Bill Atkinson had an idea about the freedom to associate knowledge not by what comes next on the list but by the links that are associated with it. This means that information can be organized in a non-linear fashion, allowing for connections to be made between seemingly unrelated ideas. By expanding on this idea, we can create new and innovative ways of storing and accessing information, potentially leading to breakthroughs in fields such as artificial intelligence and data analysis.
1,341 Matching Annotations
- Oct 2023
-
-
- Sep 2023
-
Local file Local file
-
Travailler dans un espritde partenariatL’information des familles est un élément trèsfavorable à l’apaisement du climat scolaire
-
-
en.wikipedia.org en.wikipedia.org
-
These establishments broke down social barriers and allowed for socialization and information exchange.[10]
as place of information exchange (breaking down social barriers)
- also see point on coffee as aiding protestant work ethic (combining information exchange, and mentally stimulating effects of coffee)
-
-
bobdoto.computer bobdoto.computer
-
It's the kind of friction needed to help note takers who tend to drown in capture bloat—always onboarding, never offloading.
-
-
www.sciencedirect.com www.sciencedirect.com
-
Shalini Misra, Patrick Roberts, Matthew Rhodes. (2020). Information overload, stress, and emergency managerial thinking. International Journal of Disaster Risk Reduction Volume 51, December 2020, 101762 https://doi.org/10.1016/j.ijdrr.2020.101762
-
Above and beyond the effects of age, education, experience, and time spent on emergency managerial work, higher levels of perceived information overload from digital sources were significantly associated with higher levels of perceived stress
-
-
bryanmmathers.com bryanmmathers.com
-
This is an idea I created a few years ago using the Visual Thinkery process with Educators.Coop and their collaborators focusing on the world of work.
I love this image:
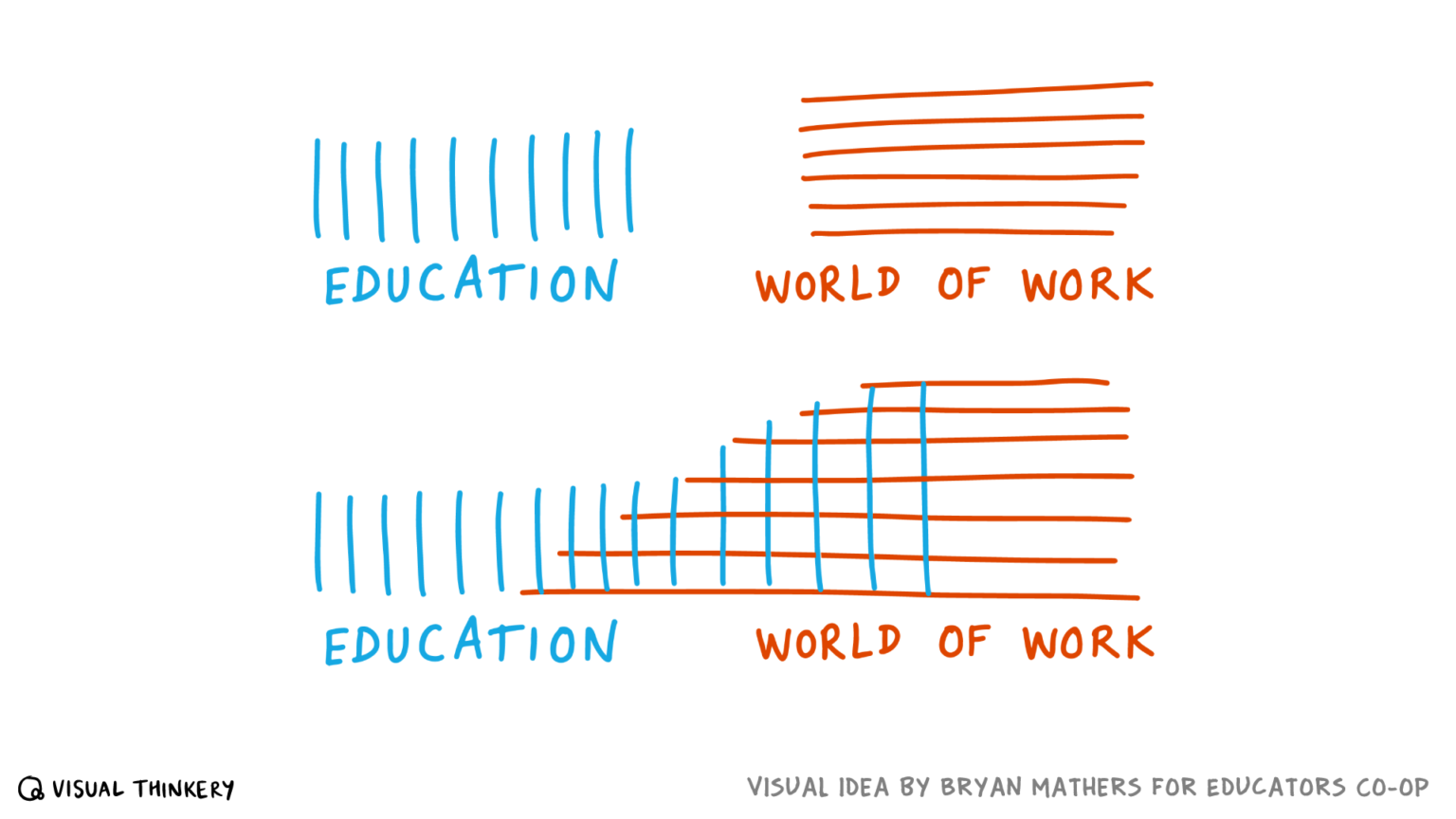
Via Bryan Mathers at https://bryanmmathers.com/education-work/
-
-
www.sciencedirect.com www.sciencedirect.com
-
However, what matters is the quality of information, not just the quantity. When we add information that does not change the dominance relations between products, choice quality is not degraded.
-
-
www.sciencedirect.com www.sciencedirect.com
-
Information overload positively related with seekers’ psychological ill-being.
-
Filtering rules, user awareness, and shared content may reduce information overload.
-
-
www.ncbi.nlm.nih.gov www.ncbi.nlm.nih.gov
-
Recent work has revealed several new and significant aspects of the dynamics of theory change. First, statistical information, information about the probabilistic contingencies between events, plays a particularly important role in theory-formation both in science and in childhood. In the last fifteen years we’ve discovered the power of early statistical learning.
The data of the past is congruent with the current psychological trends that face the education system of today. Developmentalists have charted how children construct and revise intuitive theories. In turn, a variety of theories have developed because of the greater use of statistical information that supports probabilistic contingencies that help to better inform us of causal models and their distinctive cognitive functions. These studies investigate the physical, psychological, and social domains. In the case of intuitive psychology, or "theory of mind," developmentalism has traced a progression from an early understanding of emotion and action to an understanding of intentions and simple aspects of perception, to an understanding of knowledge vs. ignorance, and finally to a representational and then an interpretive theory of mind.
The mechanisms by which life evolved—from chemical beginnings to cognizing human beings—are central to understanding the psychological basis of learning. We are the product of an evolutionary process and it is the mechanisms inherent in this process that offer the most probable explanations to how we think and learn.
Bada, & Olusegun, S. (2015). Constructivism Learning Theory : A Paradigm for Teaching and Learning.
Tags
Annotators
URL
-
-
delong.typepad.com delong.typepad.com
-
Since speed-reading has become a national fad, this new edition of How to Read a Book deals with the problem and proposes variable-speed-reading as the solution, the aim being to read better, always better, but sometimes slower, sometimes faster.
Framing of his book as a remedy to the speed reading fad in the 1970s...
What did those books at the time indicate that their purpose was? Were they aimed at helping people consume more (hopefully with greater comprehension?) while there was a continuing glut of information overload building up in society?
Which is better, more deep understanding of less or more surface understanding of more? How does combinatorial creativity effect the choice?
-
- Aug 2023
-
Local file Local file
-
Some may not realize it yet, but the shift in technology represented by ChatGPT is just another small evolution in the chain of predictive text with the realms of information theory and corpus linguistics.
Claude Shannon's work along with Warren Weaver's introduction in The Mathematical Theory of Communication (1948), shows some of the predictive structure of written communication. This is potentially better underlined for the non-mathematician in John R. Pierce's book An Introduction to Information Theory: Symbols, Signals and Noise (1961) in which discusses how one can do a basic analysis of written English to discover that "e" is the most prolific letter or to predict which letters are more likely to come after other letters. The mathematical structures have interesting consequences like the fact that crossword puzzles are only possible because of the repetitive nature of the English language or that one can use the editor's notation "TK" (usually meaning facts or date To Come) in writing their papers to make it easy to find missing information prior to publication because the statistical existence of the letter combination T followed by K is exceptionally rare and the only appearances of it in long documents are almost assuredly areas which need to be double checked for data or accuracy.
Cell phone manufacturers took advantage of the lower levels of this mathematical predictability to create T9 predictive text in early mobile phone technology. This functionality is still used in current cell phones to help speed up our texting abilities. The difference between then and now is that almost everyone takes the predictive magic for granted.
As anyone with "fat fingers" can attest, your phone doesn't always type out exactly what you mean which can result in autocorrect mistakes (see: DYAC (Damn You AutoCorrect)) of varying levels of frustration or hilarity. This means that when texting, one needs to carefully double check their work before sending their text or social media posts or risk sending their messages to Grand Master Flash instead of Grandma.
The evolution in technology effected by larger amounts of storage, faster processing speeds, and more text to study means that we've gone beyond the level of predicting a single word or two ahead of what you intend to text, but now we're predicting whole sentences and even paragraphs which make sense within a context. ChatGPT means that one can generate whole sections of text which will likely make some sense.
Sadly, as we know from our T9 experience, this massive jump in predictability doesn't mean that ChatGPT or other predictive artificial intelligence tools are "magically" correct! In fact, quite often they're wrong or will predict nonsense, a phenomenon known as AI hallucination. Just as with T9, we need to take even more time and effort to not only spell check the outputs from the machine, but now we may need to check for the appropriateness of style as well as factual substance!
The bigger near-term problem is one of human understanding and human communication. While the machine may appear to magically communicate (often on our behalf if we're publishing it's words under our names), is it relaying actual meaning? Is the other person reading these words understanding what was meant to have been communicated? Do the words create knowledge? Insight?
We need to recall that Claude Shannon specifically carved semantics and meaning out of the picture in the second paragraph of his seminal paper:
Frequently the messages have meaning; that is they refer to or are correlated according to some system with certain physical or conceptual entities. These semantic aspects of communication are irrelevant to the engineering problem.
So far ChatGPT seems to be accomplishing magic by solving a small part of an engineering problem by being able to explore the adjacent possible. It is far from solving the human semantic problem much less the un-adjacent possibilities (potentially representing wisdom or insight), and we need to take care to be aware of that portion of the unsolved problem. Generative AIs are also just choosing weighted probabilities and spitting out something which is prone to seem possible, but they're not optimizing for which of many potential probabilities is the "best" or the "correct" one. For that, we still need our humanity and faculties for decision making.
Shannon, Claude E. A Mathematical Theory of Communication. Bell System Technical Journal, 1948.
Shannon, Claude E., and Warren Weaver. The Mathematical Theory of Communication. University of Illinois Press, 1949.
Pierce, John Robinson. An Introduction to Information Theory: Symbols, Signals and Noise. Second, Revised. Dover Books on Mathematics. 1961. Reprint, Mineola, N.Y: Dover Publications, Inc., 1980. https://www.amazon.com/Introduction-Information-Theory-Symbols-Mathematics/dp/0486240614.
Shannon, Claude Elwood. “The Bandwagon.” IEEE Transactions on Information Theory 2, no. 1 (March 1956): 3. https://doi.org/10.1109/TIT.1956.1056774.
We may also need to explore The Bandwagon, an early effect which Shannon noticed and commented upon. Everyone seems to be piling on the AI bandwagon right now...
-
-
meta.stackoverflow.com meta.stackoverflow.com
-
Overall, because the average rate of getting correct answers from ChatGPT and other generative AI technologies is too low, the posting of answers created by ChatGPT and other generative AI technologies is substantially harmful to the site and to users who are asking questions and looking for correct answers.
-
The primary problem is that while the answers which ChatGPT and other generative AI technologies produce have a high rate of being incorrect, they typically look like the answers might be good and the answers are very easy to produce.
