Article recommended by @wfinck. Based on backlinks, look like the author may be using Obsidian or Notion and syncing into Dropbox to create free published version of notes
-
-
www.cs.ucr.edu www.cs.ucr.edu
-
Dr. Miho Ohsaki re-examined workshe and her group had previously published and confirmed that the results are indeed meaningless in the sensedescribed in this work (Ohsaki et al., 2002). She has subsequently been able to redefine the clustering subroutine inher work to allow more meaningful pattern discovery (Ohsaki et al., 2003)
Look into what Dr. Miho Ohsaki changed about the clustering subroutine in her work and how it allowed for "more meaningful pattern discovery"
-
Eamonn Keogh is an assistant professor of Computer Science at the University ofCalifornia, Riverside. His research interests are in Data Mining, Machine Learning andInformation Retrieval. Several of his papers have won best paper awards, includingpapers at SIGKDD and SIGMOD. Dr. Keogh is the recipient of a 5-year NSF CareerAward for “Efficient Discovery of Previously Unknown Patterns and Relationships inMassive Time Series Databases”.
Look into Eamonn Keogh's papers that won "best paper awards"
-
http://www.cs.ucr.edu/~eamonn/meaningless.pdf Paper that argues cluster time series subsequences is "meaningless". tl;dr: radically different distributions end up converging to translations of basic sine or trig functions. Wonder if constructing a simplicial complex does anything?
Note that one researcher changed the algorithm to produce potentially meaningful results
-
-
www.health.harvard.edu www.health.harvard.edu
-
A quick and dirty guide to choosing "slow carbs" (low GLI) and "fast carbs" (high GLI). Purportedly, insulin spikes (from high GLI foods) and prevent amino acids from entering the blood brain barrier. Need to fact-check this
-
-
www.med.upenn.edu www.med.upenn.edu
-
J. Russell Ramsay, Ph.D.
Prof of clinical psychology in psychiatry. Specializes in CBT for ADHD. Think I orginally learned about from mentions by Russell Barkley, and listened to conversations of the ADHD reWired podcast
-
-
www.self.com www.self.com
-
Article on brown noise and it's impact on ADHD focus. Suggested by Adam A. Provides useful links to primary sources for experiments, topics, and people
-
-
-
“In order to talk to each other, we have to have words, and that’s all right. It’s a good idea to try to see the difference, and it’s a good idea to know when we are teaching the tools of science, such as words, and when we are teaching science itself,” Feynman said.
Maths, Logic, Computer Science, Chess, Music, and Dance
A similar observation could be made about mathematics, logic, and computer science. Sadly, public education in the states seems to lose sight that the formalisms in these domains are merely the tools of the trade and not the trade itself (ie, developing an understanding of the fundamental/foundational notions, their relationships, their instantiations, and cultivating how one can develop capacity to "move" in that space).
Similarly, it's as if we encourage children that they need to merely memorize all the movements of chess pieces to appreciate the depth of the game.
Or saying "Here, just memorize these disconnected contortions of the hand upon these strings along this piece of wood. Once you have that down, you've experienced all that guitar, (nay, music itself!) has to offer."
Or "Yes, once, you internalize the words for these moves and recite them verbatim, you will have experienced all the depth and wonder that dance and movement have to offer."
However, none of these examples are given so as to dismiss or ignore the necessity of (at least some level of) formalistic fluency within each of these domains of experience. Rather, their purpose is to highlight the parallels in other domains that may seem (at first) so disconnected from one's own experience, so far from one's fundamental way of feeling the world, that the only plausible reasons one can make to explain why people would waste their time engaging in such acts are 1. folly: they merely do not yet know their activities are absurd, but surely enough time will disabuse them of their foolish ways. 2. madness: they cannot ever know the absurdity of their acts, for "the absurd" and "the astute" are but two names for one and the same thing in their world of chaos. 3. apathy: they in fact do see the absurdity in their continuing of activities which give them no sense of meaning, yet their indifference insurmountably impedes them from changing their course of action. For how could one resist the path of least resistance, a road born of habit, when one must expend energy to do so but that energy can only come from one who cares?
Or at least, these 3 reasons can surely seem like that's all there possibly could be to warrant someone continuing music, chess, dance, maths, logic, computer science, or any apparently alien craft. However, if one takes time to speak to someone who earnestly pursues such "alien crafts", then one may start to perceive intimations of something beyond their current impressions
The contorted clutching of the strings now seems... coordinated. The pensive placement of the pawns now appears... purposeful. The frantic flailing of one's feet now feels... freeing. The movements of one's mind now feels... marvelous.
So the very activity that once seemed so clearly absurd, becomes cognition and shapes perspectives beyond words
-
-
www.cisco.com www.cisco.com
-
Meta-analysis statistical procedures provide a measure of the difference between two groups thatis expressed in quantitative units that are comparable across studies
The units are only "comparable across studies" if there weren't any mishaps (eg, clinical or methodological heterogeneity). If there's clinical heterogeneity, then we're probably comparing apples to oranges (ie, either participants, interventions, or outcomes are different among studies). If there's methodological heterogeneity, then that means there's a difference in study design
-
Quadrants I and II: The average student’s scores on basic skills assessments increase by21 percentiles when engaged in non-interactive, multimodal learning (includes using textwith visuals, text with audio, watching and listening to animations or lectures that effectivelyuse visuals, etc.) in comparison to traditional, single-mode learning. When that situationshifts from non-interactive to interactive, multimedia learning (such as engagement insimulations, modeling, and real-world experiences – most often in collaborative teams orgroups), results are not quite as high, with average gains at 9 percentiles. While notstatistically significant, these results are still positive.
I think this is was Thomas Frank was referring to in his YT video when he said "direct hands-on experience ... is often not the best way to learn something. And more recent cognitive research has confirmed this and shown that for basic concepts a more abstract learning model is actually better."
By "more abstract", I guess he meant what this paper calls "non-interactive". However, even though Frank claims this (which is suggested by the percentile increases shown in Quadrants I & II), no variance is given and the authors even state that, in the case of Q II (looking at percentile increase of interactive multimodal learning compared to interactive unimodal learning), the authors state that "results are not quite as high [as the non-interactive comparison], with average gains at 9 percentiles. While not statistically significant, these results are still positive." (emphasis mine)
Common level of signifcances are \(\alpha =.20,~.10,~.05,~.01\)
-
Paper gives surprisingly good overview of models of learning within the cognitive sciences up to 2008. Attempts to dispel myths and summarize the literature on multimodal learning. Link to paper on Semantic Scholar
-
Multimodal Learning Through Media:What the Research Says
A white paper written by Metiri Group commissioned by Cisco in 2008. I came here to fact check some claims on this YT video about a "Feynman Technique 2.0".
The claims were that
-
direct hands-on experience in unimodal learning is (on average) inferior to multi-modal learning that wasn't hand-on. viz., for "basic concepts", a more abstract learning model is better
-
"Once you get into higher-order concepts then hand-on experience is better"
Page 13 was displayed while making these claims.
These claims still need to be verified.
-
-
Scaffolding is the act of providing learners with assistance or support to perform a taskbeyond their own reach if pursued independently when “unassisted.”
Wood, Bruner, & Ross (1976) define scaffolding as what? (Metiri Group, Cisco Sytems, 2008) The act of providing learners with assistance or support to perform a task beyond their own reach if pursued independently when "unassisted."
What term do Wood, Bruner, & Ross (1976) define as "The act of providing learners with assistance or support to perform a task beyond their own reach if pursued independently when 'unassisted.'"? (Metiri Group, Cisco Sytems, 2008) Scaffolding
-
Schemas are chunks of multiple individual units of memory that are linked into a system ofunderstanding
How do Bransford, Brown, & Cocking (2000) define schemas? (Metiri Group, Cisco Sytems, 2008) As chunks of multiple individual units of memory that are linked into a system of understanding
What term is defined by Bransford, Brown, & Cocking (2000) to be "chunks of multiple individual units of memory that are linked into a system of understanding"? (Metiri Group, Cisco Sytems, 2008) Schemas.
