The model is not merely sampling more images or videos; it is debugging a visual program in a closed-loop, renderable environment.
大多数人认为AI生成内容的改进主要依靠增加计算量和样本数量,但作者认为真正的进步在于AI能够像程序员一样调试视觉程序。这一观点将AI从内容生成者转变为问题解决者,暗示未来AI的发展方向是编程能力而非单纯的生成能力。
The model is not merely sampling more images or videos; it is debugging a visual program in a closed-loop, renderable environment.
大多数人认为AI生成内容的改进主要依靠增加计算量和样本数量,但作者认为真正的进步在于AI能够像程序员一样调试视觉程序。这一观点将AI从内容生成者转变为问题解决者,暗示未来AI的发展方向是编程能力而非单纯的生成能力。
The most interesting visual AI tools today have stopped trying to generate the final output. Instead, they're generating the source code behind it.
大多数人认为视觉AI的进步主要体现在生成更逼真的图像和视频上,但作者认为真正的突破在于AI从生成像素转向生成代码。这一观点挑战了当前视觉AI领域的主流发展方向,暗示未来价值不在于最终视觉效果,而在于可编辑、可迭代的代码结构。
For the computer-use work that sits at the heart of XBOW's autonomous penetration testing, the new Claude Opus 4.7 is a step change: 98.5% on our visual-acuity benchmark versus 54.5% for Opus 4.6.
在视觉敏锐度测试中从54.5%跃升至98.5%是一个惊人的进步,这展示了AI在网络安全领域的突破性进展,'our single biggest Opus pain point effectively disappeared'表明这一进步解决了实际应用中的关键瓶颈。
Gemini Robotics-ER 1.6 achieves its highly accurate instrument readings by using agentic vision, which combines visual reasoning with code execution. The model takes intermediate steps: first zooming into an image to get a better read of small details in a gauge, then using pointing and code execution to estimate proportions and intervals and get an accurate reading.
这一描述揭示了AI如何通过多步骤推理解决复杂问题,展示了模型在处理精细视觉任务时的创新方法。将视觉推理与代码执行相结合的能力代表了AI系统向更接近人类认知方式的方向发展,这种混合方法可能成为未来AI解决复杂物理任务的标准范式。
You can share your window and ask, 'What are the three biggest takeaways here?' to get an instant summary.
这种屏幕共享与AI分析结合的功能展示了AI如何理解视觉内容并提取关键信息的能力。这不仅是技术创新,更是工作流程的革命,预示着AI将从文本理解扩展到视觉内容分析,可能改变我们处理信息和数据的方式。
feat(benchmarks): add screenshot-based evaluator, screenshot collector, and --parallelize flag - Add screenshot-based LLM judge evaluator (evaluator.ts) - Add ScreenshotCollector for capturing browser screenshots during runs
令人惊讶的是:这个项目包含一个基于截图的评估系统,使用LLM作为评判员来评估自动化任务的结果。它能够捕获浏览器截图并在运行过程中收集这些视觉数据,这为网页自动化任务提供了一种全新的评估方式,超越了传统的文本比较方法。
Scrub through CSS `@keyframes` animations on a visual timeline.
令人惊讶的是:CSS Studio提供了可视化的动画时间线编辑功能,让设计师能够像操作视频时间轴一样直观地编辑CSS动画,包括添加、移动、编辑和删除关键帧,甚至可以调整持续时间、延迟、方向和缓动效果,这大大简化了复杂动画的制作过程。
The Many Lives of the Medieval Wound Man<br /> by [[Jack Hartnell]] in The Public Domain Review <br /> accessed on 2026-01-25T00:57:34
Use of a diagram in a medieval manuscript to index information visually to other parts of a text.
Qwen3-VL
Qwen models are by Alibaba. The VL versions are for visual inputs to generating code. Listed in ollama
My Last Duchess
Depending on the edition of the poem, after the title, there is supposed to be in italics, and all capitalized the word/name FERRARA.
However, It is important to note that the poem did not always feature FERRARA as an epigraph—it was intentionally added by Browning in later editions of the poem, hence scholar Louis S. Friedland’s exploration of the history of the Duke Vespasiano Gonzaga, and comparison to Duke Alfonso II d’Este.
What was discovered was that despite both Dukes having multiple marriages and young wives, Gonzaga’s wife, Diana Folch de Cardona, did not die young, unlike Lucrezia de' Medici—a point the poem hints to the reader. Through Friedland’s comparisons of the histories between the two to the poem, the final verdict aligned with d’Este as the mysterious Duke.
That’s my last Duchess painted on the wall, Looking as if she were alive.

The image is a painting of Lucrezia de' Medici, and though this was painted for her brother one year after her passing, this painting could be used as the stand-in for the image the Duke is describing. The Duchess' somber gaze is antithetical to how the Duke describes the Duchess as a person, which makes the reader question how much truth could the Duke be speaking. Is it possible that the Duke is imagining a smile on her face because he feels guilty? Is the Duchess' stoic look a reflection of her feelings, or was it "by design" as the Duke later states?
Notice Neptune, though, Taming a sea-horse, thought a rarity, Which Claus of Innsbruck cast in bronze for me!

The Duke's final words being about another artpiece he has demonstrates how little he cared for the Duchess. The need to brag about more art being made for him not only shows his ability to display power, but it also shows a reflection of his true intentions. The bronze cast is of Neptune (a god) taming a seahorse--this reflects how the Duke views himself: a god taming a lesser creature; as he sees himself as a god, he will inevitably treat the new duchess similarly. There was never going to be a dual-respect and understanding between him and the Duchess as she was as useful as a seahorse to him. His calculated shift from a painting of his "beloved" wife, to a bronze cast displaying a feat of dominance demonstrates the Duke's ability for social politics and directs attention away from the gruesome end of the Duchess.
My Last
While looking up the Duchess, Lucrezia de' Medici, came a poem called "My Next Duchess" by a priest named Lawrence Jones in which a member of the envoy warns of the Duke as a means to save the next duchess from his grasp. While the poem does not follow all the same writing conventions as Browning's poem such as form and tone, it is effective in the way that provides a secondary perspective on the story within this poem. The break of such conventions lends a sort of response that is more human that the facade that the Duke puts on.
The poem aims to explore how the envoy reacted to the Duke's monologue, and the horror at which is deemed worthy enough to become a cautionary tale to future noblewomen about the Duke of Ferrara.
BUT, knowing now that they would have her speak,
(https://youtu.be/91t7U1SjCTU)
In this YouTube video, “The Defence of Guenevere” is read by a female narrator whose soft, but firm tone highlights Guenevere’s resilience during her defense, making Guenevere appear more assertive. The narrator’s voice demonstrates Guenevere’s emotional state more vividly and convincingly, allowing listeners to better empathize with her defense against Sir. Gauwaine and other knights.
For, all day, we drag our burden tiring, Through the coal-dark, underground —
This article has photos of the book, the poem, and images from the survey of children working in mines relating to "Cry of The Children".
https://www.youtube.com/shorts/YdWLxoHYR1E
This video shows how close, cramp, and claustrophobic the mines would be. Also, the ground is sometimes lined with rails, other times consists purely of mud and even imbedded with large rocks. This little clip is an attempt to let the readers see the harsh conditions the children working in mines had to deal with daily.
Elizabeth Browning was friends and frequent correspondent with Richard Hengist Horne. RH Horne was the assistant commissioner to an inquiry that reported the "Physical & Moral Conditions of the Children and Young Persons Employed in Mines and Manufacture." The horrific conditions that Horne related to EBB spurred her to write "Cry of the Children" (Robertson).
Burningly it came on me all at once, This was the place! those two hills on the right, Crouched like two bulls locked horn in horn in fight; While to the left, a tall scalped mountain… Dunce, Dotard, a-dozing at the very nonce, After a life spent training for the sight!
When heard aloud, like in this reading of "Childe Roland" the irregularity of this stanza becomes more noticeable. For instance, heavy stresses pile up in “Crouched like two bulls locked horn in horn in fight,” and the abrupt pauses throughout break the poem’s forward rhythm. The rhyme sequence (once/right/fight/Dunce/nonce/sight) echoes unevenly, giving the language a tense, unstable energy. Essentially, at the precise moment of Roland’s recognition of “the place,” where there should be triumph, the poem loses composure, creating dissonance between narrative climax and emotional collapse. Heard this way, Browning’s form enacts the poem’s theme of meaning arriving through struggle, a quality that has made its strangeness continually compelling to later readers.
As for the grass, it grew as scant as hair In leprosy; thin dry blades pricked the mud
 This 1859 painting by Thomas Moran, inspired directly by Browning’s “Childe Roland,” visualizes the poem’s barren and hostile terrain. Turbulent clouds, jagged rocks, and desolate expanses dramatize the emotional weight of the quest. Additionally, the fiery, ominous sky evokes Romantic and Sublime traditions, but instead of ennobling Roland’s journey, the natural grandeur seems to overwhelm him. Rather than a knight striding toward a glorious destiny, the lone figure of Roland, dwarfed by the vast landscape, gazes toward the distant, looming tower. By pairing the poem with such imagery, anthology audiences can more fully experience the poem’s tension between heroic aspiration and environmental hostility. This artistic reimagining also shows how the Tower’s imagery quickly began to shape visual as well as literary culture.
This 1859 painting by Thomas Moran, inspired directly by Browning’s “Childe Roland,” visualizes the poem’s barren and hostile terrain. Turbulent clouds, jagged rocks, and desolate expanses dramatize the emotional weight of the quest. Additionally, the fiery, ominous sky evokes Romantic and Sublime traditions, but instead of ennobling Roland’s journey, the natural grandeur seems to overwhelm him. Rather than a knight striding toward a glorious destiny, the lone figure of Roland, dwarfed by the vast landscape, gazes toward the distant, looming tower. By pairing the poem with such imagery, anthology audiences can more fully experience the poem’s tension between heroic aspiration and environmental hostility. This artistic reimagining also shows how the Tower’s imagery quickly began to shape visual as well as literary culture.