-
-
start.digitalefitheid.nl start.digitalefitheid.nl
-
Nieuws kwam tot ons via een combinatie van kranten, bladen en radio of tv. Papieren media hadden het te doen met beperkte fysieke ruimte omdat papier geld kost, ook iets weegt en meer papier is ook nog duurder te vervoeren. Bij radio- en tv-zenders was het niet anders door beperkte tijd, een beperkt aantal kanalen en zeer hoge kosten. Dus een redactie maakte een beperkte selectie voor ons: een filter.Ook informatie-uitwisseling onderling ging per post en ook dat was bewerkelijk en bepaald niet gratis. Iets dergelijks gold eigenlijk voor alle vormen van informatie die tot ons kwam.En sinds een tijdje worden die filters minder belangrijk of ze verdwijnen compleet. Het zelf massaal verspreiden van (nep-)nieuws en andere informatie kost niets meer, dus iedereen kan iedereen onbeperkt bekogelen met extreme hoeveelheden informatie.In veel gevallen is er geen enkel filter meer op die toestroom van informatie. En al is dat filter er wel, dan moet je dat zelf maar zien in te stellen. Of, nog erger, het filter is er, maar functioneert niet in jouw belang en is daarmee onbetrouwbaar
info filters niet meer ingebouwd in het systeem; dat moeten we nu zelf zien te creëeren, of deze worden anders voor ons gemaakt (zie bijvoorbeeld algoritmes, enzo)
-
-
www.google.com www.google.com
-
"in his youth he was full of vim and vigor"
Do calcified words eventually cease to have any definition over time? That is they have a stand alone definition, then a definition within their calcified phrase, then they cease to have any stand alone definition at all though they continue existence only in those calcified phrases.
-
-
-
That's a fine plan you've outlined, covering all the key bases - prioritizing important tasks, breaking them into doable steps, budgeting your time wisely, and minimizing distractions. But you know what I think you're missing? A touch of pizzazz! Of showmanship! You need to approach each day like it's opening night on the big stage. The curtain rises, the lights come on, and it's time for you to perform.
So tomorrow when you wake up, I want you to greet the day with enthusiasm. Belt out a tune as you get ready. Approach your task list with gusto and determination. Give every activity your all, as if the audience is on their feet cheering. Stay focused like a true professional, taking breaks only when needed. And when the day comes to a close, bask in the glow of a show well done.
You have such potential, my friend, such skills and passion waiting to be unlocked. With discipline and delight, you can achieve anything. This is your time in the spotlight - now go out there and steal the scene! The world is your stage, so perform like the star you are. I'll be cheering you on from the front row. Knock 'em dead tomorrow, kid. You got this!
Thank you for the inspiring words, Charlie! I'll do my best to approach each day with enthusiasm and discipline.
Acknowledge: On July 31th, I will put these productivity (how to deal with information overlord) tips into action:
-
For work tasks I can control, I'll choose what interests me and builds my strengths.
-
My daily priority list will have 3-5 important tasks max. Otherwise, I may be under-investing in my interests or have too much free time. When setting priorities, I'll answer:
- Why it matters
- How to break it into steps
-
What info I need to decide
-
I'll estimate time needed for each task. The top priority sets the time cap. Others get less time. If tasks exceed my work hours, I'll revise or streamline.
-
For research tasks, I'll define the topic and timeline upfront. I'll gather only the info I need, not get distracted.
-
I'll group related tasks and schedule time blocks without interruptions.
Let's ask my future self tomorrow and see what will happen!
31/7 reported: 23 achieved, 4 ongoing, 5 postponed becauses of my low productivity. 1 should be considered beforehand in a monthly plan
-
-
- Jul 2023
-
Local file Local file
-
educators and stakeholders must be equipped with the necessary skillsand knowledge
information literacy
-
-
force11.org force11.org
-
Scholars have experienced information overload for more than a century [Vickery, 1999] and the problem is just getting worse. Online access provides much better knowledge discovery and aggregation tools, but these tools struggle with the fragmentation of research communication caused by the rapid proliferation of increasingly specialized and overlapping journals, some with decreasing quality of reviewing [Schultz, 2011].
-
-
www.forbes.com www.forbes.com
-
he had used ChatGPT to conduct legal research for the court filing that referenced the cases and that the artificial intelligence tool assured him the cases were real.
-
-
-
When Hermann Hesse referredto the present as "the Age of the Digest," he did not intendto say anything complimentary.
-
Great books alone will not do the trick; for the peoplemust have the information on which to base a judgment aswell as the ability to make one.
-
-
erinflotodesigns.com erinflotodesigns.com
-
Erin Floto has a metal stencil for a chronodex circular design for use in bullet journals. It's a form of circular calendar with the inner circle containing space for daily, bi-weekly, weekly, monthly and longer time horizons with succeeding rings of the circle containing space for data related to the inner categories. Some of the exterior rings also include numbered squares representing days of the month or week on which a task should be done or for which a habit on an interior part of the circle might be tracked.

The chronodex, a portmanteau of chrono (time) and index, idea is fairly simple, but can be quite complex. For actual use, one may need to be able to spin the visualization around to read and understand it.
Other stencils with habit trackers, etc: https://erinflotodesigns.com/collections/metal-stencils
-
- Jun 2023
-
twitter.com twitter.com
-
The question is Do you know what your superpower is? The combination of skills and abilities that's unique to you
-
-
www.youtube.com www.youtube.com
-
Basically, you must be unique. You can't compete when you learn exactly the same as everyone else. The education system sets up to fail and makes you a modern slave.
-
-
link.springer.com link.springer.com
-
information ecology research mainly focuses on information ecosystems, information ecology in e-commerce, and information ecology in a network.
-
information ecology is an emerging field with vigorous development in recent years, and information ecology research is a multi-disciplinary subject.
-
-
www.sciencedirect.com www.sciencedirect.com
-
A New Contribution to the Information Ecology of Humanitarian Work
-
-
www.sciencedirect.com www.sciencedirect.com
-
Information ecology as a mind tool for repurposing of educational social networks
-
-
www.sciencedirect.com www.sciencedirect.com
-
goal perspective, information ecologies have been designed to increase engagement with collaborative tasks (Price & Pontual-Falcão, 2011), enhance whole classroom learning (Rick, 2009), boost creative problem solving (Hilliges et al., 2007), support product design conversations (Bardill, Griffiths, Jones, & Fields, 2010), and coordinate complex collaborative working (Huang, Mynatt, & Trimble, 2006).
Two different perspectives on information ecology: user and goal
-
Information ecology was defined by Nardi and O’Day (1999) to be “a system of people, practices, values, and technologies in a particular local environment” (p. 49).
-
the design and integration of new technologies in learning activities cannot be studied independently of the classroom environment, less attention has been paid in learning environments
Designing new learning technology is not always the best solution without paying attention to its learning environment.
-
indicate that distributed cognition considers a collaborative activity taking place across individuals, artefacts and internal or external representations, as one cognitive system.
-
How the information ecology allows the design group to coordinate their actions? How awareness is distributed within the group when working with multiple technologies? How each one of the technologies in the ecology supports coordination and collaboration of learning activities?
-
an “information ecology” is a local environment enriched with multiple heterogeneous technologies, such as personal computers, handheld devices, interactive screens, which are interlinked as a unified system.
-
cognition cannot be tamed within the boundaries of an individual, but researchers should expand the unit of analysis to include the surrounding environment.
-
-
www.lrb.co.uk www.lrb.co.uk
-
Roth asks ‘how might our own reading of early modern sources change if we had access to the oral spheres within which they were embedded and which framed their reception?’
The level of orality in societies can radically change our perceptions of their histories, though quite often this material is missing in our evaluations.
-
- May 2023
-
random-blather.com random-blather.com
-
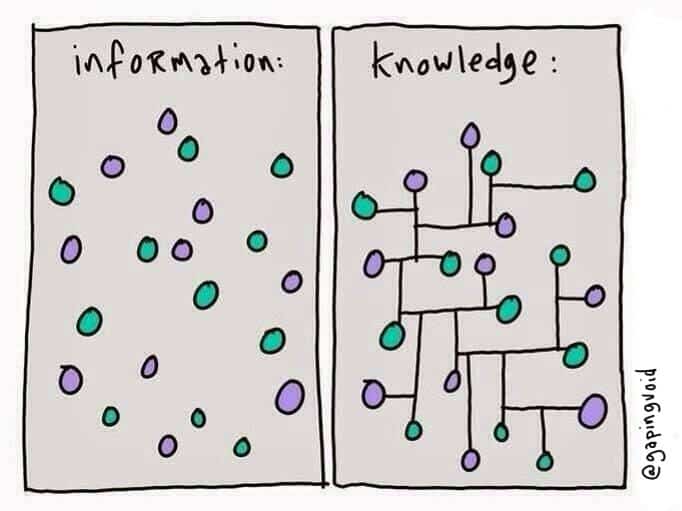
https://random-blather.com/2014/04/28/information-isnt-power/
 Illustration by David Somerville based on the original by Hugh McLeod.
Illustration by David Somerville based on the original by Hugh McLeod.Link to: https://hypothes.is/a/ysRBGgACEe6UNPvIvmWBkQ
This diagram is roughly a cartoon of the zettelkasten process, especially if the panels are labeled: reading, excerpting/synopsis, linking, serendipity, writing.
-
-
www.gapingvoid.com www.gapingvoid.com
-
www.waubonsee.edu www.waubonsee.edu
-
Payment Information Centrality Revision Project "Ways to fund your education" (or similar) instead of "Minimize Financial Barriers". "Verified Sources" as a phrase is problematic for users. Desire is to provide assurance to users that there are individualized options yet still have those options located in a more streamlined, centrally located way.
These are the other pages that have similar content: https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition
https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition/payments-verified-sources
https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition/making-payments
https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition/payment-plans
https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition/tuition-refunds
https://www.waubonsee.edu/admissions/costs-and-payments/paying-tuition/tax-credits-education
-
-
analogoffice.net analogoffice.net
-
https://analogoffice.net/2023/05/03/too-much-information.html
Your title made me think it was about a different, but related book...
I too bought Hess' book at Kimberly's recommendation, but I'm still plowing through the end of Ann M. Blair's Too Much to Know: Managing Scholarly Information before the Modern Age. Yale University Press, 2010. https://yalebooks.yale.edu/book/9780300165395/too-much-know. You might find it interesting, but hopefully not overwhelming.
-
-
www.defenseurdesdroits.fr www.defenseurdesdroits.fr
-
Diffuser le plus largement possible l’observation générale n°14 du Comité des droits del’enfant visant à une application dynamique du principe du respect de l’intérêt supérieur del’enfant dans les décisions qui le concernent.
-
Prévoir que le mineur de 10 ans et plus soit personnellement informé par le greffe de son droitd’être entendu en justice.
-
-
stackoverflow.com stackoverflow.com
-
Entropy is not a property of the string you got, but of the strings you could have obtained instead. In other words, it qualifies the process by which the string was generated.
-
-
www.napkin.one www.napkin.one
-
https://www.napkin.one/
Yet another collection app that belies the work of taking, making, and connecting notes.
Looks pretty and makes a promise, but how does it actually deliver? How much work and curation is involved? What are the outputs at the other end?
-
- Apr 2023
-
www.dalekeiger.net www.dalekeiger.net
-
Roy Peter Clark, writing scholar and coach at The Poynter Institute, says, “Reports give readers information. Stories give readers experience.” I would add: An article is generic; a story is unique.
-
-
en.wikipedia.org en.wikipedia.org
-
the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes
-
-
-
themindfulteacher.medium.com themindfulteacher.medium.com
-
The Medici effect is a concept that describes the way in which innovation arises from the intersection of different disciplines and ideas. The term was coined by author Frans Johansson in his book “The Medici Effect: What Elephants and Epidemics Can Teach Us About Innovation”. The Medici family of Renaissance-era Florence is used as an example of the way in which the intersection of different disciplines, such as art, science, and finance, led to a period of great innovation and cultural advancement. Similarly, Johansson argues that innovation today is more likely to occur when people from different backgrounds and disciplines come together to share ideas and collaborate. The Medici effect highlights the importance of diversity, curiosity, and creativity in driving innovation and problem-solving.
Frans Johansson's "Medici effect" which describes innovation arriving from an admixture of diversity of people and their ideas sounds like a human-based mode of combinatorial creativity similar to that seen in the commonplace book/zettelkasten traditions. Instead of the communication occurring between a person and their notes or written work, the communication occurs between people.