-
Learning is defined to be “storage of automated schema in long-term memory.
How is learning defined by Sweller in 2002? (Metiri Group, Cisco Sytems, 2008) The storage of automated schema in long-term memory
What term does Sweller define as the "storage of automated schema in long-term memory"?
Tags
- to-do
- Thomas Frank
- learning
- chunks
- assistance
- stats
- education
- cognitive
- memory
- research article
- scaffolding
- system
- critiques
- meta-analysis
- fact-checking
- Metiri Group
- experience
- performance
- support
- psychology
- unimodal
- Cisco
- fact-checking solution
- hand-on
- long-term
- understanding
- multimodal
- Anki cards
- cognitive psychology
- storage
Annotators
URL
-
-
cccrg.cochrane.org cccrg.cochrane.org
-
PDF summary by Cochrane for planning a meta-analysis at the protocol stage. Gives guidance on how to anticipate & deal with various types of heterogeneity (clinical, methodological , & statistical). Link to paper
Covers - ways to assess heterogeneity - courses of action if substantial heterogeneity is found - methods to examine the influence of effect modifiers (either to explore heterogeneity or because there's good reason to suggest specific features of participants/interventions/study types will influence effects of the intervention. - methods include subgroup analyses & meta-regression
-
Statistical heterogeneity is the term given to differences in the effects of interventions and comesabout because of clinical and/or methodological differences between studies (ie it is a consequenceof clinical and/or methodological heterogeneity). Although some variation in the effects ofinterventions between studies will always exist, whether this variation is greater than what isexpected by chance alone needs to be determined.
If the statistical heterogeneity is larger that what's expected by chance alone, then what does that imply? That there's either clinical or methodological heterogeneity within the pooled studies.
What's the impact of the presence of clinical heterogeneity? The statistical heterogeneity (variation of effects/results of interventions) becomes greater than what's expected by chance alone
What's happens if methodological heterogeneity is present? The statistical heterogeneity (variation of effects/results of interventions) becomes greater than what's expected by chance alone
-
-
w3codemasters.in w3codemasters.in
-
I came to this page looking for a way to disable news stories in Windows 11 Widgets. I attempted one of the solutions (Disable Interests From Widgets To Turn Off News Feeds) but News recommendations still appeared.
Since I mainly wanted the Widget enabled for a calendar view, I decided against using Widgets altogether and settled for using the calendar in the notifications bar.
Another alternative I considered was to have 4 static Widgets pinned to obscure any news articles in the feed. However, unless one uses the insider Windows 11 build 25211 or later, Widget display will pop up from mouse hovering.
-
-
stackoverflow.com stackoverflow.com
-
Use the Get-ChildItem cmdlet with the -Recurse switch: Get-ChildItem -Path V:\Myfolder -Filter CopyForbuild.bat -Recurse -ErrorAction SilentlyContinue -Force
Useful PowerShell command to do recursive file search in Windows through PowerShell.
-
-
www.reddit.com www.reddit.com
-
anditails · 1 yr. agoDell Pro Support Engineer (3rd party)You don't need Support Assist on Windows 11. Enable the "Optional Updates" and it'll do all the drivers through Windows Update.It's fast, too. Far quicker than Support Assist!
Someone recommending to avoid using Dell SupportAssist on Windows 11. I came across this because I was trying to see if there was a way to update SA in order to ensure the driver iqvw64e.sys was removed. Related to the problem here. Uninstalling SupportAssist resolved the aforementioned problem since recursive file search through C drive failed to find driver iqvw64e.sys
Based on other comments in this thread, seems like it's best to let Windows Update handle the drivers. Will no longer use Dell SA and will utilize "Optional Updates" to handle drivers
Currently, the only perceived benefit from SA is automating support tickets submissions if product is under warranty. Last IT support experience with Dell was positive (they did the best they could), but they didn't know much about sys admin stuff on Windows (weren't very helpful in resolving issue without losing all files and installed software).
-
-
answers.microsoft.com answers.microsoft.com
-
The correct answer here is to uninstall the intel network driver completely because it is not supported anymore. Support Information for Intel® PROSet and Intel® Advanced...Let Kernel isolation on. saying home users should not care about safety is just a stupid way of thinking. installing bad drivers is a way to spread malware with ease. This should be the "marked solution" to this thread.And I would also add a link to the Intel® Driver & Support Assistant (Intel® DSA) to easily install the latest official driver. Thank you BjornVermeulen for pointing out the support info from Intel.
I came here looking for a way to resolve an error "A driver cannot load on this device" for the driver "iqvw64e.sys". This error popped up after I enabled "memory integrity" in Windows 11.
Note that "some malware camouflages itself as iqvw64e.sys" source.
This driver is associated with Intel network connections software, and gets removed by uninstalling the software per this reddit comment in r/sysadmin. This error is probably because Intel won't support Intel PROSet & Intel Advanced Network Services on Windows 11. The driver is likely a holdover from my Windows 10 OS before I upgraded it to Windows 11. The driver is probably unneeded since other Intel drivers are available .
The accepted answer in this Microsoft Q&A forum seems silly (just disable memory integrity), so I kept reading and found the highlighted response which quoted a more sensible answer (get rid of bad drivers). Later in the replies, someone asks what's the most efficient way to remove the driver and someone else states
I found the solution to this problem. After digging for the source of this file, I came across this article. File.net description of iqvw64e.sys. According to the article, this driver can be removed by uninstalling "Intel(R) Network Connections". Sure enough, I went to Control Panel, uninstalled the recommended app, rebooted, and voila! No more error. As for the value of that application, I have no idea. I am however happy to be rid of this error.
This didn't work for my case since "Intel(R) Network Connections" wasn't installed. Couldn't find iqvw64e.sys in the expected location of C:\Windows\System32\drivers. May have been removed after memory integrity enabled?
Presently looks like non-issue and can disregard warning in the future
-
-
stackoverflow.com stackoverflow.com
-
I came to this page looking for a way to add Xournal++ to the official winget repository. The accepted answer seems like it might do this: https://stackoverflow.com/a/64367435/6457597
Need to open issue on GH repo about creating manifest file for Xournal++
-
-
xournalpp.github.io xournalpp.github.io
-
Work in Progress¶ The HandwritingRecognition plugin uses cloud-based handwriting recogntion to recognize handwritten text from a selection or page layer in a user-specified language.
This HandwritingRecognition plugin is a work-in-progress, but extremely exciting. They ran into some issues using Google's API; broke strokes into batches of 150 which would make reassembling more than a couple sentences a nontrivial problem.
-
-
xournalpp.github.io xournalpp.github.io
-
Currently Xournal++ does not have shortcuts/keybindings configurable in the preferences. However you can write your custom plugin to achieve exactly that.
Must learn (and install) Lua (version >=5.3) to make custom shortcuts for Xournal++ via personally made plugins.
-
-
watermark.silverchair.com watermark.silverchair.com
-
Introduction to Daniel Rosiak's spectacular "Sheaf Theory through Examples" available open access from MIT Direct Press: https://doi.org/10.7551/mitpress/12581.003.0003
-
-
docdrop.org docdrop.org
-
okay so remind you what is a sheath so a sheep is something that allows me to 00:05:37 translate between physical sources or physical realms of data and physical regions so these are various 00:05:49 open sets or translation between them by taking a look at restrictions overlaps 00:06:02 and then inferring
Fixed typos in transcript:
Just generally speaking, what can I do with this sheaf-theoretic data structure that I've got? Okay, [I'll] remind you what is a sheaf. A sheaf is something that allows me to translate between physical sources or physical realms of data [in the left diagram] and the data that are associated with those physical regions [in the right diagram]
So these [on the left] are various open sets [an example being] simplices in a [simplicial complex which is an example of a] topological space.
And these [on the right] are the data spaces and I'm able to make some translation between [the left and the right diagrams] by taking a look at restrictions of overlaps [a on the left] and inferring back to the union.