So many times among “The Band”—-to wit, The knights who to the Dark Tower’s search addressed
When Roland recalls “the knights who to the Dark Tower’s search addressed,” he gestures toward a centuries-old literary tradition. The name Roland first appears in the eleventh-century La Chanson de Roland, a French chanson de geste celebrating the knight’s heroism at Roncevaux Pass under Charlemagne. In 1595, George Peele revived the name in The Old Wives’ Tale. Then, Robert Jamieson recorded a folk version of the tale and placed it within Arthurian legend, making Roland the son of Arthur and Guinevere. Joseph Jacobs’s English Fairy Tales, pictured below, adopted Jaimeson’s version and introduced the “Dark Tower” as the dwelling of the King of Elfland, where Roland must save his sister. Where earlier Rolands fought or rescued, Browning’s hero merely endures, stripped of glory or divine purpose. With this history in mind, this scene helps capture part of why “Childe Roland” continues to haunt later writers. Its hero perseveres not because he hopes to succeed, but because turning back would mean erasing the meaning of every struggle that came before.

“To Imagination” (1846)
Attached is reading from youtube.com to enhance the experience of the reader. The speaker is quiet and pensive as she moves through the poem and talks with the personified spirit of imagination. https://youtu.be/iIeVTWX3bho?si=_cHytep8B8emESj3
Personally, I love this; Image annotations.
This can be used as an effective analysis tool. Visual stimulus is powerful and for many individuals constitutes a deeper connection to fundamental learning. Balanced learning across the three basic modes; written, auditory and visual is implied in academics and the workplace but the reality is that one mode is dominant. Recognizing that mode and enhancing reaps far more advantage than forcing an inferior mode. @Byrnesz
iPhone Air Bumper - Light Blue
Apple incorporates large headings providing a smooth reading experience for visitors on their webpage to identify the products they are looking for. This practice ensures that those with visual impairments, or are not familiar with technology have a similar experience of those who are more tech savvy.
iPhone 17
Apple makes use of bright visuals of their bright coloured products contrasted with plain black and white plain background makes their products identifiable and clear. Such as their new Iphone Pro 17, a bright orange color in contrast to a black background. Also, Apple’s webpage provides interactive elements such as motion pictures of their products with in depth descriptions providing accessibility for consumers to shop from home.
the first, the serried collection ofdifferent objects transmits the idea of a total culinary service, on the one hand as though Panzanifurnished everything necessary for a carefully balanced dish
Idea: To advertise other products that Panzani sells, commonly used ingredients are placed around to show the variety of dishes that can be made using their products.
ts signifier is the half-open bag which lets the provisions spill out over the table, 'unpacked'.To read this first sign requires only a knowledge which is in some sort implanted as part of the habits ofa very widespread culture where 'shopping around for oneself' is opposed to the hasty stocking up(preserves, refrigerators)
Idea: When building a business one important thing to identify is your demographic. Based on Barthes analysis, Panzani demographic for this certain AD is for the individuals who live alone and want a delicious simple meal.
linguistic
Defintion of Linguistic: The study of human speech including the units, nature, structure, and modification of language
Your file structure might look something like this:
poor man's file structure diagram
Voici un sommaire de la vidéo avec des indications temporelles basées sur le déroulement du contenu :
Introduction (Début de la vidéo) : L'introduction est faite par Elena, la fondatrice de Toadhouse Games. Elle explique que ce tutoriel est conçu pour les débutants qui n'ont aucune connaissance en codage et que les premières vidéos seront gratuites sur YouTube. Elle présente Ren'Py comme un moteur de roman visuel utilisé par des milliers de créateurs.
Qu'est-ce que Ren'Py ? (Environ 0:00 - 1:00) : Ren'Py est un moteur pour créer des romans visuels et de la fiction interactive. Bien qu'il fonctionne avec du code Python, il n'est pas nécessaire de savoir coder pour l'utiliser. Le logiciel fournit tout ce dont vous avez besoin, y compris des éditeurs de texte.
Téléchargement de Ren'Py (Environ 1:00 - 2:00) : Il faut se rendre sur ri.org et cliquer sur le bouton de téléchargement. Différentes versions sont disponibles pour Windows, Mac, Linux, Android et iOS. Une fois le fichier téléchargé, il faut l'exécuter et extraire les fichiers dans le dossier de votre choix.
Ouverture et présentation du lanceur Ren'Py (Environ 2:00 - 4:00) : Dans le dossier extrait, double-cliquez sur l'application Ren'Py (l'icône avec un anime) pour ouvrir le lanceur. Le lanceur affiche les projets ouverts (tutoriel et question par défaut) et les fichiers associés à chaque projet. Sur la droite, l'option "script" permet d'accéder aux fichiers de code, qui peuvent être édités dans un éditeur de texte comme Atom. Ren'Py peut télécharger et installer Atom pour vous.
Exploration des fichiers du projet (Environ 4:00 - 5:00) : Le dossier "game" contient tous les fichiers du jeu (audio, musique, images, etc.). Un raccourci vers le dossier "images" est également disponible. Le fichier "script" contient le code du jeu, y compris les dialogues, les transitions, la musique et les scènes. Les options et les écrans (screens) permettent de personnaliser l'apparence du jeu.
Construction et distribution du jeu (Environ 5:00 - 5:30) : L'option "build distributions" permet de créer une version jouable de votre jeu pour la partager avec d'autres sur différentes plateformes comme PC, Linux, Mac, itch.io ou Steam.
Exercice pratique avec le projet "The Question" (Environ 5:30 - 8:00) : Il est recommandé de sélectionner le projet "the question" et de lancer le projet pour jouer au jeu. Ensuite, ouvrez le script du projet "the question". L'exercice consiste à jouer au jeu tout en regardant le code correspondant dans l'éditeur de texte. Cela permet de comprendre comment le code contrôle le déroulement du jeu (musique, scènes, dialogues, choix). Il est possible de faire de petites modifications dans le script et de recharger le jeu pour voir les changements.
Présentation de Scrivener (Environ 8:00 - 9:00) : Scrivener est un logiciel optionnel qui peut être utilisé pour écrire le dialogue et organiser le contenu de votre roman visuel. Un modèle Ren'Py pour Scrivener créé par Toadhouse Games est disponible. Scrivener propose des conseils d'écriture de base et des modèles pour les profils de personnages et le code Ren'Py.
Conclusion (Environ 9:00 - Fin de la vidéo) : Elena encourage les spectateurs à commencer à expérimenter avec Ren'Py en modifiant le projet "the question". Des tutoriels plus avancés sur les "flags" et les choix seront proposés ultérieurement. Des ressources d'aide sont disponibles sur Twitter, par e-mail (teamtoadhouse@gmail.com), sur les subreddits et les forums Ren'Py, ainsi que sur le Discord de Toadhouse Games.
Voici un sommaire avec des indications temporelles basées sur le déroulement de la vidéo :
Elle mentionne des ateliers animés par des professionnels de Toad House pour aider à la création de visual novels. L'objectif est de rendre la création de jeux accessible aux débutants.
Elle précise que Ren'Py est un moteur de jeu open source et gratuit spécialement conçu pour les visual novels. Elle cite d'autres moteurs de jeu comme Unity, Unreal, Game Maker, Godot et Twine, notant qu'ils sont adaptés à différents types de jeux.
Elle souligne que la connaissance de Python n'est pas nécessaire pour utiliser Ren'Py, bien que le "pi" dans Ren'Py fasse référence à Python.
Elena mentionne que le site de Ren'Py contient de la documentation, qui est parfois considérée comme peu conviviale.
Elle recommande également le serveur Discord Ren'Py et le forum Lumisoft comme ressources d'aide.
La documentation couvre les bases et les utilisations plus spécifiques de Ren'Py, y compris les systèmes de dates, de monnaie et d'inventaire.
Elena montre l'interface du lanceur Ren'Py, affichant des projets existants comme ceux de Toad House Games.
Elle explique comment créer un nouveau projet, choisir la langue (avec des options comme le pig latin) et sélectionner un éditeur de texte (recommandant Adam, qui peut être téléchargé directement depuis Ren'Py).
Il est possible de choisir la résolution du projet, avec 1280x720 comme valeur par défaut, et un schéma de couleurs clair ou foncé pour l'interface (GUI).
Elena présente la structure des dossiers créés pour un nouveau projet Ren'Py, notamment les dossiers game (contenant images, audio, gui, saves), audio cache et autres.
Elle explique que le fichier script.rpy est l'endroit où le code du jeu est écrit.
Elle montre comment remplacer l'icône de l'application et modifier les éléments de l'interface graphique dans le dossier gui.
Elena lance le projet par défaut de Ren'Py pour montrer les fonctionnalités intégrées comme les sauvegardes, les chargements, les préférences (volume, plein écran, saut, etc.) et l'écran "À propos". Elle exécute le court jeu par défaut pour illustrer la structure de base : arrière-plan (bg), sprites et dialogue.
Elle ouvre ensuite le fichier script.rpy dans Adam pour montrer le code correspondant, expliquant les déclarations de personnages (define) et le point de départ du jeu (label start).
Elle montre comment écrire du dialogue en utilisant le nom du personnage défini. Elle aborde la question de la gestion de plusieurs personnages avec des noms similaires.
Outil Narratif Scrivener (Environ 19-22 minutes) : Elena présente Scrivener comme un outil utile pour la planification et l'écriture du récit d'un visual novel, permettant d'organiser l'intrigue, les dialogues et même d'intégrer des éléments de code de base avant de les copier-coller dans Ren'Py.
Narration et Positionnement du Texte (Environ 22-24 minutes) : Elena explique comment gérer le texte de narration (sans nom de personnage), souvent utilisé pour les pensées internes.
Elle mentionne les deux modes de texte principaux dans Ren'Py : en bas de l'écran et en plein écran (NVL). Elle déconseille de placer le texte narratif ailleurs à cause de la complexité du code.
Elena démontre comment créer des choix (menu) dans Ren'Py, en utilisant les mots-clés menu, les options et les actions à entreprendre (texte, jump vers un autre label, call à un autre label).
Elle explique la différence entre jump (saut sans retour) et call (appel avec retour après un return).
Elle introduit le concept de drapeaux (flags), qui sont des variables utilisées pour suivre les décisions du joueur et influencer le déroulement de l'histoire (default nom_du_drapeau = False, \$ nom_du_drapeau = True, if nom_du_drapeau:).
Elle montre comment les drapeaux peuvent être utilisés avec des instructions if pour afficher du contenu conditionnel.
Elena examine le jeu tutoriel inclus avec Ren'Py, soulignant ses fonctionnalités (sauvegarde, chargement, préférences, rollback, historique) et son contenu éducatif sur les bases de Ren'Py.