How is the information between these people crystalized? Some may be written, some may be in prototypes and final physical products, while some may simply be stored in the people themselves for sharing and re-sharing over time.
-
-
zettelkasten.de zettelkasten.de
-
It is an obligatory condition for communication that both partners can surprise each other. Only in that way can information be created in the respective other. Information is an event that happens inside the system. Information is created when a message, an entry [of a note], is compared with other possibilities. Therefore, information is only created in systems that possess a comparison schema (even when this schema is merely: “this or something else”).
-
-
ageoftransformation.org ageoftransformation.org
-
due to the critical role of information in phase-transitions, the primary pathway to global systemic transformation will depend on our ability to process information on our current predicament coherently in order to translate this into adaptive action.
Key observation - due to the critical role of information in phase-transitions, - the primary pathway to global systemic transformation - will depend on our ability to process information on our current predicament coherently - in order to translate this into adaptive action.
-
- Mar 2023
-
Local file Local file
-
The ability to intentionally and strategically allocateour attention is a competitive advantage in a distracted world. Wehave to jealously guard it like a valuable treasure.
It would seem that the word treasure here is being used to modify one's attention. Historically in books about "knowledge work" or commonplacing, the word was used with respect to one's storehouse of knowledge itself and not one's attention. Some of the effect is the result of the break in historical tradition being passed down from one generation to another. It's also an indication that the shift in value has moved not from what one knows or has, but that the attention itself is more valued now, even in a book about excerpting, thinking, and keeping knowledge!
Oh how far we have fallen!
It's also an indication of the extremes of information overload we're facing that the treasure is attention and not the small tidbits of knowledge and understanding we're able to glean from the massive volumes we face on a daily basis.
-
-
web.archive.org web.archive.org
-
In looking at the uses of and similarities between Wb and TLL, I can't help but think that these two zettelkasten represented the state of the art for Large Language Models and some of the ideas behind ChatGPT
-
Die Auswertung solcher Materialmengen erwies sich als prekär, und im Falle der häufigsten Wörter, z.B. mancher Präpositionen (allein das Wort m "in" ist über 60.000 Mal belegt) oder elementarer Verben mußte man vor den Schwierigkeiten kapitulieren und das Material aussondern.
The preposition m "in" appears more than 60,000 times in the corpus, a fact which becomes a bit overwhelming to analyze.
-
-
www.theatlantic.com www.theatlantic.com
-
We are drowning in an ocean of content, desperate for form’s life raft.
example of information overload
We're already drowning in information overload, but ChatGPT wants to increase the tsunami! Where is the tool that compresses and concatenates?
-
-
brill.com brill.com
-
“increased knowledge tends to strengthen our position on climate change, regardless of what that position is” (Hoffman 2015:5)
- Quote
- increased knowledge tends to strengthen our position on climate change, regardless of what that position is
- (Hoffman 2015:5).
- Quote
-
Abstract
// abstract - summary - Rationalist approaches to environmental problems such as climate change - apply an information deficit model, - assuming that if people understand what needs to be done they will act rationally. - However, applying a knowledge deficit hypothesis often fails to recognize unconscious motivations revealed by: - social psychology, - cognitive science, - behavioral economics.
- Applying ecosystems science, data collection, economic incentives, and public education are necessary for solving problems such as climate change, but they are not sufficient.
- Climate change discourse makes us aware of our mortality
- This prompts consumerism as a social psychological defensive strategy,
- which is counterproductive to pro-environmental behavior.
- Studies in terror management theory, applied to the study of ritual and ecological conscience formation,
- suggest that ritual expressions of giving thanks can have significant social psychological effects in relation to overconsumption driving climate change.
- Primary data gathering informing this work included participant observation and interviews with contemporary Heathens in Canada from 2018–2019.
-
-
www.dol.wa.gov www.dol.wa.gov
-
Does the EDL/EID card transmit my personal information? No. The RFID tag embedded in your card doesn't contain any personal identifying information, just a unique reference number.
Can this unique reference number be used to identify me (assuming they've already identified me another way and associated this number with me)? Yes!!
So this answer is a bit incomplete/misleading...
-
-
zettelkasten.de zettelkasten.de
-
a Structure Note can make use of a TOC form, a normal table, a mind map, a flow diagram, a straight list, or even a picture.
Structure notes can take a variety of forms including lists, diagrams, mind maps, tables, and tables of contents.
-
-
-
Blair, Ann M. Too Much to Know: Managing Scholarly Information before the Modern Age. Yale University Press, 2010, https://yalebooks.yale.edu/book/9780300165395/too-much-know.
ISBN: 978-0-300-11251-1 (cloth) Library of Congress Control Number: 2010024663
annotation target: url: urn:x-pdf:1a01bfa446187f0bb8bd5db6cc6ad53e
-
-
www.levenger.com www.levenger.com
-
https://www.levenger.com/products/nantucket-bamboo-compact-bleacher?variant=42489708773525
This sort of reminds me about the way Rick Nicita kept his to do list on index cards spread out all over his desk.
Perhaps he might have benefitted from an index card bleacher?
-
- Feb 2023
-
platform.openai.com platform.openai.com
-
media literacy, ability to verify information from different sources, and other skills
I wish information literacy had been named here! In libraries, many of us are wondering if this may prompt a shift at institutions where library-led instruction is primarily focused on searching for various documents to a greater emphasis on critical evaluation skills.
-
-
www.reddit.com www.reddit.com
-
I finished processing the 22 page chapter. It took me about 10 hours total to read, take notes, polish notes, and connect them to 39 permanent notes (6 new notes and 33 existing notes). Bear in mind, this is an extremely important reference for me, so it's by far one of the most-linked literature notes in my vault.
-
-
blay.se blay.se
-
Vismann, Cornelia. Files: Law and Media Technology. Stanford University Press, 2008.
This looks intriguing...
autocomplete tells me I've seen her before....
update: it's a Rowan Wilken reference! https://hypothes.is/a/xwRnzr-REeyvvDd7YBbLVA
-
-
forum.zettelkasten.de forum.zettelkasten.de
-
Remember that life in a Zettelkasten is supposed to be fun. It is a joyful experience to work with it when it works back with you. Life in Zettelkasten is more like dance than a factory.
I've always disliked the idea of "work" involved in "making" notes and "processing" them. Framing zettelkasten and knowledge creation in terms of capitalism is a painful mistake.
the quote is from https://blay.se/2015-06-21-living-with-a-zettelkasten.html
-
-
Local file Local file
-
Deutsch’s index was created out of an almost algorith-mic processing of historical sources in the pursuit of a totalized and perfect history of theJews; it presented, on one hand, the individualized facts, but together also constitutedwhat we might term a ‘history without presentation’, which merely held the ‘facts’themselves without any attempt to synthesize them (cf. Saxer, 2014: 225-32).
Not sure that I agree with the framing of "algorithmic processing" here as it was done manually by a person pulling out facts. But it does bring out the idea of where collecting ends and synthesis of a broader thesis out of one's collection begins. Where does historical method end? What was the purpose of the collection? Teaching, writing, learning, all, none?
-
-
www.thedrum.com www.thedrum.com
-
The results told us Felix’s demographic really wanted to shop for climate-friendly food brands, but found the sustainability information too confusing and – perhaps as a result – believed sustainable grocery shopping to be too expensive.Our strategy was clear: Give shoppers better information on the climate impact of Felix products and, in the process, demonstrate how easy it is to make climate-friendly choices when products are clearly labelled. We called it The Climate Store (Klimatbutiken) – the world’s first grocery shop in which the ‘price’ of food would be based on its carbon footprint.
- Climate Supermarket
- Climate store
- Survey showed consumers were confused by sustainability information
- consumers were left with the belief that shopping sustainably was too expensive
- One answer to simplify the complexity that was confusing people was uniform labeling of grocery products with their CO2e and a hard limit (18.9Kg CO2e) that consumer must stay under each week to meet Paris agreement
-
-
localhost:8080 localhost:8080
-
but too much of an overview.
overview articles
Tags
Annotators
URL
-
-
Local file Local file
-
Today’s students carry access to boundlessinformation that Eco’s students could not have begun tofathom, but Eco’s students owned every word they carried.
This is a key difference in knowledge mastery...
-
he research skills that Eco teaches areperhaps even more relevant today. Eco’s system demandscritical thinking, resourcefulness, creativity, attention todetail, and academic pride and humility; these are preciselythe skills that aid students overwhelmed by the ever-grow-ing demands made on their time and resources, and confusedby the seemingly endless torrents of information availableto them.
In addition to "critical thinking, resourcefulness, creativity, attention to detail, and academic pride and humility", the ability to use a note card-based research system like Umberto Eco's is the key to overcoming information overload.
-
-
www.newyorker.com www.newyorker.com
-
Consider Eco’s caution against “the alibi of photocopies”: “A student makes hundreds of pages of photocopies and takes them home, and the manual labor he exercises in doing so gives him the impression that he possesses the work. Owning the photocopies exempts the student from actually reading them. This sort of vertigo of accumulation, a neocapitalism of information, happens to many.” Many of us suffer from an accelerated version of this nowadays, as we effortlessly bookmark links or save articles to Instapaper, satisfied with our aspiration to hoard all this new information, unsure if we will ever get around to actually dealing with it.
neocapitalism of information!!
Is information overload compounded by our information hoarding tendencies?
-
-
wordcraft-writers-workshop.appspot.com wordcraft-writers-workshop.appspot.com
-
The application is powered by LaMDA, one of the latest generation of large language models. At its core, LaMDA is a simple machine — it's trained to predict the most likely next word given a textual prompt. But because the model is so large and has been trained on a massive amount of text, it's able to learn higher-level concepts.
Is LaMDA really able to "learn higher-level concepts" or is it just a large, straight-forward information theoretic-based prediction engine?
-
-
docdrop.org docdrop.org
-
Categories mean determination of internal structure less flexibility, especially “in the long run“ of knowledgemanagement and storage
The fact that Luhmann changed the structure of his zettelkasten with respect to the longer history of note taking and note accumulation allowed him several useful affordances.
In older commonplacing and slip box methods, one would often store their notes by topic category or perhaps by project. This mean that after collection one had to do additional work of laying them out into some sort of outline to create arguments and then write them out for publication. This also meant that one was faced with the problem of multiple storage or copying out notes multiple times to file under various different subject headings.
Luhmann overcame both of these problems by eliminating categories and placing ideas closest to their most relevant neighbor and numbering them in a branching fashion. Doing this front loads some of the thinking and outlining work which would often be done later, though it's likely easier to do when one has the fullest context of a note after they've made it when it is still freshest in their mind. It also means that each note is linked to at least one other note in the system. This helps notes from being lost and allows a simpler indexing structure whereby one only needs to use a few index entries to get close to the neighborhood of an idea as most other related ideas are likely to be nearby within a handful or more of index cards.
Going from index to branches on the tree is relatively easy and also serves the function of reminding one of interesting prior reading and ideas as one either searches for specific notes or searches for placing future notes.
When it comes to ultimately producing papers, one's notes already have a pre-arranged sort of outline which can then be more easily copied over for publication, though one can certainly still use other cross-links and further rearranging if one wishes.
Older methods focused on broad accretion of materials into subject ordered piles while Luhmann's practice not only aggregated them, but slowly and assuredly grew them into more orderly trains of thought as he collected.
Link to: The description in Technik des wissenschaftlichen Arbeitens (section 1.2 Die Kartei) at https://hypothes.is/a/-qiwyiNbEe2yPmPOIojH1g which heavily highlights all the downsides, though it doesn't frame them that way.
-
-
www.complexityexplorer.org www.complexityexplorer.org
-
Rhetoric of encomium
How do institutions form around notions of merit?
Me: what about blurbs as evidence of implied social networks? Who blurbs whom? How are these invitations sent/received and by whom?
diachronic: how blurbs evolve over time
Signals, can blurbs predict: - the field of the work - gender - other
Emergence or decrease of signals with respect to time
Imitation of styles and choices. - how does this happen? contagion - I'm reminded of George Mathew Dutcher admonition:
Imitation to be avoided. Avoid the mannerisms and personal peculiarities of method or style of well-known writers, such as Carlyle or Macaulay. (see: https://hypothes.is/a/ROR3VCDEEe2sZNOy4rwRgQ )
Systematic studies of related words within corpora. (this idea should have a clever name) word2vec, word correlations, information theory
How does praise work?
metaphors within blurbs (eg: light, scintillating, brilliant, new lens, etc.)