So that's what a sheaf is [regarding data structures]. It's something that allows me to make an inference, an inferential machine.
-
-
webapps.stackexchange.com webapps.stackexchange.com
-
You can do searches that exclude certain labels. That is, searches like this will do what you expect: (label:MyLabel1 AND NOT label:inbox AND NOT label:MyBadLabel1) That search will show you only messages that: Do have MyLabel1 And do not have label inbox And do not have label MyBadLabel1 The tricks are: to get yourself out of conversation mode! (As @Ruben says above.) to use UPPER CASE for the logic operators (AND NOT will work, and not won't) If you leave "conversation mode" on, you will get confusing results. For example, doing that search above (with conversation mode on), will likely return messages that do NOT match your search. It may be a bit weird. Here's the deal: Conversations are collections of messages that all have the same Subject. When "conversation mode" is on, searches return entire conversations as results. So what should gmail search do if a conversation contains both a message that matches, and a message that does not match your search? You are probably expecting it to return conversations only if all messages in that conversation match. But that is not correct. Instead, Gmail search will return conversations even if only a single message in that conversation matches. So that means that if you do the same search above with "conversation mode" on, the results are likely to include messages that do not match your search!
I came here looking for a way to exclude certain emails from searches in Gmail. I was trying to make sure some emails that were archived don't show up, and this approach works (but the Boolean operators must be capitalized):
(label:label_I_want AND NOT label:label_I_dont)If the unwanted label msgs are a part of a conversation thread containing the wanted msgs, then I'll need to turn this off first:
Go to the main Settings page, look for the “Conversation View” section, select the option to turn it off, and save changes. If you change your mind, you can always go back. source
-
-
-
Paul M mentioned Tilium having a shared aspect that Obsidian doesn't. Seems to be like a GitHubish approach to Obsidian.
-
-
docdrop.org docdrop.org
-
i think so like in social terms the conservatives would say well i like that it benefits from the wisdom of math already invented you're not 00:36:39 throwing anything away you're not you're not throwing it all away and starting over you're taking what we already have and you're you're using it that's great and a libertarian might say i really like that you're free to create as you see fit you can make anything you 00:36:52 want and you're working within this background framework that's minimally invasive it doesn't make a lot of rules for you but it is highly functional i like that it kind of keeps everyone in line while 00:37:03 like satisfying some formal contracts or something while still being uh i'm still free to create and a progressive might say i like about category that theory that everyone can contribute to 00:37:15 making their own world making it more rich adding new ideas uh making it more meaningful understanding connections between things a modern viewpoint would say i like that 00:37:26 it's completely rigorous that it's been used in proving well-known conjectures that people thought were important to prove but also that it's interesting it's useful in science and technology and a postmodern person might say i like 00:37:40 that um that no perspective is right that that there's just all sorts of different categories but that navigating between these perspectives lets you look at problems from all sides or a hippie might say i like that it's 00:37:53 all about relationship and connection or irrelevant i don't know what that means maybe a practical person might say that i like that it's that we can actually use it to organize and learn from big data in 00:38:06 today's world or to manage complexity of software projects that are that are very large and changing all the time i like that you can think about ai and other complex systems with this stuff i think it's relevant and 00:38:19 practical for right now so that's that's my uh tutorial or that's the the part i'm going to record and now i'm going to open it up for questions
David Spivak discusses how category theory may appeal to different political ideologies for a variety of reasons.
-
-
www.autohotkey.com www.autohotkey.com
-
Testing if Google Chrome can make annotations on this Auto Hotkey documentation page.
It (and Brave) can't make highlights or annotations for some reason. The prompt doesn't appear when text is highlighted, why is this? Is there a way to force the prompt to appear?
-
Page: Escape Sequences
I was looking for documentation on escaped characters.
This was because Auto Hotkey threw an error when I used
<%* %>as an option for the text insert script. It said the illegal character was*but really what was happening was that the unquoted text%* %was treated like a variable since%is used to enclose variables in Auto Hotkey. The solution was to escape the percent sign with one left back tick.
-
-
app.slack.com app.slack.com
-
Kevin Flowers Nov 7th at 12:50 PM# Question about repliesForgive me a bit if this is the wrong place to ask, but is the feature of having Hypothes.is list replies somewhere on the roadmap? I checked the github issues with "label:enhancement" but nothing matches what I'm wondering aboutI could be missing something obvious, but when I search my username in https://hypothes.is/users, none of the replies I've made on other people's public annotations show up# Use casesSometimes people have insightful observations and references they provide, so I tend to reply to those annotations with tags that I use to sort through (eg, tags like "to read", "how to", "tutorial", and so forth)I also tend to make comments on what the OP's annotation made me think of at the time of reading it which is exemplified in the attached screenshotimage.png 9 repliesMichael DiRoberts 7 days ago@Kevin Flowers You’re right, the Activity Page (https://hypothes.is) doesn’t show replies. The Notebook, which will be built out more with time, does.https://web.hypothes.is/help/how-to-preview-the-hypothesis-notebook/HypothesisHow to Preview the Hypothesis Notebook : HypothesisHypothesis has released an early preview of Notebook, which enables you to view, search for, and filter annotations. While this tool is available in both the LMS and web apps, it is designed to bring much-needed functionality to our LMS users. This initial release contains some basic features we have planned to include in the […]Est. reading time2 minutes1Michael DiRoberts 7 days agoI hope Notebook solves the issue for you! For now it’s going to work on private groups and not the Public group (due to it having a limit of 5,000 annotations), though that may change in the future.Michael DiRoberts 7 days agoIf you’re comfortable using APIs then you might check out our API as well: https://h.readthedocs.io/en/latest/api-reference/v1/.You can find replies by looking at rows that contain references.Kevin Flowers 7 days agoOh, the Notebook seems like a neat tool, I'll have to share that with some friendsKevin Flowers 7 days agoThe issue for my own PKM (personal knowledge management) stack is that I couple Hypothes.is with an Obsidian [1] plugin that imports my annotations into my local file system. Atm, I think the plugin only references the Activity Page to import annotations, so it looks like I'll have to play around with the API you mentioned if I want to grab my replies (along with their parent replies & annotations)[1] Obsidian is a notetaking software similar to Roam & Logseq; it just adds a pretty GUI on top of .md files which are stored locallyMichael DiRoberts 7 days agoNote that the Obsidian plugin wasn’t made by us, so I’m not familiar with how it works. It’s a little weird to me that it would work over the activity page and not use our API, however.Brian Cordan Young 7 days ago@Kevin Flowers Do you have, or have you considered, blogging about your use of Hypothesis as a part of a PKM?I’m still not a regular user of Hypothesis because it doesn’t fit in to my current info consumption well enough. That said I love learning how others do fit it in.(Obsidian is really great too) (edited) Kevin Flowers 7 days ago@Michael DiRoberts ah, you're right, thanks for mentioning that. Looks like it requires one to generate an API token in order to pull highlights, so it must be using the Hypothes.is API in some way. Sadly, I'm not familiar enough with general software development design (or JavaScript/TypeScript), and the source code for obsidian-hypothesis-plugin doesn't have enough high level comments for me to parse what any given file does. It'll probably be cumbersome and somewhat painful, but I'll probably learn more by just building something from scratch@Brian Cordan Young Huh, I hadn't considered that until you mentioned it. Recently developed some interest in building something with JavaScript (probably with the Next.js framework), so a blog might be just the project I've been looking forGitHubobsidian-hypothesis-plugin/src at master · weichenw/obsidian-hypothesis-pluginAn Obsidian.md plugin that syncs highlights from Hypothesis. - obsidian-hypothesis-plugin/src at master · weichenw/obsidian-hypothesis-plugin (150 kB)https://github.com/weichenw/obsidian-hypothesis-plugin/tree/master/srcMichael DiRoberts 7 days agoJust in case, or for others in the future, you can generate a Hypothesis API token here: https://hypothes.is/account/developer1
This is a post I made on the Slack public channel asking about whether or not Hypothes.is indexes replies. A tech support membered confirmed this is true.