Elle explore ensuite le jeu d'exemple "The Question", attirant l'attention sur l'analyse du jeu du point de vue d'un développeur (apparence des sprites, positionnement, expressions, choix).
Elle montre comment le code du jeu "The Question" utilise la définition de personnages avec des couleurs de texte personnalisées (codes hexadécimaux), les drapeaux et la structure des labels pour créer des choix et des embranchements narratifs.
Elena présente le code de son jeu "Good Looking Home Cooking" comme un exemple plus complexe, montrant l'utilisation de définitions pour les sons, les curseurs et les personnages (avec des propriétés comme la couleur et le texte alternatif pour la synthèse vocale).
Elle explique l'utilisation de variables pour suivre les choix importants (drapeaux) et comment ces drapeaux sont utilisés dans les menus et les instructions conditionnelles pour créer différents embranchements et fins.
Elle illustre l'utilisation de transformations et de positionnement pour les sprites, les transitions (dissolve, fade to black), et la création d'une séquence de crédits animée à partir d'une image PNG défilante. Elle discute des différentes fins possibles dans un visual novel (bonne, mauvaise, tiède).
Elena aborde la question de la taille des images, expliquant qu'elle est déterminée par essai et erreur pour correspondre à la résolution du projet et à l'aspect souhaité. Elle montre des exemples d'arrière-plans filtrés dans le jeu Ren'Py "Karashojo".
Elena termine en donnant des conseils pour la gestion du temps et éviter le "crunch" pendant le game jam, notamment en se fixant des mini-échéances régulières et en étant réaliste quant à la portée du projet.
Elle encourage les participants à utiliser des outils comme Scrivener et à rejoindre la communauté Discord pour trouver de l'aide et des collaborateurs.
Elle rappelle l'importance d'inclure la mention légale de Ren'Py dans le jeu.
Voici un sommaire avec des horodatages (timestamps) de la vidéo, mettant en évidence les points les plus importants en gras et en français :
Document de Briefing : Conception de Jeux Vidéo de Type Visual Novel
Source : Extraits de la diffusion en direct "Basic Visual Novel Art | Characters and Environments | Lecture Stream | with Heather Gartner"
Date : Non spécifiée dans le texte
Présentateur : Heather Gartner (Thunderbird Paints), Lead Artist et Art Director chez Toad House Games.
Public Cible : Artistes débutants et développeurs de visual novels, potentiellement participants à une game jam (Toad House Jam).
Objectif de la Diffusion : Fournir des bases et des conseils pratiques pour la conception de personnages, d'environnements et potentiellement d'interfaces utilisateur (UI) pour les visual novels.
Thèmes Principaux et Idées Clés :
I. Introduction et Préambule :
II. Conception de Personnages :
III. Conception d'Environnements :
IV. Interface Utilisateur (UI) :
Le temps imparti ne permet pas d'aborder en détail la conception de l'UI. Heather invite les spectateurs à la contacter sur Discord pour toute question concernant l'UI.
V. Conclusion :
En Résumé :
Cette diffusion en direct offre une introduction pratique à la conception visuelle pour les visual novels.
Heather Gartner partage son expérience et ses méthodes de travail pour la création de personnages et d'environnements, en mettant l'accent sur l'importance du scénario comme point de départ, la considération des détails pour la reconnaissance des personnages, et l'utilisation de références et de techniques d'éclairage pour les environnements.
Elle encourage également la simplification et la réutilisation d'assets pour les projets avec des contraintes de temps. Bien que l'UI n'ait pas été abordée, la session fournit une base solide pour les artistes débutants et les développeurs de visual novels.
for - Indyweb dev - open source AI - text to graph - from - search - image - google - AI that converts text into a visual graph - https://hyp.is/KgvS6PmIEe-MjXf4MH6SEw/www.google.com/search?sca_esv=341cca66a365eff2&sxsrf=AHTn8zoosJtp__9BMEtm0tjBeXg5RsHEYA:1741154769127&q=AI+that+converts+text+into+visual+graph&udm=2&fbs=ABzOT_CWdhQLP1FcmU5B0fn3xuWpA-dk4wpBWOGsoR7DG5zJBjLjqIC1CYKD9D-DQAQS3Z598VAVBnbpHrmLO7c8q4i2ZQ3WKhKg1rxAlIRezVxw9ZI3fNkoov5wiKn-GvUteZdk9svexd1aCPnH__Uc8IUgdpyeAhJShdjgtFBxiTTC_0C5wxBAriPcxIadyznLaqGpGzbn_4WepT8N6bRG3HQLK-jPDg&sa=X&ved=2ahUKEwju5oz8ovKLAxW6WkEAHaSVN98QtKgLegQIEhAB&biw=1920&bih=911&dpr=1 - to - example - open source AI - convert text to graph - https://hyp.is/UpySXvmKEe-l2j8bl-F6jg/rahulnyk.github.io/knowledge_graph/
https://rahulnyk.github.io/knowledge_graph/
for - Indyweb dev - text to graph - open source AI - convert text to graph - adjacency - infranodus - to - AI program to convert text into visual graph
for - search - Google - image - AI that converts text into any visual graph - https://www.google.com/search?sca_esv=341cca66a365eff2&sxsrf=AHTn8zoosJtp__9BMEtm0tjBeXg5RsHEYA:1741154769127&q=AI+that+converts+text+into+visual+graph&udm=2&fbs=ABzOT_CWdhQLP1FcmU5B0fn3xuWpA-dk4wpBWOGsoR7DG5zJBjLjqIC1CYKD9D-DQAQS3Z598VAVBnbpHrmLO7c8q4i2ZQ3WKhKg1rxAlIRezVxw9ZI3fNkoov5wiKn-GvUteZdk9svexd1aCPnH__Uc8IUgdpyeAhJShdjgtFBxiTTC_0C5wxBAriPcxIadyznLaqGpGzbn_4WepT8N6bRG3HQLK-jPDg&sa=X&ved=2ahUKEwju5oz8ovKLAxW6WkEAHaSVN98QtKgLegQIEhAB&biw=1920&bih=911&dpr=1
search - google - image - AI that converts text into visual graph - interesting results returned - to - article - Medium - How to convert any text into a graph of concepts -
Amazon's dense array of visual elements, text, and advertising can create cognitive overload, making it difficult for users with cognitive impairments to navigate the site effectively. Bright pink banners or light text on some backgrounds may not have enough contrast to meet the WCAG guidelines. This makes it difficult for users with poor eyesight to read clearly.
ields
Another visual map reference to the Flanders region:
including external characteristics, social activities, and mental constitution.
what they include
closely tied to colonization as part of European expansion.
Eckhout's works are examples of this term because they are products of the period in which the genre of the ethnographic portrait was created.
based on observation rather than exoticism ?
Albert Eckhout, which occupy a transitional space between the national type of the 16th and 17th centuries and the racial categories that developed in the 18th and 19th centuries.
7th century, the representation of skin color began to take on more importance, and engravings of Africans and Americans started to suggest differences in complexion.
changed from a focus on clothing etc to focus on skin colour to reflect race concerns.
for - BEing journey - sensory substitution - visual to auditory - The vOICe Android app - from - search - Google - google play the vOICEe visual to auditory from - search - Google - google play the vOICEe visual to auditory - ghttps://hyp.is/KU2PuJ2PEe-XesNTfrguIQ/www.google.com/search?q=google+play+the+vOICEe+visual+to+auditory&sca_esv=53a8ca786e59126d&sxsrf=ADLYWIJoqIizFiTxAfm09a65hUuKEgKq_g:1731042142105&ei=XpstZ8-RBoSdhbIP9f3VkA4&ved=0ahUKEwjPuOK_-suJAxWETkEAHfV-FeIQ4dUDCA8&uact=5&oq=google+play+the+vOICEe+visual+to+auditory&gs_lp=Egxnd3Mtd2l6LXNlcnAiKWdvb2dsZSBwbGF5IHRoZSB2T0lDRWUgdmlzdWFsIHRvIGF1ZGl0b3J5MgcQIRigARgKMgcQIRigARgKSLZMUKgLWPtDcAF4AZABAJgB1QOgAZ5VqgEGMy0yNi40uAEDyAEA-AEBmAIfoALGVcICChAAGLADGNYEGEfCAg0QABiABBiwAxhDGIoFwgIOEAAYgAQYkQIYsQMYigXCAhEQABiABBiRAhixAxiDARiKBcICCBAAGIAEGLEDwgIFEAAYgATCAgsQABiABBixAxiDAcICCxAAGIAEGJECGIoFwgIKEAAYgAQYFBiHAsICBhAAGBYYHsICCBAAGBYYChgewgIHEAAYgAQYDcICCxAAGIAEGIYDGIoFwgIIEAAYgAQYogTCAggQABgWGB4YD8ICBhAhGBUYCsICBBAhGAqYAwCIBgGQBgqSBwgxLjMtMjUuNaAHlZsB&sclient=gws-wiz-serp
for - umwelt - sensory substitution - visual to auditory - V2A - David Eagleman - from - webcast - Michael Levin - Can we create new senses for humans? - interview - David Eagleman - https://hyp.is/BHS6up09Ee-1qefERFpeQg/www.youtube.com/watch?v=YCvFgrpfNGM - to - Google Play - Android app -
little camera on glasses and you turn it into an audio image um and there are very sophisticated examples of this now one is called The Voice v i and it's it's an app that you can just download on your phone
for - Deep Humanity - BEing journey - example - umwelt - visual to audio app - The Voice - David Eagleman - to - search - Google - android app "The Voice" translates images into audio signal - https://hyp.is/OJKKmJ1MEe-TAp_w_0SK_Q/www.google.com/search?q=android+app+%22The+Voice%22+translates+images+into+audio+signal&sca_esv=6fa4053b1bfce2fa&sxsrf=ADLYWIK_UqZZZ9OCRCwH4D6FoSaykbMTpQ:1731013461104&ei=VSstZ4eCBqi8xc8P5KP_kAU&ved=0ahUKEwjHgM3Tj8uJAxUoXvEDHeTRH1IQ4dUDCA8&uact=5&oq=android+app+%22The+Voice%22+translates+images+into+audio+signal&gs_lp=Egxnd3Mtd2l6LXNlcnAiO2FuZHJvaWQgYXBwICJUaGUgVm9pY2UiIHRyYW5zbGF0ZXMgaW1hZ2VzIGludG8gYXVkaW8gc2lnbmFsMggQABiABBiiBDIIEAAYgAQYogQyCBAAGIAEGKIEMggQABiABBiiBDIIEAAYgAQYogRI2xdQpglYjRJwAXgCkAEAmAGZA6ABmQOqAQM0LTG4AQPIAQD4AQGYAgOgAqADwgIKEAAYsAMY1gQYR8ICBBAAGEeYAwDiAwUSATEgQIgGAZAGCJIHBTIuNC0xoAewBA&sclient=gws-wiz-serp
The vOICe is the most practical and widely used, clearly demonstrated by its 100k+ downloads and around 1300 current active users on Android only.
for - BEing journey - sensory substitution - visual-to-auditory (V2A) - Android app - The vOICe - to - Android app - The vOICe - https://hyp.is/T8YlEJ0_Ee-jKFfo0TcpWQ/medium.com/mindsoft/translating-vision-into-sound-443b7e01eced
Visual-to-auditory (V2A) sensory substitution devices are designed to convert images to sound.
for - BEing journey - sensory substitution - visual-to-auditory (V2A)
Time Series
The Prometheus time series are streams of timestamped values belonging to the same metric and the same set of labeled dimensions. Prometheus stores all data as time series.


