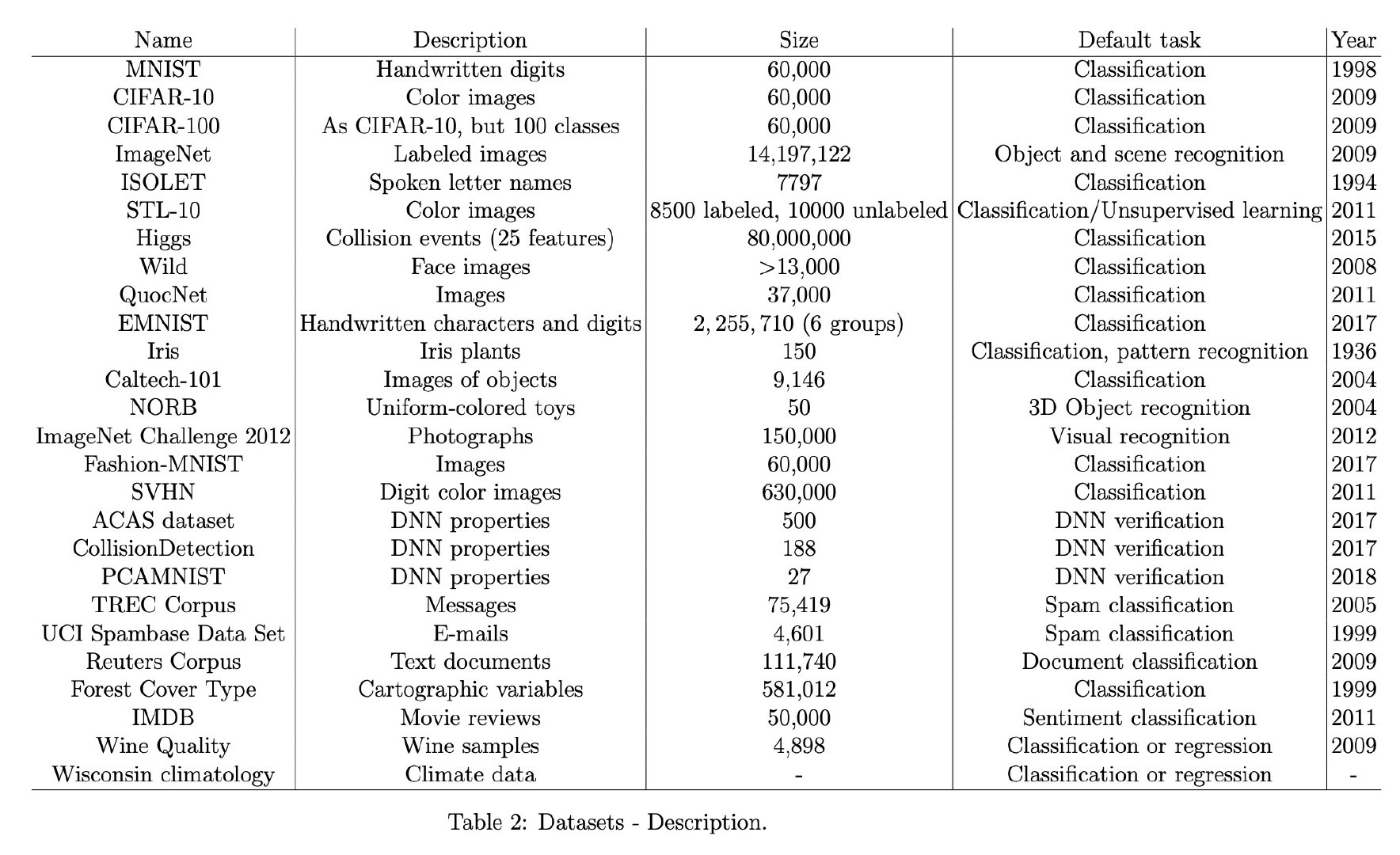
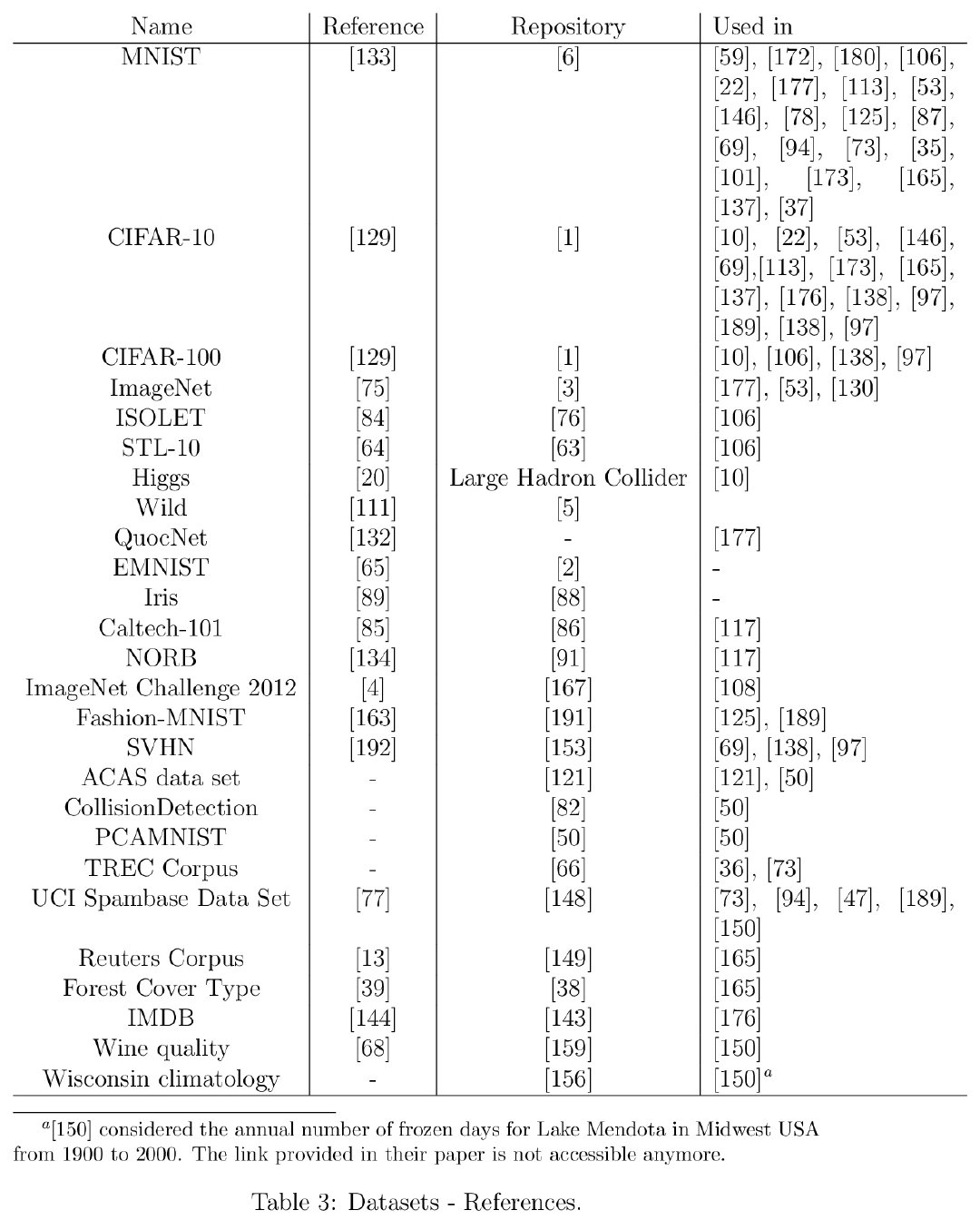
The minimum training cutoffs are: ECI (June 2024), METR Time Horizon (January 2024), Combined Math (September 2024), and WeirdML V2 (January 2025).
这些时间节点表明研究使用的数据集长度不同,从2024年初到2024年中不等。较短的训练数据集(如WeirdML V2只有约1年的推理模型前数据)可能限制了检测加速的能力,这解释了为什么该指标未能显示加速趋势。时间跨度的差异也反映了不同AI能力指标的发展历史不同。