However, Obsidian's Hypothes.is plugin does pull replies. It should be noted that default settings don't capture updates to the annotations or tags.
-
-
web.hypothes.is web.hypothes.is
-
Page for how to contribute to the Hypothes.is Project.<br /> - Code on GitHub - main repository: h - new feature ideas and current bugs: product-backlog - Chat in - Slack: anyone who wants to talk to contributors & community members, hang out, discuss project, get questions answered - Public forum: Less technical place for users to ask questions & discuss needs - Documentation - Using the Hypothesis API: enables you to create applications and services which read or write data from the Hypothesis service - Developing Hypothesis: set up development environment and contribute to Hypothes.is - Roadmap - High level view of features the dev team is evaluating, planning, & building
-
One big feature that the Hypothes.is Notebook affords is indexing on replies (which currently aren't displayed on the Activity Page). I confirmed this on 2022-11-07 with one of Hypothes.is's support admins in their Slack channel.
Sadly, this won't help my personal use case since I'm using the obsidian-hypothesis-plugin which seems to only pull highlights, annotations, and page notes from the Activity Page
Consequently, I'll probably have to build something myself which will be somewhat painful but a good learning experience
-
Is there a way to search for your replies to someone's public annotations?
Currently, they don't show up when I search my user name and the tag I used in the reply. Is there an elegant way to search for these annotations and my reply to them?
-
-
-
dsmdavid commented Mar 8, 2021 @tchakabam if you right click on the status bar, do you get many options? Might be worth not showing some of the other options (in my case the line/column was not shown because there were too many options already there) and, after unselecting one:
Post about status bar in VS Code (visible at bottom of window by default).
I looked for this since I couldn't figure out the column numbers of where my cursor was in the editor.
You can toggle this setting by opening command palette and searching "View: Toggle Status Bar Visibility"
Displays Ln & Col numbers.
-
-
en.wikipedia.org en.wikipedia.org
-
Contents 1 Overview 2 Reasons for failure 2.1 Overconfidence and complacency 2.1.1 Natural tendency 2.1.2 The illusion of control 2.1.3 Anchoring 2.1.4 Competitor neglect 2.1.5 Organisational pressure 2.1.6 Machiavelli factor 2.2 Dogma, ritual and specialisation 2.2.1 Frames become blinders 2.2.2 Processes become routines 2.2.3 Resources become millstones 2.2.4 Relationships become shackles 2.2.5 Values becomes dogmas 3 The paradox of information systems 3.1 The irrationality of rationality 3.2 How computers can be destructive 3.3 Recommendations for practice 4 Case studies 4.1 Fresh & Easy 4.2 Firestone Tire and Rubber Company 4.3 Laura Ashley 4.4 Xerox 5 See also 6 References
Wiki table of contents of the Icarus paradox
-
Computers can only deal with well-structured problems
ie, "well-defined problems" in John Vervaeke's language. Cultivation of wisdom, per Vervaeke, is developing the capacity to navigate a ill-defined problem space, and realize (ie, recognize, and make real) what is relevant to resolving the situation.
Examples of ill-defined problems: - how to take good notes? - how to tell a funny joke? - how to go on a successful 1st date? - how to be a good friend?
May relate to Shapiro's "role theory". Needs further research
-
The paradox of information systems[edit] Drummond suggests in her paper in 2008 that computer-based information systems can undermine or even destroy the organisation that they were meant to support, and it is precisely what makes them useful that makes them destructive – a phenomenon encapsulated by the Icarus Paradox.[9] For examples, a defence communication system is designed to improve efficiency by eliminating the need for meetings between military commanders who can now simply use the system to brief one another or answer to a higher authority. However, this new system becomes destructive precisely because the commanders no longer need to meet face-to-face, which consequently weakened mutual trust, thus undermining the organisation.[10] Ultimately, computer-based systems are reliable and efficient only to a point. For more complex tasks, it is recommended for organisations to focus on developing their workforce. A reason for the paradox is that rationality assumes that more is better, but intensification may be counter-productive.[11]
From Wikipedia page on Icarus Paradox. Example of architectural design/technical debt leading to an "interest rate" that eventually collapsed the organization. How can one "pay down the principle" and not just the "compound interest"? What does that look like for this scenario? More invest in workforce retraining?
Humans are complex, adaptive systems. Machines have a long history of being complicated, efficient (but not robust) systems. Is there a way to bridge this gap? What does an antifragile system of machines look like? Supervised learning? How do we ensure we don't fall prey to the oracle problem?
Baskerville, R.L.; Land, F. (2004). "Socially Self-destructing Systems". The Social Study of Information and Communication Technology: Innovation, actors, contexts. Oxford: Oxford University Press. pp. 263–285
Tags
- communication system
- complex
- Greek mythology
- well-defined problems
- compound interest
- design debt
- antifragility
- anchoring
- illusion of control
- ill-defined problems
- cognitive
- John Vervaeke
- interest
- social cohesion
- wisdom
- fragility
- to do
- Wikipedia
- role theory
- biases
- information systems
- defense
- Icarus paradox
- cultivation
- technical debt
- value becomes dogmas
- Danny Miller
- complicated
- relevance realization
- principle
- cognitive biases
- relationships become shackles
- self-defeating
- resources become millstones
- Ben Shapiro
- systems
- to read
- frames become blinders
- processes become routines
Annotators
URL
-
-
blog.chain.link blog.chain.link
-
What Is a Blockchain Oracle? A blockchain oracle is a secure piece of middleware that facilitates communication between blockchains and any off-chain system, including data providers, web APIs, enterprise backends, cloud providers, IoT devices, e-signatures, payment systems, other blockchains, and more. Oracles take on several key functions: Listen – monitor the blockchain network to check for any incoming user or smart contract requests for off-chain data. Extract – fetch data from one or multiple external systems such as off-chain APIs hosted on third-party web servers. Format – format data retrieved from external APIs into a blockchain readable format (input) and/or making blockchain data compatible with an external API (output). Validate – generate a cryptographic proof attesting to the performance of an oracle service using any combination of data signing, blockchain transaction signing, TLS signatures, Trusted Execution Environment (TEE) attestations, or zero-knowledge proofs. Compute – perform some type of secure off-chain computation for the smart contract, such as calculating a median from multiple oracle submissions or generating a verifiable random number for a gaming application. Broadcast – sign and broadcast a transaction on the blockchain in order to send data and any corresponding proof on-chain for consumption by the smart contract. Output (optional) – send data to an external system upon the execution of a smart contract, such as relaying payment instructions to a traditional payment network or triggering actions from a cyber-physical system.
Seems related to the paradox of information systems. Add to Anki deck
-
-
www.miclog.com www.miclog.com
-
Info Select was on this list of DEVONthink Windows alternatives. Looks like "personal information management" preceded the boom of "personal knowledge management"
-
-
discourse.devontechnologies.com discourse.devontechnologies.com
-
Holy mackerel, when I saw the subject line of this topic I thought about Zoot – which I have not thought about in many months, and not for many years before that. Zoot was my introduction to this sort of “everything bucket” app. I also tried Info Select – which is also on Windows and may be an answer to @Claude’s question, assuming it’s still updated – and then to DevonThink and Evernote. My introduction to Zoot was an article by journalist James Fallows, of all people. He is the former editor-in-chief of The Atlantic, and reports mainly on public policy and politics. I wonder if he is still using Zoot? Three more probable options: Microsoft OneNote will be the most accessible to most Windows users. It doesn’t get you the search and “see also” of DevonThink. Obsidian and Roam Research take a different approach to the content-organization problems than DevonThink/OneNote/Evernote do. They rely on links and backlinks, like a personal Wikipedia. But they achieve the same goal of organizing information. They have search. AFAIK there’s nothing comparable to “see also,” but users report the same kind of serendipitous connections just by following the links they themselves made in the past. Another liability of Roam and Obsidian compared with DT: DT supports pretty much any kind of document that your computer can read, whereas Obsidian only supports Markdown, PDF, and images. I’m not as familiar with Roam, but I believe it has the same limitations. P.S. Partial answer to my own question: Fallows comes up in this forum as a person who advocated DT in a 2005 NYTimes article about “everything bucket” apps.