A sample is a single value at a point in time in a time series.
In Prometheus, each sample consists of a float64 value and a millisecond-precision timestamp.
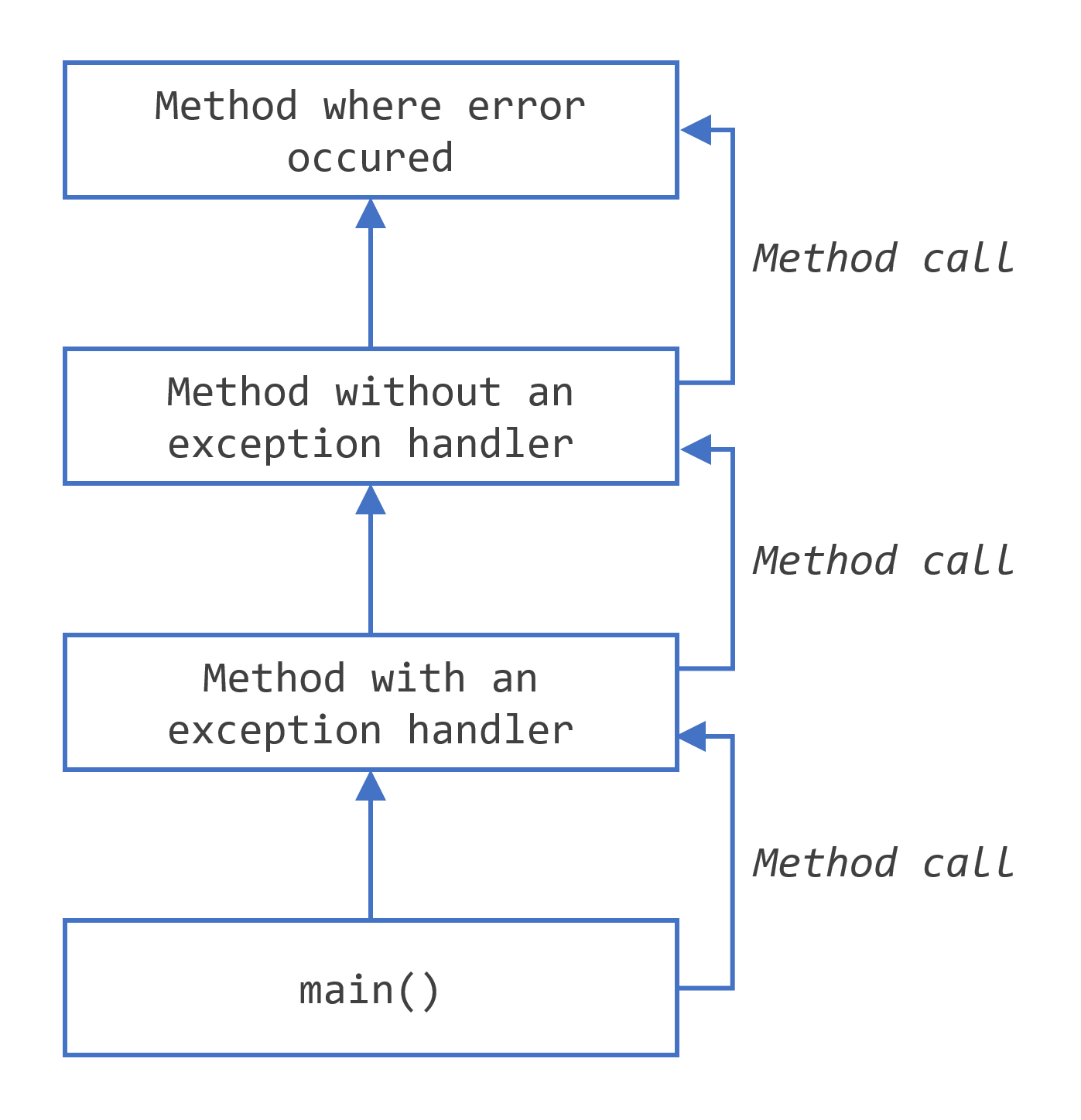
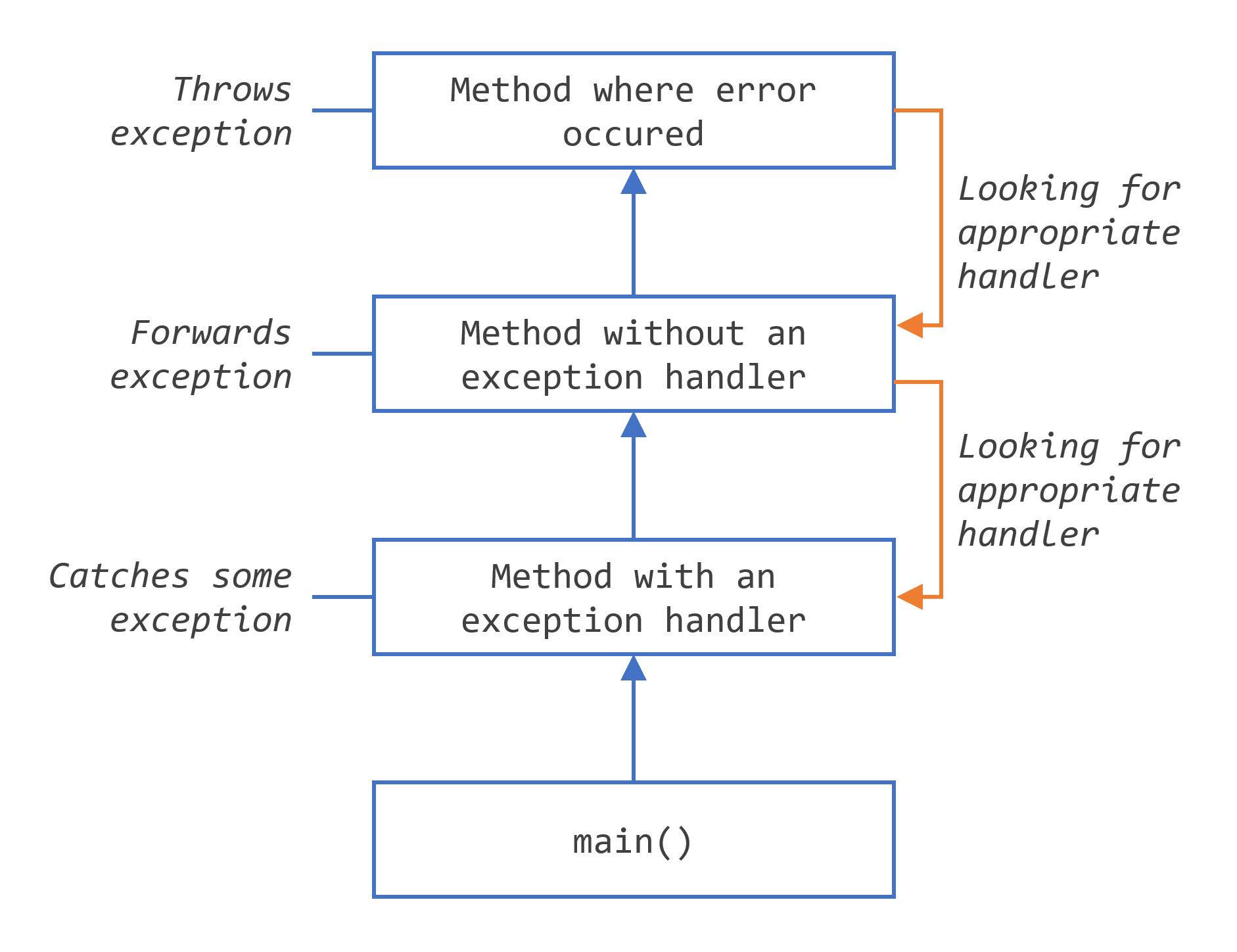
Searching the call stack for the exception handler
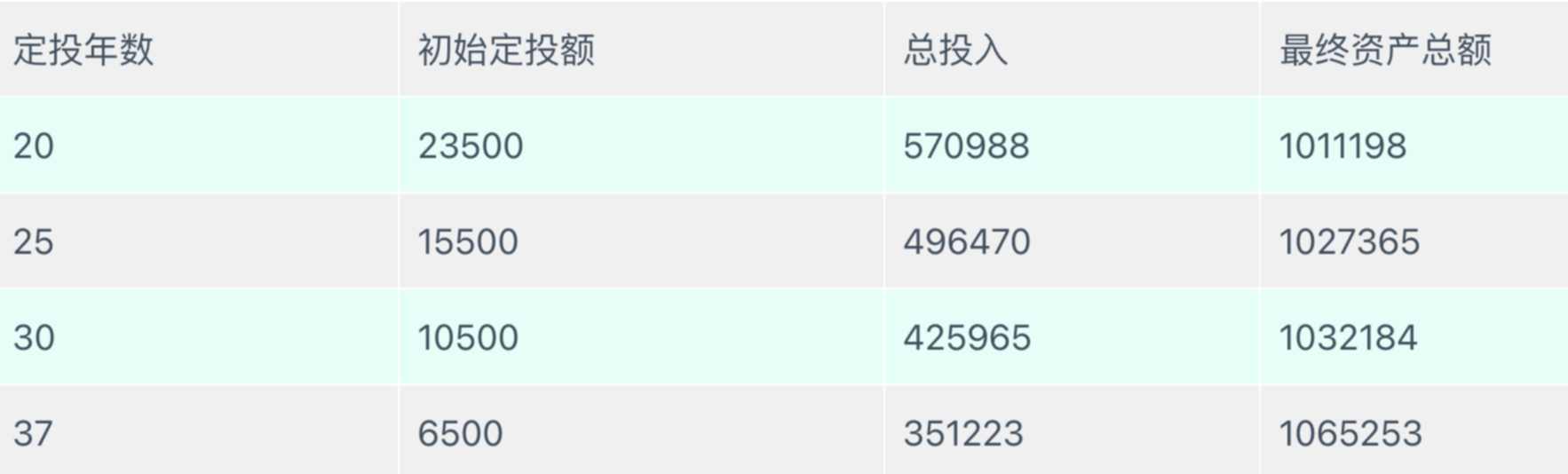
根据自己的年龄,可以依据上表的计算结果估计第一年需要的定投量。比如67岁退休,而现在是30岁,退休前还可以定投37年。那么想要退休时拥有百万欧元的资产,第一年要定投6500欧元,相当于每月投入542欧元。当然股市是有波动的,假如在定投的最后几年赶上了超级熊市,可能资产并不能在退休时达到100万欧元,但是只要再等等,总会等到牛市的。
定投年数和初始定投额

Our diagrams and charts make it easy to see where every dollar of your hard-earned money is flowing, so you can track your spending patterns at a glance.