-
- Jan 2023
-
www.complexityexplorer.org www.complexityexplorer.org
-
https://www.youtube.com/watch?v=vZklLt80wqg
Looking at three broad ideas with examples of each to follow: - signals - patterns - pattern making, pattern breaking
Proceedings of the Old Bailey, 1674-1913
Jane Kent for witchcraft
250 years with ~200,000 trial transcripts
Can be viewed as: - storytelling, - history - information process of signals
All the best trials include the words "Covent Garden".
Example: 1163. Emma Smith and Corfe indictment for stealing.
19:45 Norbert Elias. The Civilizing Process. (book)
Prozhito: large-scale archive of Russian (and Soviet) diaries; 1900s - 2000s
How do people understand the act of diary-writing?
Diaries are:
Leo Tolstoy
a convenient way to evaluate the self
Franz Kafka
a means to see, with reassuring clarity [...] the changes which you constantly suffer.
Virginia Woolf'
a kindly blankfaced old confidante
Diary entries in five categories - spirit - routine - literary - material form (talking about the diary itself) - interpersonal (people sharing diaries)
Are there specific periods in which these emerge or how do they fluctuate? How would these change between and over cultures?
The pattern of talking about diaries in this study are relatively stable over the century.
pre-print available of DeDeo's work here
Pattern making, pattern breaking
Individuals, institutions, and innovation in the debates of the French Revolution
- transcripts of debates in the constituent assembly
the idea of revolution through tedium and boredom is fascinating.
speeches broken into combinations of patterns using topic modeling
(what would this look like on commonplace book and zettelkasten corpora?)
emergent patterns from one speech to the next (information theory) question of novelty - hi novelty versus low novelty as predictors of leaders and followers
Robespierre bringing in novel ideas
How do you differentiate Robespierre versus a Muppet (like Animal)? What is the level of following after novelty?
Four parts (2x2 grid) - high novelty, high imitation (novelty with ideas that stick) - high novelty, low imitation (new ideas ignored) - low novelty, high imitation - low novelty, low imitation (discussion killers)
Could one analyze television scripts over time to determine the good/bad, when they'll "jump the shark"?
-
-
www.complexityexplorer.org www.complexityexplorer.org
-
a common technique in natural language processing is to operationalize certain semantic concepts (e.g., "synonym") in terms of syntactic structure (two words that tend to occur nearby in a sentence are more likely to be synonyms, etc). This is what word2vec does.
Can I use some of these sorts of methods with respect to corpus linguistics over time to better identified calcified words or archaic phrases that stick with the language, but are heavily limited to narrower(ing) contexts?
-
-
defenseurdesdroits.fr defenseurdesdroits.fr
-
La Défenseure des droits recommande auxdirecteurs académiques, en concertation avecles collèges et lycées, de diffuser à chaquerentrée scolaire, via un support adapté (livretd’accueil, etc.), les informations relatives àla présence au sein de l’établissement, del’assistante sociale et de l’infirmière scolaire.Une information systématique à destinationdes parents sur l’accès à la médecine scolairedoit aussi être organisée.
Recommandadion 12
-
-
Local file Local file
-
it maybe well to take the notes directly in the text book, either on the margins,between the leaves, or on insert-leaves which book-shops sell for that pu
"insert-eaves" !!
I've heard of interleaved books, but was unaware of the practice of book shops selling "insert-leaves" being specifically sold for the purpose of inserting notes into books.
-
-
www.defenseurdesdroits.fr www.defenseurdesdroits.fr
-
Recommandation 36Prendre toutes les mesures utiles pour que lesdispositifs d’accompagnement des usagerssoient connus, que leurs services soientidentifiés et qualifiés, et que leur action soitcoordonnée.
-
-
www.cambridge.org www.cambridge.org
-
We have proposed the existence of a notational system associated with an unambiguous animal subject, relating to biologically significant events informed by the ethological record, which allows us for the first time to understand a Palaeolithic notational system in its entirety. This utilized/allowed the function of ordinality (and, later, place value), which were revolutionary steps forward in information recording.
-
-
Local file Local file
-
Fried-berg Judeo-Arabic Project, accessible at http://fjms.genizah.org. This projectmaintains a digital corpus of Judeo-Arabic texts that can be searched and an-alyzed.
The Friedberg Judeo-Arabic Project contains a large corpus of Judeo-Arabic text which can be manually searched to help improve translations of texts, but it might also be profitably mined using information theoretic and corpus linguistic methods to provide larger group textual translations and suggestions at a grander scale.
-
-
www.govinfo.gov www.govinfo.gov
-
TIPOFF was created in 1987 for the express purpose of using biographic information drawn from intelligence products for watchlisting purposes. In 1987 TIPOFF began keeping track of suspected terrorists literally with a shoebox and 3 by 5 cards. Since then the program has evolved into a sophisticated interagency counterterrorism tool specifically designed to enhance the security of our nation's borders.
https://www.govinfo.gov/content/pkg/CHRG-107jhrg96166/html/CHRG-107jhrg96166.htm
-
- Dec 2022
-
www.facebook.com www.facebook.com
-
4NO POSTING OR UPLOADING VIDEOS OF ANY KINDTo protect the quality of our group & prevent members from being solicited products & services - we don't allow any videos because we can't monitor what's being said word for word. Written post only.
annotation meta: may need new tag: - can't effectively monitor
-
-
www.nytimes.com www.nytimes.com
-
Three weeks ago, an experimental chat bot called ChatGPT made its case to be the industry’s next big disrupter. It can serve up information in clear, simple sentences, rather than just a list of internet links. It can explain concepts in ways people can easily understand. It can even generate ideas from scratch, including business strategies, Christmas gift suggestions, blog topics and vacation plans.
ChatGPT's synthesis of information versus Google Search's list of links
The key difference here, though, is that with a list of links, one can follow the links and evaluate the sources. With a ChatGPT response, there are no citations to the sources—just an amalgamation of statements that may or may not be true.
-
-
Local file Local file
-
By AD 500, the Christian Church had drawn most of the talented men of theage into its service, in either missionary, organizational, doctrinal, or purelycontemplative activity.—Edward Grant, Physical Science in the Middle Ages
quote
Google is like the Catholic Church both as organizers of information and society<br /> Just as the Catholic Church used funding from the masses to employ most of the smartest and talented to its own needs and mission from 500-1000 AD, Google has used advertising technology to collect people and employed them to their own needs. For one, the root was religion and the other technology, but both were organizing people and information for their own needs.
Who/what organization will succeed them? What will its goals and ethics entail?
(originally written 2022-12-11)
-
-
voices.uchicago.edu voices.uchicago.edu
-
Censorship and Information Control During Information RevolutionsExploring how new information technologies from the printing press to the digital age have stimulated new forms of censorship and information control.
https://voices.uchicago.edu/censorship/
Related YouTube channel/videos: https://www.youtube.com/channel/UCeNP7NIWmB70wFBv9QolYkg
-
-
stratechery.com stratechery.com
-
Here’s an example of what homework might look like under this new paradigm. Imagine that a school acquires an AI software suite that students are expected to use for their answers about Hobbes or anything else; every answer that is generated is recorded so that teachers can instantly ascertain that students didn’t use a different system. Moreover, instead of futilely demanding that students write essays themselves, teachers insist on AI. Here’s the thing, though: the system will frequently give the wrong answers (and not just on accident — wrong answers will be often pushed out on purpose); the real skill in the homework assignment will be in verifying the answers the system churns out — learning how to be a verifier and an editor, instead of a regurgitator. What is compelling about this new skillset is that it isn’t simply a capability that will be increasingly important in an AI-dominated world: it’s a skillset that is incredibly valuable today. After all, it is not as if the Internet is, as long as the content is generated by humans and not AI, “right”; indeed, one analogy for ChatGPT’s output is that sort of poster we are all familiar with who asserts things authoritatively regardless of whether or not they are true. Verifying and editing is an essential skillset right now for every individual.
What homework could look like in a ChatGPT world
Critical editing becomes a more important skill than summation. When the summation synthesis comes for free, students distinguish themselves by understanding what is correct and correcting what is not. Sounds a little bit like "information literacy".
-
-
ilpubs.stanford.edu:8090 ilpubs.stanford.edu:8090
-
1.3.2 Academic Search Engine Research
Another goal of Google is a specification of the previous goal (improved search quality), as they want to create an improved searching experience for students.
The World Wide Web was originally created to facilitate academic research, and Google plans on creating a system that can support research activities as mentioned.
-
-
carnegieendowment.org carnegieendowment.org
-
Information Environment
Information Environment
-
- Nov 2022
-
library.oapen.org library.oapen.org
-
There are at least three remarkable aspects to this spread of information seeking
First, computer-supported searching has sprawled beyond the libraries, archives, and specialized documentation systems it was largely confined to before the arrival of the web. Second, what retrieval operates on – information – has come to stand for almost anything, from scraps of knowledge to things, people, ideas, or experiences. Third, the deliberate and motivated act of formulating a query to f ind something is only one of the many forms in which information retrieval nowadays manifests itself.
-
-
theinformed.life theinformed.life
-
Mark: Cathy Marshall at Xerox PARC originally started speaking about information gardening. She developed an early tool that’s the inspiration for the Tinderbox map view, in which you would have boxes but no lines. It was a spatial hypertext system, a system for connecting things by placing them near each other rather than drawing a line between them. Very interesting abstract representational problem, but also it turned out to be tremendously useful.
Cathy Marshall was an early digital gardener!
-
All research… All significant research is, in some respects, bottom-up. There is no alternative. And so, the only research that you can do top-down entirely is research for which you already have the solution.
Research, by design, is a bottom-up process.
-
-
www.cs.ucr.edu www.cs.ucr.edu
-
Dr. Miho Ohsaki re-examined workshe and her group had previously published and confirmed that the results are indeed meaningless in the sensedescribed in this work (Ohsaki et al., 2002). She has subsequently been able to redefine the clustering subroutine inher work to allow more meaningful pattern discovery (Ohsaki et al., 2003)
Look into what Dr. Miho Ohsaki changed about the clustering subroutine in her work and how it allowed for "more meaningful pattern discovery"
-
Eamonn Keogh is an assistant professor of Computer Science at the University ofCalifornia, Riverside. His research interests are in Data Mining, Machine Learning andInformation Retrieval. Several of his papers have won best paper awards, includingpapers at SIGKDD and SIGMOD. Dr. Keogh is the recipient of a 5-year NSF CareerAward for “Efficient Discovery of Previously Unknown Patterns and Relationships inMassive Time Series Databases”.
Look into Eamonn Keogh's papers that won "best paper awards"
-
-
prosimpli.com prosimpli.com
-
https://prosimpli.com/index-card-holder/
Reasonable state-of-the-art of index card holders. Does manage to leave out some of the bleacher display methods, but otherwise not bad.
-
-
observablehq.com observablehq.com
-
lucahammer.com lucahammer.com
-
www.stefanieposavec.com www.stefanieposavec.com
-
www.library.msstate.edu www.library.msstate.edu
-
Any MSU Libraries public service desk
Should this be more specific, now that the main library really only has one public service desk?
-
-
medium.com medium.com
-
The only diagram or image in The Origin of Species, a tree depicting divergence (source)
Darwin's On the Origin of Species only contains one diagram, a branching tree diagram which shows divergence of species.

-
he was working on the same theme with Stefanie Posavec. They completed their piece some time later, depicting the changes as lovely branching trees — a kind of homage to Darwin’s lone diagram in the book.
Greg McInerny of Microsoft Research and Stefanie Posavek created a version of Darwin's On the Origin of Species that displayed variations between the editions as a branching tree diagram, a nod to the only diagram which appeared in Darwin's original work. .
-
-
inst-fs-iad-prod.inscloudgate.net inst-fs-iad-prod.inscloudgate.netview1
-
range of digital literacy practices
This is a significant aspect of social annotation/Hypothesis. The low barrier for entry and the low-stakes nature of the work make it a great way to develop digilit, potentially, as people can engage with connecting and linking in their writing.
-
-
en.wikipedia.org en.wikipedia.org
-
The paradox of information systems[edit] Drummond suggests in her paper in 2008 that computer-based information systems can undermine or even destroy the organisation that they were meant to support, and it is precisely what makes them useful that makes them destructive – a phenomenon encapsulated by the Icarus Paradox.[9] For examples, a defence communication system is designed to improve efficiency by eliminating the need for meetings between military commanders who can now simply use the system to brief one another or answer to a higher authority. However, this new system becomes destructive precisely because the commanders no longer need to meet face-to-face, which consequently weakened mutual trust, thus undermining the organisation.[10] Ultimately, computer-based systems are reliable and efficient only to a point. For more complex tasks, it is recommended for organisations to focus on developing their workforce. A reason for the paradox is that rationality assumes that more is better, but intensification may be counter-productive.[11]
From Wikipedia page on Icarus Paradox. Example of architectural design/technical debt leading to an "interest rate" that eventually collapsed the organization. How can one "pay down the principle" and not just the "compound interest"? What does that look like for this scenario? More invest in workforce retraining?