From a discussion on DEVONthink alternatives for Windows users.
-
I work primarily on Windows, but I support my kids who primarily use Mac for their college education. I have used DT on Mac, IPOS, IOS for about a year. On Windows, I have been using Kinook’s UltraRecall (UR) for the past 15 years. It is both a knowledge outliner and document manager. Built on top of a sql lite database. You can use just life DT and way way more. Of course, there is no mobile companion for UR. The MS Windows echo system in this regard is at least 12 years behind.
Reference for UltraRecall (UR) being the most DEVONthink like Windows alternative. No mobile companion for UR. Look into this being paired with Obsidian
-
-
en.wikipedia.org en.wikipedia.org
-
it became clear that Fermat's Last Theorem could be proven as a corollary of a limited form of the modularity theorem (unproven at the time and then known as the "Taniyama–Shimura–Weil conjecture"). The modularity theorem involved elliptic curves, which was also Wiles's own specialist area.[15][16]
Elliptical curves are also use in Ed25519 which are purportedly more robust to side channel attacks. Could there been some useful insight from Wiles and the modularity theorem?
-
-
security.stackexchange.com security.stackexchange.com
-
From the Introduction to Ed25519, there are some speed benefits, and some security benefits. One of the more interesting security benefits is that it is immune to several side channel attacks: No secret array indices. The software never reads or writes data from secret addresses in RAM; the pattern of addresses is completely predictable. The software is therefore immune to cache-timing attacks, hyperthreading attacks, and other side-channel attacks that rely on leakage of addresses through the CPU cache. No secret branch conditions. The software never performs conditional branches based on secret data; the pattern of jumps is completely predictable. The software is therefore immune to side-channel attacks that rely on leakage of information through the branch-prediction unit. For comparison, there have been several real-world cache-timing attacks demonstrated on various algorithms. http://en.wikipedia.org/wiki/Timing_attack
Further arguments that Ed25519 is less vulnerable to - cache-timing attacks - hyperthreading attacks - other side-channel attacks that rely on leakage of addresses through CPU cache Also boasts - no secret branch conditions (no conditional branches based on secret data since pattern of jumps is predictable)
Predicable because underlying process that generated it isn't a black box?
Could ML (esp. NN, and CNN) be a parallel? Powerful in applications but huge risk given uncertainty of underlying mechanism?
Need to read papers on this
-
More "sales pitch" comes from this IETF draft: While the NIST curves are advertised as being chosen verifiably at random, there is no explanation for the seeds used to generate them. In contrast, the process used to pick these curves is fully documented and rigid enough so that independent verification has been done. This is widely seen as a security advantage, since it prevents the generating party from maliciously manipulating the parameters. – ATo Aug 21, 2016 at 7:25
An argument why Ed25519 signature alg & Curve 25519 key exchange alg is more secure; less vulnerable to side attacks since the process that generates is have been purportedly verified and extensively documented.
-
-
syntaxbug.com syntaxbug.com
-
[Solved] Git: LF will be replaced by CRLF the next time Git touches it’ problem solving and thinking
Trouble shooting git add . issue.
Setting method one for Windows system working with others:
git config --global core.autocrlf true
Tags
Annotators
URL
-
-
wexler.free.fr wexler.free.fr
-
Amos Tversky's famous "The Hot Hand in Basketball: On the Misperception of Random Sequences".
-
-
www.youtube.com www.youtube.com
-
Louis Burki 6 months ago (edited) I have make some changes to make it work, because I had a similar error. First, I have add a ":" before the "=" in the Text variable at the beginning of the script. Now it looks like that: "Text:=". Then I have put double quotes around (**your snippets**) so now it looks like this "(***your snippets***)". Then, I also changed the sort line to make it look that: Text:= sort(Text). And now it works as intended. Also, be careful not to remove the pipe symbol in your snippets.
Someone giving a troubleshooting solution to using Joe Glines' Auto Hotkey script that inserts text from a list of the user's choosing. The problem another user had was including it in their main script file, but this was resolved with Louis Burki's answer
-
-
github.com github.com
-
Another Authotkey user here! 😃 On my machine, Mehul's solution with the 1ms delay takes noticeably longer to actually insert some text. I found the following solution which inserts it in a less "chunky" manner. Adjust the 1ms till it works for your setup :) ; This worked ::dx::{Sleep 1}DevExpress ; For longer hotstrings, I needed more ::azerty::{Sleep 60}DevExpress With 250ms pretty much any length of hotstring expanded correctly. I answered this Stackoverflow question with details from this issue. The same bug might have been present in an earlier version of VSCode: microsoft/vscode#1934 They make mention of this commit fixing it. Unfortunately it's a rather large commit :( microsoft/vscode@a1bd50f Commit msg: "Fixes #1168: Read synchronously from textarea" The problem has to do with the backspace remapping. Take the following autohotkey hotstring: ::tada::🎉 This will make typing "tada" followed by one of the "EndingChars" (space, tab, comma, dot, ...) expand to the 🎉 emoji. What you see visually happening on the screen is that Autohotkey does this by first sending a backspace to the editor 4 times (length of hotstring "tada") and then inserts the replacement text (🎉) What happens when this (pretty fantastic) extension is active is that the first x characters get deleted then the replacement text gets inserted and then the remaining (hotstring length - x) characters get deleted. But because the cursor is now at the end of the replacement text... which gets chewed on 😃 I'll have to learn how to debug the IDE itself or always add a {Sleep 250} to my hotstrings...
Solution to AutoHotkey text replacement bug. Just add sleep parameter. Adding
{Sleep 250}should generally work -
Page that has some guidance on troubleshooting AutoHotkey issues in VS Code.
-
-
pipdecks.com pipdecks.com
-
Something @chrisaldrich mentioned on Reddit as examples of someone selling niche Zettelkasten decks. Seem more like protocol-kasten decks to aid problem-solving in specific contexts.
-
-
www.reddit.com www.reddit.com
-
Zettelkasten as a product?! .t3_xsoaya._2FCtq-QzlfuN-SwVMUZMM3 { --postTitle-VisitedLinkColor: #9b9b9b; --postTitleLink-VisitedLinkColor: #9b9b9b; --postBodyLink-VisitedLinkColor: #989898; }
@chrisaldrich's post on "pip decks". They seem less like Zettelkasten decks and more like protocol-kastens (think of a better name for this)
Seem poor for knowledge generation (Zettelkasten) and recollection (Anki), but may be useful for specific contexts of problem-solving (even in ill-defined problem spaces).
-
-
bafybeih7c3e2cbi7jlvodqtxfvrnpwjxz7kcwmbbo7ka2tycfwxg5cciza.ipfs.dweb.link bafybeih7c3e2cbi7jlvodqtxfvrnpwjxz7kcwmbbo7ka2tycfwxg5cciza.ipfs.dweb.link
-
Paper by Gyuri Lajos and Andras Benedek. Gyuri's context was recommended by @wfinck. Looks like it pertains to knowledge graphs. Gyuri's own annotation calls it a "meta-knowledge graph"
-
-
www.webnots.com www.webnots.com
-
A brief tutorial on PowerToys Run that has some handy tricks listed
-
-
winstall.app winstall.app
-
Winstall is a way to bulk install WIndows apps quickly with Windows Package Manager (winget)
Tags
Annotators
URL
-
-
github.com github.com
-
An open issue on the Obsidian Hypothes.is plugin about edits in annotations not being added to Obsidian. A proposed solution is given; change the settings script with the code provided.