my visual cortex loves the point-symmetric "tunnel visions" from 1:50<br /> aka: visual cortex form constants, resonance between external and internal patterns<br /> this is also why kids in school are forced to write on "lined paper" aka "ruled paper"...
Software and applications for creating visualizations of zettelkasten contents: - Tinderbox (Mac) - Apple's Freeform (app) - Obsidian Canvas - Excalidraw (plugin for Obsidian) - Scrintal - Heptabase - Card Buddy (Mac) - AFFiNE (https://github.com/toeverything/AFFiNE)
Publish completed designs to Zeplin's platform while you iterate on designs in your design tool.
I'm not sure that isolating design is something I'd prefer. I'd rather have an issue tagged (labeled) as such, and then attach design artifacts. I start a design in the same way I start frontend, with a list of requirements and acceptance criteria in mind, the design is just an artifact, a deliverable, an asset.
I feel that the current design area should be a key part of the workflow on any work item, not just type of designs. As a PM I don't schedule designs independently. It's odd to open and close a design issue when it doesn't deliver value to the customer.
考虑到现有模型还没有探索,什么样的Instruction数据集是更有效的,而且什么因素导致了好的Instruction data,暂未有人探索。 考虑到这些问题,作者探索什么是好的visual Instruction这个问题。基于这个目标,作者首先对现有的 visual Instruction set进行了评估,目标是发现关键因素。
作者主要从task type和Instruction characteristic两个方面来评估。作者选择了六个典型的Instruction dataset,使用两个典型的BLIP2和MiniGPT-4来评估。根据实验结果,作者发现: 1. 对于task type,视觉推理任务对于提升模型的image caption和quetison answering任务很重要。 2. 对于Instruction characteristic,提升Instruction的复杂度更加有帮助对于提升性能,相比task的多样性,以及整合细粒度的标注信息。
基于上述发现,作者开始构建复杂的视觉推理指令集用于改善模型。
首先最直接的方法是通过chatgpt和gpt4来优化指令集,基于图像的标注。因为指令集跨跨模态的特性,LLMs可能会过于简单甚至包含本来图片中不存在的物体。 考虑到上述问题,作者提出了一个系统的多阶段的方法,来自动生成visual Instruction数据集。
输入一张图,根据可以获得标注,caption或者object,作者采用了一种先生成,再复杂化,再在重组的pipeline来生成Instruction。具体的,作者首先,使用特殊的prompt指导prompt来生成一个初始指令。然后使用迭代的方式,复杂化-->验证的方式,来逐步提升Instruction的复杂程度,同时保证质量。最后,将Instruction重组成多种形式,在下游任务重,获得更好的适应性。
任务类型,之前的指令微调的数据集,都是利用带有标注的图片。主要包括一下三个任务类型: 1. Image Caption,生成文本描述 2. VQA任务:需要模型根据问题生成关于图片的回答 3. Visual reasoning:需要模型基于图片内容进行推理。
为了研究任务类型的影响, 作者考虑一个最常用的指令微调数据集LLaVA-Instruct。作者将其划分成三个子数据集,LLaVA-Caption, LLaVA-VQA and LLaVA-Reasoning。
指令特性: 指令的特性包括。 * 任务的多样性,已经有工作发现,提升工作的多样性,对于zero-shot能力是有帮助的。可以通过和不同的任务整合来获得此类能力。 * 指令的复杂程度,这是一个被广泛应用的策略,提升LLMs指令集的复杂程度。作者同样使用复杂的多模态做任务,例如,多跳的推理任务,来提升MLLMs的指令遵循能力。 * 细粒度的空间感知。对于MLLMs而言,感知细粒度的空间信息对图片中的特定物体,是必要的。基于这个目标。空间位置的标注可以包括在有文本的指令集中。
(Weight W1) (Rope Rp) (Rope Rq) (Pulley Pa) (hangs W1 from Rp) (pulley-system Rp Pa Rq) (Weight W2) (hangs W2 from Rq) (Rope Rx) (Pulley Pb) (Rope Ry) (Pulley Pc) (Rope Rz) (Rope Rt) (Rope Rs) (Ceiling c) (hangs Pa from Rx) (pulley-system Rx Pb Ry) (pulley-system Ry Pc Rz) (hangs Pb from Rt) (hangs Rt from c) (hangs Rx from c) (hangs Rs from Pc) (hangs W2 from Rs) (value W1 1) (b) P1. P2. P3. P4. .. Single-string support. (weight < Wx>) (rope <Ry >) (value <Wx> <n>) (hangs <Wx> <Ry>) -(hangs <Wx> <Rx>) - (value <Ry> <W-number>) Ropes over pulley. (pulley <P>) (rope <R1>) (rope <R2>) (pulley-system <R1 > <P> <R2>) (value <R1> <nl>) - (value <R2> <nl>) Rope hangs from or supports pulley. (pulley <R1>) (rope <R1>) (rope R2>) (pulley-system <R1> <P> <R2>) { (hangs <R3> from <P>) or (hangs <P> from <R3>) } (value <R1> <nl>) (value <R2> <n2>) - (value <R3> <nl + <n2>) Weight and multiple supporting ropes. (weight <W1 >) (rope <R1 >) (rope R2>) (hangs <W1> <Rl>) (hangs <W1> <R2>) -(hangs <W1> <R3>) (value <R1> <nl>) (value <R2> <n2>) - (value <W1> <nl> + <n2>) P2. Ropes over pulley. If a pulley system < P> has two ropes < RI > and < R2> over it, and the value (tension) associated with < RZ > is < nl > , then < nl > is also the value associated with rope < RZ > . P3. Rope hangs from or supports pulley. If there is a pulley system with ropes < RZ > and < R2> over it, and the pulley system hangs from a rope < R3 > , and c R1> and < R2 > have the values (tensions) < nl > and < n2 > associated with them, then the value (tension) associated with < R3 > is the sum of < nl > plus <n2>.
Please explain to me how it is not evident to programmers that this is how we program.. we cannot hold more than seven items at a time. We cannot fracture. As Miller mentioned, 2 3 digit numbers are outside t capacity, but if you multiply them by paper w, if we free your memory, we can let the brain focus on the v
If you assign the memory function to a diagram, you can let your brain concentrate on the manipulation function.
Once we codify, we no longer have to keep the information in memory, for example : This hurts my brain
There are five roads in Brown County. One runs from Abbeville to Brownsville by way of Clinton. One runs from Clinton to Derbyshire by way of Fremont. One runs from Fremont to Brownsville by way of Abbieville. That's all the roads in Brown County, and all the roads in and out of those towns.
Which towns have roads connecting them directly to three other towns? Which towns have roads connecting them directly to only two other towns? How many towns must you pass through to get from Brownsville to Derbyshire?
But if we diagram it to a map, all of this makes sense.
"The learning of numbers and language must be subordinated ... Visual understanding is the essential and only valid means of teaching how to judge things correctly." ~ Johann Heinrich Pestalozzi
Pestalozzi was the guy who designed the educational system in which Einstein, the most extraordinary visualization of his time, was born q
what about the visual field itself? Can it reveal anything about its being seen by an eye? Yes. Why, because there is a structure of a vanishing point and vanishing lights, 00:06:14 converging towards the vanishing point. The vanishing point is the expression in the visual field of it being seen from somewhere. Namely, from an eye.
In order to enable MPP, users must have Apple devices, configure their email account to use Apple Mail applications, update their operating system to the latest version, and opt into MPP.
https://xtiles.app/en
Map of Content Vizualized (VMOC)
a start of thinking on the space of converging written and visual thinking, but not as advanced as even Raymond Llull or indigenous ways of knowing which more naturally merge these modes of thinking.
Western though is just missing so much... sigh
It is difficult to see interdependencies This is especially true in the context of learning something complex, say economics. We can’t read about economics in a silo without understanding psychology, sociology and politics, at the very least. But we treat each subject as though they are independent of each other.
Where are the tools for graphing inter-dependencies of areas of study? When entering a new area it would be interesting to have visual mappings of ideas and thoughts.
If ideas in an area were chunked into atomic ideas, then perhaps either a Markov monkey or a similar actor could find the shortest learning path from a basic idea to more complex ideas.
Example: what is the shortest distance from an understanding of linear algebra to learn and master Lie algebras?
Link to Garden of Forking Paths
Link to tools like Research Rabbit, Open Knowledge Maps and Connected Papers, but for ideas instead of papers, authors, and subject headings.
It has long been useful for us to simplify our thought models for topics like economics to get rid of extraneous ideas to come to basic understandings within such a space. But over time, we need to branch out into related and even distant subjects like mathematics, psychology, engineering, sociology, anthropology, politics, physics, computer science, etc. to be able to delve deeper and come up with more complex and realistic models of thought.Our early ideas like the rational actor within economics are fine and lovely, but we now know from the overlap of psychology and sociology which have given birth to behavioral economics that those mythical rational actors are quaint and never truly existed. To some extent, to move forward as a culture and a society we need to rid ourselves of these quaint ideas to move on to more complex and sophisticated ones.