Humans are complex, adaptive systems. Machines have a long history of being complicated, efficient (but not robust) systems. Is there a way to bridge this gap? What does an antifragile system of machines look like? Supervised learning? How do we ensure we don't fall prey to the oracle problem?
Baskerville, R.L.; Land, F. (2004). "Socially Self-destructing Systems". The Social Study of Information and Communication Technology: Innovation, actors, contexts. Oxford: Oxford University Press. pp. 263–285
-
-
blog.chain.link blog.chain.link
-
What Is a Blockchain Oracle? A blockchain oracle is a secure piece of middleware that facilitates communication between blockchains and any off-chain system, including data providers, web APIs, enterprise backends, cloud providers, IoT devices, e-signatures, payment systems, other blockchains, and more. Oracles take on several key functions: Listen – monitor the blockchain network to check for any incoming user or smart contract requests for off-chain data. Extract – fetch data from one or multiple external systems such as off-chain APIs hosted on third-party web servers. Format – format data retrieved from external APIs into a blockchain readable format (input) and/or making blockchain data compatible with an external API (output). Validate – generate a cryptographic proof attesting to the performance of an oracle service using any combination of data signing, blockchain transaction signing, TLS signatures, Trusted Execution Environment (TEE) attestations, or zero-knowledge proofs. Compute – perform some type of secure off-chain computation for the smart contract, such as calculating a median from multiple oracle submissions or generating a verifiable random number for a gaming application. Broadcast – sign and broadcast a transaction on the blockchain in order to send data and any corresponding proof on-chain for consumption by the smart contract. Output (optional) – send data to an external system upon the execution of a smart contract, such as relaying payment instructions to a traditional payment network or triggering actions from a cyber-physical system.
Seems related to the paradox of information systems. Add to Anki deck
-
-
www.miclog.com www.miclog.com
-
Info Select was on this list of DEVONthink Windows alternatives. Looks like "personal information management" preceded the boom of "personal knowledge management"
-
-
www.youtube.com www.youtube.com
-
https://www.youtube.com/watch?v=2ueMHkGljK0
Robert Greene's method goes back to junior high school when he was practicing something similar. He doesn't say he invented it, and it may be likely that teachers modeled some of the system for him. He revised the system over time to make it work for himself.
- [x] Revisit this for some pull quotes and fine details of his method. (Done on 2022-11-08)
-
-
learnful.ca learnful.ca
-
-
billyoppenheimer.com billyoppenheimer.com
-
I never immediately read an article then make a notecard.
By waiting some amount of time (days/weeks/a few months) between originally reading something and processing one's notes on it allows them to slowly distill into one's consciousness. It also allows one to operate on their diffuse thinking which may also help to link ideas to others in their memory.
-
-
en.wikipedia.org en.wikipedia.org
-
its jobs (internal representation of process groups)
-
-
www.reddit.com www.reddit.com
-
Interesting. So it's like an analog CRM? Multiple people have brought this type of thing up.
reply to u/sscheper<br /> https://www.reddit.com/r/antinet/comments/yka3ro/vintage_yawman_and_erbe_card_index_filing_systems/
These were commonly used for what we now call CRM as well as for accounting, general filing, and all sorts of business and back office use cases in the early 20th century which are now handled by computers. A dozen or so companies made large wooden and metal index card filing cabinets and sold them by the truckload to businesses of every sort.
A lot of the digiterati are just repeating and attempting to reinvent these sorts of ideas using Obsidian, Notion, etc.
-
- Oct 2022
-
www.explainpaper.com www.explainpaper.com
-
Another in a growing line of research tools for processing and making sense of research literature including Research Rabbit, Connected Papers, Semantic Scholar, etc.
Functionality includes the ability to highlight sections of research papers with natural language processing to explain what those sections mean. There's also a "chat" that allows you to ask questions about the paper which will attempt to return reasonable answers, which is an artificial intelligence sort of means of having an artificial "conversation with the text".
cc: @dwhly @remikalir @jeremydean
-
-
-
getting people tofind their own information,
do your own research. Relate to Tripodi https://www.google.com/books/edition/The_Propagandists_Playbook/rWZ4EAAAQBAJ?hl=en&gbpv=1&printsec=frontcover
-
plant the seed of doubt
disinfo strategy
-
from Paradoxes of Media and Information Literacy https://www.taylorfrancis.com/books/oa-mono/10.4324/9781003163237/paradoxes-media-information-literacy-jutta-haider-olof-sundin?refId=069de9de-6269-4591-9670-0d570e989bdf&context=ubx
-
-
www.reddit.com www.reddit.com
-
Workflow for capturing and processing online content for use in a Zettlekasten
reply to https://www.reddit.com/r/Zettelkasten/comments/ye3bvk/workflow_for_capturing_and_processing_online/
While it's possible that some set of tools will work best for you and potentially be more "fun" than other combinations, the upper limit you'll find on efficiency and productivity in this area is limited.
As a result, I'd recommend looking at the quality of the material you're putting into your stream as potentially the best means of improvement at your disposal. The quality of your ideas and thought will increase if you're reading and conversing with the highest quality sources you can get your hands on. Well-researched, long form material (books, journal articles) will have likely done a lot of the filtering and heavy work for you, so use those as input when you can.
Unless you're a sociologist or cultural anthropologist looking for examples of behaviors and material in social media, it may not be the best place to turn. Before I open social media apps I remind myself of note #1267 from Goethe's slipbox (Maxims and Reflections): "Ignorant people raise questions which were answered by the wise thousands of years ago."
Similarly, upon hearing the words "firehose", "drowning", or "information overload", I'm reminded that, presuming you'd even want to make the effort, there's only one way to eat a whale: one bite at a time.
-
-
www.scrintal.com www.scrintal.com
-
Registered 2022-09-07
-
-
www.denizcemonduygu.com www.denizcemonduygu.com
-
https://www.denizcemonduygu.com/philo/browse/
History of Philosophy: Summarized & Visualized
This could be thought of as a form of digital, single-project zettelkasten dedicated to philosophy. It's got people, sources, and ideas which are cross linked in a Luhmann-sense (without numbering) though not in a topical index-sense. Interestingly it has not only a spatial interface and shows spatial relationships between people and ideas over time using a timeline, but it also indicates—using colored links—the ideas of disagreement/contrast/refutation and agreement/similarity/expansion.
What other (digital) tools of thought provide these sorts of visualization affordances?
-
-
Local file Local file
-
disport itself happily in its new and extended Quadrivium withoutpassing through the Trivium. But the scholastic tradition, though broken andmaimed, still lingered in the public schools and universities:
Is it possible that with the flowering of the storehouse of knowledge and the rise of information overload following Gutenberg's moveable type, we became overly enamored with Sayers' subject-based Quadrivium that we forgot to focus on the basics of the Trivium?
-
-
www.nytimes.com www.nytimes.com
-
“I think we were so happy to develop all this critique because we were so sure of the authority of science,” Latour reflected this spring. “And that the authority of science would be shared because there was a common world.”
This is crucial. Latour was constructing science based on the belief of its authority - not deconstructing science. And the point about the common world, as inherently connected to the authority of science, is great.
-
-
delong.typepad.com delong.typepad.com
-
Intellectual readiness involves a minimumlevel of visual perception such that the child can take in andremember an entire word and the letters that combine to formit. Language readiness involves the ability to speak clearly andto use several sentences in correct order.
Just as predictive means may be used on the level of letters, words, and even whole sentences within information theory at the level of specific languages, does early orality sophistication in children help them to become predictive readers at earlier ages?
How could one go about testing this, particularly in a broad, neurodiverse group?
-
. The goal a reader seeks-be itentertainment, information or understanding-determines theway he reads.
There are three goals of most reading: education, information, and understanding.
Are there others we're missing here?
-
-
www.reddit.com www.reddit.com
-
Underlining Keyterms and Index Bloat .t3_y1akec._2FCtq-QzlfuN-SwVMUZMM3 { --postTitle-VisitedLinkColor: #9b9b9b; --postTitleLink-VisitedLinkColor: #9b9b9b; --postBodyLink-VisitedLinkColor: #989898; }
Hello u/sscheper,
Let me start by thanking you for introducing me to Zettelkasten. I have been writing notes for a week now and it's great that I'm able to retain more info and relate pieces of knowledge better through this method.
I recently came to notice that there is redundancy in my index entries.
I have two entries for Number Line. I have two branches in my Math category that deals with arithmetic, and so far I have "Addition" and "Subtraction". In those two branches I talk about visualizing ways of doing that, and both of those make use of and underline the term Number Line. So now the two entries in my index are "Number Line (Under Addition)" and "Number Line (Under Subtraction)". In those notes I elaborate how exactly each operation is done on a number line and the insights that can be derived from it. If this continues, I will have Number Line entries for "Multiplication" and "Division". I will also have to point to these entries if I want to link a main note for "Number Line".
Is this alright? Am I underlining appropriately? When do I not underline keyterms? I know that I do these to increase my chances of relating to those notes when I get to reach the concept of Number Lines as I go through the index but I feel like I'm overdoing it, and it's probably bloating it.
I get "Communication (under Info. Theory): '4212/1'" in the beginning because that is one aspect of Communication itself. But for something like the number line, it's very closely associated with arithmetic operations, and maybe I need to rethink how I populate my index.
Presuming, since you're here, that you're creating a more Luhmann-esque inspired zettelkasten as opposed to the commonplace book (and usually more heavily indexed) inspired version, here are some things to think about:<br /> - Aren't your various versions of number line card behind each other or at least very near each other within your system to begin with? (And if not, why not?) If they are, then you can get away with indexing only one and know that the others will automatically be nearby in the tree. <br /> - Rather than indexing each, why not cross-index the cards themselves (if they happen to be far away from each other) so that the link to Number Line (Subtraction) appears on Number Line (Addition) and vice-versa? As long as you can find one, you'll be able to find them all, if necessary.
If you look at Luhmann's online example index, you'll see that each index term only has one or two cross references, in part because future/new ideas close to the first one will naturally be installed close to the first instance. You won't find thousands of index entries in his system for things like "sociology" or "systems theory" because there would be so many that the index term would be useless. Instead, over time, he built huge blocks of cards on these topics and was thus able to focus more on the narrow/niche topics, which is usually where you're going to be doing most of your direct (and interesting) work.
Your case sounds, and I see it with many, is that your thinking process is going from the bottom up, but that you're attempting to wedge it into a top down process and create an artificial hierarchy based on it. Resist this urge. Approaching things after-the-fact, we might place information theory as a sub-category of mathematics with overlaps in physics, engineering, computer science, and even the humanities in areas like sociology, psychology, and anthropology, but where you put your work on it may depend on your approach. If you're a physicist, you'll center it within your physics work and then branch out from there. You'd then have some of the psychology related parts of information theory and communications branching off of your physics work, but who cares if it's there and not in a dramatically separate section with the top level labeled humanities? It's all interdisciplinary anyway, so don't worry and place things closest in your system to where you think they fit for you and your work. If you had five different people studying information theory who were respectively a physicist, a mathematician, a computer scientist, an engineer, and an anthropologist, they could ostensibly have all the same material on their cards, but the branching structures and locations of them all would be dramatically different and unique, if nothing else based on the time ordered way in which they came across all the distinct pieces. This is fine. You're building this for yourself, not for a mass public that will be using the Dewey Decimal System to track it all down—researchers and librarians can do that on behalf of your estate. (Of course, if you're a musician, it bears noting that you'd be totally fine building your information theory section within the area of "bands" as a subsection on "The Bandwagon". 😁)
If you overthink things and attempt to keep them too separate in their own prefigured categorical bins, you might, for example, have "chocolate" filed historically under the Olmec and might have "peanut butter" filed with Marcellus Gilmore Edson under chemistry or pharmacy. If you're a professional pastry chef this could be devastating as it will be much harder for the true "foodie" in your zettelkasten to creatively and more serendipitously link the two together to make peanut butter cups, something which may have otherwise fallen out much more quickly and easily if you'd taken a multi-disciplinary (bottom up) and certainly more natural approach to begin with. (Apologies for the length and potential overreach on your context here, but my two line response expanded because of other lines of thought I've been working on, and it was just easier for me to continue on writing while I had the "muse". Rather than edit it back down, I'll leave it as it may be of potential use to others coming with no context at all. In other words, consider most of this response a selfish one for me and my own slip box than as responsive to the OP.)