-
-
forums.ankiweb.net forums.ankiweb.net
-
I realize that having the same FE/BE on all platforms is the fabled cross-platform panacea. But I’ve yet to see this work well in practice for any app of significant complexity. Quite a few major development teams that were early adopters of ideas like this have since abandoned that approach e.g. AirBnB with React Native, or DropBox with their custom C++ core. As it turns out, while you do write less platform-specific code, you still have to deal with platform-specific bugs and performance issues (not too dissimilar from Qt, just the with additional headaches of mobile platforms). So creating one “universal” code base ends up being almost as much work as working with each platform’s native technologies.
(Test) Glutimate's argument against moving away from Qt for Anki development.
-
-
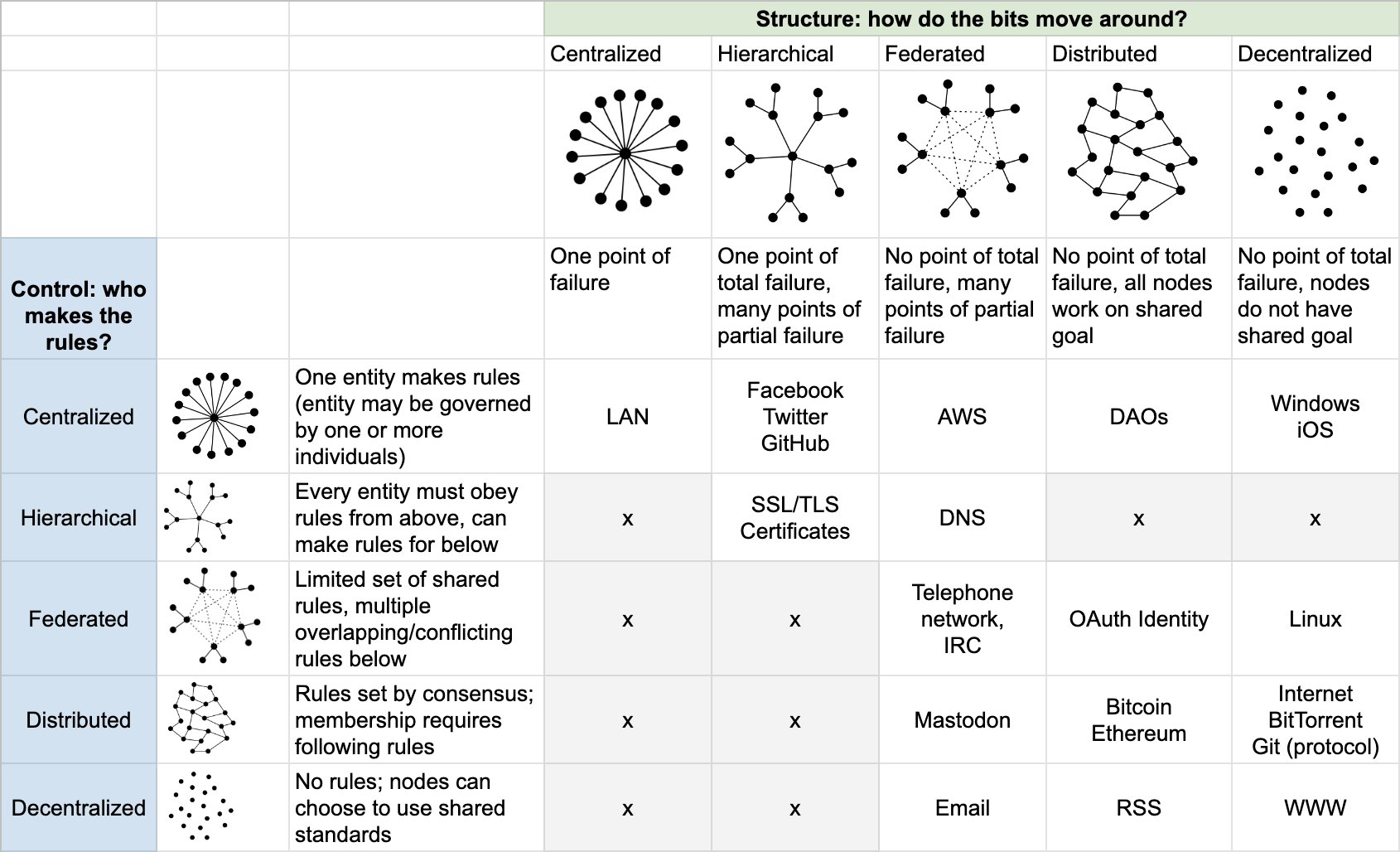
twitter.com twitter.comTwitter1
-
v5: added git and github (thanks @ceejbot), and RSS (thanks @zem42). Taking suggestions for hierarchical/distributed and hierarchical/decentralized.
t Laurie Voss's crowdsourced set of examples of things that have structure & control in the form of the following: - centralized - hierarchical - federated - distributed - decentralized
Picture below:
Link to tweet: https://twitter.com/seldo/status/1486563446099300359?s=20&t=C6z9xUF_YBkOFmfcjfjpUA
-
-
beepb00p.xyz beepb00p.xyz
-
What would a secure Federated PMK / archive network backed by a minimal blockchain look like?
Possibly like Holochain (which is distinct from the blockchain architecture). Blockchain only seems helpful if you need all of the following: - a database - immutability - distributed data - decentralized & totally trustless - append only - cryptographically secure assurance
Confer Brandon Enright's provocative talk "Blockchain is Bullshit" for an elaboration of these features. The first 10 or so minutes is mostly uninsightful trolling, so the link takes one to his argument about the key features of blockchain.
AFAICT, Holochain eases the feature of "decentralized", although Laurie Voss suggests that it's better to think of Bitcoin & Ethereum as "distributed" (in both the structure & control).
In Voss' taxonomy, I suspect that Holochain's structure would be "distributed" (ie, "No total point of failure, all nodes work on shared goal") and control would be "federated" (ie, "Limited set of shared rules, multiple overlapping/conflicting rules below")
-
I also think being able to self-host and export parts of your data to share with others would be great.
This might be achievable through Holochain application framework. One promising project built on Holochain is Neighbourhoods. Their "Social-Sensemaker Architecture" across "neighbourhoods" is intriguing
-
Page recommended by @wfinck. Seems @karlicoss is the author. This project seems similar to what I've been trying to do with Hypothes.is, Obsidian, Anki, Zotero, and PowerToys Run but goes beyond the scope of my endeavors to just quickly access whatever resource comes to mind (without creating duplicates). The things that Promnesia adds beyond my PKM stack is the following: - prioritize new info - keeping track of which device things were read and how long
-
-
github.com github.com
-
Short video demo on how to setup Templater scripts in Obsidian
-
-
www.nateliason.com www.nateliason.com
-
A good summary of James Carse's book "Finite and Infinite Games"
-
-
silentvoid13.github.io silentvoid13.github.io
-
Page on the the Templater syntax
<%+ ... %>. It allows use of "dynamic commands" which are only executed in preview mode in Obsidian
-
-
github.com github.com
-
Template: <%* const id = tp.file.creation_date("YYYYMMDDHHmmss"); await tp.file.rename(`${id} ${tp.file.title}`); %>
Templater code snippet that renames current file to add date & time creation to title of note.