09:36 - From his early youth, he loved to collect stamps,09:42 and he said if all the images which are around us09:47 would have been lost,09:47 an album of stamps would help us to understand the world.
Just as Warburg's suggestion that an album of collected stamps could help us to understand the world visually if all other images were lost, perhaps subsections of traces of other cultures could do the same.
Although Virgil, MM and others like them certainly possess a rudimentary form of vision, decades of visual deprivation may never be completely redeemable. The human brain has an amazing capacity for plasticity, but there are some things that it cannot do. MM will likely never see the way that we see.
// Gradients of perceptual experiences of reality - The sense impaired teach us something fundamental about human nature. - The majority of non-sense-impaired people create the cultural norms of reality - but this reality can be very different for the sense impaired - Our reality is, to a large extent constructed from by our brain and depends on critical sensory inputs - But what is the brain itself, this magical organ that makes sense of reality? - The answer is going to vary depending on the subject experiencing it as well
MM's visual capacities continue to improve, but he also remains somewhat uncomfortable with his new sense. As a blind person, MM became extremely proficient at skiing, with the help of a guide to give him oral directions. After his eyesight was restored, skiing frightened him. The trees, snow, slopes, people -- everything whizzed by him, chaotic and uninterpretable. After much practice, he is now a moderate sighted skiier -- but when he really wants to go fast and feel confident, he closes his eyes.
// In Other Words - when sensory organs fail while we are young - we may construct different interpretations, and therefor experiences of our perceived realities - and adapt to them effortlessly. - If not for social stigma from the normative population, they would not know the difference - once we've adapted to sensory abnormalities, - a return to the normative way of experiencing reality via some medical intervention - that corrects a deficient sensory modality - is not guarantied to create the normative perceptual experience ordinary people have
There is a window of opportunity in youth, often called a critical period, during which the brain can best form neural connections that correspond both to retinal images and to practical experience. During the critical period for the visual cortex, normal visual input is required to wire everything correctly. If input is missing during this period, the brain's links will probably not be built correctly. In fact, brain tissue ordinarily used in visual processing might even be taken over by other systems, perhaps tactile or olfactory systems. Some of MM's visual abilities lend further support to the theory that he missed a critical period of visual development. He is quite good at visual tasks that involve motion. Tasks that stumped him at first often became solvable if motion was incorporated into them. He became able to detect the circular patterns in random noise if the patterns were moving. And he began to see the "square with lines" as a cube if the lines moved, and the cube appeared to be rotating. At the end of their evaluations, the researchers saw some patterns emerging in MM's visual abilities and deficiencies. His ability to detect and identify simple form, color, and motion is essentially normal. His ability to detect and identify complex, three-dimensional forms, objects, and faces is severely impaired. The researchers have a tentative explanation for these variations in visual skill. Motion processing develops very early in infancy compared with form processing. By the time MM lost his eyesight in the accident, the motion centers in his brain were probably nearly complete. So when he regained some eyesight in his forties, those connections in the brain were ready to go. The parts of the brain that process complex shapes, however, do not develop until later in childhood, so MM's brain likely missed its chance to establish those particular brain connections. The authors also propose that our brains may retain the ability to modify and refine complex form identifications throughout life, not just throughout childhood. New objects and faces are continually encountered throughout life, and our visual processing centers must be able to adapt and learn to see new shapes and forms. MM's brain never had the chance to learn.
// summary - MM could perform better if motion was involved - It is known that motion processing develops very early in infancy, whilst form processing occurs much later - the researchers hypothesized that when MM had his accident, he had already experienced enough motion processing to be familiar with it, but had not had any opportunity to perform form processing yet. - He missed the early opportunity and other brain functions took over those plastic areas, crowding out the normally reserved functional development
//
By far the most difficult tasks for MM involve three-dimensional interpretation of his environment. When an image is projected onto the retina, it is two dimensional, because the retina is essentially flat. When we are very young, our brains learn to use depth cues, such as shadows and line perspective, to see the three-dimensional world. Eventually, incorporating these cues into a coherent picture of the world becomes involuntary. Our ability to judge size correctly is one example of the brain's reinterpretation of two-dimensonal images. When a person walks away from us, the image of her becomes smaller and smaller on our retina. We know that people do not actually shrink as they move away, however. The brain combines the shrinking retinal image with perspective and depth cues from the surroundings, and we "decide" that the person is moving away. When MM lost his sight when he was three years old, his brain probably had not yet constructed the connections that incorporate separate perceptions into one combined perception. When a person walks away from MM, he has to remind himself that the person is not actually shrinking in size!
// Constructing 3D interpretation of visual information - most adults take for granted that an "object" has a fixed "size" - this depends on learning how to synchronize depth cues and shrinking retinal image size.at an early age - when we lose that ability, it dramatically impacts our perceptual construction of vision
//
If you have experienced trouble in rememberingdates try the following system which has proved beneficial to at least onestudent.
Maxfield suggest drawing out a timeline as a possible visual cue for helping to remember dates. He seemingly misses any mention of ars memoria techniques here.
the illusion of subject object duality 01:21:14 because the moment i think of myself as a self then i think that there's me a subject and then there's my objects there's the i and there's its visual field and they're totally different from one 01:21:26 another and that the basic structure of experience is there's me the subject who's always a subject and never an object and then all of those objects and i take that to be primordially given to 01:21:39 be the way experience just is instead of being a construction or superimposition so that's one illusion
!- self illusion : creates illusion of duality - as soon as a self is imputed, that is metaphorically Wittgenstein's eye that stands in opposition to the visual field, the object - hence, existence of the imputed self imputes opposing objects
now i want to talk about that serpent and really focus um firmly on what the 01:18:05 self illusion is this will be the last part of this little section that self is supposed to be something that stands outside of the world not something embedded in the world 01:18:17 it's the wittgenstein um the austrian philosopher of the first half of the 20th century um expressed this beautifully in his book the trektatus he said that the self stands to the world 01:18:30 like the eye stands to the visual field we don't see the eye but the fact that we have a visual field lets us know that there is an eye behind it but not in the field 01:18:42 the self he said is just like that we see a world we experience a world we act on a world and that tells us that there has to be a subject that stands outside of that world and experiences it just like the 01:18:56 eye stands outside of the visual field that's one of the worst things about the self-illusion is the illusion that we're not even in the world that we're totally transcendent to it that's really weird right i mean when you realize that 01:19:09 that's what you believe in your gut um that is it's like the eye and the visual field um that the self is continuous it doesn't stop as hume said talking about descartes 01:19:22 that it's always present to us that it's conscious it's the thing that's aware of everything else that it's free from causation that we can act freely on our motives without being caused so when you go to the 01:19:34 notary public to have a document notarized and she asks you those beautiful questions is this your free act and deed and if you said no i'm being caused to 01:19:46 do this she wouldn't notarize it would you so you say yes this is my free act indeed and i always just have my fingers crossed behind my back i don't believe in free acts and deeds but 01:19:59 we do take have this ideology about ourselves that we're with our free actions aren't cause we just do them as can't put it spontaneously that we are independent not 01:20:11 interdependent that when your mom tells you you've got to learn to stand on your own two feet that somehow that makes sense that ourselves can stand on our own two feet as independent objects 01:20:24 and mostly the self is what i am i am not my body my body is constantly changing my body was once young and fast now it's old and has a new knee um i'm 01:20:36 not my mind my mind was once sharp now it's dulled and beaten into submission by years of overwork but that i the jay who was once young is still here in this old man's body 01:20:49 so when we think about that self-illusion the self-illusion is partly bad because it's only a root illusion that leads to a whole cascade 01:21:01 of terrible illusions so now i want to really dump on the self-illusion by showing you just how dangerous it is
!- Wittgenstein : Self-illusion - Wittgenstein also elucidated the power of the self-illusion - self is interpreted as something that stands outside of the world, not embedded in it - In his work "Tractacus Logico-Philosophicus", Wittgenstein used the metaphor of the eye that stands apart from the visual field to compare to the self concept - We have the compelling illusion that we as subject, like the eye, transcend the world - We perceive that this "self" is without cause, we are independent, not INTERDEPENDENT
ranslated by zalas as part of al|together 2005, io[ChristmasEve] is a novel game made in the KiriKiri engine. The game received an update a year after the release of the translation patch which caused the patched game to crash immediately after starting, so my friend at the group Re*define has made a fix for it, making the game playable from start to finish. The fix consists of removing malfunctioning lines calling for an apparently nonexistent object called options2Menu. The XP3 archive was worked on with insani's xp3tools-20060708 available at http://insani.org/tools/. The fix has been tested on Windows XP and Windows 10.
Thanks to Re*Define and Kaisernet, the original 2005 English-language translation of io [Christmas Eve], a freeware Japanese visual novel written in KiriKiri, is playable in English. The 2005 patch ceased working due to the Japanese game receiving a minor update in 2006. Kaisernet notes that "[t]he fix has been tested on Windows XP and Windows 10." I personally tested it on Linux running the game with the patch on WINE and found that it works without issue.
Creating video tutorials has been hard when things are so in flux. We've been reluctant to invest time - and especially volunteer time - in producing videos while our hybrid content and delivery strategy is still changing and developing. The past two years have been a time of experimentation and iteration. We're still prototyping!
Have you thought about opening the project setting and the remixing to educators or even kids? That could create additional momentum.
A few related resources you might want to check out for inspiration: Science Buddies, Seesaw, Exploratorium
Tanabe Meito is a psychology student in the “World of Light”, a completely ordered world were people don’t have a shadow. He’s not entirely satisfied, though; and when he meets a girl with a shadow called Shimon he ends going with her to the “World of Shadow”, a rural village where the people are shadows, and Shimon is the only one with both body and shadow. Right after that they meet two other persons with body and shadow: a girl with no memories, who they finally name Sou, and a woman also with no memories but who recalls being called Riri. Then they start living together in Shimon’s house, and have mostly slice-of-life happenings while they investigate a mysterious voice Meito heard just before going to the World of Shadow, and Meito gets used to the shadow people. And while that’s happening you have scenes of a boy who lives with his mother, who eats him, until he discover eating is love, eats her, and goes out into the outer world. Then things get real trippy, and nothing else makes any sense, until the very end, or ever.