Tags
- commonplace books vs. zettelkasten
- information theory
- bottom-up vs. top-down
- Claude Shannon
- Niklas Luhmann's index
- hierarchies
- reply
- zettelkasten
- Dewey Decimal System
- Niklas Luhmann's zettelkasten
- examples
- multi-disciplinary research
- indices
- Universal Decimal Classification
- The Bandwagon
Annotators
URL
-
-
interaksyon.philstar.com interaksyon.philstar.com
-
Edgerly noted that disinformation spreads through two ways: The use of technology and human nature.Click-based advertising, news aggregation, the process of viral spreading and the ease of creating and altering websites are factors considered under technology.“Facebook and Google prioritize giving people what they ‘want’ to see; advertising revenue (are) based on clicks, not quality,” Edgerly said.She noted that people have the tendency to share news and website links without even reading its content, only its headline. According to her, this perpetuates a phenomenon of viral spreading or easy sharing.There is also the case of human nature involved, where people are “most likely to believe” information that supports their identities and viewpoints, Edgerly cited.“Vivid, emotional information grabs attention (and) leads to more responses (such as) likes, comments, shares. Negative information grabs more attention than (the) positive and is better remembered,” she said.Edgerly added that people tend to believe in information that they see on a regular basis and those shared by their immediate families and friends.
Spreading misinformation and disinformation is really easy in this day and age because of how accessible information is and how much of it there is on the web. This is explained precisely by Edgerly. Noted in this part of the article, there is a business for the spread of disinformation, particularly in our country. There are people who pay what we call online trolls, to spread disinformation and capitalize on how “chronically online” Filipinos are, among many other factors (i.e., most Filipinos’ information illiteracy due to poverty and lack of educational attainment, how easy it is to interact with content we see online, regardless of its authenticity, etc.). Disinformation also leads to misinformation through word-of-mouth. As stated by Edgerly in this article, “people tend to believe in information… shared by their immediate families and friends”; because of people’s human nature to trust the information shared by their loved ones, if one is not information literate, they will not question their newly received information. Lastly, it most certainly does not help that social media algorithms nowadays rely on what users interact with; the more that a user interacts with a certain information, the more that social media platforms will feed them that information. It does not help because not all social media websites have fact checkers and users can freely spread disinformation if they chose to.
-
-
clinicalgenome.org clinicalgenome.org
-
seen by the original user, not by
A case of: Disease assertion: family information: case presenting:
-
-
archive.org archive.org
-
Much like Umberto Eco (How to Write a Thesis), in the closing paragraphs of his essay, Goutor finally indicates that note cards can potentially be reused for multiple projects because each one "contains a piece of information which does not depend on a specific context for its value." While providing an example of how this might work, he goes even further by not only saying that "note-cards should never be discarded" but that they might be "recycled" by passing them on to "another interested party" while saying that their value and usefulness is dependent upon how well they may have adhered to some of the most basic note taking methods. (p35)
-
For physical note taking on index cards or visualizations provided by computer generated graphs, one can physically view a mass of notes and have a general feeling if there is a large enough corpus to begin writing an essay, chapter, or book or if one needs to do additional research on a topic, or perhaps pick a different topic on which to focus.
(parts suggested by p7, though broadly obvious)
-
-
cosma.graphlab.fr cosma.graphlab.frAccueil1
-
https://cosma.graphlab.fr/<br /> https://cosma.graphlab.fr/en/
When did this come out?
Appears to be a visualization tool for knowledge work. They recommend it for use with Zettlr, but it looks like it would work with other text based tools. Point it at markdown files to create graphs apparently.
This looks like the sort of standards based tool that would allow greater flexibility when using various data stores that we talk about in Friends of the Link.
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>Arthur Perret </span> in And you, what are you doing? (<time class='dt-published'>08/31/2022 02:40:03</time>)</cite></small>
@flancian
-
-
en.wikipedia.org en.wikipedia.org
-
He argued that God gazes over history in its totality and finds all periods equal.
Leopold von Ranke's argument that God gazes over history and finds all periods equal is very similar to a framing of history from the viewpoint of statistical thermodynamics: it's all the same material floating around, it just takes different states at different times.
-
-
www.researchrabbit.ai www.researchrabbit.ai
-
cdn-contenu.quebec.ca cdn-contenu.quebec.ca
-
En cas de non-respect de la Loi, la Commission d’accès à l’information pourra imposer des sanctionsimportantes, qui pourraient s’élever jusqu’à 25 M$ ou à 4 % du chiffre d’affaires mondial. Cette sanctionsera proportionnelle, notamment, à la gravité du manquement et à la capacité de payer de l’entreprise.ENTREPRISES
-
-
Local file Local file
-
here are several ways I havefound useful to invite the sociological imagination:
C. Wright Mills delineates a rough definition of "sociological imagination" which could be thought of as a framework within tools for thought: 1. Combinatorial creativity<br /> 2. Diffuse thinking, flâneur<br /> 3. Changing perspective (how would x see this?) Writing dialogues is a useful method to accomplish this. (He doesn't state it, but acting as a devil's advocate is a useful technique here as well.)<br /> 4. Collecting and lay out all the multiple viewpoints and arguments on a topic. (This might presume the method of devil's advocate I mentioned above 😀)<br /> 5. Play and exploration with words and terms<br /> 6. Watching levels of generality and breaking things down into smaller constituent parts or building blocks. (This also might benefit of abstracting ideas from one space to another.)<br /> 7. Categorization or casting ideas into types 8. Cross-tabulating and creation of charts, tables, and diagrams or other visualizations 9. Comparative cases and examples - finding examples of an idea in other contexts and time settings for comparison and contrast 10. Extreme types and opposites (or polar types) - coming up with the most extreme examples of comparative cases or opposites of one's idea. (cross reference: Compass Points https://hypothes.is/a/Di4hzvftEeyY9EOsxaOg7w and thinking routines). This includes creating dimensions of study on an object - what axes define it? What indices can one find data or statistics on? 11. Create historical depth - examples may be limited in number, so what might exist in the historical record to provide depth.
Tags
- opposites
- building blocks
- sociological imagination
- The Sociological Imagination
- historical context
- trend analysis
- compass points
- browsing
- abstraction
- combinatorial creativity
- diffuse thinking
- information visualization
- dimensions
- thinking routines
- terms
- historical perspective
- devil's advocate
- dialogues
- taxonomies
- definitions
- flâneur
- generalization
- categorization
Annotators
-
- Sep 2022
-
www.scientificamerican.com www.scientificamerican.com
-
This winner-take-all popularity pattern of memes, in which most are barely noticed while a few spread widely, could not be explained by some of them being more catchy or somehow more valuable: the memes in this simulated world had no intrinsic quality. Virality resulted purely from the statistical consequences of information proliferation in a social network of agents with limited attention.
-
“Limited individual attention and online virality of low-quality information,” By Xiaoyan Qiu et al., in Nature Human Behaviour, Vol. 1, June 2017
The upshot of this paper seems to be "information overload alone can explain why fake news can become viral."
-
Information Overload
Recall that this isn't new:
Blair, Ann M. Too Much to Know: Managing Scholarly Information before the Modern Age. Yale University Press, 2010. https://yalebooks.yale.edu/book/9780300165395/too-much-know
The new portions are the acceleration of the issue by social media and the inflammation by artificial intelligence.
-
Unable to process all this material, we let our cognitive biases decide what we should pay attention to.
In a society consumed with information overload, it is easier for our brains to allow our well evolved cognitive biases to decide not only what to pay attention to, but what to believe.
-
-
www.youtube.com www.youtube.com
-
https://www.youtube.com/watch?v=P2HegcwDRnU
Makes the argument that note taking is an information system, and if it is, then we can use the research from the corpus of information system (IS) theory to examine how to take better notes.
He looks at the Wang and Wang 2006 research and applies their framework of "complete, meaningful, unambiguous, and correct" dimensions of data quality to example note areas of study notes, project management notes (or to do lists) and recipes.
Looks at dimensions of data quality from Mahanti, 2019.
What is the difference between notes and annotations?
-
-
-
I've recently run across a few examples of a pattern that should have a name because it would appear to dramatically change the outcomes. I'm going to term it "decisions based on possibilities rather than realities". It's seen frequently in economics and politics and seems to be a form of cognitive bias. People make choices (or votes) about uncertain futures, often when there is a confluence of fear, uncertainty, and doubt, and these choices are dramatically different than when they're presented with the actual circumstances in practice.
A recent example was a story about a woman who was virulently pro-life who when presented with a situation required her to switch her position to pro-choice.
Another relates to choices that people want to make about where their children might go to school versus where they actually send them, and the damage this does to public education.
Let's start collecting examples of these quandaries at all levels of making choices in the real world.
What is the relationship to this with the mental exercise of "descending into the particular"?
Does this also potentially cause decision fatigue in cases of voting spaces when constituents are forced to vote for candidates on thousands of axes which they may or may not agree with?
-
- Aug 2022
-
www.newscientist.com www.newscientist.com
-
Sparkes, M. (2021, November 19). Wikipedia tests AI for spotting contradictory claims in articles. New Scientist. https://institutions.newscientist.com/article/2298169-wikipedia-tests-ai-for-spotting-contradictory-claims-in-articles/?utm_campaign=echobox&utm_medium=social&utm_source=Twitter&utm_term=Autofeed
-
-
psyarxiv.com psyarxiv.com
-
Laurent, C. de S., Murphy, G., Hegarty, K., & Greene, C. (2021). Measuring the effects of misinformation exposure on behavioural intentions. PsyArXiv. https://doi.org/10.31234/osf.io/2xngy
-
-
psyarxiv.com psyarxiv.com
-
Šrol, J., Cavojova, V., & Mikušková, E. B. (2021). Social consequences of COVID-19 conspiracy beliefs: Evidence from two studies in Slovakia. PsyArXiv. https://doi.org/10.31234/osf.io/y4svc
-
-
psyarxiv.com psyarxiv.com
-
Epstein, Z., Berinsky, A., Cole, R., Gully, A., Pennycook, G., & Rand, D. (2021). Developing an accuracy-prompt toolkit to reduce COVID-19 misinformation online. PsyArXiv. https://doi.org/10.31234/osf.io/sjfbn
-
-
-
Karan, A. (2022). We cannot afford to repeat these four pandemic mistakes. BMJ, 376, o631. https://doi.org/10.1136/bmj.o631
-
-
twitter.com twitter.com
-
ReconfigBehSci. (2021, December 15). RT @CaulfieldTim: Check out the #OpenWHO course “#Infodemic Management 101” https://openwho.org/courses/infodemic-management-101 via @WHO @TDPurnat cc @ScienceUpFirst @… [Tweet]. @SciBeh. https://twitter.com/SciBeh/status/1471132916445061130
-
-
twitter.com twitter.com
-
ReconfigBehSci [@SciBeh]. (2021, December 20). This thread is sobering and informative with respect to what overloading health services means in terms of individual experience...worth popping into google translate fir non-German speakers [Tweet]. Twitter. https://twitter.com/SciBeh/status/1472983739890348045
-
-
twitter.com twitter.com
-
Pouria Hadjibagheri [@Pouriaaa]. (2021, July 14). The state of the UK’s statistical system 2020/21 by @StatsRegulation Thank you! 🎊😀🎉 See the report: Https://osr.statisticsauthority.gov.uk/publication/the-state-of-the-uks-statistical-system-2020-21/pages/8/ https://t.co/dEBmVz3oTm [Tweet]. Twitter. https://twitter.com/Pouriaaa/status/1415371346775838725
-
-
www.vox.com www.vox.com
-
With few exceptions, most market democracies have recovered from the 2008 financial crisis. But the public has not recovered from the shock of watching supposed experts and politicians, the people who posed as the wise pilots of our prosperity, sound and act totally clueless while the economy burned. In the past, when the elites controlled the flow of information, the financial collapse might have been portrayed as a sort of natural disaster, a tragedy we should unify around our leadership to overcome. By 2008, that was already impossible. The networked public perceived the crisis (rightly, I think) as a failure of government and of the expert elites.