-
-
-
A set of examples of Templater use cases. Templater uses a JavaScript-esque syntax
-
-
-
The GitHub repository for source code that generates the knowledge garden by @wfinck (which he calls a "digital garden"
-
-
github.com github.com
-
A template used by @wfinck to make this note in his public knowledge garden (ie, Zettelkasten notes with a displayed graph view of them)
-
-
www.lesswrong.com www.lesswrong.com
-
Example implementation of Anki into learning maths
-
-
www.meaningcrisis.co www.meaningcrisis.co
-
Socrates is turned into a systematic set of psycho-technologies that you internalise into your metacognition. So, what became crucial for Plato, as we saw, was argumentation. But for Antisthenes the actual confrontation with Socrates was more important. Both Plato and Antisthenes are interested in the transformation that Socrates is affording.Plato sees this happening through argumentation. Antesthenes sees it as happening through confrontation because... And you can see how they're both right, because in Socratic elenchus, Socrates comes up and he argues with you. But of course he's also confronting you. We talked about how he was sort of slamming the Axial revolution into your face! So, Antesthenes has a follower, Diogenes, and Diogenes epitomizes this: This confrontation. And by looking at the kinds of confrontation we can start to see what the followers of Antesthenes are doing. So Diogenes basically does something analogous to provocative performance art. He gets in your face in a way that tries to provoke you to realizations. Those kinds of insights that will challenge you. He tries to basically create aporia in you, that shocked experience that you had when confronting Socrates that challenges you to radically transform your life. But instead of using argumentation and discussion, as Socrates did and Plato picked up on, they were really trying to hone in on how to try to be as provocative as possible.
John Vervaeke on Socrates becoming set of psychotechnologies to internalize and augment metacognition. Agues agumentation become central for Plato, whereas confrontation itself become central for Antisthenes. They're disagree about how the cause of the transformation through the Socratic approach
Unclear is stoics take up Plato's mantle of argumentation orientation, but they at least seem distinct from the Cynics (Antisthenes & teach Diogenes
Aporia is moment of shock from experience that you're radically transformed. Could be from Diogenes' provocative performance art or through discourse a la Plato & Socrates
Nietzche may have favored Cynics approach over stoic/Socratic. Possible parallel in left-hand path and right-hand path. Quick & risky vs. slow & steady
-
-
www.reddit.com www.reddit.com
-
Run in WSL to return current total "word count": find /mnt/c/path/to/obsidian -type f -name "*.md" -exec cat '{}' \+ | wcThis will also count words in syntax - like the word "query" in an embedded query. In fact it probably counts anything separated by whitespace as separate words. But you could do some preprocessing between the cat and the wc if you like.
Linux command for WSL to count all lines, words count, & character count. OP states at end -wc restricts to word count only
-
-
www.researchgate.net www.researchgate.net
-
Google Scholar is needed to access annotations in context "Listen to the noise: noise is beneficial for cognitive performance in ADHD"
-
The most intriguing result in the present study is thepositive effect of white noise on performance for theADHD children. This noise effect was present in boththe non-medicated and medicated children. Thissupports the MBA (Moderate Brain Arousal) model(Sikstro ̈m & So ̈derlund, 2007), suggesting that theendogenous (neural) noise level in children withADHD is sub-optimal. MBA accounts for the noise-enhancing phenomenon by stochastic resonance(SR). The model suggests that noise in the environ-ment introduces internal noise into the neural sys-tem through the perceptual system. Of particularimportance, the MBA model suggests that the peakof the SR curve depends on the dopamine level, sothat participants with low dopamine levels (ADHD)require more noise for optimal cognitive performancecompared to controls.
Author's self-described "most intriguing result"
-
It has long been known that cognitive processing iseasily disturbed by noise and other distractors(Broadbent, 1958).
Known for who? General populations? Specific subpopulations?
-
The MBAmodel predicts that noise enhances memory perfor-mance for ADHD and attenuates performance forcontrols. We will also argue for a link between theeffects of noise, dopamine regulation, and cognitiveperformance.
Prediction of Moderate Brain Arousal model and author's additional argument.
-
Results: Noise exerted a positive effect on cognitive performance forthe ADHD group and deteriorated performance for the control group, indicating that ADHD subjectsneed more noise than controls for optimal cognitive performance
Explains why studies on music at general population have conflicting results (ie, general decrease in capacity to focus with noisy environment). Wonder if this relates to atonal or discordant and dissonant music (free jazz, avant-guarde, etc) or polyrhythmic and odd metered time signatures
-
The Moderate Brain Arousal model(MBA; Sikstro ̈m & So ̈derlund, 2007) suggests that dopamine levels modulate how much noise isrequired for optimal cognitive performance.
Model for explaining why the mechanism of stochastic resonance may be different for those with ADHD
-
-
en.wikipedia.org en.wikipedia.org
-
subspace topology
This definition can be used to demonstrate why the following function is continuous:
\(f: [0,2\pi) \to S^1\) where \(f(\phi)= (\cos\phi, \sin\phi)\) and \(S^1\) is the unit circle in the cartesian coordinate plane \(\mathbb{R}^2\).
Intuition
The preimage of open (in codomain) is open (in domain). Roughly, anything "close" in the codomain must have come from something "close" in the domain. Otherwise, stuff got split apart (think gaps, holes, jumps) on the way from our domain to our codomain.
Formalism
For some \(f: X \to Y\), for any open set \(V \in \tau_Y\), there exists some open set \(U \in \tau_X\) so that it's image under \(f\) is \(V\). In math, \(\forall V \in \tau_Y, \exists U \in \tau_X \text{ s.t. } f(U) = V\)
Demonstration
So for \(f: [0,2\pi) \to S^1\), we can see that \([0,2\pi)\) is open under the subspace topology. Why? Let's start with a different example.
Claim 1: \(U_S=[0,1) \cup (2,2\pi)\) is open in \(S = [0,2\pi)\)
We need to show that \(U_S = S \cap U_X\) for some \(U_X \in \mathbb{R}\). So we can take whatever open set that overlaps with our subspace to generate \(U_S\text{.}\)
proof 1
Consider \(U_X = (-1,1) \cup (2, 2\pi)\) and its intersection with \(S = [0, 2\pi)\). The overlap of \(U_X\) with \(S\) is precisely \(U_S\). That is,
$$ \begin{align} S \cap U_X &= [0, 2\pi) \cap U_X \ &= [0, 2\pi) \cap \bigl( (-1,1) \cup (2,2\pi) \bigr) \ &= \bigl( [0, 2\pi) \cap (-1,1) \bigr) \cup \bigl( [0,2\pi) \cap (2,2\pi)\bigr) \ &= [0, 1) \cup (2, 2\pi) \ &= U_S \end{align} $$
-
-
wesleyfinck.org wesleyfinck.org
-
A beautiful example of a note that imbeds core zettels that simultaneously make connections within a Zettelkasten. Each page for a note displays the network of notes and their connections. The website is based on an open-source template
The source code for the site is here
Tags
Annotators
URL
-
-
en.wikipedia.org en.wikipedia.org
-
Definition matrix
Useful 2x2 matrix of - private goods, - common-pool resources, - club goods, - public goods
-
-
www.destroyallsoftware.com www.destroyallsoftware.com
-
Video on Functional Core, Imperative Shell paradigm. Recommended in Hypothes.is testing documentation
-
-
faqs.ankiweb.net faqs.ankiweb.net
-
Steps for trouble-shooting Anki issues
-
-
-
Post about how to modify keyboard shortcut's for Brave browser extensions
-
-
supermemo.guru supermemo.guru
-
Page with many resources on - Learning - Creativity - Intelligence - Sleep - Education - Memory - Health - Productivity - Myths - SuperMemo - Older texts
-
-
h.readthedocs.io h.readthedocs.io
-
the functional core, imperative shell pattern
Link to video on "Boundaries" doesn't go into depth on the functional core, imperative shell pattern. However, this one does: https://www.destroyallsoftware.com/screencasts/catalog/functional-core-imperative-shell
-
For new code, it’s usually a good idea to design the code so that it’s easy to test with “real” objects, rather than stubs or mocks.
-
We keep our functional tests separate from our unit tests, in the tests/functional directory. Because these are slow to run, we will usually write one or two functional tests to check a new feature works in the common case, and unit tests for all the other cases.
Keep functional & unit tests separate. Functional for common cases, unit for all others.
-
To run the backend test suite only call tox directly
Probably means, "Call
toxdirectly if you only want to run the backend test suite."
-
-
-
CEO, Mike Tung was on Data science podcast. Seems to be solving problem that Google search doesn't; how seriously should you take the results that come up? What confidence do you have in their truth or falsity?