"And while that's happening you have scenes of a boy who lives with his mother, who eats him, until he discovers eating is love, eats her, and goes out into the outer world. **Then things get real trippy, and nothing else makes any sense, until the very end, or ever."
This is as apt a description of MYTH as one could write.
Rules formulated with openVALIDATION are thus at the same time a formal, machine-processable specification, but also a documentation that is easy for people to understand.
Posted byu/piloteris16 hours agoCreative output examples .t3_xdrb0k._2FCtq-QzlfuN-SwVMUZMM3 { --postTitle-VisitedLinkColor: #9b9b9b; --postTitleLink-VisitedLinkColor: #9b9b9b; --postBodyLink-VisitedLinkColor: #989898; } I am curious about examples, if any, of how an anti net can be useful for creative or artistic output, as opposed to more strictly intellectual articles, writing, etc. Does anyone here use an antinet as input for the “creative well” ? I’d love examples of the types of cards, etc
They may not necessarily specifically include Luhmann-esque linking, numbering, and indexing, but some broad interesting examples within the tradition include: Comedians: (see https://en.wikipedia.org/wiki/Zettelkasten for references/articles) - Phyllis Diller - Joan Rivers - Bob Hope - George Carlin
Musicians: - Eminem https://boffosocko.com/2021/08/10/55794555/ - Taylor Swift: https://hypothes.is/a/SdYxONsREeyuDQOG4K8D_Q
Dance: - Twyla Tharpe https://www.amazon.com/gp/product/B000SEOWBG/ (Chapter 6)
Art/Visual - Aby Warburg's Mnemosyne Atlas: https://warburg.sas.ac.uk/archive/archive-collections/verkn%C3%BCpfungszwang-exhibition/mnemosyne-materials
Creative writing (as opposed to academic): - Vladimir Nabokov https://www.openculture.com/2014/02/the-notecards-on-which-vladimir-nabokov-wrote-lolita.html - Jean Paul - https://www.tandfonline.com/doi/abs/10.1080/00168890.2018.1479240 - https://journals.co.za/doi/abs/10.10520/EJC34721 (German) - Michael Ende https://www.amazon.com/Michael-Endes-Zettelkasten-Skizzen-Notizen/dp/352271380X
the thing is about vision, same with the ear, you can only see a few at a time in detail, but you can be aware of 100 things at once. So one of the things we're really bad about is, because of our eyes, you can't get the visual point of view we want. Our eyes have a visual point of view of like 160 degrees. But what I've got here is about 25, and on a cellphone it's pathetic. So this is completely wrong. 100% wrong. Wrong in a really big way. If you look at the first description that Engelbart ever wrote about what he wanted, it was a display that was three feet on its side, built into a desk, because what is it that you design on? If anybody's ever looked at a drafting table, which they may not have for a long time, you need room to design, because there's all this bullshit that you do wrong, right?
!- insight for : user interface design - 3 feet field of view is critical - 160 degrees - VR and AR is able to meet this requirement
Mermaid allows even non-programmers to easily create detailed and diagrams through the Mermaid Live Editor.
https://www.jenniferackermanauthor.com/genius-ofbirds
Lynne Kelly mentioned that there might be some interesting research on birds and memory with respect to songlines-like activity.
I've noticed that u/khimtan has a more visual stye of note taking with respect to their cards, but is anyone else doing this sort of visualization-based type of note taking in the vein of sketchnotes or r/sketchnoting? I've read books by Mike Rohde and Emily Mills and tinkered around in the space, but haven't actively added it to my practice tacitly. For those who do, do you have any suggestions/tips? I suspect that even simple drollery-esque images on cards would help with the memory/recall aspects. This may go even further for those with more visual-based modes of thinking and memory.
For those interested in more, as well as some intro videos, here are some of my digital notes: https://hypothes.is/users/chrisaldrich?q=sketchnotes
https://www.reddit.com/r/antinet/comments/wc63sw/is_anyone_practicing_sketchnotes_like_patterns_in/
Some digital notes apps allow you to displayonly the images saved in your notes, which is a powerful way ofactivating the more intuitive, visual parts of your brain.
Visual cues one can make in their notes and user interfaces that help to focus or center on these can be useful reminders for what appears in particular notes, especially if visual search is a possibility.
Is this the reason that Gyuri Lajos very frequently cuts and pastes images into his Hypothes.is notes?
Which note taking applications leverage this sort of visual mnemonic device? Evernote did certainly, but other text heavy tools like Obsidian, Logseq, and Roam Research don't. Most feed readers do this well leveraging either featured photos, photos in posts, or photos in OGP.
"The idea is that over long periods of time, traces of memory for visual objects are being built up slowly in the neocortex," Clerkin said. "When a word is spoken at a specific moment and the memory trace is also reactivated close in time to the name, this mechanism allows the infants to make a connection rapidly." The researchers said their work also has significant implications for machine learning researchers who are designing and building artificial intelligence to recognize object categories. That work, which focuses on how names teach categories, requires massive amounts of training for machine learning systems to even approach human object recognition. The implication of the infant pathway in this study suggests a new approach to machine learning, in which training is structured more like the natural environment, and object categories are learned first without labels, after which they are linked to labels.
visual objects are encoded into memory over a long period of time until it becomes familiar. When a word is spoken when the memory trace associated with the visual object is reactivated, connection between word and visual object is made rapidly.
This is reminiscent of Rapid Serial Visual Presentation (RSVP) reading method which became popular for a while a few years back, got squashed by patent claims, and then has slowly been coming back as the method was reported in the early 1970s.
We are here to help you get your designs implemented on codes pixel perfectly
XYZ
To ease the process of icon designing for you, we have compiled some of the best icon design sets that are created by amazing designers across the globe.
Reduce review time to half
Loving this website anyways!
Any thoughts guys??
https://www.connectedpapers.com/
See also: - Research Rabbit - Open Knowledge Maps
I put some visual noise on the big screen if I’m not using it for work, usually an art film or a landscape documentary, muted.
Perhaps I should be creating some beautiful visual noise myself?
Another visual-mapping tool is Open Knowledge Maps, a service offered by a Vienna-based not-for-profit organization of the same name. It was founded in 2015 by Peter Kraker, a former scholarly-communication researcher at Graz University of Technology in Austria.
https://openknowledgemaps.org/
Open Knowledge maps is a visual literature search tool that is based on keywords rather than on a paper's title, author, or DOI. The service was founded in 2015 by Peter Kraker, a former scholarly communication researcher at Graz University of Technology.
visual design: paper look
I tried mapping out the different flow of information for the two different contexts:
What Iam alluding to here is well drawn out in Walter Benjamin’s reflectionin his Moscow Diary on how we ‘grasp’ a visual image. ‘One does notin any way enter into its space’, he writes. Rather, ‘It opens up to usin corners and angles in which we believe we can localise crucialexperiences of the past; there is something inexplicably familiarabout these spots’ (Benjamin, 1985: 42).
systematize
shuffling cards:
is like how this combines/interleaves structure migrations and data migrations together
Evaluations of the platform show that users who follow the avatar inmaking a gesture achieve more lasting learning than those who simply hear theword. Gesturing students also learn more than those who observe the gesture butdon’t enact it themselves.
Manuela Macedonia's research indicates that online learners who enact specific gestures as they learn words learn better and have longer retention versus simply hearing words. Students who mimic these gestures also learn better than those who only see the gestures and don't use them themselves.
How might this sort of teacher/avatar gesturing be integrated into online methods? How would students be encouraged to follow along?
Could these be integrated into different background settings as well to take advantage of visual memory?
Anecdotally, I remember some Welsh phrases from having watched Aran Jones interact with his cat outside on video or his lip syncing in the empty spaces requiring student responses. Watching the teachers lips while learning can be highly helpful as well.
Kerry Ann Dickson, an associate professor of anatomy and cell biology atVictoria University in Australia, makes use of all three of these hooks when sheteaches. Instead of memorizing dry lists of body parts and systems, her studentspractice pretending to cry (the gesture that corresponds to the lacrimal gland/tearproduction), placing their hands behind their ears (cochlea/hearing), and swayingtheir bodies (vestibular system/balance). They feign the act of chewing(mandibular muscles/mastication), as well as spitting (salivary glands/salivaproduction). They act as if they were inserting a contact lens, as if they werepicking their nose, and as if they were engaging in “tongue-kissing” (motionsthat represent the mucous membranes of the eye, nose, and mouth, respectively).Dickson reports that students’ test scores in anatomy are 42 percent higher whenthey are taught with gestures than when taught the terms on their own.
Example of the use of visual, auditory, and proprioceptive methods used in the pedagogy of anatomy.
proprioceptive cue may be the mostpowerful of the three: research shows that making gestures enhances our abilityto think even when our gesturing hands are hidden from our view.
Annie Murphy Paul indicates that proprioceptive associations may be more powerful than auditory or visual ones as she notes that "research shows that making gestures enhances our ability to think even when our gesturing hands are hidden from our view."
This is something that could be researched and analyzed.
My personal experience is that visual >> auditory >> smell >> proprioception. Smell with respect to memory is incredibly difficult to exercise as are auditory method. Visual and proprioceptive methods are easier to actively practice though.
In a study carried out by Susan Goldin-Meadow and colleagues at theUniversity of Chicago, a group of adults was recruited to watch video recordingsof children solving conservation problems, like the water-pouring task weencountered earlier. They were then offered some basic information aboutgesture: that gestures often convey important information not found in speech,and that they could attend not only to what people say with their words but alsoto what they “say” with their hands. It was suggested that they could payparticular attention to the shape of a hand gesture, to the motion of a handgesture, and to the placement of a hand gesture. After receiving these simpleinstructions, study subjects watched the videos once more. Before the briefgesture training, the observing adults identified only around 30 to 40 percent ofinstances when children displayed emerging knowledge in their gestures; afterreceiving the training, their hit rate shot up to about 70 percent.
Concentrating on the shape, motion, and placement of hand gestures dramatically help a learner to more concretely understand material and understanding in others.
Link this to the use of movement in dance with respect to memory in Lynne Kelly's work.
Research demonstrates that gesture can enhance our memory by reinforcing thespoken word with visual and motor cues.
Research shows that gesture can impact our memories by helping to associate speech with visual cues.
References for this?