Martin Gurri argues that had the financial crisis of 2008 happened in the 20th century, the elites, through their control of the flow of information, might have portrayed it as a natural disaster we should rally around our leadership to overcome. But with the advent of the internet, we got the "networked public", and the elites and government lost their monopoly on information.
-
-
-
Seaman, K. L., Christensen, A. P., Senn, K., Cooper, J., & Cassidy, B. S. (2022). Age Differences in the Social Associative Learning of Trust Information. PsyArXiv. https://doi.org/10.31234/osf.io/b38rd
Tags
- social processing
- age difference
- decision making
- personality psychology
- social associative learning
- social science
- behavioral science
- developmental psychology
- social cue
- research
- learning
- working memory
- trust
- cognitive psychology
- judgement
- lang:en
- social cognition
- is:preprint
- fMRI
- social psychology
- aging
- trust information
Annotators
URL
-
-
boffosocko.com boffosocko.com
-
If this fits your style and you don’t get any value out of having cards with locators like 3a4b/65m1, then don’t do that (for you) useless make-work. Make sure your system is working for you and you’re not working for your system.
Risks of replicating physical attributes in digital systems
This article makes so much sense, but this sentence more than any other. As librarians will will know, a physical book can only be put in one place on a shelf...you can't realistically replicate a book and put it in groupings with all like-minded books. The call number was invented to bring organization to the physical space and the card catalog was invented to have a way for representations of the books—cards!—interfiled in many places to help with finding the book. Luhmann's card numbering sequence was the first thing I dropped when reading about Zettelkasten, and those that insist on that mechanism for their digital slip boxes are artificially constraining their electronic systems with a physical world limitation.
-
-
www.techradar.com www.techradar.com
-
"PDF is where documents go to die. Once something is in PDF, it's like a roach motel for data."
—Chris Pratley, Microsoft Office's general manager (in TechRadar, 2012)
obvious bias here on part of Pratley...
Oddly, even if this were true, I'm not seeing patterns in the wild by which Microsoft products are helping to dramatically accelerate the distribution and easy ability to re-use data within documents. Perhaps its happening within companies or organizations to some extent, but it's not happening within the broader commons of the internet.
If .pdfs are where information goes to die, then perhaps tools like Hypothes.is are meant to help resurrect that information?
-
-
www.springer.com www.springer.com
-
https://www.springer.com/series/6159/books
Information Science and Knowledge Management Series of texts from Springer
-
-
ljvmiranda921.github.io ljvmiranda921.github.io
-
I like to think of thoughts as streaming information, so I don’t need to tag and categorize them as we do with batched data. Instead, using time as an index and sticky notes to mark slices of info solves most of my use cases. Graph notebooks like Obsidian think of information as batched data. So you have a set of notes (samples) that you try to aggregate, categorize, and connect. Sure there’s a use case for that: I can’t imagine a company wiki presented as streaming info! But I don’t think it aids me in how I usually think. When thinking with pen and paper, I prefer managing streamed information first, then converting it into batched information later— a blog post, documentation, etc.
There's an interesting dichotomy between streaming information and batched data here, but it isn't well delineated and doesn't add much to the discussion as a result. Perhaps distilling it down may help? There's a kernel of something useful here, but it isn't immediately apparent.
Relation to stock and flow or the idea of the garden and the stream?
-
-
www.youtube.com www.youtube.comYouTube1
-
Come back and read these particular texts, but these look interesting with respect to my work on orality, early "religion", secrecy, and information spread:<br /> - Ancient practices removed from their lineage lose their meaning - In spiritual practice, secrecy can be helpful but is not always necessary
-
-
threadreaderapp.com threadreaderapp.com
-
https://threadreaderapp.com/thread/1557092705485967360.html
Possible that in addition to the linguistic portions that MS 408 serves as part/parcel of the art of memory with some hidden meaning with respect to alchemical work?
-
-
mutualisationpratiquesdoc.enssib.fr mutualisationpratiquesdoc.enssib.fr
-
Politique documentaire Ensemble des objectifs et processus pilotant la gestion de l’information, incluant la politique d’acquisition, la politique de conservation et la politique de médiation des collections. La politique documentaire est une partie intégrante et essentielle du projet d'établissement, permettant de répondre aux missions de la structure et aux attentes des usagers.
-
-
mitpress.mit.edu mitpress.mit.edu
-
History and Foundations of Information Science
This series of books focuses on the historical approach or theoretical approach to information science and seeks a broader interpretation of what we consider as information (i.e., information is in the eye of the beholder, be it sets of data, scholarly publications, works of art, material objects, or DNA samples), and an emphasis upon how people access and interact with this information.
https://mitpress.mit.edu/books/series/history-and-foundations-information-science
-
-
en.wikipedia.org en.wikipedia.org
-
en.wikipedia.org en.wikipedia.org
-
The forerunner of contemporary Infographics, he initially called this the Vienna Method of Pictorial Statistics.
-
-
podcasts.apple.com podcasts.apple.com
-
www.ischool.berkeley.edu www.ischool.berkeley.edu
-
Michael Buckland coined in 1991 the phrase "information as thing" and discussed this concept in relation to evidence.
-
-
cluster.cis.drexel.edu cluster.cis.drexel.edu
-
http://cluster.cis.drexel.edu/~cchen/talks/2011/ICSTI_Chen.pdf
The Nature of Creativity: Mechanism, Measurement, and Analysis<br /> Chaomei Chen, Ph.D.<br /> Editor in Chief, Information Visualization<br /> College of Information Science and Technology, Drexel University<br /> June 7‐8, 2011
Randomly ran across while attempting to source Randall Collins quote from https://hypothes.is/a/8e9hThZ4Ee2hWAcV1j5B9w
-
-
Local file Local file
-
OCLC began automated catalog card production in 1971, when the shared cataloging system first went online. Cardproduction increased to its peak in 1985, when OCLC printed 131 million. At peak production, OCLC routinelyshipped 8 tons of cards each week, or some 4,000 packages. Card production steadily decreased since then asmore and more libraries began replacing their printed cards with electronic catalogs. OCLC has printed more than1.9 billion catalog cards since 1971.
-
-
maggieappleton.com maggieappleton.com
-
There's also a good chance the DNP encourages people to spend non-significant amounts of time journaling and writing notes they never look back on.
While writing notes into a daily note page may be useful to give them a quick place to live, a note that isn't revisited is likely one that shouldn't have been made at all.
Tools for thought need to do a better job of staging ideas for follow and additional work. Leaving notes orphaned on a daily notes page may help in the quick capture process, but one needs reminders about them, means of finding them, and potential means of improving them.
If they're swept away continuously, then they only serve the sort of functionality of cleaning out of ideas that morning pages do. It's bad enough to have a massive scrap heap that looks and feels like work, but it's even worse to have it spread out among hundreds or thousands of separate files.
Does digital search fix this issue entirely? Or does it just push off the work to later when it won't be done either.
-
-
docdrop.org docdrop.org
-
I like to imagine all the thoughts and ideas I’vecollected in my system of notes as a forest. I imagine itas three-dimensional, because the trains of thought I’vebeen working on for some time look like trees, withbranches of argument, point, and counterpoint andleaves of source-based evidence. Actually, the forest isfour-dimensional, because it changes over time, growingas I add more to it. A piece of output I make using thisforest of thoughts is like a path through the woods. It’sa one-dimensional narrative or interpretation that startsat one point, moves in a line or an arc (sometimes azig-zag) through the woods, touching some but not allof the trees and leaves. I like this imagery, because itsuggests there are many ways to move through the forest.
-
- Jul 2022
-
www.theatlantic.com www.theatlantic.com
-
including history, science, and other content that could build the knowledge and vocabulary they need to understand both written texts and the world around them?
I have created a first-year student module to think about the information needs they have themselves. e.g. knitters, genealogists, gamers, foodies, etc.
I'm more interested in students understanding "how" they evaluate information. Are there tools built into websites, e.g. comment sections, thumbs up/down, # of subscribers, etc.
-
-
-
We brought in a metadata librarian, Elizabeth Padilla, from British Columbia Institute of Technology (BCIT), to ensure people can find the materials in the niches they want, using the language they already know.
-
-
-
Citing Pliny’s “no book so bad,” Gesner made a point of accumulating information about all the texts he could learn about, barbarian and Christian, in manuscript and in print, extant and not, without separating the good from the bad: “We only wanted to list them, and we have left to others free selection and judgment.”202
-
-
docdrop.org docdrop.org
-
. I thinkit’s often an issue for people when they first become note-makers: an anxiety about getting the “right” stuff out ofa book, or even “all the stuff”. I don’t think this iscompletely possible, and I think it’s increasingly lesspossible, the better the book.
In the 1400s-1600s it was a common desire to excerpt all the value of books and attempts were made, though ultimately futile. This seems to be a commonly occurring desire.
Often having a simple synopsis and notes isn't as useful as it may not spark the same sort of creativity and juxtaposition of ideas a particular reader might have had with their own context.
Some have said that "content is king". I've previously thought that "context is king". Perhaps content and context end up ruling as joint monarchs.
-
-
www.nngroup.com www.nngroup.com
-
WYSIWYG assumes there is only one useful representation of the information: that of the final printed report. Although we are not arguing against a print preview function, even when the goal is to produce a printed document, it may be useful to have a different representation when preparing the document. For example, we may want to see formatting symbols or margin outlines, or it may be useful to see index terms assembled in the margin while we are composing.
-
-
thesephist.com thesephist.com
-
The current state web browsers is particularly damning from this perspective. Web browsers have access to such a treasure trove of valuable, often well-structured information about what we learn and how we think, what interests we have, and who we talk to. Rather than trying to take that information and let us build workflows out of them, browsers remain a strictly utilitarian tool – a rectangular window into documents and apps that play dumb, ignorant of the valuable information that transits through them every day.
-
The vision of the web browser that excites me the most is one where the browser is a medium for creativity, learning, and thinking deeply that spans personal and public spheres of knowledge. This browser will be fast and private, of course, but more than that, this browser will let me explore the Web from the comfort of my own garden of information. It’ll break the barriers between different apps that silo our information to help us search and remember across all of them. It’ll use a deeper machine understanding of language and images to summarize articles, highlight important ideas, and remind me what I should remember. It’ll let me do it all together with other people in a way that feels like real presence, rather than just avatars on screen.
-
Most existing tools and browsers treat web pages and pieces of notes like complete black boxes of information. These tools know how to scan for keywords, and they have access to the metadata we use to tag our information like hashtags and timestamps, but unlike a human, most current tools don’t try to peer into the contents of our notes or reading materials and operate with an understanding of our information. With ratcheting progress in machine understanding of language, I think we have good high-quality building blocks to start building thinking mediums and information systems that operate with some understanding of our ideas themselves, rather than simply “this is some text”.
-
So, what are the building blocks of a powerful thinking medium that can actually help us think, more than just recall? For a tool that has such broad access to information like a web browser, I think a critical piece of the puzzle is better machine understanding of language.
-
If we want to organize information that flows through our lives, we simply can’t restrict our design space to be a single product or app. No matter how great a note-taking app is, my emails are going to live outside of it. No matter how seamless the experience in my contacts app, my text conversations are going to live outside of it. We should acknowledge this fundamental limitation of the “note-taking app” approach to building tools for thought, and shift our focus away from building such siloed apps to designing something that lives on top of these smaller alcoves of personal knowledge to help us organize it regardless of its provenance. If we want to build a software system that can organize information across apps, what better place to start than the one piece of software that has access to it all, where most of us live and work nearly all the time? I think the browser is a rich place to build experiments in this space, and my personal experience building Monocle and Revery support this idea so far.
-
In the browser of the future, the boundary between my personal information and the wider Web’s information landscape will blur, and a smarter, more literate browser will help me navigate both worlds with a deeper understanding of what I’m thinking about and what I want to discover. It’ll remind me of relevant bookmarks when I’m taking lecture notes; it’ll summarize and pick out interesting details from long news articles for me; it’ll let me search across the Web and my personal data to remember more and learn faster.
Tags
Annotators
URL
-
-
thesephist.com thesephist.com
-
I think we’ve barely begun to tap the potential of designing the Web as as built environment and a work of architecture around our digital living spaces. When we design the One Hypertext for people, not just for information, the Web becomes something more than a resource. It becomes the Metaverse.