Tags
Annotators
URL
-
-
medium.com medium.com
-
6 min read on tracking tasks with Obsidian. Might be helpful
-
-
boffosocko.com boffosocko.com
-
Now I can take an article from almost anywhere on my phone (reading services like Pocket, my feed readers, or even articles within the browser themselves), click share, choose “URL Forwarder” from the top of the list, select “Hypothesize” and the piece I want to annotate magically opens up with Hypothes.is ready to go in my default browser. Huzzah!
Useful how-to for setting up Hypothes.is for mobile use on Android. Confirmed that this works on Brave mobile browser
-
http:
Using "https:" also works (at least with the Brave mobile browser on Android)
-
-
curtismchale.ca curtismchale.ca
-
Obsidian Kanban for Someday Maybe
Examples include a separate Kanban board for - camping tasks - home-based tasks - Obsidian management - such as organize old files in database
-
-
www.makeuseof.com www.makeuseof.com
-
How to Turn Obsidian Into a Personal Kanban Organizer
Checking if Hypothesis works on Android via Brave mobile browser. Here's some LaTex being tested \(A \cup B\)
-
-
stats.stackexchange.com stats.stackexchange.com
-
The random process has outcomes
Notation of a random process that has outcomes
The "universal set" aka "sample space" of all possible outcomes is sometimes denoted by \(U\), \(S\), or \(\Omega\): https://en.wikipedia.org/wiki/Sample_space
Probability theory & measure theory
From what I recall, the notation, \(\Omega\), was mainly used in higher-level grad courses on probability theory. ie, when trying to frame things in probability theory as a special case of measure theory things/ideas/processes. eg, a probability space, \((\cal{F}, \Omega, P)\) where \(\cal{F}\) is a \(\sigma\text{-field}\) aka \(\sigma\text{-algebra}\) and \(P\) is a probability density function on any element of \(\cal{F}\) and \(P(\Omega)=1.\)
Somehow, the definition of a sigma-field captures the notion of what we want out of something that's measurable, but it's unclear to me why so let's see where writing through this takes me.
Working through why a sigma-algebra yields a coherent notion of measureable
A sigma-algebra \(\cal{F}\) on a set \(\Omega\) is defined somewhat close to the definition of a topology \(\tau\) on some space \(X\). They're both collections of sub-collections of the set/space of reference (ie, \(\tau \sub 2^X\) and \(\cal{F} \sub 2^\Omega\)). Also, they're both defined to contain their underlying set/space (ie, \(X \in \tau\) and \(\Omega \in \cal{F}\)).
Additionally, they both contain the empty set but for (maybe) different reasons, definitionally. For a topology, it's simply defined to contain both the whole space and the empty set (ie, \(X \in \tau\) and \(\empty \in \tau\)). In a sigma-algebra's case, it's defined to be closed under complements, so since \(\Omega \in \cal{F}\) the complement must also be in \(\cal{F}\)... but the complement of the universal set \(\Omega\) is the empty set, so \(\empty \in \cal{F}\).
I think this might be where the similarity ends, since a topology need not be closed under complements (but probably has a special property when it is, although I'm not sure what; oh wait, the complement of open is closed in topology, so it'd be clopen! Not sure what this would really entail though 🤷♀️). Moreover, a topology is closed under arbitrary unions (which includes uncountable), but a sigma-algebra is closed under countable unions. Hmm... Maybe this restriction to countable unions is what gives a coherent notion of being measurable? I suspect it also has to do with Banach-Tarski paradox. ie, cutting a sphere into 5 pieces and rearranging in a clever way so that you get 2 sphere's that each have the volume of the original sphere; I mean, WTF, if 1 sphere's volume equals the volume of 2 sphere's, then we're definitely not able to measure stuff any more.
And now I'm starting to vaguely recall that this what sigma-fields essentially outlaw/ban from being possible. It's also related to something important in measure theory called a Lebeque measure, although I'm not really sure what that is (something about doing a Riemann integral but picking the partition on the y-axis/codomain instead of on the x-axis/domain, maybe?)
And with that, I think I've got some intuition about how fundamental sigma-algebras are to letting us handle probability and uncertainty.
Back to probability theory
So then events like \(E_1\) and \(E_2\) that are elements of the set of sub-collections, \(\cal{F}\), of the possibility space \(\Omega\). Like, maybe \(\Omega\) is the set of all possible outcomes of rolling 2 dice, but \(E_1\) could be a simple event (ie, just one outcome like rolling a 2) while \(E_2\) could be a compound(?) event (ie, more than one, like rolling an even number). Notably, \(E_1\) & \(E_2\) are NOT elements of the sample space \(\Omega\); they're elements of the powerset of our possibility space (ie, the set of all possible subsets of \(\Omega\) denoted by \(2^\Omega\)). So maybe this explains why the "closed under complements" is needed; if you roll a 2, you should also be able to NOT roll a 2. And the property that a sigma-algebra must "contain the whole space" might be what's needed to give rise to a notion of a complete measure (conjecture about complete measures: everything in the measurable space can be assigned a value where that part of the measurable space does, in fact, represent some constitutive part of the whole).
But what about these "random events"?
Ah, so that's where random variables come into play (and probably why in probability theory they prefer to use \(\Omega\) for the sample space instead of \(X\) like a base space in topology). There's a function, that is, a mapping from outcomes of this "random event" (eg, a role of 2 dice) to a space in which we can associate (ie, assign) a sense of distance (ie, our sigma-algebra). What confuses me is that we see things like "\(P(X=x)\)" which we interpret as "probability that our random variable, \(X\), ends up being some particular outcome \(x\)." But it's also said that \(X\) is a real-valued function, ie, takes some arbitrary elements (eg, events like rolling an even number) and assigns them a real number (ie, some \(x \in \mathbb{R}\)).
Aha! I think I recall the missing link: the notation "\(X=x\)" is really a shorthand for "\(X(\omega)=x\)" where \(\omega \in \cal{F}\). But something that still feels unreconciled is that our probability metric, \(P\), is just taking some real value to another real value... So which one is our sigma-algebra, the inputs of \(P\) or the inputs of \(X\)? 🤔 Hmm... Well, I guess it has the be the set of elements that \(X\) is mapping into \(\mathbb{R}\) since \(X\text{'s}\) input is a small omega \(\omega\) (which is probably an element of big omega \(\Omega\) based on the conventions of small notation being elements of big notation), so \(X\text{'s}\) domain much be the sigma-algrebra?
Let's try to generate a plausible example of this in action... Maybe something with an inequality like "\(X\ge 1\)". Okay, yeah, how about \(X\) is a random variable for the random process of how long it takes a customer to get through a grocery line. So \(X\) is mapping the elements of our sigma-algebra (ie, what customers actually end up experiencing in the real world) into a subset of the reals, namely \([0,\infty)\) because their time in line could be 0 minutes or infinite minutes (geesh, 😬 what a life that would be, huh?). Okay, so then I can ask a question like "What's the probability that \(X\) takes on a value greater than or equal to 1 minute?" which I think translates to "\(P\left(X(\omega)\ge 1\right)\)" which is really attempting to model this whole "random event" of "What's gonna happen to a particular person on average?"
So this makes me wonder... Is this fact that \(X\) can model this "random event" (at all) what people mean when they say something is a stochastic model? That there's a probability distribution it generates which affords us some way of dealing with navigating the uncertainty of the "random event"? If so, then sigma-algebras seem to serve as a kind of gateway and/or foundation into specific cognitive practices (ie, learning to think & reason probabilistically) that affords us a way out of being overwhelmed by our anxiety or fear and can help us reclaim some agency and autonomy in situations with uncertainty.
-
-
en.wikipedia.org en.wikipedia.org
-
the moments of a function are quantitative measures related to the shape of the function's graph
Vaguely recall these "uniquely determined" some (but not all) functions. Later on, the article says all moments from \(0\) to \(\infty\) do uniquely determine bounded functions. Guess you can't judge a book (or graph) by it's cover; you have to wait moment by moment for it to reveal itself
-