Link this to the idea that our visual memories are much stronger than our verbal ones.
sing Obsidian for thematic analysis .t3_t3bjuw ._2FCtq-QzlfuN-SwVMUZMM3 { --postTitle-VisitedLinkColor: #9b9b9b; --postTitleLink-VisitedLinkColor: #9b9b9b; } I am planning to do this. Just wondering if others have been down this path or have suggestions.I am going to be doing a fair bit of thematic analysis of literature (journal articles) and interview transcripts. Essentially - read, find interesting themes, and discuss. I have used Nvivo to do this before. But Nvivo is (a) proprietary (b) slow as a tortoise on immodium
调出快捷键设置: Ctl + k Ctrl + s (这是代表联合一起的)
A High-Density EEG Study Showing Advantages of Drawing Over Typing for Learning
Shipping solved for your business Save time, money, and headaches with intelligent software and shipping services designed for small and midsize e-commerce companies.
More rational
as of February 2021, Europeana comprises 59%images and 38% text objects, but only 1% sound objects and 2% video objects.3 DPLA iscomposed of 25% images and 54% text, with only 0.3% sound objects, and 0.6% videoobjects.4Another reason, beyond cost, that audiovisual recordings are not widely accessible is the lack ofsufficiently granular metadata to support identification, discovery, and use, or to supportinformed rights determination and access control and permissions decisions on the part ofcollections staff and users.
Despite concerted efforts, there is a minimal amount of A/V material in Europeana and DPLA. This report details a pilot project to use a variety of machine-generated-metadata mechanisms to augment the human description efforts. Although this paragraph mentions rights determination, it isn't clear from the problem statement whether the machine-generated description includes anything that will help with rights. I would expect that unclear rights—especially for moving image content—would be a significant barrier to the open publication of A/V material.
What I'm interested in is doing this with visual artefacts as source material. What does visual pkm look like? Journaling, scrapbooking, collecting and the like. The most obvious tool is the sketchbook. How does a sketchbook work?
It builds on many of these traditions, but there is a rather sizeable movement in the physical world as well as lots online of sketchnotes which might fit the bill for you Roy.
The canonical book/textbook for the space seems to be Sketchnote Handbook, The: the illustrated guide to visual note taking by Mike Rohde.
For a solid overview of the idea in about 30 minutes, I found this to be a useful video: https://www.youtube.com/watch?v=evLCAYlx4Kw
It looks like they make their business model is based predominantly on hardware over software.
Moving mental contents out of our heads and onto the space of a sketch pad or whiteboard allows us to inspect it with our senses, a cognitive bonus that the psychologist Daniel Reisberg calls “the detachment gain.”
Moving ideas from our heads into the real world, whether written or potentially using other modalities, can provide a detachment gain, by which we're able to extend those ideas by drawing, sketching, or otherwise using them.
How might we use the idea of detachment gain to better effect in our pedagogy? I've heard anecdotal evidence of the benefit of modality shifts in many spaces including creating sketchnotes.
While some sketchnotes don't make sense to those who weren't present for the original talk, perhaps they're incredibly useful methods for those who are doing the modality shifts from hearing/seeing into writing/drawing.
Tailwind automatically removes all unused CSS when building for production
The BMJ on Twitter. (n.d.). Twitter. Retrieved 3 September 2021, from https://twitter.com/bmj_latest/status/1432056729743863810
Akhther, N. (2021). Internet Memes as Form of Cultural Discourse: A Rhetorical Analysis on Facebook. PsyArXiv. https://doi.org/10.31234/osf.io/sx6t7
Ortiz, E., & Serrano, M. Á. (2021). Multiscale opinion dynamics on real networks. ArXiv:2107.06656 [Physics]. http://arxiv.org/abs/2107.06656
What?
Mielicki, M., Fitzsimmons, C., Schiller, L., Scheibe, D., Taber, J. M., Sidney, P., Matthews, P. G., Waters, E. A., Coifman, K., & Thompson, C. A. (2021). Adults’ Health-Related Problem Solving Is Facilitated by Number Lines, But Not Risk Ladders and Icon Arrays. PsyArXiv. https://doi.org/10.31234/osf.io/h3stw
I’m going to represent tests as sequence diagrams (handily created via plantuml) rather than actually coding them out. For me the diagrams make it easier to talk about what the tests do without getting bogged down by how they do it.
I’m going to add the API Server as an actor to my first test sequence to give some granularity as to what I’m actually testing.
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>juanjosefernandez</span> in 📚-reading (<time class='dt-published'>06/04/2021 16:32:12</time>)</cite></small>
Wilson next exploresAd Herennium’stechnique of visual homophony, such as remembering a man named Wingfeelde by picturing“thewing of a birde, and a greene feelde to walke in.”
The use of [[visual homophony]] as a [[mnemonic techniques]].
Händel, M., Bedenlier, S., Kopp, B., Gläser-Zikuda, M., Kammerl, R., & Ziegler, A. (2021). Visual and Verbal Engagement of Higher Education Students in Videoconferencing. PsyArXiv. https://doi.org/10.31234/osf.io/my4ze
Would you rather use a friendly drag-and-drop interface rather than coding? Try Passport, the email builder based on MJML!
The players plot to get the cards to yellow on player G's turn so he can lay down some Double Draw cards...
Academy Games has always prided itself in the quality of its rules. Most of our rules are taught in stages, allowing you to start playing as soon as possible without needing to read everything. We are very careful about the order we teach rules and rely heavily on graphics and pictures to facilitate understanding. We also include a large number of detailed picture examples, often with 3D renders, that help you understand the context of the rules.
It’s a visual novel, there’s a dialogue box with a nameplate on to indicate who is talking, why the hell do we need the constant ‘she ordered’, ‘he says’, ‘he exclaims’ etc? The box already identifies the speaker. The art is supposed to convey the emotion, the authority or surprise etc. What we have here is a novel where the various parts that make it a visual novel don’t work in tandem with each other, which is the ultimate sin for a visual novel in my opinion. That could be salvaged by storytelling, and indeed, there’s an interesting, if basic sci-fi story here, but the method of telling it is far too amateur, breaking every rule in the rulebook of storytelling, including telling rather than showing. One to avoid.
Pinilla, A., Garcia, J., Raffe, W., Voigt-Antons, J.-N., & Möller, S. (2021). Visual representation of emotions in Virtual Reality. PsyArXiv. https://doi.org/10.31234/osf.io/9jguh
Design SHOGI pieces have been redesigned with new iconography to indicate the piece’s movement.
Write That PhD. (2020, October 31). Doing a systematic review? How to prepare, conduct & document a search + manage your results & screening tools https://t.co/xdAC35VmaK #phdchat #phdadvice #phdforum #phdlife #ecrchat #acwri https://t.co/sh62MypqOi [Tweet]. @WriteThatPhD. https://twitter.com/WriteThatPhD/status/1322467814733713408
To implement such an activity, we only need to rewire the second step’s failure output to a new terminus.
Visualized, our new composed structure would look as follows.
Version HEAD now
Tree Navigation
The .chain() method allows us to switch over to the left track if an error occurs. Note that the switches only go one way.
Back to what railway oriented programming really is. Below is a visual representation of what this looks like:
If you are a VISUAL LEARNER, start here.
The thought of an illustrated book will, no doubt, make the purists recoil in horror - that's their loss. Sometimes a couple of drawings are far more illuminating than pages full of discrete mathematics, and this is what we have here.
Great pricing plan names that illustrate the type of plan you’re about to choose – from simple “hammering” for quick storage to the full blown “crane” offering unlimited storage.
This idea is not new, there are reference books which teach the use of grid layout, I haven't seen a single book that doesn't show a grid overlay as part of the process.
a designer / developer / designoper is able to create a grid overlay which would act as design reference.
Generally speaking, one will use smaller or less prominent buttons style for this.
The most dangerous kind of assumption is the one we don’t know we have. In Rumsfeldian, that’s an “Unknown unknown.”
5 Step Guide to Checking Ventilation Rates in Classrooms. (n.d.). Schools For Health. Retrieved September 9, 2020, from https://schools.forhealth.org/ventilation-guide/
Resume 5 Tips for Designers
he is using Illustrator, which is a good sign, lmao.
How to Design Your Resume
Kick Resume Examples
36 Beautiful Resume Ideas That Work
When grouping items into close proximity, you typically need to makesome changes, such as in the size or weight or placement of text or graphics.Body copy (the main bulk of reading text) does not have to be 12 point!
noteworthy
Items relating to each other should be grouped close together. Whenseveral items are in close proximity to each other, they become one visualunit rather than several separate units.
On proximity
Every element shouldhave some visual connection with another element on the page. This createsa clean and sophisticated look.
On alignment
Repeat visual elements of the design throughout the piece. You canrepeat colors, shapes, textures, spatial relationships, line thicknesses, fonts,sizes, graphic concepts, etc. This develops the organization and strengthensthe unity.
On repetition
Contrast is often the mostimportant visual attraction on a page—it’s what makes a reader look at thepage in the first place. It also clarifies the communication.
on contrast
ypefaces designed specifically for screen readinglike Verdana, Tahoma, Georgia, or Azuro.
screen reading typefaces
Strategies for readable text
Readable text strats
Examples of beautiful color combinations
Resources
Mismatching Fonts
2-3 Fonts MAX.
Another common mistake is to attempt to fit too many words into one line of text. For readability purposes, 50 to 60 characters per line is the ideal length.
ideal length of a line.
GitLab CI/CD
We are not testing styles specifically at this time
The above diagram shows which Linking Open Data datasets are connected, as of August 2014.
Vertical navigation needs to scroll and “stick” to the screen so that users don’t lose it. Often vertical navigation works well on a single page design
With wider screens, the scroll is higher and some navigation elements might get “lost.”
One thing is certain when it comes to navigation trends, users and designers seem to be fed up with completely hidden styles and demand options that work in similar formats on desktops and mobile devices. This might be one of the reasons a vertical pattern is trending.
Responsive design almost forced designers to think about alternative navigation patterns to make getting around on small screens easier. And the hamburger menu icon was born.
The common theme is that many hamburger icons open into vertical sliding navigation.
One more word of advice when thinking about vertical navigation: Don’t be tempted to cram it too full of elements just to fill up the depth of a standard-resolution screen. White space is totally acceptable – and even highly recommended – as a design tool in this format.
Non-traditional navigation styles can be a fun way to break up some of the same old design patterns.
See the really creative/fun example image above.