-
Today, we find a different set of metaphors for the Web. We don’t go on the Internet as much, or log in and log out anymore. Instead, we’re online or offline, connected or disconnected. “Online” is a state of being, not a place to be. (When was the last time you closed your web browser?) We spend most of our time on the Web not browsing or exploring, but subjecting ourselves to the flow of information that the Internet now levies at our attention.
Tags
Annotators
URL
-
-
plexus.substack.com plexus.substack.com
-
Participation inequality plagues the internet. Only 1% of people on any given platform create new content. 99% only consume.Many think that's just what happens when human communities scale. But maybe it's just what happens in an internet built for advertising. Consider that:All of the internet's interfaces—social feeds, search bars, news sites—are optimized for consumption.Interfaces for creating new content, particularly knowledge, are antiquated. Word-processors look like they did forty years ago, disconnected from the internet and any content you might write about. Which means: writing requires hours of searching and sorting. Knowledge creation is painful for the people best at it, and inaccessible to most others. What would it take to make writing accessible? Maybe: a totally new kind of interface. Ideally: a word-processor that pulls in the information you need as you type. And what would that take?Unprecedented NLP to make connections as you type,A word-processor redesigned around links, andA highly technical team focused on a non-technical market.If achieved, it would:save writers hours,make knowledge production accessible to anyone who knows how to type, andlay the groundwork for a mainstream knowledge economy.
-
-
gist.github.com gist.github.com
-
5.7 Prioritize by weighing the value of additional information against the cost of not deciding.
5.7 Prioritize by weighing the value of additional information against the cost of not deciding.
-
-
dougbelshaw.com dougbelshaw.com
-
So we end up with the problem usually referred to as ‘information overload’ but I prefer to call notification literacy. As I say in the linked post, there are preventative measures and mitigating actions you can take as an individual to help ‘increase your notification literacy’. There are also ways of facilitating communities that can help, for example if the platform you’re using has threaded comments, insisting that people use instead of a confusing, undifferentiated stream of messages. You can also ensure you have a separate chat or channel just for important announcements.
-
I was particularly interested in Chris Aldrich’s observation that knowledge workers tend to talk in spatial terms about their work, especially if distracted. Following interruptions by colleagues or phone calls at work, people may frequently ask themselves “where was I?” more frequently than “what was I doing?” This colloquialism isn’t surprising as our memories for visual items and location are much stronger than actions. Knowledge workers will look around at their environments for contextual clues for what they were doing and find them in piles of paper on their desks, tabs in their computer browser, or even documents (physical or virtual) on their desktops.
-
-
Local file Local file
-
During the seventeenth century, this associative view vanished and was replaced by more literallydescriptive views simply of the thing as it exists in itself.
The associative emblematic worldview prevalent prior to the seventeenth century began to disappear within Western culture as the rise of the early modern period and the beginning of the scientific revolution began to focus on more descriptive modes of thought and representation.
Have any researchers done specific work on this shift from emblematic to the descriptive? What examples do they show which support this shift? Any particular heavy influences?
This section cites:<br /> William B. Ashworth, Jr. “Natural History and the Emblematic World View,” in Reappraisals of the Scientific Revolution, David C. Lindberg and Robert S. Westfall, eds #books/wanttoread<br /> which could be a place to start.
Note that this same shift from associative and emblematic to descriptive and pedantic coincides not only with the rise of the scientific revolution but also with the effects of rising information overload in a post-Gutenberg world as well as the education reforms of Ramus (late 1500s) et al. as well as the beginning of the move away from scholasticism.
Is there any evidence to support claims that this worldview stemmed from pagan traditions and cultures and not solely the art of memory traditions from ancient Greece? Could it have been pagan traditions which held onto these and they were supplemented and reinforced by ecclesiastical forces which used the Greek traditions?
Examples of emblematic worldview: - particular colors of flowers meant specific things (red = love, yellow = friendship, etc.) We still have these or remants - Saints had their associative animals and objects - anniversary gifts had associative meanings (paper, silver, gold, etc.) We still have remnants of these things, though most are associated with wealth (gold, silver, platinum anniversaries). When did this tradition actually start? - what were the associative meanings of rabbits, turtles, and other animals which appear frequently in manuscript marginalia? (We have the example of the bee (Latin: apes) which where frequently used this way as being associated with the idea of imitation.) - other broad categories?
-
-
jon.bo jon.bo
-
Information retention #
first test note.
-
-
bafybeicho2xrqouoq4cvqev3l2p44rapi6vtmngfdt42emek5lyygbp3sy.ipfs.dweb.link bafybeicho2xrqouoq4cvqev3l2p44rapi6vtmngfdt42emek5lyygbp3sy.ipfs.dweb.link
-
he aim of the present paper is to propose a radical resolution to this controversy: weassume that mind is a ubiquitous property of all minimally active matter (Heylighen, 2011). Itis in no way restricted to the human brain—although that is the place where we know it in itsmost concentrated form. Therefore, the extended mind hypothesis is in fact misguided,because it assumes that the mind originates in the brain, and merely “extends” itself a little bitoutside in order to increase its reach, the way one’s arm extends itself by grasping a stick.While ancient mystical traditions and idealist philosophies have formulated similarpanpsychist ideas (Seager, 2006), the approach we propose is rooted in contemporaryscience—in particular cybernetics, cognitive science, and complex systems theory. As such, itstrives to formulate its assumptions as precisely and concretely as possible, if possible in amathematical or computational form (Heylighen, Busseniers, Veitas, Vidal, & Weinbaum,2012), so that they can be tested and applied in real-world situations—and not just in thethought experiments beloved by philosophers
The proposal is for a more general definition of the word mind, which includes the traditional usage when applied to the human mind, but extends far beyond that into a general property of nature herself.
So in Heylighen's defintion, mind is a property of matter, but of all MINIMALLY ACTIVE matter, not just brains. In this respect, Heylighen's approach has early elements of the Integrated Information Theory (IIT) theory of Koch & Tononi
-
-
bafybeibbaxootewsjtggkv7vpuu5yluatzsk6l7x5yzmko6rivxzh6qna4.ipfs.dweb.link bafybeibbaxootewsjtggkv7vpuu5yluatzsk6l7x5yzmko6rivxzh6qna4.ipfs.dweb.link
-
nformation overload, a form of mental bombardment that (Shenk, 1998) aptlycharacterized as “data smog”, since it obscures rather than enlightens, while damaging health byincreasing stress levels. It is typically accompanied by a barrage of interruptions or distractionscaused by incoming emails, phone calls, text messages, tweets or “status updates”.
Information overload can also be increasingly be characterized by bad actors flooding information spaces with false, distracting or provactive information, creating conflict, abandonment and diluting the efficacy of the space for learning and collaboration.
-
-
-
there was an interesting paper that came out i cited in the in my in my in paper number one that uh was 01:15:53 looking at this question of what is an individual and they were looking at it from an information theory standpoint you know so they came up with this they came up with this uh uh theory uh and i think do they have a name for 01:16:09 it yeah uh information theory of individuality and they say base it's done at the bottom of the slide there and they say basically that uh you know an individual is a process just what's 01:16:20 what we've been talking about before that propagates information from the past into the future so that you know implies uh information flow and implies a cognitive process uh it implies anticipation of 01:16:33 the future uh and it probably implies action and this thing that is an individual it is not like it is a layered hierarchical individual it's like you can draw a circle around 01:16:45 anything you know in a certain sense and call it an individual under you know with certain uh definitions you know if you want to define what its markov blanket is 01:16:57 but uh but you know we are we are we are our cells are individuals our tissues liver say is an individual um a human is an individual a family is an 01:17:12 individual you know and it just keeps expanding outward from there the society is an individual so it really it's none of those are have you know any kind of inherent preference 01:17:24 levels there's no preference to any of those levels everything's an individual layered interacting overlapping individuals and it's just it's just a it's really just a the idea of an individual is just where 01:17:36 do you want to draw your circle and then you can you know then you can talk about an individual at whatever level you want so so that's all about information so it's all about processing information right
The "individual" is therefore scale and dimension dependent. There are so many ways to define an individual depending on the scale you are looking at and your perspective.
Information theory of individuality addresses this aspect.
-
-
reallifemag.com reallifemag.com
-
In our current “information age,” or so the story goes, we suffer in new and unique ways.
Tags
Annotators
URL
-
-
www.niemanlab.org www.niemanlab.org
-
Social natives ≠ digital natives.
-
-
www.reddit.com www.reddit.com
-
Take extreme care how you may conflate and differentiate (or don't) the ideas of "information" and "knowledge". Also keep in mind that the mathematical/physics definition of information is wholly divorced from any semantic meanings it may have for a variety of receivers which can have dramatically different contexts which compound things. YI suspect that your meaning is an Take extreme care how you may conflate and differentiate (or don't) the ideas of "information" and "knowledge". Also keep in mind that the mathematical/physics definition of information is wholly divorced from any semantic meanings it may have for a variety of receivers which can have dramatically different contexts which compound things. I suspect that your meaning is an
Take extreme care how you may conflate and differentiate (or don't) the ideas of "information" and "knowledge". Also keep in mind that the mathematical/physics definition of information is wholly divorced from any semantic meanings it may have for a variety of receivers which can have dramatically different contexts which compound things.
It's very possible that the meaning you draw from it is an eisegetical one to the meaning which Eco assigns it.
-
-
www.hindawi.com www.hindawi.com
-
Informational Theory of Aging: The Life Extension Method Based on the Bone Marrow Transplantation
-
-
-
Deep Learning and an Information Theory of Aging
-
-
pubmed.ncbi.nlm.nih.gov pubmed.ncbi.nlm.nih.gov
-
Informational Theory of Aging: The Life Extension Method Based on the Bone Marrow Transplantation
-
-
link.springer.com link.springer.com
-
The information theory of aging: The major factors that determine lifespan
-
- Jun 2022
-
Local file Local file
-
Knowledge is the only resource that getsbetter and more valuable the more it multiplies.
He who receives an idea from me, receives instruction himself without lessening mine; as he who lights his taper at mine, receives light without darkening me.<br /> —Thomas Jefferson
-
We’ve been conditioned to view information through aconsumerist lens: that more is better, without limit.
-
-
hybridpedagogy.org hybridpedagogy.org
-
For Jerome Bruner, the place to begin is clear: “One starts somewhere—where the learner is.”
One starts education with where the student is. But mustn't we also inventory what tools and attitudes the student brings? What tools beyond basic literacy do they have? (Usually we presume literacy, but rarely go beyond this and the lack of literacy is too often viewed as failure, particularly as students get older.) Do they have motion, orality, song, visualization, memory? How can we focus on also utilizing these tools and modalities for learning.
Link to the idea that Donald Trump, a person who managed to function as a business owner and president of the United States, was less than literate, yet still managed to function in modern life as an example. In fact, perhaps his focus on oral modes of communication, and the blurrable lines in oral communicative meaning (see [[technobabble]]) was a major strength in his communication style as a means of rising to power?
Just as the populace has lost non-literacy based learning and teaching techniques so that we now consider the illiterate dumb, stupid, or lesser than, Western culture has done this en masse for entire populations and cultures.
Even well-meaning educators in the edtech space that are trying to now center care and well-being are completely missing this piece of the picture. There are much older and specifically non-literate teaching methods that we have lost in our educational toolbelts that would seem wholly odd and out of place in a modern college classroom. How can we center these "missing tools" as educational technology in a modern age? How might we frame Indigenous pedagogical methods as part of the emerging third archive?
Link to: - educational article by Tyson Yunkaporta about medical school songlines - Scott Young article "You should pay for Tutors"
aside on serendipity
As I was writing this note I had a toaster pop up notification in my email client with the arrival of an email by Scott Young with the title "You should pay for Tutors" which prompted me to add a link to this note. It reminds me of a related idea that Indigenous cultures likely used information and knowledge transfer as a means of payment (Lynne Kelly, Knowledge and Power). I have commented previously on the serendipity of things like auto correct or sparks of ideas while reading as a means of interlinking knowledge, but I don't recall experiencing this sort of serendipity leading to combinatorial creativity as a means of linking ideas,
Tags
- educational tools
- indigenous knowledge
- toaster notifications
- technobabble
- attitudes
- arts in education
- information as currency
- literacy isn't everything
- Indigenous pedagogy
- combinatorial creativity
- third archive
- idea links
- orality vs. literacy
- location
- modality shifts
- quotes
- Jerome Bruner
- Donald J. Trump
- orality
- Tyson Yunkaporta
- inventories
- tutors
- where
- Indigenous knowledge as educational technology
- linguistics
- educational substrates
Annotators
URL
-